논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
Google Gemini에서 OpenAI Q*(Q-스타)까지: 생성 인공지능(AI) 연구 환경 변화에 대한 조사
Timothy R. McIntosh, Teo Susnjak, Tong Liu, Paul Watters, IEEE 선임 회원, 그리고 Malka N. Halgamuge,
IEEE 선임 회원
초록
이 종합적인 조사는 생성 인공지능(AI)의 진화하는 환경을 탐구하였으며, 특히 전문가 혼합(Mixture of Experts, MoE), 다중 모달 학습, 그리고 인공 일반 지능(Artificial General Intelligence, AGI)으로의 추정된 발전이 변형시키는 영향에 초점을 맞추었습니다. 이 연구는 생성 인공지능(AI)의 현재 상태와 미래의 궤적을 비판적으로 검토하며, Google의 Gemini와 기대되는 OpenAI Q* 프로젝트와 같은 혁신이 연구 우선순위와 다양한 분야의 응용 프로그램을 재편성하는 방식, 그리고 생성 AI 연구 분류에 대한 영향 분석을 탐구했습니다. 이 기술들의 계산적 도전, 확장성, 그리고 실제 세계에서의 영향을 평가하면서, 건강 관리, 금융, 교육과 같은 분야에서 중요한 진전을 이끌어낼 잠재력을 강조했습니다. 또한 AI 테마의 논문과 AI가 생성한 사전 인쇄물의 확산으로 인해 대두되는 새로운 학술적 도전을 다루며, 이것들이 동료 평가 과정과 학술적 소통에 미치는 영향을 검토했습니다. 이 연구는 AI 개발에서 윤리적이고 인간 중심적인 방법을 통합하는 것의 중요성을 강조하며, 사회적 규범과 복지와의 일치를 보장하고, MoE, 다중 모달성, 그리고 AGI를 생성 AI에서 균형 있고 신중하게 사용하는 미래 AI 연구 전략을 제시했습니다.
인덱스 용어-AI 윤리, 인공 일반 지능(AGI), 인공지능(AI), Gemini, 생성 AI, 전문가 혼합(MoE), 다중 모달성, Q*(Q-스타), 연구 영향 분석.
I. 서론
인공지능(AI)의 역사적 맥락은 앨런 튜링의 "모방 게임" [1], 초기 계산 이론 [2], [3], 그리고 최초의 신경망과 기계 학습의 개발 [4], [5], [6]에 이르기까지 오늘날의 고급 모델들에 대한 기초를 마련했습니다. 이러한 진화는 심층 학습(deep learning)과 강화 학습(reinforcement learning)의 부상과 같은 중요한 순간들에 의해 강조되었으며, 전문가 혼합(MoE) 모델과 다중 모달 AI 시스템과 같은 현대 AI의 트렌드를 형성하는 데 중요한 역할을 했습니다. 이러한 발전은 AI 기술의 역동적이고 끊임없이 진화하는 특성을 증명합니다. 인공지능의 진화는 대규모 언어 모델(Large Language Models, LLMs)의 등장으로 중요한 전환점을 맞이했습니다. 특히 OpenAI가 개발한 ChatGPT와 최근 구글(Google)의 Gemini [7], [8]이 공개되면서 이 기술은 산업과 학계에 혁명을 일으키는 것은 물론, AI 의식과 인류에 대한 잠재적 위협에 대한 중요한 논의를 다시 불러일으켰습니다 [9], [10], [11]. Anthropic의 Claude와 같은 주목할 만한 경쟁자들을 포함하여 이러한 고급 AI 시스템의 개발은 연구 환경을 재편하고 있습니다. 특히 Gemini는 GPT-3와 구글 자체의 LaMDA와 같은 이전 모델들을 뛰어넘는 여러 발전을 보여주고 있습니다. Gemini가 양방향 대화에서 학습할 수 있는 능력과 멀티턴 대화 중에 관련 부분에 집중할 수 있는 "스파이크 앤 슬랩(spike-and-slab)" 주의 방법은 다중 도메인 대화 응용 프로그램에 더 적합한 모델을 개발하는 데 있어 중요한 도약을 나타냅니다. Gemini가 사용하는 전문가 혼합(mixture-of-experts) 방법을 포함한 LLMs의 이러한 혁신은 다양한 입력을 처리하고 멀티모달 접근법을 촉진할 수 있는 모델로의 이동을 시사합니다. 이러한 배경 속에서, Q-러닝(Q-learning)과 A (A-Star 알고리즘)과 같은 정교한 알고리즘을 LLMs의 힘과 결합한 것으로 알려진 OpenAI 프로젝트인 Q (Q-Star)에 대한 추측이 나타나고 있으며, 이는 역동적인 연구 환경에 더욱 기여하고 있습니다 2 .
A. 인공지능 연구 인기의 변화
LLM(Large Language Models) 분야는 Gemini와 Q*와 같은 혁신을 통해 계속 발전하고 있으며, 다양한 연구 동향을 식별하거나 빠른 진전이 예상되는 분야를 강조하는 것부터 미래 연구 방향을 그리기 위한 많은 연구들이 등장하고 있습니다. 확립된 방법론과 초기 채택의 이분법은 명확하며, LLM 연구의 "핫 토픽"은 Gemini가 보여주듯 멀티모달 능력과 대화 기반 학습으로 점점 이동하고 있습니다. 프리프린트(preprints)의 확산은 지식 공유를 가속화했지만, 학문적 검토가 감소할 위험도 가져옵니다. Retraction Watch가 지적한 내재된 편향과 표절 및 위조에 대한 우려는 상당한 장애물을 제시합니다 [12]. 따라서 학계는 교차로에 서 있으며, 빠르게 진화하는 분야의 연구 방향을 정제하기 위한 통합된 노력[^0]이 필요합니다. 이는 시간이 지남에 따라 변화하는 다양한 연구 키워드의 인기를 통해 부분적으로 추적될 수 있습니다. GPT와 같은 생성 모델의 출시와 ChatGPT의 광범위한 상업적 성공은 영향력이 있었습니다. 그림 1에서 보여지듯, 특정 키워드의 상승과 하락은 "Transformer" 모델의 2017년 출시 [13], 2018년 GPT 모델 [14], 그리고 2022년 12월의 상업적 ChatGPT-3.5와 같은 중요한 산업 이정표와 연관이 있는 것으로 보입니다. 예를 들어, "딥 러닝(Deep Learning)"과 관련된 검색의 급증은 신경망 응용의 돌파구와 일치하며, GPT와 LLaMA와 같은 모델이 언어 이해와 생성에서 가능한 것을 재정의함에 따라 "자연어 처리(Natural Language Processing)"에 대한 관심이 급증합니다. AI 연구에서 "윤리(Ethics / Ethical)"에 대한 지속적인 관심은 일부 변동에도 불구하고 AI의 도덕적 차원에 대한 지속적이고 깊이 있는 우려를 반영하며, 윤리적 고려가 단순한 반응적 조치가 아니라 AI 논의 내에서 통합적이고 지속적인 대화임을 강조합니다 [15].
이러한 추세가 기술 발전이 연구 초점을 이끄는 인과 관계를 나타내는지, 아니면 번성하는 연구 자체가 기술 개발을 촉진하는지를 추측하는 것은 학문적으로 흥미롭습니다. 이 논문은 또한 AI 발전이 사회와 경제에 미치는 깊은 영향을 탐구합니다. 우리는 AI 기술이 다양한 산업을 재편하고, 고용 환경을 변화시키며, 사회 경제 구조에 영향을 미치는 방식을 검토합니다. 이 분석은 현대 세계에서 AI가 제시하는 기회와 도전을 강조하며, 혁신과 경제 성장을 주도하는 역할뿐만 아니라 윤리적 함의와 사회적 혼란 가능성도 고려합니다. 미래의 연구는 더 확실한 통찰력을 제공할 수 있지만, 혁신과 학문적 호기심 사이의 동시적 상호 작용은 AI 진보의 특징으로 남아 있습니다.
한편, 그림 2에서 보여지듯이 컴퓨터 과학 tificial Intelligence (cs.AI) 카테고리 아래에 arXiv에 게시된 프리프린트의 수가 기하급수적으로 증가하는 것은 AI 커뮤니티 내 연구 전파의 패러다임 변화를 나타내는 것으로 보입니다. 연구 결과의 빠른 배포는 신속한 지식 교환을 가능하게 하지만, 정보의 검증에 대한 우려도 제기합니다. 프리프린트의 증가는 이러한 연구들이 동료 평가를 거친 출판물의 엄격한 검토와 잠재적 철회를 겪지 않기 때문에 검증되지 않거나 편향된 정보의 전파로 이어질 수 있습니다 [16], [17]. 이러한 추세는 학계에서 신중한 고려와 비평이 필요함을 강조하며, 특히 검증되지 않은 연구가 인용되고 그 결과가 전파될 가능성을 고려할 때 더욱 그렇습니다.
B. 목표
이 연구의 동기는 Gemini의 공식 공개와 프로젝트에 대한 추측적 논의에서 비롯되었으며, 이는 생성적 AI(Generative AI) 연구의 현재 흐름에 대한 시의적절한 검토를 촉구합니다. 이 논문은 특히 전문가의 혼합(Mixture of Experts, MoE), 다중 모달성(multimodality), 그리고 인공 일반 지능(Artificial General Intelligence, AGI)이 생성적 AI 모델에 미치는 영향에 대한 이해를 높이는 데 기여하며, 이 세 가지 주요 분야 각각에 대한 상세한 분석과 향후 방향을 제시합니다. 이 연구는 아직 공개되지 않은 Q-Star 이니셔티브에 대한 추측을 확대하는 것이 아니라, 기존 연구 주제들이 구식이 되거나 중요성을 잃을 가능성을 비판적으로 평가하고, 동시에 급변하는 대규모 언어 모델(Large Language Models, LLM)의 전망에 대해 탐구하는 것을 목표로 합니다. 이 조사는 암호 중심이나 파일 엔트로피 기반 랜섬웨어 탐지 방법론이 구식이 되었음을 상기시키는데, 이는 랜섬웨어 집단이 다양한 공격 벡터를 활용하는 데이터 도난 전략으로 전환함에 따라 이러한 방법론이 뒤늦게 연구되고 있음을 의미합니다 [18], [19]. AI의 발전은 언어 분석과 지식 합성 능력을 향상시킬 뿐만 아니라 전문가의 혼합(MoE) [20], [21], [22], [23], [24], [25], 다중 모달성 [26], [27], [28], [29], [30], 그리고 인공 일반 지능(AGI) [31], [32], [10], [11]과 같은 분야에서 선구자가 될 것으로 예상되며, 이미 많은 분야에서 전통적인 통계 기반 자연어 처리 기술의 구식화를 예고하고 있습니다 [8]. 그럼에도 불구하고, AI가 인간의 윤리와 가치와 일치해야 한다는 근본적인 원칙은 여전히 중요합니다 [33], [34], [35], 그리고 추측적인 Q-Star 이니셔티브는 이러한 발전이 LLM 연구 지형을 어떻게 재구성할 수 있는지에 대한 논의를 촉발할 전례 없는 기회를 제공합니다. 이러한 맥락에서, NVIDIA의 선임 연구 과학자이자 AI 에이전트 리드인 Dr. Jim Fan이 Q에 대해, 특히 학습과 검색 알고리즘의 결합에 관한 통찰은 이러한 사업의 잠재적 기술 구조와 능력에 대한 귀중한 관점을 제공합니다. 우리의 연구 방법론은 '대규모 언어 모델'과 '생성적 AI'와 같은 핵심 용어를 사용한 체계적인 문헌 검색을 포함했습니다. 우리는 IEEE Xplore, Scopus, ACM Digital Library, ScienceDirect, Web of Science, ProQuest Central과 같은 여러 학술 데이터베이스에 걸쳐 필터를 사용하여 2017년(“Transformer” 모델 출시)부터 2023년(이 논문 작성 시간)까지 발표된 관련 기사를 식별하도록 맞춤화했습니다. 이 논문은 Gemini와 Q의 기술적 함의를 해부하고, 이들(그리고 이제 불가피하게 등장하는 유사 기술들)이 AI 분야의 연구 궤적을 어떻게 변형시키고 새로운 전망을 드러낼 수 있는지 탐구하고자 합니다. 이를 통해, 우리는 생성적 AI 연구 환경을 깊이 있게 재구성할 수 있는 세 가지 신생 연구 분야—MoE, 다중 모달성, AGI—를 지적했습니다. 이 조사는 설문 조사 스타일의 접근 방식을 채택하여, 생성적 AI의 현재 및 출현하는 추세를 종합하고 분석하는 연구 로드맵을 체계적으로 그려냅니다.
