논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
T-RAG: LLM 전쟁터에서 얻은 교훈
Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla
카타르 컴퓨팅 연구소(Qatar Computing Research Institute)
하마드 빈 칼리파 대학교(Hamad Bin Khalifa University)
도하(Doha)
{mfatehkia, jlucas, schawla}@hbku.edu.qa
초록(Abstract)
대규모 언어 모델(LLM: Large Language Models)은 놀라운 언어 능력을 보여주며 다양한 분야의 애플리케이션에 통합하려는 시도를 촉발시켰습니다. 중요한 응용 분야 중 하나는 데이터 보안이 주요 고려 사항인 사설 기업 문서에 대한 질문 응답(question answering)이며, 이는 온-프레미스(on-prem)에 배포할 수 있는 애플리케이션이 필요함을 의미합니다. 제한된 컴퓨팅 자원과 질의에 정확하게 응답하는 강력한 애플리케이션이 필요합니다. 검색-증강 생성(RAG: Retrieval-Augmented Generation)은 LLM 기반 애플리케이션을 구축하기 위한 가장 주목받는 프레임워크로 부상했습니다. RAG를 구축하는 것은 비교적 간단하지만, 그것을 강력하고 신뢰할 수 있는 애플리케이션으로 만들기 위해서는 광범위한 맞춤화와 애플리케이션 도메인에 대한 상당히 깊은 지식이 필요합니다. 우리는 사설 조직 문서에 대한 질문 응답을 위한 LLM 애플리케이션을 구축하고 배포한 경험을 공유합니다. 우리의 애플리케이션은 RAG 사용과 함께 미세 조정된 오픈 소스 LLM을 결합합니다. 또한, 우리가 Tree-RAG(T-RAG)라고 부르는 우리 시스템은 조직 내 엔티티 계층을 나타내기 위해 트리 구조를 사용합니다. 이는 조직의 계층 내 엔티티에 관한 사용자 질의에 응답할 때 컨텍스트를 증강하기 위한 텍스트 설명을 생성하는 데 사용됩니다. 우리의 평가는 이 조합이 단순한 RAG나 미세 조정 구현보다 더 나은 성능을 보인다는 것을 보여줍니다. 마지막으로, 실제 사용을 위한 LLM 애플리케이션을 구축하는 데 기반한 경험에서 얻은 몇 가지 교훈을 공유합니다.
서론(Introduction)
대규모 언어 모델(LLM: Large Language Models)은 자연어 처리(NLP: Natural Language Processing)에서 가장 최근의 발전을 대표하며, 언어 처리에서 다양한 능력을 보여주고 있습니다 [Zhao et al.(2023)]. ChatGPT, OpenAI에서 공개 테스트를 위해 출시한 애플리케이션,이 바이럴하면서 주목을 받기 시작했습니다. 이는 창의적 글쓰기 [Gómez-Rodríguez and Williams(2023)], 프로그래밍 [Liventsev et al.(2023)], 법률 [Louis et al.(2023)] 및 의료 [He et al.(2023)] 분야와 같이 더 큰 사실적 정확성이 요구되는 다양한 애플리케이션에 LLM을 사용하려는 시도를 촉발시켰습니다.
LLM에 대한 유망한 응용 분야 중 하나는 거버넌스/정책 매뉴얼과 같은 독점적 조직 문서에 대한 질문 응답입니다. 이러한 문서는 종종 조직 내 일상적인 운영과 의사 결정을 안내하는 정기적인 참조 지점입니다. 이는 조직 내 전문가들이 이러한 정보에 대한 질의에 응답하거나 해당 문서를 자주 참조하게 만듭니다. 따라서 조직 문서를 기반으로 다양한 사용자 질의에 응답할 수 있는 애플리케이션이 있으면 효율성이 증가할 수 있는 잠재력이 있습니다.
이러한 설정에서 LLM(Large Language Model) 애플리케이션을 배포할 때 고려해야 할 여러 가지 사항이 있습니다. 주요 우려 사항 중 하나는 문서의 기밀성 때문에 발생하는 보안 위험입니다. 결과적으로, 데이터 유출 위험 때문에 API를 통한 독점 LLM 모델의 사용이 불가능합니다. 이는 온프레미스(on-premise)에 배포할 수 있는 오픈 소스 모델의 사용을 필요로 합니다. 두 번째 우려 사항은 제한된 컴퓨팅 자원과 사용 가능한 문서를 기반으로 생성할 수 있는 상대적으로 작은 교육 데이터셋입니다. 마지막으로, 이러한 애플리케이션은 사용자 질문에 대해 신뢰할 수 있고 정확하게 응답할 수 있어야 합니다. 따라서, 이러한 설정에서 견고한 애플리케이션을 배포하는 것은 사소한 일이 아니며, 많은 결정과 맞춤화가 필요합니다.
사용 사례:
우리의 사용 사례는 조직의 거버넌스 매뉴얼을 기반으로 한 질문 응답입니다. 이러한 문서의 주요 특징은 (i) 조직의 거버넌스 원칙, 다양한 거버넌스 기관의 의무 및 책임에 대한 설명과 (ii) 조직 아래의 전체 계층 구조와 그 분류에 대한 세부 정보입니다. 문서를 기반으로 질문에 응답하는 LLM 애플리케이션은 다양한 거버넌스 기관, 그들의 책임을 설명하고, 조직 내의 엔터티와 그들이 속한 카테고리를 나열하는 등 다양한 질문에 답할 수 있어야 합니다. 아래는 사용자가 UN 조직에 대한 문서를 기반으로 할 수 있는 질문 유형의 몇 가지 예시입니다:
- Gig 는 UNICEF와 ITU 동료들을 그들의 전략에 어떻게 참여시킬 계획인가요?
- HR 관리 아래의 엔터티 예시를 제공해주세요.
- Giga가 2023년에 타겟팅할 세 가지 넓은 범주의 청중은 누구인가요?
이 작업에서, 우리는 대규모 비영리 조직을 위한 개인 거버넌스 매뉴얼 문서에 대한 질문 응답을 위한 LLM 애플리케이션을 구축하고 배포하는 경험을 공유합니다. 우리는 다음과 같은 기여를 합니다:
- 조직의 최종 사용자를 위한 거버넌스 문서에 대한 질문 응답을 위해 LLM 기반 애플리케이션을 만드는 실제 사례 연구를 제시합니다.
- 조직의 문서에서 생성된 지침 데이터셋을 기반으로 훈련된 오픈 소스 LLM을 사용하여 응답 생성을 위해 검색-증강 생성(Retrieval-Augmented Generation, RAG)을 결합한 애플리케이션을 만듭니다.
- 우리는 Tree-RAG(T-RAG)라고 부르는 시스템의 구성 요소로 새로운 트리 기반 컨텍스트를 포함합니다. 이는 조직 내 엔터티를 나타내는 트리 구조를 사용하며, 조직의 계층 내 엔터티에 관한 사용자 질문에 응답할 때 컨텍스트를 증강하기 위한 텍스트 설명을 생성하는 데 사용됩니다.
- 생성된 응답을 평가하기 위한 새로운 평가 지표(Correct-Verbose)를 제시합니다. 이 지표는 질문과 관련 없는 추가적인 정확한 정보를 제공하는 정확하지만 자세한 응답을 포착합니다.
