AI 논문 번역
1.논문번역: Black-Box Tuning for Language-Model-as-a-Service
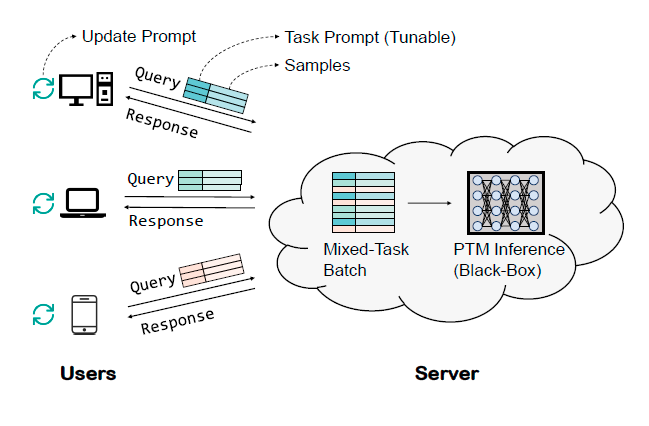
이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
2.논문번역: CPT: COLORFUL PROMPT TUNING FOR PRE-TRAINED VISION-LANGUAGE MODELS
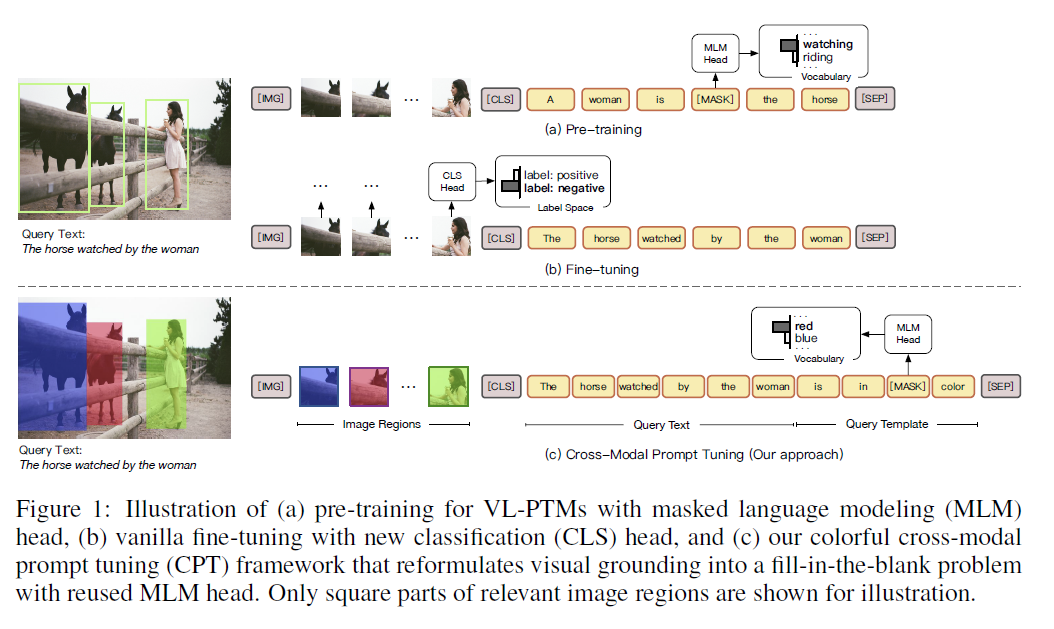
이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
3.논문번역: A Survey of Vision-Language Pre-Trained Models
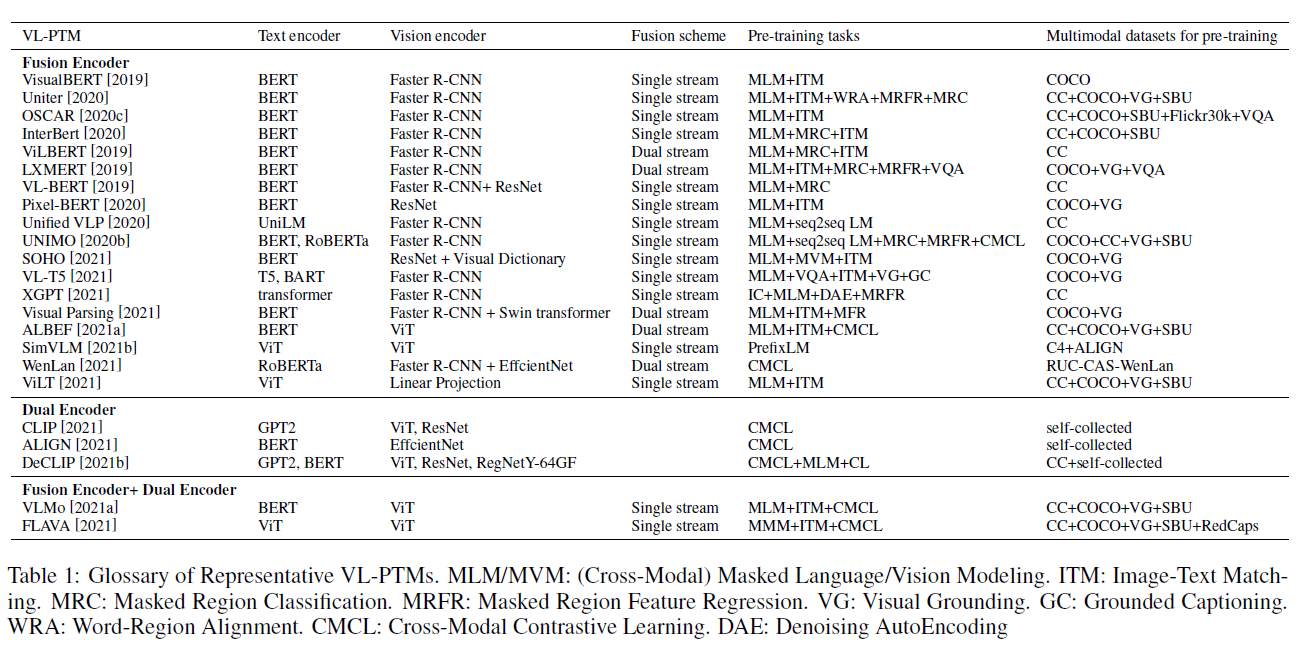
이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