이 연구의 주요 기여는 다음과 같습니다:
1) Gemini와 Q*와 같은 기술의 발전과 혁신을 강조하며, AI 분야 내에서의 광범위한 함의를 포함한 생성적 AI의 진화하는 환경에 대한 상세한 검토입니다.[^2]
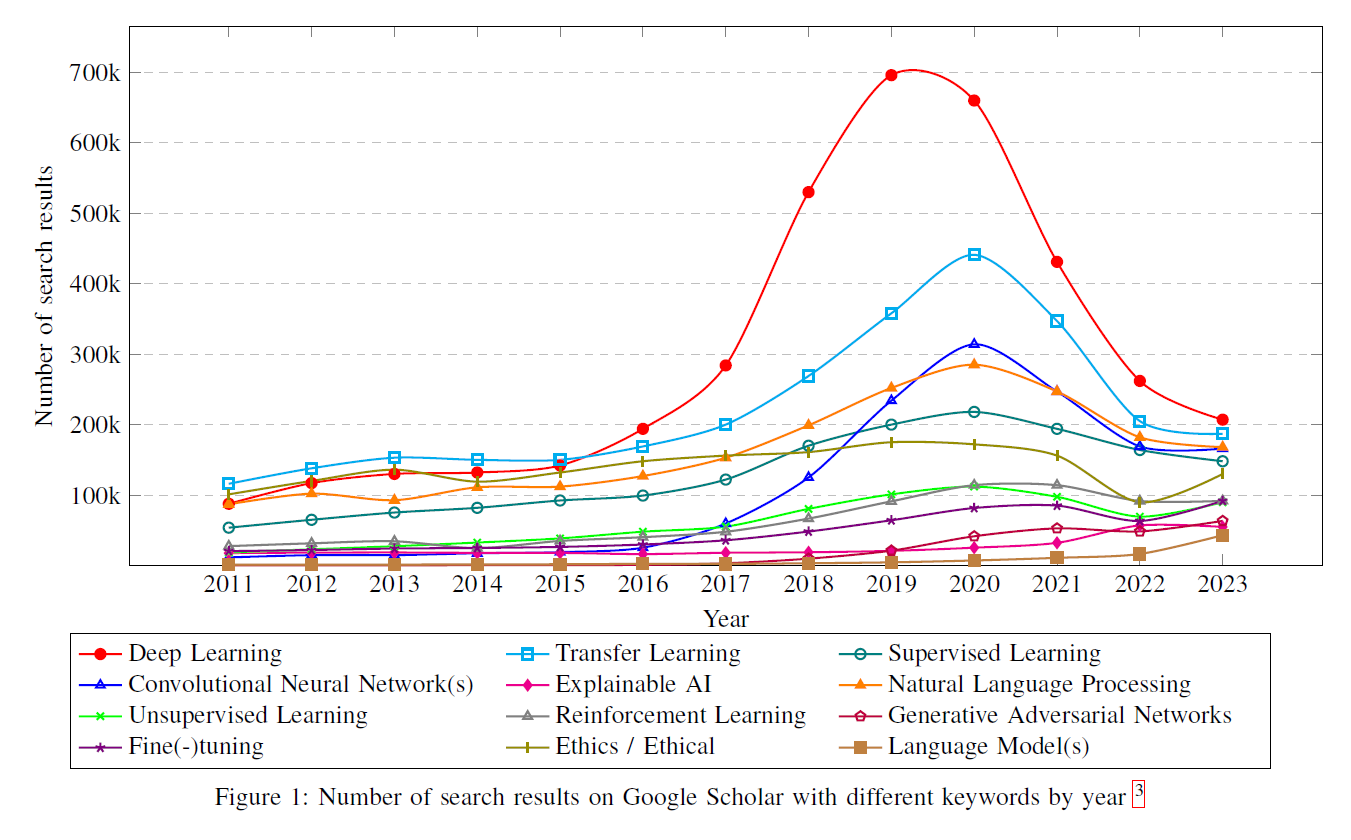
그림 1: 연도별로 다른 키워드로 Google Scholar에서 검색된 결과의 수 3
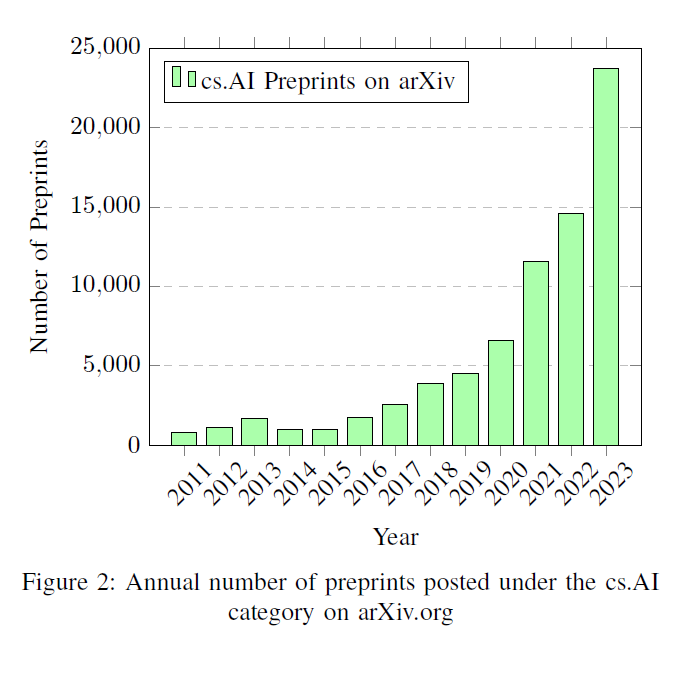
그림 2: arXiv.org의 cs.AI 카테고리에 게시된 연간 프리프린트(preprints) 수
2) 학술 연구에 대한 고급 생성 AI 시스템의 변혁적 영향 분석으로, 이러한 발전이 연구 방법론을 어떻게 변화시키고, 새로운 트렌드를 설정하며, 전통적 접근법을 구식으로 만들 가능성이 있는지 탐구합니다.
3) 학계에서 생성 AI의 통합으로 발생하는 윤리적, 사회적, 기술적 도전 과제에 대한 철저한 평가로, 이러한 기술을 윤리적 규범과 일치시키고, 데이터 프라이버시를 보장하며, 포괄적인 거버넌스 프레임워크를 개발할 필요성을 강조합니다.
이 논문의 나머지 부분은 다음과 같이 구성됩니다: 섹션 III에서는 생성 AI의 역사적 발전을 탐구합니다. 섹션 III에서는 현재 생성 AI 연구의 분류를 제시합니다. 섹션 IV에서는 전문가 혼합(Mixture of Experts, MoE) 모델 아키텍처, 그 혁신적인 특징들, 그리고 변환기 기반 언어 모델에 미치는 영향을 탐구합니다. 섹션 에서는 Q* 프로젝트의 추측된 능력에 대해 논의합니다. 섹션 VI]에서는 AGI의 예상 능력에 대해 논의합니다. 섹션 VII에서는 최근 발전이 생성 AI 연구 분류에 미치는 영향을 검토합니다. 섹션 VIII에서는 생성 AI에서 나타나는 새로운 연구 우선순위를 식별합니다. 섹션 X에서는 AI에서 프리프린트의 급격한 증가로 인한 학술적 도전을 논의합니다. 논문은 섹션 XI]에서 생성 AI의 이러한 발전의 전반적인 영향을 요약하며 마무리됩니다.
II. 배경: 생성 AI의 진화
생성 AI의 상승은 중요한 이정표들로 표시되었으며, 각각의 새로운 모델은 다음 진화적 도약을 위한 길을 닦았습니다. 단일 목적 알고리즘에서 OpenAI의 ChatGPT와 같은 대규모 언어 모델(LLMs)에 이르기까지, 그리고 최신의 다중 모달 시스템까지, AI 분야는 변모되었으며, 무수한 다른 분야들도 혼란에 빠졌습니다.
A. 언어 모델의 진화
언어 모델은 변혁적인 여정을 거쳤으며(그림 3), 기초적인 통계 방법에서부터

그림 3: 언어 모델 진화의 주요 발전 타임라인
오늘날의 대규모 언어 모델(LLMs)을 뒷받침하는 복잡한 신경망 구조는 지속적인 진화를 거듭해왔습니다 [36], [37]. 이러한 발전은 인간 언어의 미묘한 차이를 더 정확하게 반영하는 모델을 찾는 끊임없는 탐구와 기계가 이해하고 생성할 수 있는 범위를 확장하려는 욕구에 의해 주도되었습니다 [36], [38], [37]. 그러나 이 빠른 발전은 도전 없이 이루어진 것은 아닙니다. 언어 모델의 능력이 성장함에 따라, 이들의 사용과 관련된 윤리적이고 안전상의 우려도 커지고 있으며, 이는 이러한 모델들이 어떻게 개발되고 어떤 목적으로 사용되는지에 대한 재평가를 촉구하고 있습니다 [36], [39], [40].
1) 언어 모델의 전조(Language Models as Precursors): 언어 모델링의 시작은 1980년대 후반의 통계적 접근법으로 거슬러 올라갈 수 있으며, 이 시기는 자연어 처리(Natural Language Processing, NLP) [41], [42], [43], [44], [45]에서 규칙 기반(rule-based)에서 기계 학습(machine learning) 알고리즘으로의 전환을 특징으로 합니다. 초기 모델들은 주로 -gram에 기반을 두고 있었으며, 말뭉치(corpus) 내 단어 시퀀스의 확률을 계산함으로써 언어 구조에 대한 기초적인 이해를 제공했습니다 [41]. 이러한 모델들은 단순하지만 혁신적이었으며, 미래의 언어 이해 발전을 위한 기반을 마련했습니다. 계산 능력의 증가와 함께 1980년대 후반에는 NLP 분야에서 '엄격한' 규칙 기반 시스템 대신 '부드러운' 확률적 결정을 내릴 수 있는 통계적 모델로의 혁명이 일어났습니다 [43]. 이 시기 동안 IBM이 복잡한 통계 모델을 개발한 것은 이러한 접근법의 중요성과 성공을 상징했습니다. 그 다음 십년간 통계 모델의 인기와 적용 가능성이 급증하면서, 디지털 텍스트의 풍부한 흐름을 관리하는 데 있어서 무가치한 것으로 입증되었습니다. 1990년대에는 통계적 방법이 NLP 연구에 확고히 자리 잡았으며, n-gram은 언어 패턴을 수치적으로 포착하는 데 중요한 역할을 하게 되었습니다. 1997년 장단기 기억(Long Short-Term Memory, LSTM) 네트워크의 도입 [46]과 10년 후 음성 및 텍스트 처리에의 적용 [47], [48], [49]은 중요한 이정표를 표시했으며, 현재 신경망 모델이 NLP 연구 및 개발의 최첨단을 대표하는 시대로 이어졌습니다.
2) 대규모 언어 모델(Large Language Models): 기술적 진보와 상업적 성공: 딥 러닝(deep learning)의 등장은 NLP 분야를 혁신적으로 변화시켰으며, GPT, BERT, 그리고 특히 OpenAI의 ChatGPT와 같은 대규모 언어 모델(LLMs)의 개발로 이어졌습니다. 최근 모델들인 GPT-4와 LLaMA는 변환기 아키텍처(transformer architectures)와 고급 자연어 이해(advanced natural language understanding)와 같은 정교한 기술을 통합하여 이 분야의 빠른 진화를 보여주고 있습니다 [37]. 이러한 모델들은 언어 이해와 생성에서 새로운 높이를 달성하기 위해 방대한 계산 자원과 광범위한 데이터셋을 활용하는 NLP 능력에서 중요한 도약을 나타냅니다 [37], [50]. ChatGPT는 다양한 분야에서 기술적 및 상업적 성공을 입증하는 인상적인 대화 능력과 문맥 이해를 보여주었으며, 출시 직후 1억 명 이상의 사용자들에 의한 빠른 채택으로 자연어 AI에 대한 강력한 시장 수요를 강조하고, 교육, 의료, 상업 등의 분야에서의 응용에 대한 학제간 연구를 촉진하였습니다 [8], [50], [51], [52], [53]. 교육 분야에서는 ChatGPT가 개인화된 학습과 상호작용적인 교수법에 혁신적인 접근을 제공합니다 [54], [51], [55], [56], 상업 분야에서는 고객 서비스와 콘텐츠 생성을 혁신합니다 [57], [58]. ChatGPT, Google Bard, Anthropic Claude와 같은 상업적 대규모 언어 모델의 널리 퍼진 사용은 AI 분야에서 중요한 논쟁을 다시 불러일으켰으며, 특히 AI 의식과 안전성에 관한 논쟁이 있습니다. 인간과 유사한 상호작용 능력은 중요한 윤리적 질문을 제기하고 AI 개발에서 견고한 거버넌스와 안전 조치의 필요성을 강조합니다 [59], [31], [32], [11]. 이러한 영향은 기술적 성과를 넘어서 우리 세계에서 의 역할과 미래에 대한 문화적 및 사회적 논의를 형성하는 것으로 보입니다.
LLM(Large Language Models)의 발전, 특히 GPT와 BERT와 같은 모델의 개발은 Q*의 개념화를 위한 길을 열었습니다. 이 모델들을 특징짓는 확장 가능한 구조와 방대한 훈련 데이터는 가 제안하는 능력의 기초가 됩니다. 예를 들어, ChatGPT가 문맥 이해와 대화형 AI에서 보여준 성공은 Q*의 설계 원칙에 정보를 제공하며, 더 정교하고 문맥을 인식하며 적응할 수 있는 언어 처리 능력을 향한 궤적을 제시합니다. 마찬가지로, 텍스트, 이미지, 오디오, 비디오를 통합할 수 있는 다중 모달 시스템인 Gemini의 등장은 가 확장할 수 있는 진화적 경로를 반영하며, LLM의 다재다능함과 고급 학습 및 경로 찾기 알고리즘을 결합하여 더욱 종합적인 AI 솔루션을 제공합니다.
3) LLM에서의 파인튜닝, 환각 감소 및 정렬:
LLM(Large Language Models, 대규모 언어 모델)의 발전은 파인튜닝(fine-tuning) [60], [61], [62], [63], 환각 감소(hallucination reduction) [64], [65], [66], [67], 그리고 정렬(alignment) [68], [69], [70], [71], [72]의 중요성을 강조하였습니다. 이러한 측면들은 LLM의 기능성과 신뢰성을 향상시키는 데 있어 중요합니다. 특정 작업에 사전 훈련된 모델을 적용하는 파인튜닝은 상당한 진전을 보았습니다: 프롬프트 기반(prompt-based) 및 소수샷 학습(few-shot learning) [73], [74], [75], [76]과 전문 데이터셋에서의 감독된 파인튜닝(supervised fine-tuning) [60], [77], [78], [79]과 같은 기술들이 다양한 맥락에서 LLM의 적응성을 향상시켰지만, 편향 완화(bias mitigation)와 다양한 작업에 걸친 모델의 일반화(generalization)에 있어 여전히 도전이 남아있습니다 [60], [80], [72]. 환각 감소는 LLM에서 지속적인 도전 과제로, 확신에 차지만 사실적으로는 틀린 정보를 생성하는 것이 특징입니다 [36]. 파인튜닝 중 신뢰도 패널티 정규화(confidence penalty regularization)와 같은 전략이 과신(overconfidence)을 완화하고 정확도를 향상시키기 위해 도입되었습니다 [81], [82], [83]. 이러한 노력에도 불구하고, 인간 언어의 복잡성과 주제의 폭넓음은 특히 문화적으로 민감한 맥락에서 환각을 완전히 없애는 것을 어렵게 만듭니다 [36], [9]. 정렬은 LLM의 출력이 인간의 가치와 윤리와 일치하도록 하는 것으로, 지속적인 연구 분야입니다. 제약 최적화(constrained optimization) [84], [85], [86], [87], [88]부터 다양한 유형의 보상 모델링(reward modeling) [89], [90], [91], [92]에 이르기까지, 혁신적인 접근법들은 인간의 선호를 AI 시스템 내에 내재화하려고 합니다. 파인튜닝, 환각 감소, 정렬에서의 진보는 LLM을 앞으로 나아가게 했지만, 이러한 영역들은 여전히 상당한 도전을 제시합니다. 인간 윤리의 다양한 스펙트럼과 일치시키는 AI의 복잡성과 문화적으로 민감한 주제에 대한 환각의 지속성은 LLM의 개발과 적용에서 계속되는 학제간 연구의 필요성을 강조합니다 [9].