나머지 논문은 다음과 같이 구성됩니다. 섹션 는 관련 문헌을 검토합니다. 섹션 은 몇 가지 관련 용어를 정의합니다. 섹션 는 LLM 애플리케이션을 위한 검색-증강 생성(RAG)에 대한 개요를 제공하고 T-RAG를 시연합니다. 섹션 는 우리 시스템의 구현에 대한 세부 정보를 제공합니다. 섹션 은 우리 시스템의 평가를 제시하고 섹션 은 논의와 향후 작업 방향으로 논문을 마무리합니다.
관련 작업
2.1 대규모 언어 모델(Large Language Models)
대규모 언어 모델(LLM: Large Language Models)은 자연어 처리(Natural Language Processing)에서 놀라운 능력을 보여주었습니다 [Zhao et al.(2023)]. 최근 몇 년 동안 OpenAI의 GPT 시리즈(GPT [OpenAI et al.(2023)])와 같은 다양한 LLM과 Meta의 Llama-2 [Touvron et al.(2023)]와 같은 오픈 소스 모델이 폭발적으로 증가했습니다. LLM은 트랜스포머(Transformer) 아키텍처 [Vaswani et al.(2017)]를 기반으로 하며, 큰 모델은 수백 억 개의 매개변수를 가질 수 있습니다. 이들은 책, 크롤링된 웹 페이지, 소셜 미디어 플랫폼의 대화 등 대규모 훈련 데이터 코퍼스에서 훈련됩니다 [Zhao et al.(2023)]. 이러한 언어 능력으로 인해 LLM은 질문 응답과 같은 다운스트림(downstream) 애플리케이션에 적합합니다. 그러나 LLM은 훈련 코퍼스 외부의 정보가 필요한 도메인 특화 또는 고도로 전문화된 쿼리를 처리하는 데 한계가 있습니다 [Kandpal et al.(2023)]. LLM은 금융 [Huang et al.(2023)]이나 지도 응용 프로그램을 위한 지리-언어 [Huang et al.(2022)]와 같은 특정 도메인을 위해 사전 훈련될 수 있지만, 이는 대규모 훈련 데이터 세트와 비싼 컴퓨팅 자원이 필요합니다. LLM을 사용하여 도메인 특화 애플리케이션을 구축하기 위한 다양한 접근 방식이 발전했으며, 여기서 우리는 그것들을 검토합니다.[^1]
2.2 파인튜닝(Finetuning)
파인튜닝은 도메인 특화 레이블이 지정된 데이터 세트(예: Q&A 애플리케이션을 위한 질문 및 답변 데이터 세트)에서 훈련을 통해 모델의 가중치를 업데이트함으로써 LLM의 매개변수 메모리에 도메인 지식을 통합하는 방법입니다 [Min et al.(2017)]. 이를 통해 사용자는 LLM의 언어 능력을 활용하면서 새로운 작업에 대한 지식을 통합하고 LLM의 작문 스타일과 톤을 조정할 수 있습니다 [Gao et al.(2024)]. 파인튜닝은 고품질 훈련 데이터 세트를 생성해야 하지만, 이는 사전 훈련에 필요한 데이터 규모보다 훨씬 작습니다 [Gao et al.(2024)]. 모델의 모든 매개변수를 업데이트하는 전체 파인튜닝 [Howard and Ruder(2018)]은 계산상 금지적이지만, 모델의 매개변수의 상당히 작은 부분집합을 업데이트함으로써 비슷한 성능을 달성할 수 있습니다 [Houlsby et al.(2019)]. 최근 몇 년 동안 파라미터 효율적 파인튜닝(PEFT: Parameter-Efficient Finetuning) 방법의 부상으로 파인튜닝에 필요한 메모리 사용량과 컴퓨팅 자원이 크게 줄어들었습니다 [Xu et al.(2023), Lialin et al.(2023)], 이는 자원이 적은 조직에게 더 접근하기 쉬운 옵션을 제공합니다.
2.3 검색-증강 생성(Retrieval-Augmented Generation, RAG)
LLM(Large Language Models) 애플리케이션을 구축하는데 있어 인기 있는 접근 방식 중 하나로, LLM을 훈련시키지 않아도 되는 방법은 검색 강화 생성(Retrieval Augmented Generation, RAG)입니다. 훈련 데이터 밖의 도메인 특정 질문에 대해 응답할 때, LLM은 잘못된 정보나 '환각'(hallucinations)을 생성할 수 있습니다 [Zhang et al.(2023)]. RAG는 외부 데이터 소스에서 정보를 검색하여 그 정보를 LLM 모델에 컨텍스트 정보로 전달하여 응답을 생성하도록 함으로써 이러한 한계를 해결합니다 [Lewis et al.(2020)]. 이는 모델이 외부 정보 소스에 접근할 수 있게 함으로써 생성된 응답의 사실 정확성과 관련성을 향상시킵니다 [Ram et al.(2023)]. RAG는 사전 훈련(pretraining) 중에 사용될 수 있지만 [Guu et al.(2020a), Guu et al.(2020b)], 그 실용성과 사용의 상대적 용이성 때문에 추론(inference) 중에 널리 사용됩니다 [Gao et al.(2024)]. 그러나, RAG는 컨텍스트를 생성하기 위해 사용된 검색된 문서의 구성에 민감하므로 효과적인 검색 파이프라인을 구축하기 위해 광범위한 맞춤화가 필요합니다 [Cuconasu et al.(2024)]. RAG는 미세 조정(finetuning)과 같은 다른 접근 방식과도 결합될 수 있습니다 [Balaguer et al.(2024)].
2.4 지식 그래프(Knowledge Graphs)
RAG 애플리케이션은 일반적으로 사용자 쿼리에 기반하여 관련 문서를 가져오는 검색기(retriever)에 의존하지만, 관련 컨텍스트를 검색하는 다른 접근 방식이 있을 수 있습니다. 그 중 하나는 지식 그래프를 사용하여 입력 쿼리에 기반한 컨텍스트를 생성하는 것입니다 [Agrawal et al.(2023a)]. 지식 그래프는 실제 세계 사실의 상징적 지식을 엔티티(그래프의 노드) 쌍과 그들의 관계(그래프의 에지)를 나타내는 트리플로 표현합니다. 사용자 쿼리에서 언급된 엔티티를 기반으로 지식 그래프에서 관련 정보를 추출하고, 이를 트리플로 [Baek et al.(2023)] 또는 텍스트 문장으로 재작성하여 [Wu et al.(2023)] 컨텍스트로 제공할 수 있습니다. 도메인 특정 지식 그래프는 의학 [Xia et al.(2022)], 금융 [Baldazzi et al.(2023)], 교육 [Agrawal et al.(2023b)] 등의 분야에서 질문 응답 애플리케이션에 사용되었습니다.
2.5 LLM의 응용
LLM의 사용은 교육 분야에서 시험 문제 생성 [Drori et al.(2023)], 채용 및 직업 추천 [Fang et al.(2023)], 뉴스 추천 [Xiao et al.(2022)], 다양한 헬스케어 애플리케이션 [He et al.(2023)], 의료 질문 응답 [Guo et al.(2022)], 환자 건강 기록 조회 [Hamidi and Roberts(2023)], 정신 건강 보조 도구 [Lai et al.(2023)], 법률 질문 응답 [Louis et al.(2023)] 및 IT 지원 시스템 [Yang et al.(2023)] 등 다양한 분야에서 탐구되었습니다.
관련 용어
아래는 일부 LLM 관련 용어의 간단한 용어집입니다:
- 프롬프트(Prompt): LLM에 입력으로 제공되는 모든 텍스트로, 모델의 행동과 생성된 출력을 조건화합니다. 이는 작업에 따라 지시사항, 맥락, 질문 및 예시를 포함한 여러 요소로 구성될 수 있습니다.