4.논문번역: Diffusion Models: A Comprehensive Survey of Methods and Applications
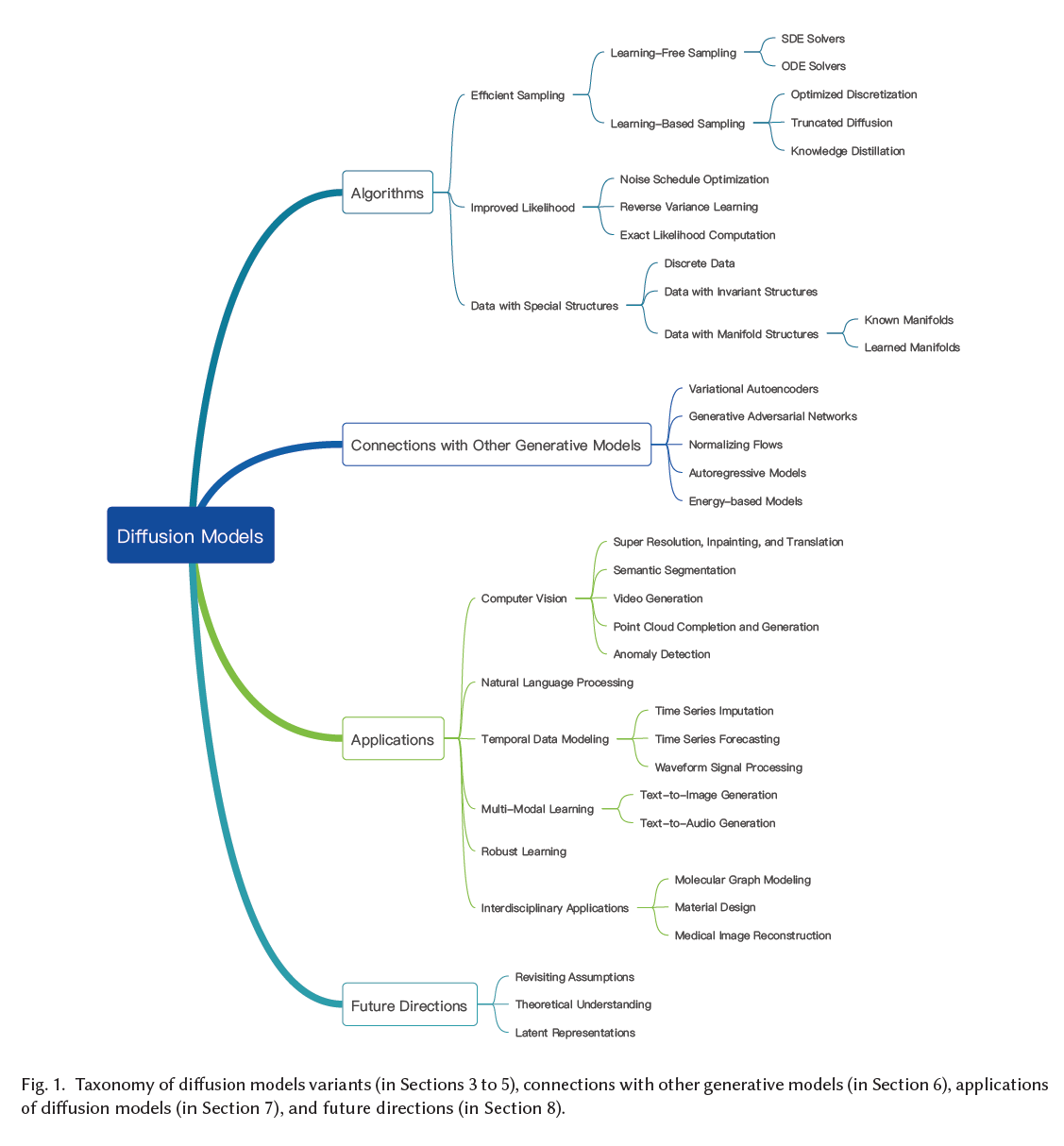
이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
5.논문번역: Language Models are Few-Shot Learners

이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
6.논문번역: High-Resolution Image Synthesis with Latent Diffusion Models

이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 600토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdo
7.논문번역: From Google Gemini to OpenAI Q* (Q-Star): A Survey of Reshaping the Generative Artificial Intelligence (AI) Research Landscape