4) 전문가의 혼합: 패러다임의 전환:
LLM에서 MoE(Mixture of Experts, 전문가의 혼합) 아키텍처의 채택은 AI 기술에서 중요한 진화를 표시합니다. 구글의 Switch Transformer와 MistralAI의 Mixtral-8x786과 같은 고급 모델들에 의해 예시된 이 혁신적인 접근법은 다수의 트랜스포머 기반 전문가 모듈들을 활용하여 동적 토큰 라우팅(dynamic token routing)을 강화하고, 모델링 효율성과 확장성을 향상시킵니다. MoE의 주요 장점은 방대한 매개변수 규모를 처리할 수 있는 능력에 있으며, 이는 메모리 사용량과 계산 비용을 상당히 줄입니다 [93], [94], [95], [96], [97]. 이는 전문가들 간의 모델 병렬 처리를 통해 수조 개의 매개변수를 가진 모델을 훈련할 수 있게 하며, 다양한 데이터 분포를 처리하는 전문화를 통해 소수샷 학습과 기타 복잡한 작업에서의 능력을 향상시킵니다 [94], [95]. 의 실용성을 예로 들면, 의료 분야에서의 그 적용을 고려해 볼 수 있습니다. 예를 들어, MoE 기반 시스템은 개인 맞춤 의학(personalized medicine)에 사용될 수 있으며, 여기서 다양한 '전문가' 모듈들은 환자 데이터 분석의 여러 측면, 즉 유전체학, 의료 영상, 전자 건강 기록 등을 전문으로 합니다. 이 접근법은 진단의 정확성과 치료의 개인화를 크게 향상시킬 수 있습니다. 마찬가지로, 금융 분야에서는 MoE 모델이 위험 평가에 배치될 수 있으며, 여기서 전문가들은 서로 다른 재무 지표, 시장 동향, 규제 준수 요소들을 분석합니다.
MoE의 이점에도 불구하고, 동적 라우팅 복잡성(dynamic routing complexity) [98], [99], [100], [101], [102], 전문가 불균형(expert imbalance) [103], [104], [105], [106], 확률 희석(probability dilution) [107]과 같은 도전에 직면하고 있으며, 이러한 기술적 장애물은 MoE의 잠재력을 완전히 활용하기 위한 정교한 해결책을 요구합니다. 또한, MoE가 성능 향상을 제공할 수는 있지만, AI의 윤리적 정렬 문제(ethical alignment issues)를 본질적으로 해결하지는 않습니다 [108], [109], [110]. MoE 모델의 복잡성과 전문성은 의사 결정 과정을 불투명하게 만들어, 윤리적 준수와 인간 가치와의 정렬을 보장하기 위한 노력을 복잡하게 합니다 [108], [111].[^3]
MoE로의 패러다임 전환은 LLM 개발에서 큰 도약을 의미하며, 상당한 확장성과 전문성의 이점을 제공하지만, 이러한 모델의 안전성, 윤리적 정렬, 그리고 투명성을 보장하는 것은 여전히 중요한 관심사입니다. 기술적으로 진보된 MoE 아키텍처는 AI를 더 넓은 사회적 가치와 윤리적 기준과 정렬하기 위해 계속되는 학제간 연구와 거버넌스를 요구합니다.
B. 멀티모달 AI와 상호작용의 미래
멀티모달 AI의 등장은 AI 개발에서 변혁적인 시대를 표시하며, 기계가 다양한 인간 감각 입력과 문맥 데이터를 해석하고 상호작용하는 방식을 혁신합니다.
1) Gemini: 멀티모달 벤치마크 재정의: Gemini, 선구적인 멀티모달 대화 시스템은 GPT-3과 같은 전통적인 텍스트 기반 LLM들과 심지어 멀티모달 대응물인 ChatGPT-4를 뛰어넘음으로써 AI 기술에서 중요한 변화를 표시합니다. Gemini의 아키텍처는 텍스트, 이미지, 오디오, 비디오와 같은 다양한 데이터 유형의 처리를 통합하도록 설계되었으며, 이는 독특한 멀티모달 인코더(multimodal encoder), 크로스-모달 주의 네트워크(cross-modal attention network), 멀티모달 디코더(multimodal decoder)에 의해 가능해졌습니다 [112]. Gemini의 핵심 아키텍처는 시각적 데이터와 텍스트 데이터를 위한 별도의 인코더를 가진 이중 인코더 구조(dual-encoder structure)로, 정교한 멀티모달 맥락화를 가능하게 합니다 [112]. 이 아키텍처는 단일 인코더 시스템의 능력을 뛰어넘는 것으로 여겨지며, Gemini가 텍스트 개념을 이미지 영역과 연결하고 장면의 구성적 이해를 달성할 수 있게 합니다 [112]. 또한, Gemini는 구조화된 지식을 통합하고 크로스-모달 지능을 위한 전문화된 훈련 패러다임을 사용하여 AI에서 새로운 벤치마크를 설정합니다 [112]. [112]에서 Google은 Gemini가 ChatGPT-4와 비교하여 몇 가지 주요 특징을 통해 차별화된다고 주장하고 입증했습니다:
- 모달리티의 폭(Breadth of Modalities): ChatGPT-4가 주로 텍스트, 문서, 이미지, 코드에 중점을 두는 반면, Gemini는 오디오와 비디오를 포함한 더 넓은 범위의 모달리티를 처리합니다. 이 광범위한 범위는 Gemini가 복잡한 작업을 처리하고 실제 세계의 맥락을 더 효과적으로 이해할 수 있게 합니다.
- 성능(Performance): Gemini Ultra는 과학, 법률, 의학과 같은 다양한 도메인을 포괄하는 대규모 다중 작업 언어 이해(MMLU)와 같은 주요 멀티모달리티 벤치마크에서 뛰어난 성능을 발휘하여 ChatGPT-4를 능가합니다.
- 확장성과 접근성(Scalability and Accessibility): Gemini는 데이터 센터부터 기기 내 작업에 이르기까지 다양한 응용 프로그램을 위해 맞춤화된 세 가지 버전 - Ultra, Pro, Nano -을 제공하여, ChatGPT-4에서는 아직 보지 못한 유연성 수준을 제공합니다.
- 코드 생성(Code Generation): Gemini는 다양한 프로그래밍 언어에서 코드를 이해하고 생성하는 능력이 더욱 발전되어 있어, ChatGPT-4의 기능을 넘어서는 실용적인 응용 분야를 제공합니다.
- 투명성과 설명 가능성(Transparency and Explainability): 설명 가능성에 초점을 맞춘 Gemini는 그것의 출력에 대한 정당화를 제공함으로써, 사용자의 신뢰와 AI의 추론 과정에 대한 이해를 향상시킵니다.
이러한 발전에도 불구하고, 상식 지식(commonsense knowledge)을 여러 모달리티(modalities)에 걸쳐 통합해야 하는 복잡한 추론 과제에서 Gemini의 실제 세계 성능은 철저히 평가되어야 합니다.
2) 다중모달 시스템의 기술적 도전: 다중모달 인공지능(AI) 시스템의 개발은 견고하고 다양한 데이터셋을 만드는 것, 확장성을 관리하는 것, 사용자 신뢰와 시스템 해석 가능성을 향상시키는 것 등 여러 기술적 장벽에 직면해 있습니다 [113, [114], 115]. 데이터 획득과 주석(annotation) 문제로 인해 데이터 편향과 오류가 만연해 있으며, 이를 해결하기 위해서는 데이터 증강(data augmentation), 액티브 러닝(active learning), 전이 학습(transfer learning)과 같은 전략을 사용하여 효과적인 데이터셋 관리가 필요합니다 [113], [116], [80], [115]. 동시에 다양한 데이터 스트림을 처리하는 것에 대한 계산 요구 사항은 강력한 하드웨어와 다중 인코더를 위한 최적화된 모델 아키텍처를 필요로 하는 중요한 도전입니다 [117], [118]. 서로 다른 입력 매체에 대한 주의를 균형 있게 조절하고, 특히 모순되는 정보를 제공할 때 모달리티 간의 충돌을 해결하기 위해서는 고급 알고리즘과 다중모달 주의 메커니즘이 필요합니다 [119], [120], [118]. 광범위한 계산 자원이 필요한 확장성 문제는 고성능 하드웨어의 제한된 가용성으로 인해 더욱 악화됩니다 [121], [122]. 구성적 장면 이해(compositional scene understanding)와 데이터 통합을 위한 보정된 다중모달 인코더의 필요성도 절실합니다 [120]. 이러한 시스템의 평가 메트릭을 정제하는 것은 실제 작업에서의 성능을 정확하게 평가하기 위해 필요하며, 포괄적인 데이터셋과 통합된 벤치마크를 요구하고, 다중모달 맥락에서 설명 가능한 AI(explainable AI)를 통해 사용자 신뢰와 시스템 해석 가능성을 향상시키는 것을 요구합니다. 이러한 도전을 해결하는 것은 다중모달 AI 시스템의 발전에 필수적이며, 인간의 기대에 부합하는 원활하고 지능적인 상호작용을 가능하게 합니다.
3) 윤리적 및 사회적 맥락에서의 다중모달 AI: 텍스트 기반 AI가 직면하는 것을 넘어서는 복잡한 윤리적 및 사회적 도전이 다중모달 AI 시스템의 확장으로 도입됩니다. 상업 분야에서 다중모달 AI는 시각적, 텍스트, 청각적 데이터를 통합하여 고객 참여를 변화시킬 수 있습니다 [123], [124], [125]. 자율주행 차량의 경우, 다양한 센서에서 데이터를 종합함으로써 안전과 내비게이션을 향상시킬 수 있으며, 여기에는 시각적, 레이더, 라이다(Light Detection and Ranging, LIDAR) 데이터가 포함됩니다 [126], [125], [127]. 그러나 DeepFake 기술이 현실적인 비디오, 오디오, 이미지를 설득력 있게 생성하는 능력은 다중모달에서 중요한 우려 사항으로, 대중 의견, 정치적 환경, 개인의 명성에 상당한 영향을 미치는 잘못된 정보와 조작의 위험을 초래하며, 디지털 미디어의 진정성을 손상시키고, 사회 공학 및 디지털 포렌식에서 AI 생성 콘텐츠와 진짜 콘텐츠를 구별하는 것이 점점 더 어려워지는 문제를 제기합니다 [128], [129]. 다양한 데이터 소스를 처리하고 상관시킬 수 있는 능력으로 인해 다중모달 AI에서는 프라이버시 문제가 확대되며, 이는 침입적인 감시와 프로파일링으로 이어질 수 있고, 특히 개인 미디어가 AI 훈련이나 콘텐츠 생성을 위해 허락 없이 사용될 때 개인의 동의와 권리에 대한 질문을 제기합니다 [113], [130], [131]. 또한, 다중모달 AI는 다양한 모달리티를 통해 편견과 고정관념을 전파하고 확대할 수 있으며, 이를 방치하면 차별과 사회적 불평등을 지속시킬 수 있어 알고리즘 편향을 효과적으로 해결하는 것이 필수적입니다 [132], [133], [134]. 다중모달 AI 시스템의 윤리적 개발은 투명성, 동의, 데이터 처리 프로토콜, 대중 인식에 중점을 둔 견고한 거버넌스 프레임워크를 요구하며, 데이터 사용에 대한 기준을 설정하고 개인 정보의 비동의적인 착취에 대한 보호를 포함하여 이 기술들이 제기하는 독특한 도전에 대응하기 위해 윤리 지침이 발전해야 합니다 [135], [136]. 또한, 사회가 다중모달 AI 기술을 이해하고 책임감 있게 상호작용하는 데 도움이 될 AI 리터러시 프로그램의 개발이 중요할 것입니다 [113], [135]. 이 분야가 발전함에 따라, 이러한 시스템이 사회적 가치와 윤리적 원칙에 부합하는 방식으로 개발되고 배치되도록 보장하기 위해 학제 간 협력이 중요할 것입니다 [113].
C. 추측적 진보와 연대기적 추세
AI 분야의 역동적인 풍경에서, 프로젝트의 추측적 능력은 LLMs(대규모 언어 모델), Q-러닝(Q-learning), 그리고 (AStar 알고리즘)을 혼합하여 중요한 도약을 몸소 보여줍니다. 이 섹션에서는 게임 중심의 AI 시스템에서부터 Q*가 예상하는 광범위한 응용 분야까지의 진화적 궤적을 탐구합니다.
1) AlphaGo의 Groundtruth에서 Q-Star의 탐색까지: 게임 중심의 인공지능인 AlphaGo에서 개념적인 Q-Star 프로젝트로의 여정은 AI에서 중요한 패러다임 변화를 나타냅니다. 바둑 게임에서의 AlphaGo의 숙련도는 잘 정의된 규칙 기반 환경 내에서 딥 러닝(deep learning)과 트리 검색(tree search) 알고리즘의 효과성을 강조하며, 복잡한 전략과 의사결정에서 AI의 잠재력을 부각시켰습니다 [137], [138]. 그러나 Q-Star는 이러한 한계를 넘어서려는 것으로 추측되며, AlphaGo에서 볼 수 있는 강화 학습(reinforcement learning)의 강점과 지식, 자연어 생성(NLG), 창의성, LLMs의 다재다능함, 그리고 와 같은 경로 탐색 알고리즘의 전략적 효율성을 융합하려고 합니다. 이러한 혼합은 경로 탐색 알고리즘과 LLMs을 결합하여, AI 시스템이 보드 게임의 한계를 넘어서고, Q-Star의 자연어 처리 능력을 통해 인간 언어와 상호작용하며, 미묘한 상호작용을 가능하게 하고, 구조화된 작업과 복잡한 인간 같은 커뮤니케이션 및 추론에서 능숙한 AI로의 도약을 표시할 수 있습니다. 또한, Q-러닝(Q-learning)과 A* 알고리즘의 통합은 Q-Star가 결정 경로를 최적화하고 상호작용에서 학습하여 시간이 지남에 따라 더 적응하고 지능적으로 만들 수 있습니다. 이러한 기술들의 결합은 문제 해결에서만 더 효율적인 AI를 초래할 수 있을 뿐만 아니라, 그 접근 방식에서 창의적이고 통찰력 있는 AI로 이어질 수 있습니다. AlphaGo의 게임 중심의 힘에서 Q-Star의 포괄적인 잠재력으로의 이러한 추측적 진보는 AI 연구의 역동적이고 끊임없이 진화하는 성격을 보여주며, 인간 생활과 더 통합되고 더 넓은 범위의 작업을 더 큰 자율성과 정교함으로 처리할 수 있는 AI 응용 프로그램의 가능성을 열어줍니다.