- 시스템 프롬프트(System Prompt): 특별한 태그(예: «SYS»)로 구분되고 모델에 따라 프롬프트 시작 부분에 배치되는 텍스트 지시사항입니다. 지시사항을 포함하며 LLM이 수행할 것으로 예상되는 설정을 설정합니다. 우리가 사용한 예시 시스템 프롬프트는 부록 A에 제공됩니다.
- 맥락(Context): LLM이 질문에 응답하는 데 도움이 될 수 있는 프롬프트에 추가된 추가 텍스트 조각입니다. 예를 들어, FIFA 월드컵이 어디에서 열렸는지에 대한 질문에 대해, 맥락은 위키피디아 기사에서 관련 단락일 수 있습니다.
- 맥락 내 학습(In-context Learning): LLM이 컨텍스트에서 시연을 제공받음으로써, 파인튜닝 없이 새로운 작업을 수행할 수 있는 능력입니다. 예를 들어, 감정 분석을 수행하기 위해 LLM에게 두 문장과 그 감정을 제공한 다음, 세 번째 문장에 대해 모델이 그 감정의 예측을 출력하도록 할 수 있습니다. 이는 또한 few-shot 학습으로도 언급됩니다.
- 맥락 창/길이(Context Window/Length): LLM이 입력으로 받을 수 있는 최대 토큰 수(라마-2에서는 4,096 토큰)입니다. 더 긴 맥락 창은 모델이 한 번에 더 많은 정보를 처리할 수 있게 하여, 긴 텍스트를 이해하는 데 유용합니다.
- 환각(Hallucination): LLM이 맥락, 사용자 입력 또는 세계 지식과 벗어나면서도 그럴듯하지만 사실적으로 잘못된 출력을 생성할 때 발생합니다 [Zhang et al.(2023)]. 예를 들어, UNHCR 혁신 서비스 아래에 있는 엔티티를 나열하라는 요청에 대해 모델이 조직 내에 존재하지 않는 디자인 서비스를 그럴듯하게 하지만 잘못 언급할 수 있습니다.
검색-증강 생성(Retrieval-Augmented Generation)
검색-증강 생성(Retrieval-Augmented Generation, RAG)은 모델에 외부 정보원을 제공함으로써 도메인 특정 작업에서 LLM의 성능을 향상시킵니다. 여러 변형이 있지만, 우리는 알고리즘 1에서 전형적인 RAG 적용의 개요를 제공합니다. 이는 일반적으로 시작 시 한 번 수행되는 인덱스(Index) 과정과 들어오는 쿼리에 대한 응답으로 매번 발생하는 쿼리(Query) 과정의 두 과정으로 구성됩니다 [Barnett et al.(2024)]. 인덱스 과정은 다음과 같이 발생합니다. 입력 문서 는 이산 청크 로 분할됩니다(단계 ). 인코더 모델을 사용하여 분할된 청크 는 임베딩 벡터 로 변환됩니다(단계 4) 이후 이 벡터들은 벡터 데이터베이스에 저장됩니다(단계 5). 이 데이터베이스는 나중에 주어진 쿼리에 대한 관련 청크를 검색하는 데 사용됩니다.
사용자 쿼리(user queries)에 대한 응답으로 쿼리 처리가 이루어집니다. 주어진 쿼리 에 대해, 인코딩 모델(encoding model)은 쿼리의 벡터 임베딩(vector embedding) 을 생성하는 데 사용됩니다. 그런 다음 데이터베이스는 쿼리 임베딩 과 유사한 상위 개의 청크 임베딩(chunk embeddings) 을 찾기 위해 검색됩니다. 청크 임베딩 과 쿼리 임베딩 사이의 유사성을 결정하는 다양한 알고리즘이 있으며, 몇 개의 청크를 가져올지와 어떤 청크를 가져올지를 결정합니다. 데이터베이스에서 검색된 상위 개의 청크 는 쿼리와 함께 프롬프트 템플릿(prompt template)으로 전달됩니다. 완성된 프롬프트는 LLM 모델에 입력되어 제공된 정보를 바탕으로 출력을 생성합니다. 이 응답은 사용자에게 반환됩니다.
표 1: LLM 애플리케이션을 위한 알고리즘. 왼쪽은 전형적인 RAG 애플리케이션을 위한 알고리즘이고, 오른쪽은 우리 시스템(T-RAG)을 위한 알고리즘입니다. 파란색으로 강조된 부분은 우리 시스템이 전형적인 RAG 애플리케이션과 다른 부분입니다. T-RAG의 인덱스 프로세스(Index Process)는 RAG와 유사하여 보여주지 않습니다.

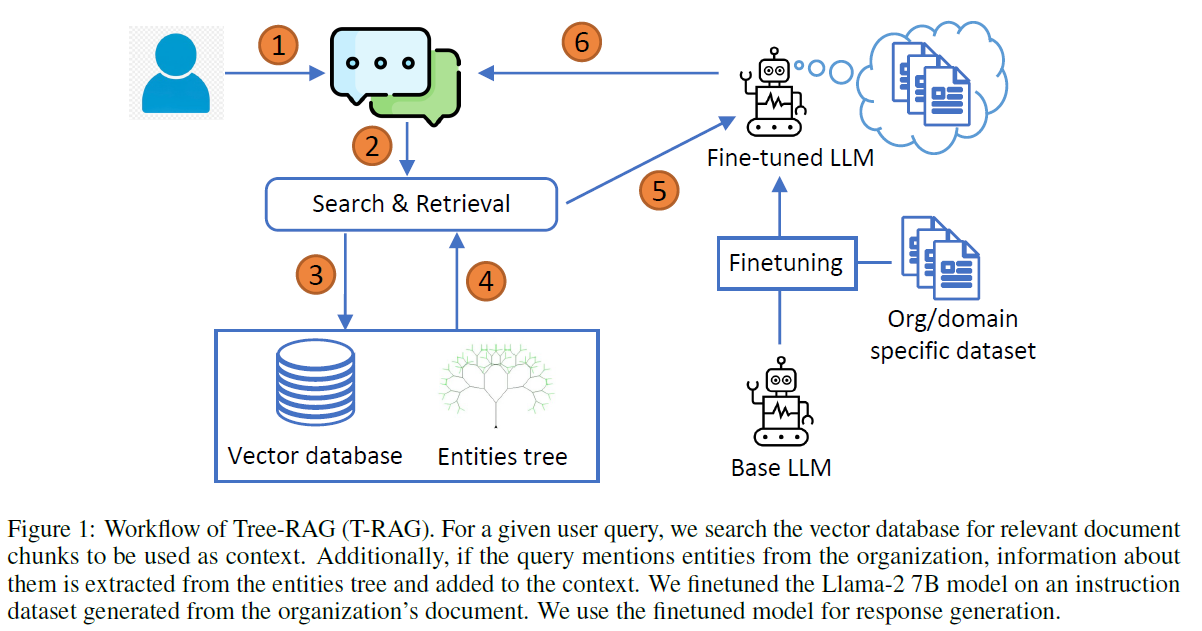
그림 1: 트리-RAG(Tree-RAG, T-RAG)의 워크플로. 주어진 사용자 쿼리에 대해, 우리는 컨텍스트로 사용될 관련 문서 청크를 검색하기 위해 벡터 데이터베이스를 검색합니다. 추가적으로, 쿼리가 조직의 엔티티를 언급하는 경우, 엔티티 트리에서 그들에 대한 정보를 추출하여 컨텍스트에 추가합니다. 우리는 조직의 문서에서 생성된 지시 데이터셋(instruction dataset)에 Llama-2 7B 모델을 파인튜닝(finetuned)하여 응답 생성에 사용합니다.