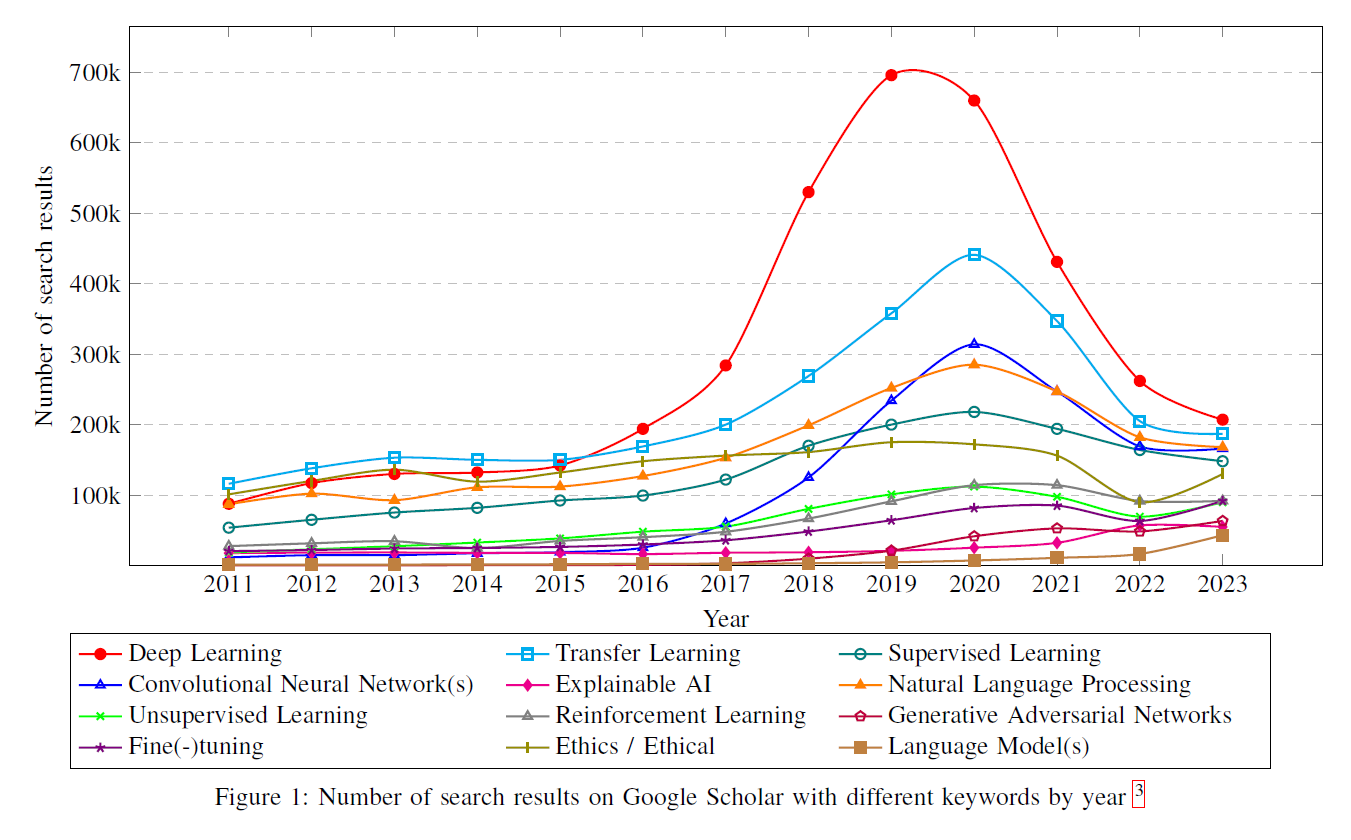
이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
8.논문번역: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity

논문 번역 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-3.5)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-3.5로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr
9.논문번역: CLASSIFIER-FREE DIFFUSION GUIDANCE

이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