2) 구조화된 학습과 창의성의 연결: Q-러닝(Q-learning)과 A 알고리즘을 LLMs의 창의성과 결합하는 기대되는 Q 프로젝트는 AI에서 혁신적인 단계를 나타내며, 최근의 혁신들, 예를 들어 Gemini를 능가할 수 있는 잠재력을 가지고 있습니다. 에서 제안된 융합은 구조화된, 목표 지향적 학습과 생성적, 창의적 능력의 통합을 가리키며, 이는 Gemini의 기존 성과를 초월할 수 있는 조합일 수 있습니다. Gemini는 텍스트, 이미지, 오디오, 비디오와 같은 다양한 형태의 데이터 입력을 결합한 다중 모달 AI에서 중요한 도약을 나타내지만, 는 창의적 추론과 구조화된 문제 해결의 더 깊은 통합을 가져올 것으로 추측됩니다. 이는 와 같은 알고리즘의 정밀성과 효율성을 Q-러닝의 학습 적응성과 LLMs가 제공하는 인간 언어와 맥락에 대한 복잡한 이해와 결합함으로써 달성될 것입니다. 이러한 통합은 AI 시스템이 복잡한 다중 모달 데이터를 처리하고 분석하는 것뿐만 아니라, 구조화된 작업을 자율적으로 탐색하면서 창의적인 문제 해결과 지식 생성에 참여할 수 있게 할 것이며, 이는 인간 인지의 다면적인 특성을 반영합니다. 이 잠재적인 진보의 함의는 광범위하며, 현재의 다중 모달 시스템인 Gemini의 능력을 넘어서는 응용 프로그램을 제안합니다. 전통적인 AI 알고리즘의 결정론적인 측면과 LLMs의 창의적이고 생성적인 잠재력을 조화시킴으로써, Q는 AI 개발에 대한 더 전체적인 접근 방식을 제공할 수 있습니다. 이는 AI의 논리적, 규칙 기반 처리와 인간 지능의 창의적, 추상적 사고 사이의 격차를 메울 수 있습니다. 구조화된 학습 기법과 창의적 문제 해결을 하나의 고급 프레임워크로 통합하는 $\mathrm{Q}^{}$의 예상되는 공개는 Gemini와 같은 시스템의 다중 모달 기능을 단순히 확장하는 것뿐만 아니라, 현저하게 능가하는 약속을 가지고 있으며, 이는 생성적 AI 분야에서 또 다른 게임 체인징 시대를 예고하며, AI의 진화 과정에서 간절히 기다려지는 중요한 개발로서의 잠재력을 보여줍니다.
III. 현재 생성적 AI 연구 분류(TAXONOMY)
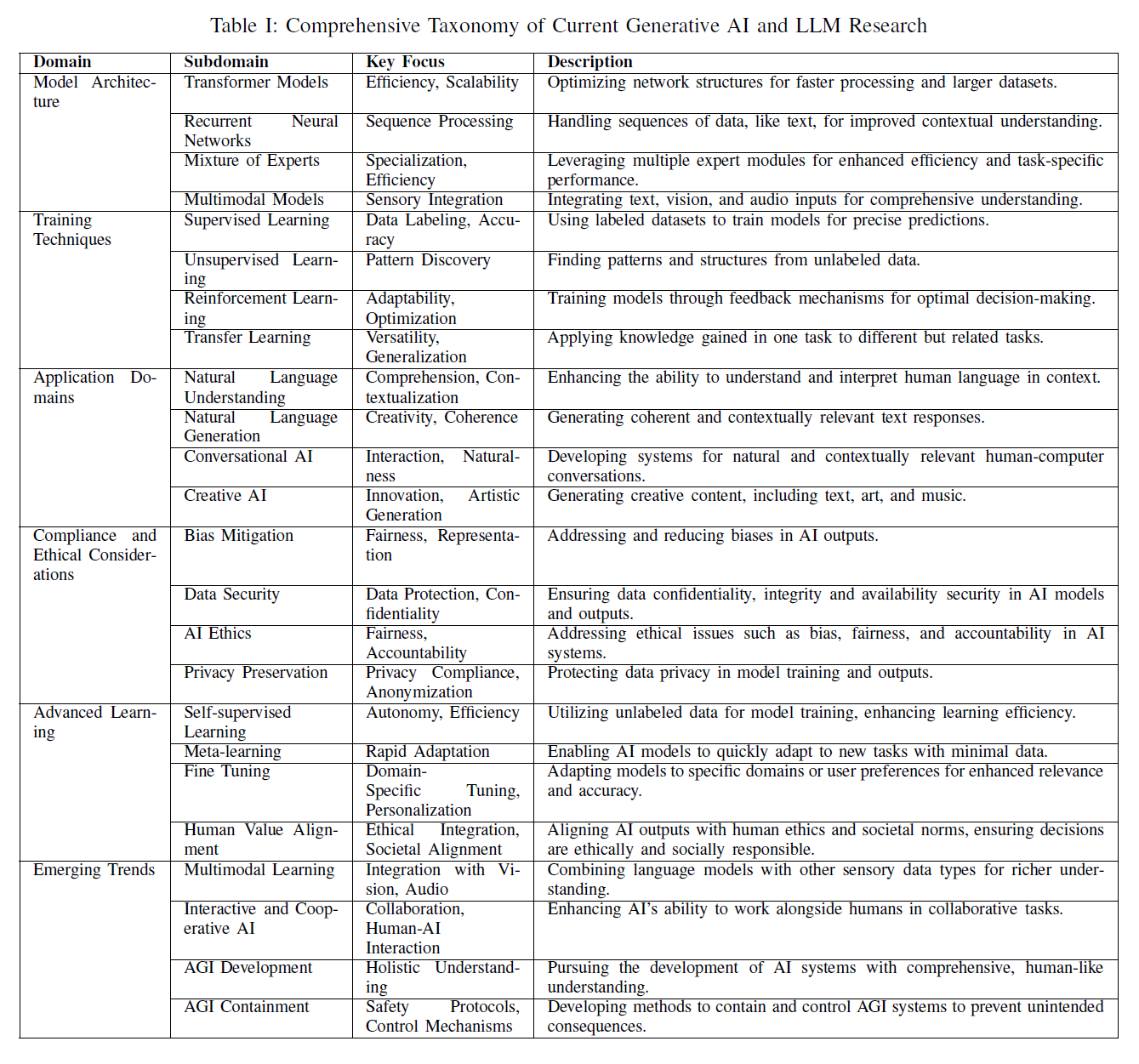
생성적 AI(Generative AI) 분야는 빠르게 발전하고 있으며, 이 영역 내의 연구 범위와 깊이를 포괄하는 종합적인 분류가 필요합니다. 표 【에 자세히 설명된 이 분류는 생성적 AI의 주요 연구 및 혁신 영역을 분류하며, 현재 분야의 상태를 이해하는 기초적인 틀을 제공하고, 진화하는 모델 구조, 고급 훈련 방법론, 다양한 응용 분야, 윤리적 함의, 신흥 기술의 최전선을 안내하는 데 도움을 줍니다.
A. 모델 구조(Model Architectures)
생성적 AI 모델 구조는 상당한 발전을 이루었으며, 특히 네 가지 주요 영역이 두드러집니다:
- 트랜스포머 모델(Transformer Models): 트랜스포머 모델은 특히 자연어 처리(NLP) 분야에서 AI 분야를 혁신적으로 변화시켰으며, 그들의 높은 효율성과 확장성 때문입니다 [139], [140], [141]. 이들은 고급 주의 메커니즘(attention mechanisms)을 사용하여 향상된 문맥 처리를 달성하며, 더 미묘한 이해와 상호작용을 가능하게 합니다 [142], [143], [144]. 이 모델들은 컴퓨터 비전 분야에서도 주목할 만한 진전을 이루었으며, EfficientViT [145], [146] 및 YOLOv8 [147], [148], [149]과 같은 비전 트랜스포머의 개발로 입증되었습니다. 이러한 혁신은 객체 탐지(object detection)와 같은 분야에서 트랜스포머 모델의 확장된 능력을 상징하며, 향상된 성능뿐만 아니라 증가된 계산 효율성을 제공합니다.
- 순환 신경망(Recurrent Neural Networks, RNNs): RNN은 시퀀스 모델링 분야에서 뛰어난 성능을 발휘하여, 언어와 시간 데이터를 다루는 작업에 특히 효과적입니다. 그들의 구조는 데이터 시퀀스, 예를 들어 텍스트를 처리하도록 특별히 설계되어 있어, 입력의 문맥과 순서를 효과적으로 포착할 수 있습니다 [150], [151], [152], [153], [154]. 이러한 순차적 정보 처리 능력은 자연어 작업과 시계열 분석과 같은 데이터 내의 시간적 역학을 깊이 이해해야 하는 응용 분야에서 필수적입니다 [155], [156]. 시퀀스에 대한 연속성을 유지하는 RNN의 능력은 특히 문맥과 역사적 데이터가 중요한 역할을 하는 시나리오에서 AI 분야의 중요한 자산입니다 [157].
- 전문가 혼합(Mixture of Experts, MoE): MoE 모델은 여러 전문가 모듈에 걸쳐 모델 병렬 처리를 배치함으로써 효율성을 크게 향상시킬 수 있으며, 이를 통해 트랜스포머 기반 모듈을 동적 토큰 라우팅에 활용하고, 조 단위의 매개변수로 확장하여 메모리 사용량과 계산 비용을 줄일 수 있습니다 [94], [98]. MoE 모델은 다양한 전문가들 사이에 계산 부하를 나누는 능력으로 두각을 나타내며, 각 전문가는 데이터의 다른 측면을 전문으로 하여, 매개변수의 거대한 규모를 더 효과적으로 처리할 수 있게 하여 복잡한 작업을 더 효율적이고 전문적으로 처리할 수 있습니다 [94], [21].
- 다중 모달 모델(Multimodal Models): 텍스트, 비전, 오디오와 같은 다양한 감각 입력을 통합하는 다중 모달 모델은 특히 의료 영상과 같은 분야에서 복잡한 데이터 세트를 포괄적으로 이해하는 데 중요합니다 [113], [112], [115]. 이 모델들은 멀티뷰 파이프라인과 크로스어텐션 블록(crossattention blocks)을 사용하여 정확하고 데이터 효율적인 분석을 가능하게 합니다 [158], [159]. 다양한 감각 입력의 통합은 데이터의 더 미묘하고 상세한 해석을 가능하게 하여, 모델이 다양한 유형의 정보를 정확하게 분석하고 이해하는 능력을 향상시킵니다 [160]. 동시에 처리되는 다양한 데이터 유형의 결합은 이 모델들이 복잡한 시나리오를 깊고 다면적으로 이해해야 하는 응용 분야에서 특히 효과적으로 전체적인 관점을 제공할 수 있게 합니다 [113], [161], [162], [160].
B. 훈련 기법
생성적 AI 모델의 훈련은 각각이 독특하게 기여하는 네 가지 주요 기법을 활용합니다:
- 지도 학습(Supervised Learning): AI의 기본적인 접근법인 지도 학습은 레이블이 붙은 데이터셋을 사용하여 모델이 정확한 예측을 할 수 있도록 안내하며, 이미지 인식과 자연어 처리(NLP)를 포함한 다양한 응용 분야에 필수적입니다 [163], [164], [165]. 최근의 발전은 지도 학습 모델의 성능과 일반화 능력을 향상시키기 위해 정교한 손실 함수와 정규화 기법을 개발하는 데 초점을 맞추고 있으며, 이를 통해 다양한 작업과 데이터 유형에 걸쳐 견고하고 효과적으로 유지되도록 보장합니다 [166], [167], [168].
표 I: 현재 생성적 AI 및 LLM(대규모 언어 모델) 연구의 포괄적 분류
- 비지도 학습(Unsupervised Learning): 비지도 학습은 레이블이 없는 데이터 내의 패턴을 발견하는 데 있어 AI에서 필수적이며, 특징 학습(feature learning)과 군집화(clustering) [169], [170]와 같은 작업에 중심적인 과정입니다. 이 방법은 오토인코더(autoencoders) [171], [172]와 생성적 적대 신경망(Generative Adversarial Networks, GANs) [173], [174], [175]의 도입으로 상당한 발전을 이루었으며, 비지도 학습의 적용 범위를 현저히 확장시켜 보다 정교한 데이터 생성과 표현 학습(representation learning) 능력을 가능하게 했습니다. 이러한 혁신은 비구조화된 데이터셋에 종종 내재된 복잡한 구조를 이해하고 활용하는 데 중요하며, 비지도 학습 기술의 다양성과 깊이가 성장하고 있음을 강조합니다.
- 강화 학습(Reinforcement Learning): 적응성과 최적화 능력이 특징인 강화 학습은 의사 결정과 자율 시스템에서 점점 더 중요해지고 있습니다 [176], [177]. 이 훈련 기법은 특히 딥 Q-네트워크(Deep Q-Networks, DQN) [178], [179], [180]와 근접 정책 최적화(Proximal Policy Optimization, PPO) 알고리즘 [181], [182], [183]의 개발로 상당한 발전을 이루었습니다. 이러한 개선은 복잡하고 동적인 환경에서 강화 학습의 효과와 적용 가능성을 향상시키는 데 결정적이었습니다. 상호작용하는 피드백 루프를 통해 의사 결정과 정책을 최적화함으로써, 강화 학습은 의사 결정에서 높은 수준의 적응성과 정밀성이 요구되는 시나리오에서 AI 시스템을 훈련하는 데 필수적인 도구로 자리 잡았습니다 [184], [185].
- 전이 학습(Transfer Learning): 전이 학습은 AI 훈련에서 다재다능함과 효율성을 강조하며, 한 작업에서 획득한 지식을 다른 관련 작업에 적용할 수 있게 함으로써 대규모 레이블이 있는 데이터셋이 필요한 것을 상당히 줄입니다 [186], [187]. 사전 훈련된 네트워크(pre-trained networks)를 사용하는 전이 학습은 모델이 특정 응용 프로그램에 효율적으로 미세 조정될 수 있도록 훈련 과정을 간소화함으로써 다양한 작업에서 적응성과 성능을 향상시키며, 방대한 레이블 데이터를 획득하는 것이 실질적으로 어렵거나 불가능한 시나리오에서 특히 유익합니다 [188], [189].
C. 응용 분야(Application Domains)
생성적 AI(Generative AI)의 응용 분야는 매우 다양하고 진화하고 있으며, 연구와 응용의 확립된 분야와 신흥 분야 모두를 포괄합니다. 이러한 분야는 최근 AI 기술의 발전과 AI 응용 범위의 확장에 의해 상당한 영향을 받았습니다.