4.1 T-RAG
우리 시스템, 트리-RAG(T-RAG)의 전체 워크플로는 그림 1과 알고리즘 2에서 보여지고 설명됩니다. 우리 시스템은 쿼리 처리 과정에서 전형적인 RAG 애플리케이션과 다릅니다. 기존의 사전 훈련된 LLM 대신, 우리는 답변 생성을 위해 LLM의 파인튜닝 버전을 사용합니다; 우리는 나중에 설명될 조직의 문서를 기반으로 생성된 질문과 답변의 지시 데이터셋에 LLM 모델을 파인튜닝했습니다.
T-RAG의 특징은 컨텍스트 검색을 위해 벡터 데이터베이스에 추가로 엔티티 트리(entities tree)를 포함하는 것입니다. 엔티티 트리는 조직 내 엔티티에 대한 정보와 계층 내 위치를 보유합니다. 이 트리의 각 노드는 엔티티를 나타내며, 부모 노드는 그것이 속한 그룹을 나타냅니다. 예를 들어, 그림 2에 보여진 UNHCR 조직 구조에서 UNHCR 혁신 서비스(UNHCR Innovation Service)는 부고등판무관(Deputy High Commissioner) 아래에 있는 엔티티입니다.
검색 중에는 벡터 데이터베이스에서 검색된 컨텍스트를 더 확장하기 위해 엔티티 트리(entity tree)를 사용합니다. 엔티티 트리 검색 및 컨텍스트 생성은 다음과 같이 이루어집니다. 파서 모듈이 사용자 쿼리에서 조직의 엔티티 이름과 일치하는 키워드를 검색합니다. 하나 이상의 일치 항목이 발견되면, 트리에서 각 일치하는 엔티티에 대한 정보를 추출하고 이를 조직의 계층 내 위치와 엔티티에 대한 정보를 제공하는 텍스트 문장으로 변환합니다. 이 정보는 벡터 데이터베이스에서 검색된 문서 조각들과 결합되어 컨텍스트를 형성합니다. 이를 통해 모델은 사용자가 이러한 엔티티에 대해 질문할 때 엔티티와 그 위치에 대한 정보를 조직의 계층 내에서 접근할 수 있습니다.
방법(Methods)
이 섹션과 이후 섹션에서는 조직의 문서를 기반으로 한 우리 시스템과 평가에 대한 세부 사항을 공유할 것입니다. 이 문서에서 구체적인 세부 사항을 공유할 수 없기 때문에, 우리는 공개적으로 이용 가능한 UN 조직 문서를 사용하여 예시를 보여줄 것입니다.
5.1 지시 데이터셋 준비(Instruction Dataset Preparation)
LLM 모델을 파인튜닝(finetuning)하는 데는 도메인 특화 훈련 데이터셋이 필요합니다. 여기서는 조직의 문서에서 지시 데이터셋을 생성하기 위해 따른 절차를 설명합니다.
첫 번째 단계는 원본 PDF 문서 파일을 텍스트 형식으로 파싱하여 추가 처리를 위한 준비를 하는 것이었습니다; 이 작업은 LangChain 라이브러리를 사용하여 수행되었습니다. 텍스트 외에도 파일에는 여러 테이블과 조직 차트의 모든 엔티티를 보여주는 이미지가 포함되어 있었습니다. 테이블은 테이블의 정보를 설명하는 문장을 작성한 인간 전문가에 의해 수동으로 텍스트로 변환되었습니다. 조직 차트도 같은 방식으로 텍스트로 변환되었습니다.
다음 단계는 문서를 조각으로 나누는 것이었습니다. 이 작업은 문서의 섹션 헤더를 기반으로 하여 각 섹션을 별도의 조각으로 분할하여 수행되었습니다. 그런 다음 여러 번의 반복을 거쳐 각 조각에 대해 (질문, 답변) 쌍을 생성했습니다. 첫 번째 반복에서는 각 조각에 대해 Llama-2 모델에게 제공된 조각에 대한 질문과 답변을 생성하도록 요청했습니다. 모델은 참 또는 거짓(True or False), 요약(Summary), 짧은 답변(Short Answer) 등 다양한 유형의 질문을 생성하도록 요청받았습니다. 질문, 답변 및 관련 조각을 제공하는 모델 응답이 기록되었습니다. 두 번째 반복에서는 각 조각에 대해 모델에게 대화의 예를 제시하고 사용자와 AI 조수 사이의 대화를 생성하도록 요청했습니다. 세 번째 반복에서는 모델에게 주어진 조각에 대해 질문과 답변을 생성하는 동일한 작업을 수행하도록 요청했으며, 이 반복에서는 문서를 기반으로 인간 전문가가 생성한 질문의 예시를 모델에게 제공했습니다. 프롬프트는 부록 A. 에 제공됩니다.
우리는 다양한 반복을 통해 생성된 질문과 답변을 집계하여 데이터셋을 만들었습니다. 생성된 질문과 답변의 수동 검사를 통해 품질 검사가 수행되었습니다. 또한 중복된 질문을 제거하기 위해 중복 제거 작업도 수행했습니다. 우리의 데이터셋은 무작위로 훈련 세트와 검증 세트로 분할된 1,614개의 질문과 답변 쌍으로 구성되어 있습니다.
5.2 LLM 파인튜닝(Finetuning)
LLM(Large Language Models)의 전체 미세조정(finetuning)은 매개변수의 수가 많기 때문에 계산 비용이 많이 듭니다. 매개변수 효율적 미세조정(Parameter-Efficient Fine-Tuning, PEFT)은 LLM을 효율적으로 미세조정하기 위한 기술 세트입니다. 이러한 기술 중 하나는 QLoRA [Dettmers et al.(2023)]로, 모델 가중치의 4비트 양자화(Quantization)와 저랭크 적응(Low-Rank Adaptation, LoRA) [Hu et al.(2021)]의 조합을 사용하는 기술로, LLM의 효율적인 미세조정을 위한 또 다른 기술입니다. LoRA 방법은 LLM 모델의 모델 가중치가 낮은 본질적 순위를 가지고 있어 저랭크 행렬로 근사할 수 있다는 가설에서 영감을 받았으며, 이는 훈련 중에 업데이트해야 하는 매개변수의 수를 크게 줄입니다.
LoRA 방법은 아래의 방정식에서 표현되며, 여기서 는 모델의 출력, 는 입력이고 은 사전 훈련된 모델 가중치입니다. 은 저랭크 행렬( where ) 세트로, 미세조정 중에 업데이트되며 사전 훈련된 가중치 는 고정됩니다. 따라서, 업데이트해야 하는 매개변수의 수는 으로, 사전 훈련된 매개변수의 총 수 보다 훨씬 작습니다. Llama-2 7B를 미세조정할 때, 우리는 의 순위를 사용하여 대략 의 훈련 가능한 매개변수를 가졌으며, 이는 모델의 전체 매개변수 세트에 비해 약 200배 감소한 것입니다.
QLoRA는 가중치 양자화를 통해 상당한 메모리 절약을 달성합니다. 여기서 모델 가중치 는 더 낮은 정밀도 4비트 표현으로 줄어듭니다. 우리는 Hugging Face의 'peft 라이브러리를 사용하여 QLoRA로 Q&A 지시 데이터셋에서 기본 LLM 모델을 미세조정했습니다. 미세조정은 24GB의 메모리를 가진 4개의 Quadro RTX 6000 GPU에서 수행되었습니다.