10.논문번역: LARGE-SCALE CONTRASTIVE LANGUAGE-AUDIO PRETRAINING WITH FEATURE FUSION AND KEYWORD-TO-CAPTION AUGMENTATION
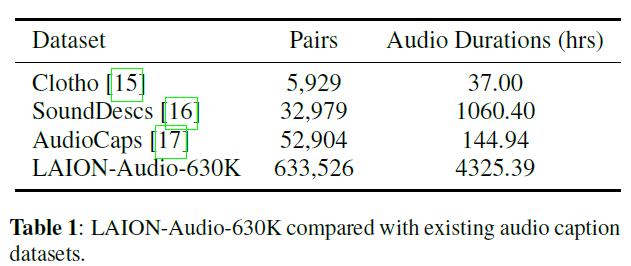
이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
11.논문번역: Multimodal Chain-of-Thought Reasoning in Language Models

논문 번역 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한
12.논문번역: Visual Chain-of-Thought Diffusion Models

이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
13.논문번역: A Generative Model for Text Control in Minecraft (Abridged Version)
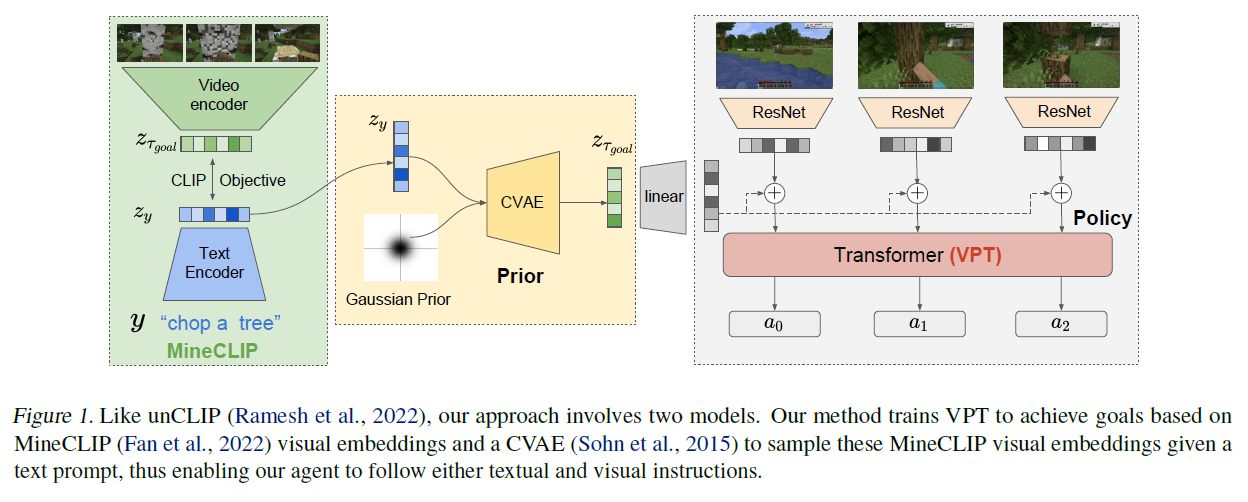