- 자연어 이해(Natural Language Understanding, NLU): NLU는 AI 시스템에서 인간 언어의 이해와 맥락화를 강화하는 데 중심적인 역할을 하며, 의미 분석(semantic analysis), 명명된 개체 인식(named entity recognition), 감정 분석(sentiment analysis), 텍스트 함축(textual entailment), 기계 독해(machine reading comprehension) [190], [191], [192], [193]와 같은 핵심 능력을 포함합니다. NLU의 발전은 대화형 교환에서 복잡한 텍스트 데이터에 이르기까지 다양한 맥락에서 언어를 해석하고 분석하는 AI의 능력을 향상시키는 데 중요했습니다 [190], [192], [193]. NLU는 감정 분석(sentiment analysis), 언어 번역(language translation), 정보 추출(information extraction) 등의 응용 분야에서 기본적인 역할을 합니다 [194], [195], [196]. 최근의 발전은 BERT와 GPT-3과 같은 대형 트랜스포머(transformer) 기반 모델을 특징으로 하며, 이 모델들은 언어의 미묘함을 더 깊고 복잡하게 이해할 수 있게 함으로써 분야를 크게 발전시켰습니다 [197], [198].
- 자연어 생성(Natural Language Generation, NLG): NLG는 일관되고 맥락에 맞으며 창의적인 텍스트 응답을 생성하는 모델의 훈련에 중점을 두며, 챗봇(chatbots), 가상 비서(virtual assistants), 자동 콘텐츠 생성 도구(automated content creation tools)에서 중요한 구성 요소입니다 [199], [36], [200], [201]. NLG는 주제 모델링(topic modeling), 담화 계획(discourse planning), 개념에서 텍스트로의 생성(concept-to-text generation), 스타일 전환(style transfer), 제어 가능한 텍스트 생성(controllable text generation)과 같은 도전 과제를 포함합니다 [36], [202]. 최근 NLG 능력의 급증은 GPT-3과 같은 고급 모델을 예로 들 수 있으며, 이는 텍스트 생성의 세련미와 뉘앙스를 크게 향상시켜, AI 시스템이 인간의 글쓰기 스타일을 밀접하게 반영하는 텍스트를 생성할 수 있게 함으로써 다양한 상호작용적이고 창의적인 맥락에서 NLG의 범위와 적용 가능성을 넓혔습니다 [203], [55], [51].
- 대화형 AI(Conversational AI): 이 하위 분야는 대화 모델링(dialogue modeling), 질문 응답(question answering), 사용자 의도 인식(user intent recognition), 다중 턴 컨텍스트 추적(multi-turn context tracking)에 중점을 두어 부드럽고 자연스럽고 맥락을 인식하는 인간-컴퓨터 상호작용을 가능하게 하는 AI 시스템 개발에 전념합니다 [204], [205], [206], [207]. 금융 및 사이버보안 분야에서 AI의 예측 분석(predictive analytics)은 위험 평가와 사기 탐지를 변화시켜 더 안전하고 효율적인 운영을 이끌어냈습니다 [205], [19]. 이 분야의 발전은 Meena 7과 BlenderBot 과 같은 대형 사전 훈련된 모델로 입증되었으며, AI 상호작용의 공감적이고 반응적인 능력을 크게 향상시켰습니다. 이러한 시스템들은 사용자 참여와 만족도를 향상시킬 뿐만 아니라 여러 턴에 걸쳐 대화의 흐름을 유지하며, 일관되고 맥락에 맞는, 그리고 참여적인 경험을 제공합니다 [208], [209].
- 창의적 AI(Creative AI): 이 신흥 하위 분야는 텍스트, 예술, 음악 등을 아우르며 이미지, 오디오, 비디오를 포함한 다양한 형식에서 AI의 창의적이고 혁신적인 잠재력의 한계를 넓히는 데 집중하고 있으며, 아이디어 생성(idea generation), 스토리텔링(storytelling), 시(poetry), 음악 작곡(music composition), 시각 예술(visual arts), 창의적 글쓰기(creative writing) 등 예술 콘텐츠 생성에 참여하며 MidJourney와 DALL-E와 같은 상업적 성공을 거두었습니다 [210], [211], [212]. 이 분야의 도전 과제는 창의성을 효과적으로 평가하고 촉진하기 위해 적절한 데이터 표현, 알고리즘, 평가 지표를 찾는 것입니다 [212], [213]. 창의적 AI는 예술 과정을 자동화하고 향상시키는 도구로서뿐만 아니라 새로운 예술 표현 형태를 탐구하는 매체로서도 기능하며, 새롭고 다양한 창의적 결과물을 창출할 수 있게 합니다 [212]. 이 분야는 AI가 창의적 노력에 참여하고 기여할 수 있는 능력에서 중요한 도약을 나타내며, 기술과 예술의 교차점을 재정의합니다.
D. 준수 및 윤리 고려 사항
AI 기술이 빠르게 발전하고 다양한 분야에 더욱 통합됨에 따라, 윤리적 고려 사항과 법적 준수는 점점 더 중요해지고 있으며, 이는 '윤리적 AI 프레임워크(Ethical AI Frameworks)' 개발에 초점을 맞추는 것을 필요로 합니다. 이는 우리 분류법에서 새로운 범주로, 책임 있는 AI 개발을 향한 추세를 반영하는 생성 AI(generative AI)에서의 새로운 경향을 반영합니다 [214], [215], [15], [216], [217]. 이러한 프레임워크는 AI 시스템이 윤리적 고려, 공정성, 투명성에 중점을 두고 구축되도록 하는 데 중요하며, 공정성을 위한 편향 완화, 데이터 보호를 위한 개인 정보 및 보안 문제, 책임 있는 AI 윤리 등 중요한 측면을 다루면서, AI에서 책임이 매우 중요한 것으로 변화하는 환경에 대응합니다 [214], [15]. 윤리적 무결성과 법적 일치를 유지하기 위한 엄격한 접근 방식이 필요한 시기는 이 기술들의 채택이 도입하는 복잡성과 다면적 도전을 반영하여 그 어느 때보다도 절실합니다 [15].
- 편향 완화: AI 시스템에서의 편향 완화는 공정성과 대표성을 보장하기 위한 중요한 노력으로, 편향된 관점을 피하기 위한 균형 잡힌 데이터 수집뿐만 아니라 편향을 최소화하기 위한 알고리즘 조정과 정규화 기법을 구현하는 것을 포함합니다 [218], [219]. 지속적인 모니터링과 편향 테스트는 AI의 예측 패턴에서 나타날 수 있는 편향을 식별하고 해결하는 데 필수적입니다 [220], [219]. 이 분야의 주요 도전 과제는 교차 편향(intersectional biases) [221], [222], [223]과[^4] 이러한 편향에 기여할 수 있는 인과적 상호작용을 이해하는 것입니다 [224], [225], [226], [227].
- 데이터 보안: AI 데이터 보안에서는 데이터 기밀성을 보장하고, 동의 규범을 준수하며, 멤버십 추론 공격(membership inference attacks)과 같은 취약점에 대한 방어를 포함한 주요 요구 사항과 도전 과제가 있습니다 [228], [229]. 일반 데이터 보호 규정(General Data Protection Regulation, GDPR) 및 캘리포니아 소비자 개인 정보 보호법(California Consumer Privacy Act, CCPA)과 같은 적용되는 관할 구역 내 엄격한 법적 기준을 준수하는 것이 필수적이며, 목적 제한과 데이터 최소화가 필요합니다 [230], [231], [232]. 또한, 데이터 주권과 저작권 문제는 강력한 암호화, 접근 제어 및 지속적인 보안 평가의 필요성을 강조합니다 [233], [234]. 이러한 노력은 AI 시스템의 무결성을 유지하고 디지털 환경에서 사용자 개인 정보를 보호하는 데 중요합니다.
- AI 윤리: AI 윤리 분야는 공정성, 책임성, 사회적 영향에 초점을 맞추고, AI의 증가하는 복잡성과 인간 가치와의 잠재적 불일치로 인해 발생하는 윤리적 도전에 대응하며, 윤리적 거버넌스 프레임워크, 다학제 협력, 기술적 해결책이 필요합니다 [214], [235], [15], [236]. 또한, AI 윤리는 모델 개발 생명주기 전반에 걸쳐 추적 가능성, 감사 가능성, 투명성을 보장하고, 알고리즘 감사, 윤리 위원회 설립, 문서화 표준 및 모델 카드(model cards) 준수와 같은 관행을 사용하는 것을 포함합니다 [237], [236]. 그러나 이러한 이니셔티브의 채택은 여전히 불균등하며, AI 개발 및 배포에서 포괄적이고 일관된 윤리적 관행에 대한 지속적인 필요성을 강조합니다 [214].
- 개인 정보 보호: 이 분야는 데이터 기밀성과 무결성을 유지하는 데 중점을 두며, 익명화(anonymization) 및 연합 학습(federated learning)과 같은 전략을 사용하여 특히 생성 AI의 부상이 사용자 프로파일링의 위험을 초래할 때 직접적인 데이터 노출을 최소화합니다 [238], [239]. 이러한 노력에도 불구하고, 상관 공격(correlation attacks)에 대한 진정한 익명성을 달성하는 것과 같은 도전은 침입적 감시에 효과적으로 대응하는 복잡성을 강조합니다 [240], [241]. 개인 정보 보호법을 준수하고 안전한 데이터 처리 관행을 구현하는 것은 이러한 맥락에서 중요하며, 강력한 개인 정보 보호 메커니즘에 대한 지속적인 필요성을 보여줍니다.
E. 고급 학습
자기 지도 학습(self-supervised learning), 메타 학습(meta-learning), 그리고 파인 튜닝(fine-tuning)을 포함한 고급 학습 기술들은 AI 연구의 최전선에 있으며, AI 모델의 자율성, 효율성, 그리고 다재다능함을 향상시키고 있습니다.
- 자기 지도 학습(Self-supervised Learning): 이 방법은 레이블이 없는 데이터를 사용하여 모델을 자율적으로 훈련시키는 것을 강조하며, 수동 레이블링 노력과 모델 편향을 줄입니다 [242], [165], [243]. 데이터 분포 학습과 원본 입력 재구성을 위해 오토인코더(autoencoders)와 GANs 같은 생성 모델을 포함합니다 [244], [245], [246], 그리고 SimCLR [247]과 MoCo [248] 같은 긍정적 및 부정적 샘플 쌍을 구별하도록 설계된 대조적 방법들도 포함합니다. 또한, NLP에서 영감을 받은 자기 예측 전략을 사용하며, 입력 재구성을 위한 마스킹(masking) 기술과 같은 기술을 사용하여, 최근의 비전 트랜스포머(Vision Transformers) 개발로 크게 향상되었습니다 [249], [250], [165]. 이러한 다양한 방법들의 통합은 자기 지도 학습이 AI의 자율 훈련 능력을 발전시키는 역할을 강조합니다.
- 메타 학습(Meta-learning): 메타 학습, 또는 '학습하는 법을 배우기'는 AI 모델에게 제한된 데이터 샘플을 사용하여 새로운 작업과 도메인에 빠르게 적응할 수 있는 능력을 부여하는 데 중점을 둡니다 [251], [252]. 이 기술은 최적화 과정을 마스터하는 것을 포함하며, 제한된 데이터가 있는 상황에서 모델이 빠르게 적응하고 다양한 작업에서 성능을 발휘할 수 있도록 보장하는 데 중요합니다, 현재 데이터 중심의 환경에서 필수적입니다 [253], [254]. 이는 소수샷 일반화(few-shot generalization)에 초점을 맞추며, AI가 최소한의 데이터로 다양한 작업을 처리할 수 있게 하여, 다재다능하고 적응 가능한 AI 시스템을 개발하는 데 중요함을 강조합니다 [255], [256], [254], [257].
- 파인 튜닝(Fine Tuning): 사전 훈련된 모델을 특정 도메인이나 사용자 선호에 맞게 조정하여, 틈새 응용 프로그램에 대한 정확도와 관련성을 향상시킵니다 [60], [258], [259]. 주요 접근 방식은 인코더와 분류기의 모든 가중치를 조정하는 엔드-투-엔드 파인 튜닝(end-to-end fine-tuning) [260], [261]과, 인코더 가중치를 고정하여 다운스트림 분류기를 위한 특징을 추출하는 특징 추출 파인 튜닝(feature-extraction fine-tuning)이 있습니다 [262], [263], [264]. 이 기술은 생성 모델이 특정 사용자의 요구나 도메인 요구에 더 효과적으로 적응하도록 보장하여, 다양한 맥락에서 더 다재다능하고 적용 가능하게 만듭니다.
- 인간 가치 정렬(Human Value Alignment): 이 신흥 측면은 AI 모델을 인간의 윤리와 가치와 조화시켜 그들의 결정과 행동이 사회적 규범과 윤리적 기준을 반영하도록 하는 데 집중합니다. 이는 윤리적 의사결정 과정의 통합과 인간의 도덕적 가치와 일치하도록 AI 출력의 적응을 포함합니다 [265], [89], [266]. 이는 특히 건강 관리, 금융, 개인 비서와 같이 AI가 인간과 밀접하게 상호작용하는 시나리오에서 점점 더 중요해지고 있으며, AI 시스템이 기술적으로 타당할 뿐만 아니라 윤리적이고 사회적으로 책임 있는 결정을 내리도록 보장하기 위함입니다. 이는 사회에 의해 신뢰되고 받아들여지는 AI 시스템을 개발하는 데 있어 인간 가치 정렬이 중요해지고 있음을 의미합니다 [89], [267].
F. 신흥 트렌드(Emerging Trends)
생성적 AI 연구의 신흥 트렌드는 기술과 인간 상호작용의 미래를 형성하고 있으며, 더 통합되고, 상호작용적이며, 지능적인 AI 시스템으로의 역동적인 변화를 나타내며, AI의 영역에서 가능한 것의 경계를 전진시키고 있습니다. 이 분야의 주요 발전에는 다음이 포함됩니다:
- 다중모달 학습(Multimodal Learning): AI의 빠르게 발전하는 하위 분야인 다중모달 학습은 언어 이해, 컴퓨터 비전, 오디오 처리를 결합하여 더 풍부한 다감각 컨텍스트 인식을 달성하는 데 중점을 둡니다 [114], [268]. 최근에는 Gemini 모델과 같은 개발이 자연 이미지, 오디오, 비디오 이해 및 수학적 추론을 포함한 다양한 다중모달 작업에서 최첨단 성능을 보여주며 새로운 벤치마크를 설정했습니다 [112]. Gemini의 본질적으로 다중모달 설계는 다른 정보 유형 간의 원활한 통합과 작동을 예시합니다 [112]. 발전에도 불구하고, 다중모달 학습 분야는 다양한 데이터 유형을 더 효과적으로 처리하기 위한 아키텍처를 개선하는 것 [269], [270], 다면적 정보를 정확하게 대표하는 포괄적인 데이터셋을 개발하는 것 [269], [271], 그리고 이러한 복잡한 시스템의 성능을 평가하기 위한 벤치마크를 설정하는 것 [272], [273]과 같은 지속적인 도전에 직면하고 있습니다.