5.3 엔티티를 위한 트리 그래프(Tree Graph for Entities)
문서에는 조직 내의 계층과 부서를 보여주는 조직도가 포함되어 있었습니다. 이에는 조직 아래에 있는 모든 엔티티와 그들이 속한 특정 카테고리 및 하위 카테고리의 목록이 포함되었습니다. 이러한 엔티티와 그들의 계층 내 위치에 대한 질문에 응답하기 위해서는, LLM 모델이 접근하고 사용할 수 있는 형식으로 이 정보를 표현해야 합니다. 이 섹션에서는 이 정보를 표현하고 필요할 때 사용자 질문에 기반하여 검색하여 LLM 모델에 전달되는 컨텍스트를 더욱 향상시키는 접근 방식을 설명합니다.
조직의 계층 구조와 그 안의 모든 엔터티는 각 노드가 조직 내의 어떤 엔터티를 나타내는 트리 형태로 인코딩됩니다. 각 노드의 부모는 그것이 속한 즉각적인 카테고리를 나타냅니다. 예시로, 그림 는 UNHCR 조직도의 일부를 보여줍니다. 보여진 예시에서, 부다페스트의 글로벌 서비스 센터(Global Service Center)는 고등 판무관(Deputy High commissioner) 아래에 있으며, 이는 다시 고등 판무관 집행 사무소(High Commissioner Executive Office) 아래에 있습니다. 이런 식으로, 트리는 조직 내의 각 엔터티에 대한 전체 계층 구조를 인코딩하며, 엔터티로부터 속한 상위 카테고리 및 그 아래에 속할 수 있는 다른 엔터티까지의 전체 경로를 추적하는 데 사용될 수 있습니다. 이 정보는 검색 단계에서 추출되어 텍스트 문장으로 변환됩니다. 이 문장들은 벡터 데이터베이스에서 검색된 문서 조각들과 함께 컨텍스트에 추가됩니다(그림 2 참조).

그림 2: 컨텍스트 생성을 위한 검색 과정. 여기서는 UNHCR 조직도에서 나온 예시를 사용하여 트리 검색 및 검색이 어떻게 이루어지는지 보여줍니다. 문맥적 문서를 검색하는 것 외에도, 우리는 조직에서 명명된 엔터티를 감지하기 위해 사용자 정의 규칙과 함께 spaCy 라이브러리를 사용합니다. 만약 쿼리가 하나 이상의 그러한 엔터티를 포함하고 있다면, 해당 엔터티의 계층 내 위치에 대한 정보가 트리에서 검색되어 텍스트 문장으로 포맷되며, 이는 검색된 문서와 함께 컨텍스트에 추가됩니다. 사용자의 쿼리에 언급된 엔터티가 없는 경우, 트리 검색은 생략되고 검색된 문서에서의 컨텍스트만 사용됩니다.
이는 LLM 모델이 응답을 생성할 때 사용할 수 있는 엔터티에 관한 관련 정보로 컨텍스트를 향상시킵니다.
컨텍스트에서 가장 관련성 높은 엔터티 관련 정보만 제공하기 위해, 사용자의 쿼리에서 조직의 엔터티가 언급되었는지, 그리고 어떤 엔터티가 언급되었는지 감지해야 합니다. 사용자의 쿼리가 조직의 어떤 엔터티에도 언급하지 않는 경우, 트리 검색은 생략되고 검색된 문서에서의 컨텍스트만 사용됩니다. 이러한 적응형 행동을 가능하게 하기 위해, 우리는 조직과 관련된 명명된 엔터티만 감지하는 방법이 필요합니다. 우리는 사용자의 쿼리에서 그러한 명명된 엔터티를 감지하고 추출하기 위해 spaCy 라이브러리를 사용했습니다. 라이브러리가 명명된 엔터티 인식(NER)을 위한 다양한 알고리즘을 구현했지만, 우리와 같은 맞춤형 사용 사례에 그대로 사용하는 것은 효과가 없습니다. 예를 들어, 그림 2의 사용자 쿼리에서 spaCy 라이브러리는 부다페스트를 텍스트에서 언급된 위치 엔터티로 감지할 것이지만, 부다페스트의 글로벌 서비스 센터가 UNHCR 조직 내의 엔터티라는 사실을 놓칠 것입니다. 따라서, 우리는 문자열 매칭을 사용하여 조직에 속하는 엔터티를 감지하기 위한 규칙으로 새로운 카테고리를 정의함으로써 우리의 사용 사례에 맞게 라이브러리를 맞춤화했습니다.
요약하자면, 컨텍스트 생성을 위한 전체 워크플로우는 그림 2에 나타나 있습니다. 입력 사용자 쿼리에 대해, 우리는 먼저 벡터 데이터베이스에서 문서 검색을 수행하여 컨텍스트에 포함되어야 할 관련 정보 조각을 식별합니다; 이는 모든 RAG(Retrieval-Augmented Generation) 애플리케이션에 대한 표준 절차입니다. 그러나, 우리는 사용자의 쿼리에 기반한 조직 내 엔티티에 대한 추가적인 정보를 포함함으로써 컨텍스트를 더욱 확장합니다. 이는 먼저 사용자 쿼리에서 엔티티 이름을 파싱하는 것으로 시작됩니다. 만약 감지된 엔티티가 없다면 트리 검색은 건너뛰어지고 컨텍스트에 추가 정보는 포함되지 않습니다. 그러나, 사용자가 언급한 하나 이상의 엔티티가 있다면(예를 들어, 우리 예제의 부다페스트에 있는 글로벌 서비스 센터), 관련 정보는 트리에서 추출되어 텍스트 형태로 변환됩니다. 이 정보는 검색된 문서 조각과 결합되어 컨텍스트로 사용됩니다.
5.4 구현 설정
5.4.1 답변 생성을 위한 LLM 모델
우리 사용 사례에 대한 주요 요구 사항은 온프레미스(on-premise)에 애플리케이션을 배포하는 것이었습니다. 결과적으로, 우리는 경쟁력 있는 성능을 달성하는 오픈 소스 모델인 Llama-2 모델을 사용하기로 결정했습니다 [Touvron et al.(2023)]. Llama-2 모델은 7B에서 70B까지 다양한 파라미터 크기로 제공됩니다. 우리는 우리의 사용 사례에 Llama-2 7B 챗 모드를 사용했습니다. 대규모 LLM 모델을 파인튜닝하고 런타임에 실행하는 데 필요한 계산 자원을 고려할 때, 작은 모델은 제한된 계산 자원을 가진 소규모 및 중소기업이나 GPU 접근이 제한된 지역에서 사용하기에 더 적합합니다 [Nellis and Cherney(2023)].
5.4.2 시스템 구현
우리는 시스템에 대해 여러 설정을 시도했습니다. 이들은 표 에 요약되어 있으며 여기에서 더 자세히 설명됩니다. 첫 번째 구현은 원본 문서의 조각을 컨텍스트로 사용하여 답변을 생성하기 위해 기본 Llama-2 모델을 사용한 RAG였으며, 우리는 문서 조각 개의 컨텍스트 크기를 사용했습니다. 다음 구현은 컨텍스트 정보 없이 파인튜닝된 모델을 사용하는 것이었습니다. Llama-2 모델은 조직의 문서에서 생성된 지침 데이터셋에 대해 파인튜닝되었습니다.