이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
14.논문번역: Pretrained Language Models to Solve Graph Tasks in Natural Language

이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
15.
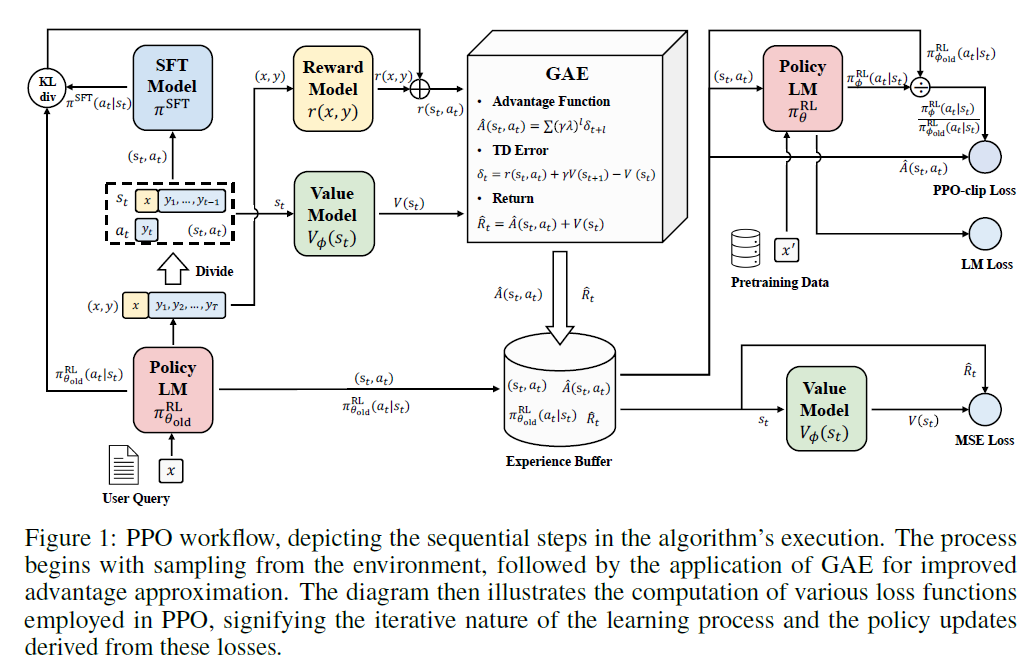
이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd
16.논문번역: T-RAG: LESSONS FROM THE LLM TRENCHES

이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다. 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다. 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markd