- 상호작용 및 협력 AI(Interactive and Cooperative AI): 이 하위 분야는 복잡한 작업에서 인간과 효과적으로 협력할 수 있는 AI 모델의 능력을 향상시키는 것을 목표로 합니다 [274], [35]. 이 트렌드는 인간과 함께 작업할 수 있는 AI 시스템을 개발하는 데 중점을 두어, 생산성 및 건강 관리를 포함한 다양한 응용 분야에서 사용자 경험과 효율성을 향상시킵니다 [275], [276], [277]. 이 하위 분야의 핵심 측면은 설명 가능성(explainability) [278], 인간의 의도와 행동 이해(theory of mind) [279], [280], 그리고 AI 시스템과 인간 간의 확장 가능한 조정과 같은 영역에서 를 발전시키는 것으로, 다양한 맥락에서 인간의 능력을 돕고 증진할 수 있는 더 직관적이고 상호작용적인 AI 시스템을 만드는 데 중요한 협력적 접근법입니다 [281], [35].
- AGI(인공 일반 지능) 개발: AGI는 인간 인지의 포괄적이고 다면적인 측면을 모방하는 AI 시스템을 만드는 비전 있는 목표를 대표하며, 인간의 인지 능력의 깊이와 폭에 밀접하게 맞춰진 전체적인 이해와 복잡한 추론 능력을 갖춘 AI를 개발하는 데 중점을 둔 하위 분야입니다 [282], [283], [32]. AGI는 단순히 인간 지능을 복제하는 것뿐만 아니라, 인간과 유사한 적응성과 학습 능력을 보여주며 다양한 작업을 자율적으로 수행할 수 있는 시스템을 만드는 것을 포함합니다 [282], [283]. AGI를 추구하는 것은 AI 연구와 개발의 경계를 지속적으로 넓히는 장기적인 열망입니다.
- AGI(인공 일반 지능) 격리: AGI 안전성 및 격리는 매우 발전된 AI 시스템과 관련된 잠재적 위험을 인식하고, 이러한 고급 시스템이 기술적으로 능숙할 뿐만 아니라 인간의 가치와 사회적 규범과 윤리적으로 일치하도록 보장하는 데 중점을 둡니다 [15], [32], [11]. 초지능 시스템을 개발해 나가면서 엄격한 안전 프로토콜과 제어 메커니즘을 수립하는 것이 중요해집니다 [11]. 주요 관심사는 대표적 편향 완화, 분포 변화 대응, AI 모델 내의 잘못된 상관관계 수정과 같은 영역을 포함합니다 [11], [284]. 목표는 AI 개발을 책임감 있고 윤리적인 기준과 일치시켜 의도하지 않은 사회적 결과를 방지하는 것입니다.
그림 4: MoE의 혁신적인 전망에 대한 개념도
IV. MoE의 혁신적인 지평선
MoE 모델 아키텍처는 변환기 기반 언어 모델에서 선구적인 발전을 나타내며, 비교할 수 없는 확장성과 효율성을 제공합니다(그림 4). 최근 모델들인 1.6조 개의 매개변수를 가진 스위치 트랜스포머(Switch Transformer) [285]와 8x7B 매개변수를 가진 믹스트라(Mixtra) [286]와 같은 MoE 기반 설계는 다양한 언어 작업에서 모델 규모와 성능의 새로운 경계를 빠르게 재정의하고 있습니다.
A. 핵심 개념과 구조
MoE 모델은 신경망 설계에서 중요한 혁신을 나타내며, 훈련과 추론에서 향상된 확장성과 효율성을 제공합니다 [287], [288], [110]. 핵심적으로 MoE 모델은 밀집층(dense layers)을 여러 전문가 네트워크로 구성된 희소 MoE 층(sparse MoE layers)으로 대체하여 희소성 기반 아키텍처를 활용합니다. 여기서 각 전문가는 훈련 데이터나 작업의 특정 부분에 전념하며, 훈련 가능한 게이팅 메커니즘이 동적으로 입력 토큰을 이러한 전문가들에게 할당하여, 계산 자원을 최적화하고 작업의 복잡성에 효과적으로 적응합니다 [94], [21], [110]. MoE 모델은 사전 훈련 속도 측면에서 상당한 이점을 보여주며, 밀집 모델(dense models)을 능가합니다 [94], [287]. 그러나, 모든 전문가를 비디오 랜덤 액세스 메모리(VRAM)에 로드해야 하는 필요성으로 인해 미세 조정(fine-tuning)에서는 도전을 겪고 추론 시 상당한 메모리가 필요합니다 [289], [290], [110]. MoE의 구조는 전문가 라우팅을 위한 게이팅 네트워크를 포함하는 라우터 층(router layers)과 변환기 층(transformer layers)을 번갈아 가며, 상당한 매개변수 확장과 문제 해결에서의 고급 전문화를 가능하게 하는 아키텍처로 이어집니다 [291], [21].
MoE 모델의 두드러진 특징은 대규모 데이터셋을 관리하는 유연성으로, 계산 효율성에 미미한 감소만을 경험하면서 모델 용량을 천 배 이상 증폭시킬 수 있는 능력입니다 [289], [292]. 이 모델들의 핵심 구성 요소인 희소 게이팅 혼합 전문가 층(Sparsely-Gated Mixture-of-Experts Layer)은 수많은 간단한 피드포워드 전문가 네트워크와 전문가 선택을 담당하는 훈련 가능한 게이팅 네트워크로 구성되어 있으며, 각 입력 인스턴스에 대해 동적이고 희소한 전문가 활성화를 용이하게 하여 높은 계산 효율성을 유지합니다 [293], [294], [110].
스위치 트랜스포머(Switch Transformer)와 같은 최근 MoE 모델의 발전은 라우터가 적절한 전문가에게 토큰을 지능적으로 라우팅하는 능력이 MoE 모델에 상당한 이점을 부여하며, 계산 시간을 일정하게 유지하면서 모델 크기를 확장할 수 있음을 강조했습니다 [295], [296], [297]. 실험적 증거는 라우터가 데이터 클러스터에 따라 입력을 라우팅하는 것을 학습한다는 것을 보여주며, 실제 응용에서의 잠재력을 보여줍니다 [295], [289]. MoE 모델의 핵심 개념과 구조는 동적 라우팅과 전문화 능력에 있으며, 다양한 작업에서 신경망을 확장하고 효율성과 적응성을 향상시키는 유망한 방법을 제공하지만, 라우터의 견고성은 적대적 공격에 대해 보호되어야 합니다 [289], [298].
B. 훈련 및 추론 효율성
MoE 모델, 특히 Mixtral 8x7B는 밀집 모델(dense models)에 비해 뛰어난 사전 학습 속도로 유명하지만, 모든 전문가(experts)를 로드해야 한다는 요구 사항 때문에 미세 조정(fine-tuning)에서 어려움을 겪고 추론(inference)에 상당한 VRAM을 요구합니다 [289], [290], [110]. 최근 MoE 아키텍처의 발전은 특히 인코더-디코더(encoder-decoder) 모델에서 주목할 만한 훈련 비용 효율성을 가져왔으며, 특정 상황에서 밀집 모델에 비해 최대 다섯 배까지 비용 절감을 보여주는 증거가 있습니다 [21], [289], [298], [287]. DeepSpeedMoE [287]와 같은 혁신은 새로운 아키텍처 디자인과 모델 압축을 제공하여 MoE 모델 크기를 대략 줄이고, 추론을 최적화하여 최대 더 나은 지연 시간(latency)과 비용 효율성을 달성했습니다. Lina [299]와 같은 혁신을 통한 분산 MoE 훈련 및 추론의 진보는 텐서 분할(tensor partitioning)을 향상시켜 all-to-all 통신 병목 현상을 효과적으로 해결했으며, 이는 all-to-all 통신과 훈련 단계 시간을 개선할 뿐만 아니라 추론 중 자원 스케줄링을 최적화하여 기존 시스템에 비해 훈련 단계 시간을 최대 1.73배 줄이고 95번째 백분위 추론 시간을 평균 1.63배 감소시켰습니다. 이러한 발전은 대규모 모델 환경에서 밀집 모델에서 희소 MoE 모델로 중요한 전환을 표시하며, 적은 자원으로 더 높은 품질의 모델을 훈련함으로써 AI의 잠재적 응용 분야를 확장하고 있습니다.
C. 부하 균형 및 라우터 최적화
MoE 모델에서 효과적인 부하 균형(load balancing)은 전문가들 사이에 계산 부하를 균등하게 분배하는 것을 보장하는 데 필수적이며, 특정 토큰을 처리하기 위해 적절한 전문가를 선택하는 MoE 레이어의 라우터 네트워크(router network)가 이 균형을 달성하는 데 중추적인 역할을 합니다. 이는 MoE 모델의 안정성과 전반적인 성능에 기본적인 요소입니다 [293], [289], [288], [300], [110]. 라우터 Zloss 정규화 기법(router Zloss regularization techniques)의 발전은 MoE 모델에서 전문가 불균형을 해결하는 데 중요한 역할을 하며, 게이팅 메커니즘(gating mechanism)을 미세 조정함으로써 전문가들 사이에 더 공평한 작업 부하 분배를 보장하고 안정적인 훈련 환경을 조성하여 모델 성능을 향상시키고 훈련 시간 및 계산 오버헤드를 줄입니다 [301], [302]. 동시에, 전문가 용량 관리 전략(expert capacity management strategies)의 통합은 각 전문가가 처리할 수 있는 토큰의 수에 대한 임계값을 설정하여 개별 전문가의 처리 능력을 조절하는 MoE 모델에서 중요한 접근법으로 등장하며, 병목 현상을 효과적으로 방지하고 더 효율적이고 간소화된 모델 운영을 보장하여 복잡한 계산 작업 중에 향상된 훈련 과정과 높은 성능을 이끌어냅니다 [293], [303], [289].
D. 병렬성 및 서빙 기술
최근 MoE(혼합 전문가) 모델의 발전은 병렬 처리와 서비스 기술에서의 효율성을 강조하며, 대규모 신경망에 상당한 영향을 미쳤습니다. 예를 들어, DeepSpeed-MoE는 데이터 병렬 처리, 비전문가(non-expert) 파라미터를 위한 텐서 슬라이싱(tensor-slicing), 전문가(expert) 파라미터를 위한 전문가 병렬 처리(expert parallelism)와 같은 고급 병렬 처리 모드를 도입하여 모델의 효율성을 향상시켰습니다. 이들의 접근 방식은 MoE 모델 추론에서 지연 시간(latency)과 처리량(throughput)을 모두 최적화하여, 여러 그래픽 처리 장치(GPU)를 사용하는 생산 환경에서 확장 가능한 솔루션을 제공합니다 [287]. 다국어 작업과 코딩과 같은 다양한 응용 분야에서 MoE 모델은 단일 프레임워크 내에서 앙상블과 같은 구조로 인해 복잡한 작업을 처리하는 인상적인 능력을 보여주었습니다 [304], [305], [306]. 특히, 1.6조 개의 파라미터를 가진 Mixtral과 Switch Transformer 모델은 MoE 계산의 모델 크기 대비 아래로의 선형적인 확장(sublinear scaling)으로 인해 100억 개 파라미터의 밀집 모델(dense model)과 동등한 계산 효율성을 달성했으며, 이는 고정된 계산 예산 내에서 상당한 정확도 향상을 이끌어냈습니다 [21], [289], [287], [110]. 또한, DeepSpeed-MoE는 모델 크기를 최대 까지 줄이면서 정확도를 유지하는 모델 압축 기술과 DeepSpeed 라이브러리의 일부인 MoE 훈련 및 추론 솔루션을 포함하여, 대규모 MoE 모델을 더 빠르고 비용 효율적으로 제공하는 데 중요한 역할을 했습니다 [287]. 이러한 혁신은 AI의 새로운 방향을 열어, 밀집 모델에서 희소 MoE 모델로 전환하며, 더 적은 자원으로 더 높은 품질의 모델을 훈련하고 배포하는 것이 더 널리 달성 가능해집니다.
E. 미래의 방향과 응용 분야
MoE 아키텍처에 대한 신흥 연구는 희소 미세 조정(sparse fine-tuning) 기술을 발전시키고, 지시어 튜닝(instruction tuning) 방법을 탐구하며, 성능과 효율성 향상을 완전히 활용하기 위해 라우팅 알고리즘을 개선하는 데 초점을 맞출 수 있습니다. 모델이 10억 개 이상의 파라미터로 확장됨에 따라, MoE는 과학, 의료, 창의적 및 실제 세계 응용 분야에서 능력을 대폭 확장하는 패러다임 변화를 나타냅니다. 최전선의 작업은 미세 조정 중에 하이퍼파라미터(hyperparameters)의 자동 조정을 개선하여 정확도, 보정(calibration), 그리고 안전성을 최적화하는 것을 목표로 할 수도 있습니다. MoE 연구는 전이 학습(transfer learning)에 대한 전문화를 유지하면서 모델 규모의 한계를 계속해서 밀어붙이고 있습니다. 적응형 희소 접근(Adaptive sparse access)은 추론에서 개방형 대화에 이르기까지 다양한 작업에 대해 수천 명의 전문가들이 협력하도록 조정합니다. 라우팅 메커니즘에 대한 지속적인 분석은 전문가들 간의 부하를 균형있게 분배하고 중복된 계산을 최소화하려고 합니다. AI 커뮤니티가 대규모에서 MoE 방법을 더 깊이 조사함에 따라, 이러한 모델들은 언어, 코드 생성, 추론 및 멀티모달(multimodal) 응용 분야에서 새로운 돌파구를 약속합니다. 교육, 의료, 금융 분석 등 다양한 분야에서의 영향을 평가하는 데 큰 관심이 있습니다. 결과는 모델 최적화뿐만 아니라 조합적 일반화(combinatorial generalization) 뒤에 있는 원리를 이해하는 데에도 통찰력을 제공할 수 있습니다.
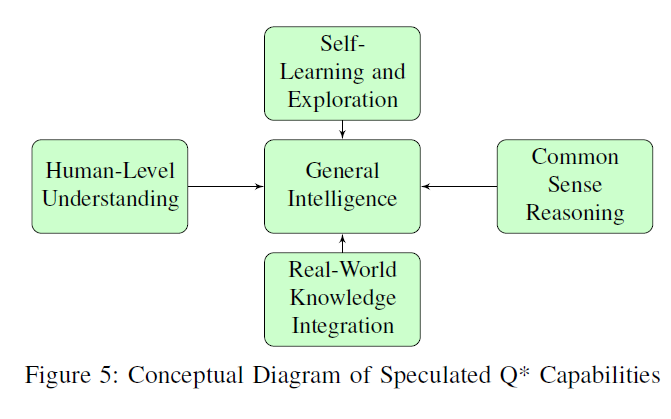
그림 5: 추측된 Q* 능력의 개념도
V. Q*의 추측된 능력
의 급성장하는 영역에서, 예상되는 프로젝트는 잠재적인 돌파구의 등대로서, AI 능력의 풍경을 재정의할 수 있는 진보를 예고합니다(그림 5).