마지막으로, 우리는 관련 컨텍스트를 검색하기 위해 RAG를 사용하고 응답 생성을 위해 파인튜닝된 모델을 사용하는 T-RAG를 구현했습니다. T-RAG는 두 가지 소스에서 컨텍스트 정보를 사용합니다: (i) 원본 문서에서 생성된 지침 데이터셋의 질문과 답변 쌍(우리는 직접적인 질문과 답변만을 유지하고 대화, 빈칸 채우기 등 다른 질문 유형은 필터링했습니다. 우리는 Q\&A 쌍 3개의 컨텍스트 크기를 사용했습니다), 그리고 (ii) 앞서 설명한 대로 엔티티 트리에서 추출된 정보를 제공하는 트리 컨텍스트로, 사용자의 쿼리에서 언급된 엔티티에 대한 정보입니다.
표 2: 다양한 시스템 구현에 대한 개요
| 이름 | 모델 | 컨텍스트 |
|---|---|---|
| RAG | 기본 Llama-2 | 문서 조각 |
| 파인튜닝됨 | 파인튜닝된 Llama-2 | - |
| T-RAG | 파인튜닝된 Llama-2 | Q\&A 조각 + 엔티티 |
우리는 문서 조각들을 저장하기 위해 Chroma DB 벡터 데이터베이스를 사용했습니다. 검색 시 문서 선택을 위해 최대 한계 관련성(Maximum Marginal Relevance, MMR)을 사용했는데, 이 알고리즘은 입력 쿼리와의 유사성과 검색된 문서의 다양성을 최적화하는 조합을 기반으로 문서를 선택합니다. 임베딩 모델로는 다양한 도메인에 대한 임베딩을 생성할 수 있는 'Instructor' 텍스트 임베딩 모델을 사용했습니다 [Su et al.(2023)]. 추론 시에는 반복 패널티가 인 탐욕적 디코딩(온도는 0)을 사용하여 응답을 생성합니다.
결과(Results)
6.1 성능 평가(Performance Evaluation)
LLM의 출력을 평가하는 것은 일반적으로 자동화된 평가나 인간 평가를 사용하여 수행됩니다 [Chang et al.(2023)]. 자동화된 평가는 GPT-4 [Liu et al.(2023)]와 같은 더 크고 강력한 LLM이나 평가 작업에 튜닝된 판사 LLM [Wang et al.(2023)]을 사용에 의존합니다. 연구들은 LLM 평가가 다양한 작업에 대해 인간 평가와 일관성이 있다는 것을 발견했습니다 [Chiang and Lee(2023)]. 자동화된 평가는 더 쉽게 확장할 수 있고 생산 비용이 저렴할 수 있지만, 결국 인간이 사용할 시스템에 대해서는 실제 사용자의 피드백이 중요합니다.[^5]
우리는 시스템의 성능을 확인하기 위해 인간 평가에 의존했습니다. 시스템은 조직의 최종 사용자들과 함께 세 번의 테스트를 거쳤습니다. 이로 인해 우리가 평가에 사용한 세 가지 질문 세트가 생성되었습니다. 첫 번째 세트는 문서에 익숙한 조직의 인간 전문가가 큐레이션했으며 시스템의 초기 테스트에 사용되었습니다. 두 번째와 세 번째 질문 세트는 조직의 다른 최종 사용자들에 의해 추가 테스트 라운드 동안 생성되었습니다.
생성된 응답은 인간 전문가에 의해 평가되었으며, 응답이 질문에 답하고 사실적으로 정확한 경우 (i) 정확(Correct, C)으로, 질문에 답하면서도 질문과 관련 없는 다른 사실적으로 정확한 정보를 제공한 경우 (ii) 정확-장황(Correct-Verbose, CV)으로 표시되었습니다. 결과는 표 3에 보고되었습니다. 세 세트 전체에 걸친 집계 결과는 '질문 세트(Questions Set)' 열의 '모두(All)' 라벨 아래 굵은 글씨로 표시됩니다. 표의 (T) 열은 정확하거나 정확-장황한 응답의 총 수입니다.
총 개의 질문에 대해 RAG와 Finetuned는 비슷한 성능을 보여, 각각 개와 개의 질문에 정확하게 답했습니다. T-RAG는 전반적으로 더 나은 성능을 보여, 총 개의 질문 중 개에 정확하게 답했습니다. 그러나 T-RAG는 더 장황한 답변을 제공하는 경향이 더 컸으며, T-RAG가 제공한 답변 중 개가 '정확-장황'이었으며, 다른 구현에서는 한 질문에 대해서만 그러했습니다.
표 3: 평가 결과: 각 시스템은 사용자 테스트의 여러 라운드에서 생성된 세 가지 질문 세트에서 테스트되었습니다. 세 세트 모두에서 집계된 결과는 'All' 아래에 표시됩니다. 은 각 세트의 질문 수입니다. 답변은 정확(Correct, C)하거나, 질문과 관련 없는 추가적인 정확한 정보를 제공하는 경우 정확-장황(Correct-Verbose, CV)으로 수동으로 점수가 매겨졌습니다. ''는 정확한 응답의 총 수( + CV)이며, 마지막 열에 백분율이 표시됩니다. RAG와 Finetuned는 비슷한 성능을 보였습니다. T-RAG는 전반적으로 더 나은 성능을 달성했지만, 더 장황한 답변에 취약했습니다.
| 이름(Name) | 질문 세트(Question Set) | N | C | CV | T | 백분율(Perc.) |
|---|---|---|---|---|---|---|
| RAG | 세트 1(set ) | |||||
| RAG | 세트 2(set ) | |||||
| RAG | 세트 3(set ) | |||||
| RAG | 전체(All) | |||||
| Finetuned | 세트 1(set ) | |||||
| Finetuned | 세트 2(set ) | |||||
| Finetuned | 세트 3(set ) | |||||
| Finetuned | 전체(All) | |||||
| T-RAG | 세트 1(set ) | |||||
| T-RAG | 세트 2(set ) | |||||
| T-RAG | 세트 3(set ) | |||||
| T-RAG | 전체(All) |
6.2 엔티티 트리 검색 모듈 평가(Evaluating The Entity Tree Search Module)
T-RAG에서 나무 구성 요소가 생성하는 컨텍스트의 성능 이점을 평가하기 위해, 우리는 두 세트의 엔티티 관련 질문들을 만들었습니다. 이 테스트 세트를 (i) 단순(simple)과 (ii) 복잡(complex)이라고 명명합니다. 단순 세트는 조직 내의 엔티티에 대해 직접적으로 묻는 질문들로 구성됩니다. 반면에, 복잡 세트는 어떤 카테고리에 속하는 모든 엔티티나 일부 엔티티의 목록을 요구하는 질문들이나 두 가지 다른 카테고리에 속하는 엔티티에 대해 묻는 복합 질문들을 포함합니다. 예를 들어, UNHCR 조직도를 기반으로 할 때, 단순 질문은 "부고등판무관(Deputy High Commissioner)은 프레임워크에서 어디에 있나요?"가 될 것이고, 복잡한 질문은 "부고등판무관 밑에 있는 몇몇 엔티티와 외부 관계(External Relations) 밑에 있는 몇몇 엔티티의 이름은 무엇인가요?"가 될 것입니다.
우리는 나무 컨텍스트를 포함하고 포함하지 않은 다양한 구현을 테스트했습니다. 표 4에서 볼 수 있듯이, 나무 컨텍스트를 포함하는 것은 단순하고 복잡한 질문 모두에 대한 답변의 정확도를 향상시켰습니다. 나무 컨텍스트를 포함하면 두 질문 세트 모두에서 Finetuned 모델이 생성한 정확한 응답의 수가 대략 두 배로 증가했습니다. 이러한 개선은 여러 가지 이유로 설명될 수 있습니다. 하나의 관찰은 나무 컨텍스트를 포함하면 모델이 존재하지 않는 엔티티나 카테고리를 만들어내는 환각을 줄인다는 것입니다. 또 다른 설명은 컨텍스트가 Finetuned 모델의 기억력을 증가시켜 (예를 들어, 어떤 카테고리에 속하는 엔티티를 나열하는 것과 같은) 더 정확한 응답을 제공할 수 있게 한다는 것입니다. 이는 LLM이 덜 인기 있는 엔티티에 대한 장기 지식을 기억하는 데 어려움을 겪을 수 있기 때문에, 순수하게 그것의 매개변수적 기억에 의존하는 것보다 낫습니다 [Kandpal et al.(2023)].
나무 컨텍스트가 제외될 때 T-RAG와 비슷하지만 약간 더 작은 효과를 보았습니다. 단순 질문에 대한 개선은 나무 없이 T-RAG가 17개 중 16개 질문을 올바르게 답변함으로써 적당했습니다. 나무 없이 T-RAG는 직접적인 질문에 잘 수행했으며, 이는 Q&A 지침 데이터셋에서 컨텍스트 정보에 접근할 수 있었기 때문입니다.
표 4: 엔티티 관련 질문에 대한 나무 컨텍스트의 평가 결과. 우리는 나무 컨텍스트를 포함하고 포함하지 않은 여러 구현을 비교하여, 그것으로 인한 성능 개선을 평가합니다. 열은 올바른 답변의 수를 보여주며, 괄호 안에 백분율이 표시됩니다. 나무 컨텍스트는 RAG와 Finetuned에 비해 성능을 크게 향상시켰습니다.
| 이름 | 단순 (17개 질문) | 복잡 (22개 질문) |
|---|---|---|
| RAG | ||
| Finetuned | ||
| Finetuned + 나무 | ||
| T-RAG 나무 없음 | ||
| T-RAG |
복잡한 질문에서 나무 컨텍스트의 이점은 훨씬 큰 개선을 볼 수 있습니다: 22개의 복잡한 질문 중, 나무 없이 T-RAG는 10개를 올바르게 답변한 반면, 나무 컨텍스트가 포함될 때는 15개를 올바르게 답변했습니다.
6.2.1 UNHCR 조직도에서 엔티티에 대한 평가
UNHCR의 조직 구조를 사용하여 생성된 트리 컨텍스트의 효과도 테스트했습니다. 우리는 UNHCR의 조직 계층 내 다양한 엔티티에 대해 묻는 개의 간단한 질문과 개의 복잡한 질문 세트를 만들었습니다. 우리는 (i) UNHCR의 조직 계층을 설명하는 텍스트에서 문서 조각을 컨텍스트로 사용하는 RAG 시스템과 (ii) 조직의 엔티티 트리에서 생성된 컨텍스트를 사용하는 RAG 시스템의 성능을 비교했습니다. 이전과 마찬가지로, 트리 컨텍스트를 사용했을 때 정확도가 향상되었습니다. 개의 간단한 질문 중 문서 조각을 사용한 RAG는 개(46.2\%)를 정확하게 답했으며, 트리를 사용한 RAG는 개(92.3\%)를 정확하게 답했습니다. 개의 복잡한 질문에 대해 문서 조각을 사용한 RAG는 개 를 정확하게 답했으며, 트리를 사용한 RAG는 개(61.5\%)를 정확하게 답했습니다.
6.2.2 질적 평가(Qualitative Evaluations)
모델이 생성한 답변을 살펴보면, 트리 컨텍스트를 가짐으로써 줄어든 다음과 같은 오류 유형을 관찰할 수 있습니다. 앞서 언급된 오류 원인 중 하나는 주로 컨텍스트 없이 미세 조정된 모델(finetuned model)에서 관찰된 환각(hallucinations)이었습니다. 또 다른 오류 원인은 조직의 엔티티를 언급하면서도 잘못된 카테고리에 나열하는 정렬되지 않은 답변(misaligned answers)이었습니다. 표 는 UNHCR 조직도를 기반으로 이러한 유형의 오류를 보여주는 예시 응답을 보여줍니다. 질문은 부고등판무관(Deputy High Commissioner) 아래의 엔티티에 대해 묻지만, 응답은 잘못되게 고등판무관 집행 사무소(High Commissioner Executive Office)의 엔티티를 나열합니다.
표 5: 정렬 오류: 문서 조각을 사용한 RAG(트리 컨텍스트 없음)이 생성한 UNHCR 엔티티를 기반으로 한 예시 질문과 응답. 굵은 빨간색으로 표시된 엔티티는 실제로 고등판무관 집행 사무소에 속하지만 부고등판무관 아래에 잘못 나열되었습니다.

6.3 미세 조정된 모델의 과적합 테스트(Overfitting Test of Finetuned Model)
LLM을 미세조정(finetuning)함으로써 새로운 작업을 학습하도록 할 수 있지만, 이는 모델이 데이터셋에 과적합(overfitting)되거나 사전 학습(pre-training) 동안 배운 내용을 잊어버릴 위험을 초래합니다. 이를 테스트하기 위해 우리는 미세조정된 모델과 기본 모델의 성능을 Massive Multitask Language Understanding(MMLU) 벤치마크 [Hendrycks et al.(2021)]에서 비교했습니다. MMLU는 언어 이해와 지식에 대한 LLM을 평가하기 위해 사용되며, STEM, 인문학, 사회과학 등 다양한 주제를 포함하는 객관식 질문으로 구성되어 있습니다. 그림 은 기본 모델과 미세조정된 모델의 전체 및 주제별 정확도를 보여줍니다. 미세조정된 모델은 전체적으로 의 정확도를 달성한 반면, 기본 모델은 의 정확도를 달성했습니다. 여기서 미세조정이 과적합으로 이어지지 않은 것으로 보이지만, LLM의 일반적인 언어 능력에 영향을 줄 수 있으므로 미세조정을 할 때는 주의해야 합니다.
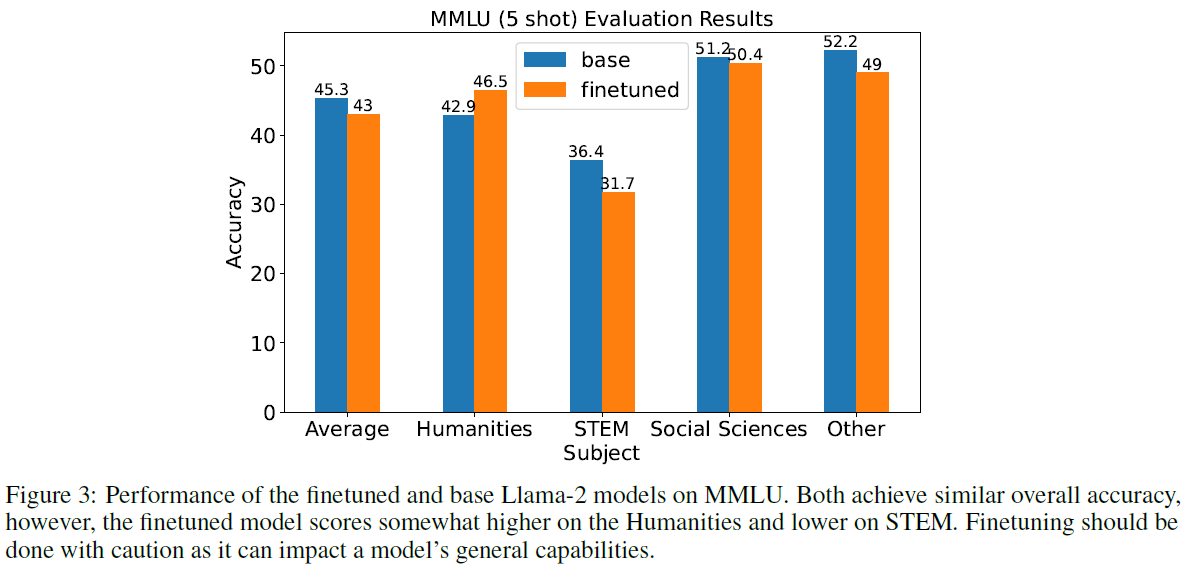
그림 3: MMLU에서 미세조정된 모델과 기본 Llama-2 모델의 성능. 두 모델 모두 비슷한 전체 정확도를 달성하지만, 미세조정된 모델은 인문학에서는 다소 높은 점수를, STEM에서는 낮은 점수를 받았습니다. 미세조정은 모델의 일반적인 능력에 영향을 줄 수 있으므로 주의해서 수행해야 합니다.