A. 향상된 일반 지능
Q*의 일반 지능(general intelligence) 분야에서의 발전은 특화된 AI에서 전체적인 AI로의 패러다임 전환을 나타내며, 인간 지능과 유사한 모델의 인지 능력의 확장을 의미합니다. 이러한 고급 형태의 일반 지능은 다양한 신경망 구조(neural network architectures)와 기계 학습 기술(machine learning techniques)을 통합하여, AI가 다면적인 정보를 원활하게 처리하고 종합할 수 있게 합니다. T0과 같은 모델을 반영하는 범용 어댑터 접근법(universal adapter approach)은 Q*에게 다양한 도메인에서 지식을 빠르게 흡수할 수 있는 능력을 부여할 수 있습니다. 이 방법은 가 적응 가능한 모듈 플러그인(module plugins)을 학습하게 하여, 새로운 데이터 유형에 대처하는 능력을 향상시키고 기존 기술을 유지하면서, 좁은 전문화를 포괄적이고 적응력 있으며 다재다능한 추론 시스템(reasoning system)으로 결합하는 AI 모델로 이어집니다. 해당 준수학적(quasi-mathematical) 공식은 다음과 같이 표현될 수 있습니다:
여기서:
- EGI: "향상된 일반 지능(Enhanced General Intelligence)"
- : 다양한 신경망 구조들
- : 다양한 기계 학습 기술들
- : 이러한 구성 요소들의 통합
- : 신경망과 기계 학습 기술 간의 기능적 상호작용
AI의 이러한 발전은 인간의 인지 유연성과 맞먹거나 잠재적으로 뛰어넘을 수 있는 지능의 출현을 시사하며, 학제 간 혁신과 복잡한 문제 해결을 촉진하는 데 있어 멀리 미치는 영향을 가집니다. 의 추측되는 능력은 복잡한 윤리적 함의와 거버넌스(governance) 도전을 야기합니다. AI 시스템이 더 높은 수준의 자율성과 의사결정 능력에 접근함에 따라, 책임감 있고 투명한 AI 개발을 보장하기 위해 견고한 윤리적 프레임워크와 거버넌스 구조를 확립하는 것이 중요합니다. 이는 고급 AI 능력과 관련된 잠재적 위험을 완화하는 것을 포함하며, AI 발전과 함께 진화하는 포괄적이고 동적인 윤리적 지침의 필요성을 강조합니다.
B. 고급 자기 학습 및 탐색
고급 AI 개발의 영역에서, 는 자기 학습(self-learning)과 탐색(exploration) 능력에서 중요한 진화를 대표할 것으로 예상됩니다. 이는 AlphaGo에 사용된 것과 유사하지만 언어와 추론 작업의 복잡성을 처리하기 위해 상당히 향상된 기능을 가진 정교한 정책 신경망(Policy Neural Networks, NNs)을 활용할 것으로 추측됩니다. 이러한 네트워크는 정책 업데이트를 안정화하고 샘플 효율성을 향상시키는 Proximal Policy Optimization(PPO)과 같은 고급 강화 학습 기술을 사용할 것으로 기대됩니다. 이는 자율 학습에서 중요한 요소입니다. 이 NN들을 최첨단 검색 알고리즘과 통합하는 것은, 아마도 사고의 트리(Tree of Thought)나 그래프(Graph of Thought)의 새로운 반복을 포함할 수 있으며, Q*가 복잡한 정보를 자율적으로 탐색하고 흡수할 수 있게 할 것으로 예측됩니다. 이 접근법은 메타 학습(meta-learning) 능력을 강화하기 위해 그래프 신경망(graph neural networks)과 결합될 수 있으며, 이를 통해 Q*는 이전에 획득한 지식을 유지하면서 새로운 작업과 환경에 빠르게 적응할 수 있습니다. 해당 준수학적 공식은 다음과 같이 나타낼 수 있습니다:
여기서:
- ASLE: "고급 자가 학습 및 탐색(Advanced Self-Learning and Exploration)"
- : 강화 학습(reinforcement learning) 알고리즘, 특히 근접 정책 최적화(Proximal Policy Optimization, PPO)에 대한 것입니다.
- PNN: 언어 및 추론 작업에 적응된 정책 신경망(Policy Neural Networks)입니다.
- : 생각의 나무(Tree of Thought)나 그래프와 같은 정교한 탐색 알고리즘(sophisticated search algorithms)을 말합니다.
- GNN: 메타 학습(meta-learning)을 위한 그래프 신경망(Graph Neural Networks)의 통합입니다.
- : RL과 GNN의 교차 기능 향상(cross-functional enhancement)을 의미합니다.
이러한 능력은 기존 데이터를 이해하는 데 국한되지 않고 새로운 지식을 적극적으로 탐색하고 종합할 수 있는 모델을 나타냅니다. 이는 자주 재교육할 필요 없이 진화하는 시나리오에 효과적으로 적응할 수 있음을 의미하며, 현재 AI 모델을 넘어서는 자율성과 효율성의 새로운 수준을 내포합니다.
C. 우수한 인간 수준의 이해(Superior Human-Level Understanding)
Q*가 우수한 인간 수준의 이해를 달성하려는 목표는 여러 신경망의 고급 통합에 달려 있다고 추측됩니다. 여기에는 AlphaGo와 같은 시스템에서 발견되는 평가 구성 요소와 유사한 가치 신경망(Value Neural Network, VNN)이 포함될 수 있습니다. 이 네트워크는 언어와 추론 과정에서 정확성과 관련성을 평가하는 것을 넘어 인간 커뮤니케이션의 미묘함에 깊이 파고들 것입니다. 모델의 깊은 이해 능력은 DeBERTa와 같은 변환기(transformer) 아키텍처에서 발견되는 고급 자연어 처리 알고리즘과 기술에 의해 향상될 수 있습니다. 이러한 알고리즘은 Q*가 텍스트뿐만 아니라 의도, 감정, 그리고 내포된 의미와 같은 미묘한 사회-감정적 측면을 해석할 수 있게 할 것입니다.
감정 분석(sentiment analysis)과 자연어 추론(natural language inference)을 통합함으로써, 는 공감, 비꼬기, 태도를 포함한 사회-감정적 통찰의 층을 탐색할 수 있습니다. 해당 준수학적(quasi-mathematical) 공식은 다음과 같이 표현될 수 있습니다:
여기서:
- SHLU: "우수한 인간 수준의 이해(Superior Human-Level Understanding)".
- : AlphaGo와 같은 시스템에서 평가 구성 요소와 유사한 가치 신경망(Value Neural Network).
- NLP: 고급 NLP 알고리즘 세트.
- : VNN 평가와 NLP 알고리즘의 결합.
- : NLP 세트 내의 개별 알고리즘.
이러한 수준의 이해는 현재 언어 모델을 뛰어넘어, 가 공감적이고 상황 인식(contextaware) 상호작용에서 뛰어난 성과를 낼 수 있게 하며, 이를 통해 AI 애플리케이션에서 개인화와 사용자 참여의 새로운 계층을 가능하게 합니다.
D. 고급 상식 추론(Advanced Common Sense Reasoning)
Q의 고급 상식 추론(advanced common sense reasoning)에서의 예상되는 발전은 정교한 논리 및 의사결정 알고리즘을 통합하고, 상징적 AI(symbolic AI)와 확률적 추론(probabilistic reasoning)의 요소를 결합할 수도 있습니다. 이 통합은 Q에 일상적인 논리에 대한 직관적인 이해와 인간의 상식에 가까운 이해를 부여하려는 목적을 가지고 있으며, 인공 지능과 자연 지능 사이의 중요한 격차를 메우는 것을 목표로 합니다. Q의 추론 능력 향상은 CogSKR과 같은 모델에서 볼 수 있는 물리 및 사회 엔진과 유사한 그래프 구조의 세계 지식을 포함할 수 있습니다. 현실에 기반한 이 접근법은 현대 AI 시스템에서 종종 결여된 일상적 논리를 포착하고 해석할 것으로 기대됩니다. 대규모 지식 베이스와 의미 네트워크를 활용함으로써 Q는 복잡한 사회적 및 실용적 시나리오를 효과적으로 탐색하고 대응할 수 있으며, 그 추론과 결정을 인간의 경험과 기대에 더 밀접하게 맞출 수 있을 것입니다. 해당 준수학적 공식은 다음과 같이 나타낼 수 있습니다:
여기서:
- : "고급 상식 추론(Advanced Common Sense Reasoning)".
- LogicAI와 ProbAI: 각각 상징적 AI(symbolic AI)와 확률적 추론(probabilistic reasoning) 구성 요소.
- WorldK: 그래프 구조의 세계 지식(graph-structured world knowledge) 통합.
- : 이러한 요소들의 통합된 작동으로 상식 추론을 위함.
E. 광범위한 실세계 지식 통합
Q*의 광범위한 실세계 지식 통합 접근 방식은 고급 형식 검증 시스템(advanced formal verification systems)의 사용을 포함할 것으로 추측되며, 이는 논리적이고 사실적인 추론을 검증하는 견고한 기반을 제공할 것입니다. 이 방법은
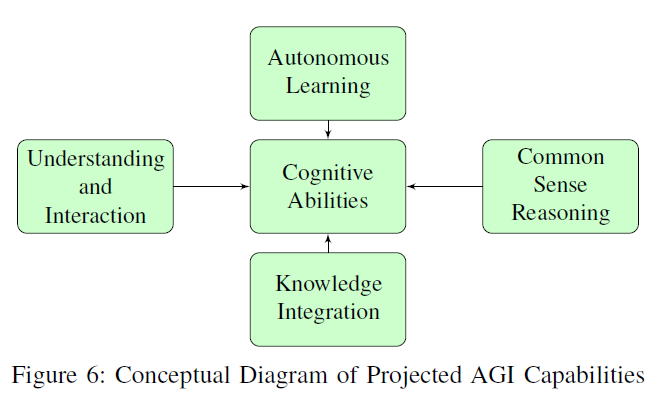
그림 6: 예상되는 AGI 능력의 개념도
고급 신경망 구조(neural network architectures)와 동적 학습 알고리즘(dynamic learning algorithms)과 결합될 때, 는 실세계의 복잡성을 깊이 있게 다루고 기존 AI의 한계를 초월할 수 있게 됩니다. 또한, Q*는 수학적 정리 증명 기법(mathematical theorem proving techniques)을 검증을 위해 사용할 수 있으며, 이를 통해 그것의 추론과 결과물이 정확할 뿐만 아니라 윤리적으로도 탄탄하다는 것을 보장합니다. 이 과정에서 윤리 분류기(Ethics classifiers)의 통합은 실세계 시나리오에 대한 신뢰할 수 있고 책임감 있는 이해와 상호작용을 제공하는 능력을 더욱 강화합니다. 해당 준수학적(quasi-mathematical) 공식화는 다음과 같이 표현될 수 있습니다:
여기서:
- ERWKI: "광범위한 실세계 지식 통합(Extensive Real-World Knowledge Integration)".
- FVS: 형식 검증 시스템(Formal Verification Systems).
- : 신경망 구조(neural network architectures).
- LTP: 논리적 및 사실적 검증을 위한 수학적 정리 증명(mathematical theorem proving).
- EC: 윤리 분류기(Ethics classifiers)의 통합.
- : 지식 종합과 윤리적 정렬을 위한 포괄적 통합.
더 나아가, 의 추측된 능력은 일자리 시장과 노동 역학을 크게 변화시킬 잠재력을 가지고 있습니다. 고급 기능을 갖춘 Q*는 복잡한 작업을 자동화할 수 있으며, 이는 일자리 요구 사항의 변화와 새로운 기술 수요의 출현으로 이어질 수 있습니다. 이는 노동력 전략과 교육 패러다임의 재평가를 필요로 하며, 기술적 환경의 변화에 맞추고 이러한 고급 AI 시스템과 상호작용하고 보완할 수 있는 노동력을 준비시키는 것을 보장합니다.
Vi. AGI의 예상 능력
AGI는 AI에서 인간의 인지 능력을 소프트웨어 패러다임으로 반영하려는 변혁적인 도약으로 서 있습니다(그림 6). AGI의 진화는 정책 신경망(policy neural networks)과 고급 강화 학습 기법(advanced reinforcement learning techniques)을 활용한 고급 자기 학습 능력(self-learning capabilities)으로 특징지어집니다. 이러한 네트워크와 함께 사고의 나무/그래프(Tree/Graph of Thought)와 같은 알고리즘의 통합은 AGI가 독립적으로 다양한 분야에 걸쳐 지식을 습득하고 적용할 수 있는 미래를 제시합니다.
A. 자율 학습의 혁명
AGI는 자가 학습(self-learning)과 탐색(exploration)을 혁명적으로 변화시킬 것으로 예상됩니다 [282], [307], [283], [32]. PPO와 같은 방법을 통합함으로써, AGI 모델들은 현재의 AI 모델들이 훈련 데이터에 의존하는 것을 넘어서 자율적인 학습과 문제 해결을 달성할 수 있는 위치에 있으며, 이는 빈번한 재훈련의 필요성을 줄이고 진화하는 시나리오에 대한 동적 적응을 용이하게 하는 새로운 패러다임으로의 전환 가능성을 나타냅니다 [181], [308].
B. 인지 능력의 확장
다양한 아키텍처를 통합할 것으로 기대되는 AGI는 인간 인지의 다면적인 특성을 복제하는 일반 지능의 수준을 약속할 수 있습니다 [282], [309]. GPT와 BERT와 같은 모델을 반영하는 범용 어댑터 접근 방식은 다양한 정보의 빠른 동화를 용이하게 하여, AGI를 인간 지능과 유사한 적응성을 가진 다양한 도메인에서 작업을 수행할 수 있는 시스템으로 위치시킬 수 있습니다 [282], [310]. AGI의 전체 능력은 아직 추측의 영역에 있지만, 현재의 추세는 고급 건강 진단 분야에서의 잠재적 응용을 시사하며, 이는 AI 주도의 예측 의학 모델에서의 최근 돌파구에 의해 입증되며, AGI가 의료 진단과 치료를 혁명화할 잠재력을 나타냅니다.