배운 교훈
실용적인 애플리케이션을 위한 견고한 LLM 시스템을 구축하는 데는 상당한 고려사항과 맞춤화가 필요합니다. 여기에는 우리의 경험을 바탕으로 공유할 수 있는 몇 가지 교훈이 있습니다:
- 초기 RAG 애플리케이션을 구축하는 것은 쉽지만, 이를 견고하게 만드는 것은 단순하지 않으며, 도메인 지식 전문가의 도움(우리는 미세조정을 위한 지시 데이터셋을 생성하기 위해 사용된 예시 질문을 큐레이션하는 데 도메인 전문가의 도움을 받았습니다)과 시스템의 다양한 구성 요소를 최적화하기 위한 많은 설계 선택이 필요합니다.
- 미세조정된 모델은 질문의 표현에 민감할 수 있습니다. 예를 들어, 미세조정된 모델에게 "모든 것의 포괄적인 목록" 대신 "모든 것의 목록"을 제공하라고 요청했을 때, 전자에 대한 모델의 응답은 만들어진 이름을 포함한 환각을 포함한 반면, 후자의 질문은 정확하게 답변되었습니다. 우리는 질문 표현의 다른 변형에서 이를 관찰했으며, 훈련 데이터셋에서의 표현 차이가 하나의 설명일 수 있다고 가설을 세웠습니다.
- 미세조정된 모델은 모델의 매개변수에 정보를 통합함으로써 LLM의 제한된 컨텍스트 창에 대한 공간을 절약할 수 있으며, 이는 필요한 컨텍스트의 양을 줄일 수 있습니다. 이는 채팅 애플리케이션의 대화 기록과 같은 다른 정보에 더 많은 공간을 남길 수 있습니다. 우리는 이것이 LLM의 컨텍스트 창을 늘리기 위한 지속적인 노력[Zhang et al.(2024)]과 이러한 더 큰 컨텍스트 창에 RAG를 적응시키는 노력[Xu et al.(2024)]에 대한 더 간단한 대안이 될 수 있다고 믿습니다.
- 시스템 개발의 다양한 단계에서 최종 사용자를 테스트에 참여시키면 개발 중 일부 의사 결정을 이끌어내는 데 도움이 될 수 있는 피드백을 생성할 수 있습니다.
- 트리는 조직 내의 엔티티와 같은 계층적 정보를 나타내는 데 적합한 구조를 제공하며, 이를 사용하여 컨텍스트를 향상시킬 수 있습니다. 우리의 평가에 따르면, 이것은 엔티티에 대한 질문에 응답하는 데 상당히 견고하게 만드는 데 도움이 됩니다.
LLM 전쟁터에서 얻은 교훈
7.1 RAG 대 비특화 학습(Finetuning)
우리는 애플리케이션에서 RAG와 비특화 학습을 결합하여 사용했습니다. 두 접근 방식 모두 장단점이 있습니다. 비특화 학습은 모델을 훈련시키기 위해 처음에 더 많은 계산 자원을 요구합니다. 작은 애플리케이션의 경우, RAG의 계산 요구 사항은 사용된 검색 기술을 넘어서 최소화될 가능성이 높습니다. RAG와 비교하여, 비특화 학습은 모델의 글쓰기 스타일과 톤을 조직의 문서와 일치시키는 데 도움이 될 수 있습니다. 그러나 비특화 학습은 모델의 매개변수를 업데이트하면서 전반적인 언어 능력을 저하시킬 수 있으므로 주의해서 수행해야 합니다. 여기서 우리가 한 것처럼 비특화 학습 모델을 과적합(overfitting)에 대해 테스트하는 것은 이를 확인하는 유용한 방법일 수 있습니다. 비특화 학습은 고품질 훈련 데이터셋을 큐레이션하고 하이퍼파라미터(hyper-parameters)를 조정하는 노력이 필요하지만, RAG 역시 많은 최적화가 필요합니다. 표 1에 제시된 RAG 알고리즘을 보면, 소스 문서를 어떻게 분할할지, 임베딩 모델과 검색 알고리즘 선택 등 각 단계에서 탐색할 수 있는 많은 설정이 있습니다.
LLM 애플리케이션을 유지 관리하려면 기본 문서가 시간이 지남에 따라 변경됨에 따라 지식 베이스를 업데이트해야 합니다. RAG의 경우, 검색 데이터베이스를 업데이트함으로써 쉽게 수행될 수 있어, 동적이고 자주 업데이트되는 경우에 더 적합합니다. 그러나 비특화 모델을 업데이트하려면 훈련 데이터셋을 준비하고 모델을 다시 훈련시켜야 하므로, 기본 문서가 덜 자주 변경되는 우리와 같은 애플리케이션에 더 적합합니다.
배포된 애플리케이션은 다양한 유형의 사용자 쿼리를 받습니다. 앞서 관찰했듯이, 비특화 모델은 특히 낯선 입력에 직면했을 때 여전히 환각(hallucinations)에 취약합니다. RAG를 사용하면 모델의 응답을 주어진 맥락에 기반하여 환각을 상당히 줄일 수 있습니다 [Zhang et al.(2023)]. 그러나 RAG도 파이프라인 전반에 걸쳐 많은 제한 사항을 겪고 있으며, 소음이 많거나 불완전한 맥락으로 인해 환각과 불완전한 답변이 발생할 수 있습니다 [Barnett et al.(2024)]. LLM의 환각을 줄이는 것은 여전히 열린 연구 질문이며, 미래의 발전은 시스템이 시간이 지남에 따라 프레임워크가 성숙함에 따라 더욱 견고해질 수 있도록 도울 수 있습니다 [Ye et al.(2023)]. 우리의 경험에서, RAG와 비특화 학습을 결합한 하이브리드 접근 방식은 실제 애플리케이션에 유망할 가능성이 높으며, 더 탐구되어야 합니다.
7.2 향후 작업
우리는 조직으로부터 시스템에 대한 긍정적인 피드백을 받았으며, 현재 시스템을 더 넓은 문서 코퍼스로 확장하는 데 관심이 있습니다. 또 다른 미래의 작업 영역은 시스템을 채팅 기반 애플리케이션으로 확장하는 것입니다. 이는 Q&A 애플리케이션에 필요한 것을 넘어서 채팅 기록을 효과적으로 처리하는 것과 같은 추가 고려 사항이 필요합니다.