C. 이해와 상호작용의 향상
AGI는 인간 언어와 사회-감정적 미묘함에 대한 비할 데 없는 이해를 달성할 것으로 예상되며, 이는 AGI가 복잡하고 공감적이며 맥락을 인식하는 상호작용에 참여할 수 있게 하는 변환기 아키텍처(transformer architectures)와 같은 알고리즘을 활용할 것을 시사하며, AI 시스템이 의사소통하고 상호작용하는 방식을 혁명화할 잠재적 응용 분야를 나타냅니다 [282], [307], [311].
D. 고급 상식 추론
AGI에 통합된 상징적 AI(Symbolic AI)와 확률적 추론(probabilistic reasoning)은 이 시스템들에 본능적인 상식을 부여하여 인공 지능과 자연 지능 사이의 격차를 메우고, AGI가 실제 세계 시나리오를 효과적으로 탐색하고 인간 사고 과정과 밀접하게 일치하는 추론으로 반응할 수 있게 할 수 있습니다 [282], [312], [313].
E. 지식의 전체적 통합
실세계 지식을 광범위하게 통합하는 AGI의 잠재력은 형식 검증 시스템(formal verification systems)에 의해 안내되며, AGI의 출력이 정확할 뿐만 아니라 윤리적으로 기반을 둔 미래의 능력을 암시하며, AGI가 실세계의 복잡성과 책임감 있는 상호작용을 할 수 있는 능력을 나타냅니다 [282], [311]. AGI의 예상되는 능력은 기후 변화와 같은 중대한 글로벌 도전 과제에 대응하는 것으로 확장되며, 여기서 AGI의 고급 데이터 분석 및 예측 모델링은 환경 모니터링, 기후 패턴 예측 및 지속 가능한 해결책을 고안하는 데 있어 더 나은 역할과 더 중요한 역할을 할 수 있으며, 글로벌 생태 노력에 크게 기여할 수 있습니다 [282], [283], [32].
F. AGI 개발의 도전과 기회
AGI의 개발은 도전과 기회를 모두 포함합니다. AGI는 창의적 분야에서의 생산성 향상과 교차 모달 생성 기술에서의 혁신을 약속하지만, 데이터 편향, 계산 효율성 및 윤리적 함의와 같은 상당한 도전이 지속됩니다 [15], [32]. 이러한 도전은 데이터 큐레이션, 효율적인 시스템 및 사회적 영향에 중점을 둔 AGI 개발에서 균형 잡힌 접근 방식을 필요로 합니다 [309].
AGI(인공 일반 지능) 개발의 맥락에서, 다양한 분야의 전문가들은 현재 AI의 능력을 과대평가하는 것에 대해 경고하며, AGI의 이론적 틀과 오늘날 AI의 실제 현실 사이의 격차를 강조합니다 [314], [32]. AGI가 상상하는 자율성과 인지 능력은 현재의 AI 모델들과 구별되며, 인간의 개입 없이 다양한 분야에서 작업을 수행할 수 있는 미래의 AI 시스템을 제안합니다 [282]. 이러한 개발 궤적은 AGI가 사회에서 변혁적인 힘이 되어가는 여정에서 윤리적 고려사항과 기술적 돌파구의 중요성을 강조합니다 [15], [32]. 진정한 AGI를 달성하기 위한 시간표를 예측하는 것은 여전히 추측의 영역에 머물고 있지만, 현재의 계산 능력 제한과 인간과 같은 인지 능력을 복제하는 복잡성과 같은 잠재적인 장애물을 인식하는 것이 중요합니다. 이러한 점들은 AGI를 추구하는 과정에서 지속적인 연구와 윤리적 고려가 필요함을 강조하며, 책임감 있고 양심적인 개발을 보장합니다.
VII. 생성적 AI 연구 분류에 대한 영향 분석
MoE(전문가들의 앙상블), 멀티모달리티, AGI와 같은 고급 AI 개발의 등장으로 생성적 AI 연구의 풍경은 크게 변모하고 있습니다. 이 섹션에서는 이러한 개발이 생성적 AI 연구 분류를 어떻게 재편하고 있는지 분석합니다.
A. 영향 분석 기준
다양한 연구 분야에 걸쳐 변혁적인 변화를 촉발하는 지속적으로 진화하는 생성적 AI의 풍경은 이러한 발전의 영향을 체계적으로 평가할 필요성을 야기합니다. 이를 위해 우리는 표 III에 자세히 설명된 일련의 기준을 설정하여, 기술적 진보와 연구 초점 영역의 진화하는 패러다임 간의 역동적인 상호작용에 깊이 뿌리를 둔 영향을 정량화하고 분류하는 분석 렌즈로 활용합니다. 우리의 분석 프레임워크는 생성적 AI 연구 영역이 얼마나 재편되고 있는지를 반영하여, 신흥에서 구식에 이르기까지의 그라데이션 척도에 기반을 두고 구축되었습니다. 다섯 가지의 명확한 클래스로 분류함으로써 복잡한 평가를 가능하게 하며, 모든 영역이 동일하게 영향을 받지는 않을 것임을 인정합니다. 이 다층적 접근법은 기술적 혼란의 역사적 패턴과 과학적 탐구의 적응성에 의해 정보를 제공받습니다.
우리 평가 계층 구조의 정점에 있는 'Emerging Direction'은 추측이 아닌 AI 진화의 역사적 연속선에 기반을 둔, 진행 중인 AI 돌파구에 의해 추진되는 미개척 연구의 전망을 포괄합니다. 기술력의 각 증가는 새로운
표 II: 생성적 AI 연구에 대한 영향 분석 기준

과학적 수수께끼와 길들 [315], [316]. '재방향 필요(Areas Requiring Redirection)'는 확립된 연구 분야를 나타내지만, 전략적 전환점에 있으며, 신흥 인공지능(AI) 패러다임을 흡수하고 전통적인 방법론을 전면적으로 개편해야 하는 필요성이 있음을 나타냅니다. 이는 규칙 기반 전문가 시스템에서 적응형 머신 러닝(machine learning) 프레임워크로의 전환과 유사합니다 [315], [317]. '여전히 관련성 있음(Still Relevant)' 분류는 지속적인 과학적 질문에 대응하거나 본질적인 유연성을 통해 인공지능(AI) 혁신의 조류에도 불구하고 여전히 영향을 받지 않는 특정 연구 영역의 끈기를 확인합니다 [317]. 반면, '쓸모없어질 가능성이 있는(Likely to Become Redundant)' 영역은 잠재적 구식화에 직면하여 과학적 정체를 방지하기 위한 전략적 예지와 자원 재배분을 요구합니다 [318]. 마지막으로, '본질적으로 해결 불가(Inherently Unresolvable)' 도전은 인공지능(AI) 연구 내에서 해결이 불가능한 영원한 딜레마를 상기시키는 역할을 하며, 이는 인간 윤리와 문화 다양성의 복잡한 망에 뿌리를 두고 있어, 인공지능(AI) 추구를 인간 가치와 사회적 필수 요소의 해결할 수 없는 태피스트리(tapestry)에 고정시킵니다 [319], [320].
B. 영향 분석 개요(Overview of Impact Analysis)
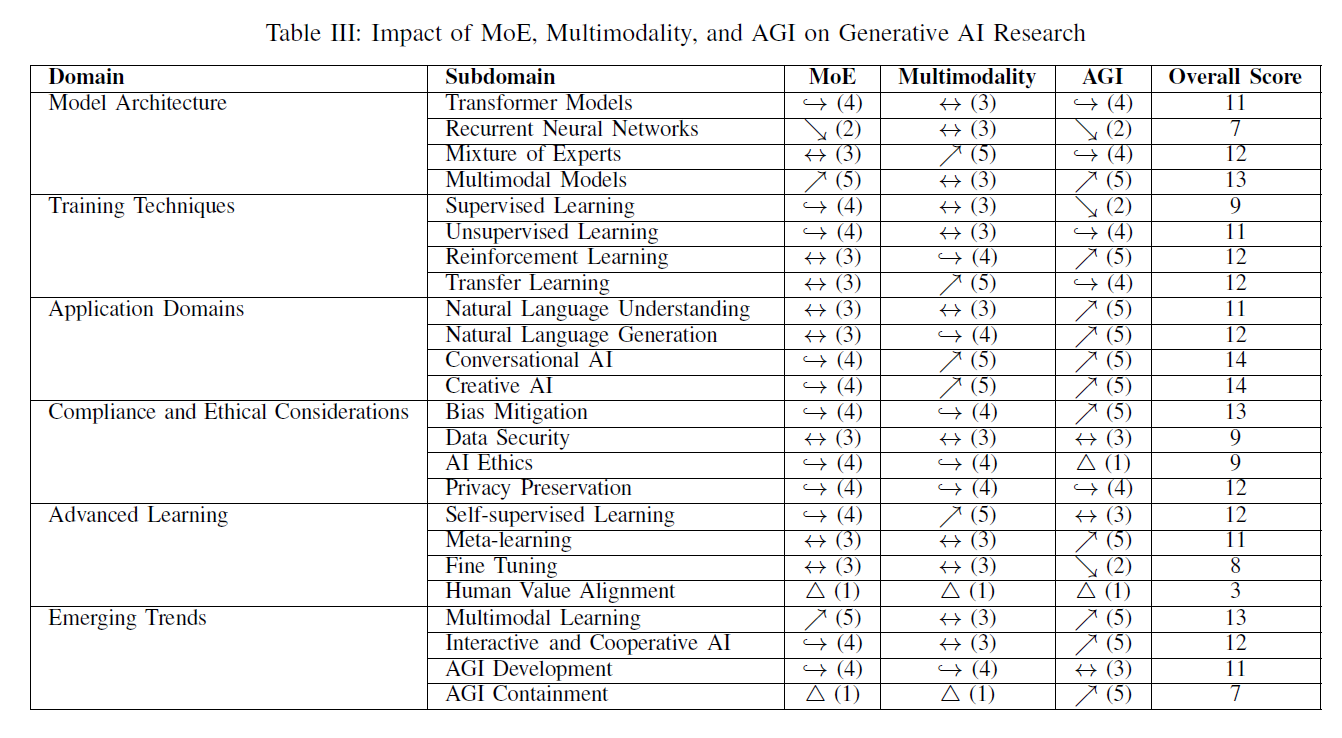
이 소절은 생성적 인공지능(generative AI)의 연구 분류에 대한 영향 분석에 대한 자세한 개요를 제공하며, 특히 MoE, 다중 모드(multimodality), 그리고 AGI의 최근 진전에 초점을 맞추어, 이러한 혁신적 개발이 생성적 인공지능(AI) 연구의 다양한 측면에 미치는 영향을 평가하고자 합니다. 이는 모델 아키텍처에서부터 정교한 학습 방법론에 이르기까지 포함하며, LLM 연구의 다양한 도메인과 하위 도메인에 걸쳐 양적 및 질적 평가를 포함하고, 각 영역이 이러한 기술적 발전의 영향을 어느 정도 받는지에 대한 통찰을 제공합니다. 이 평가는 새로운 연구 방향의 등장, 기존 연구 영역의 재방향 필요성, 특정 방법론의 지속적인 관련성, 그리고 다른 방법론의 잠재적 쓸모없음 등의 요소를 고려하였으며, 표 III에 요약되어 있습니다.
1) 모델 아키텍처에 미치는 영향: 트랜스포머 모델(Transformer Models)은 MoE와 AGI에서 모두 4의 전환 요구도 와 다중 모달성(multimodality)에서 3의 관련성 을 받아 총 점수는 11입니다. 이 모델들은 많은 현재 AI 아키텍처의 기반이 되며, 복잡한 입력 시퀀스를 처리하는 데 여전히 관련성이 있습니다. 그러나 와 의 등장은 더 동적이고 전문화된 아키텍처로의 변화를 나타냅니다. 트랜스포머는 여전히 필수적이지만, 이러한 고급 시스템과 통합되어 성능과 적응성을 향상시키기 위해 진화할 필요가 있습니다.
순환 신경망(Recurrent Neural Networks, RNNs)은 MoE와 AGI 맥락에서 모두 2의 잠재적 중요성 감소 와 다중 모달성에서 여전히 관련성이 있다는 3의 점수를 받아 총 점수는 7입니다. 시퀀스 처리에 효과적이지만, RNN은 장거리 의존성 처리의 한계와 트랜스포머와 같은 새로운 모델에 비해 낮은 효율성으로 인해 도전을 받고 있습니다. 순차적 데이터를 다루는 다중 모달 작업에서 일부 관련성을 유지할 수 있지만, 일반적으로 더 진보된 아키텍처에 의해 가려집니다.
MoE 모델은 자체 개발에서 일관된 3의 관련성 과 다중 모달성에서 5의 점수 를 받았으며, AGI 맥락에서 4의 전환 점수 를 받아 총 점수는 12입니다. 모델은 다양한 데이터 유형을 처리할 수 있는 능력으로 인해 다중 모달 연구의 최전선에 있습니다. AGI를 위해서는 이 모델들이 일반 지능을 나타내는 시스템에 효과적으로 통합되기 위해 조정이 필요하며, 특히 초기 전문화를 넘어서는 분야에서 그러합니다.
다중 모달 모델(Multimodal Models)은 MoE와 AGI 맥락에서 모두 5의 신흥 연구 방향 점수 와 다중 모달성에서 현재 관련성에 대한 3의 점수 를 받아 총 점수는 13입니다. MoE의 통합과 AGI 추구는 다중 모달 모델 연구에 새로운 길을 열고 있습니다. 이러한 발전은 다양한 모달리티에서 정보를 처리하고 통합하는 능력을 향상시키는 데 중요하며, 이는 전문화된 AI 시스템과 일반화된 AI 시스템 모두에 있어 핵심적인 측면입니다.
2) 훈련 기법에 미치는 영향: 지도 학습(Supervised Learning)은 4의 전환 점수 , 다중 모달성에서 3의 관련성 점수 , 그리고 AGI 맥락에서 잠재적 중요성 감소를 나타내는 2의 점수 를 받아 총 점수는 9입니다. 지도 학습은 MoE 프레임워크에 맞게 적응이 필요하지만, 레이블이 지정된 데이터에 의존하는 다중 모달 AI 모델에 여전히 관련성이 있습니다. 그러나 AGI에서 더 자율적인 학습 방법으로의 전환으로 인해, 지도 학습과 전형적으로 연관된 방대한 레이블이 지정된 데이터셋에 대한 의존성이 줄어들 수 있으며, 이는 그 중요성이 감소할 수 있음을 의미합니다.
표 III: MoE, 다중 모달성, AGI가 생성적 AI 연구에 미치는 영향
비지도 학습(Unsupervised Learning)은 MoE와 AGI 맥락에서 모두 4점의 방향 전환 요구 를 받고, 다중 모달성(multimodality)에서 3점의 관련성 유지 를 받아 총 11점을 얻습니다. MoE 아키텍처에서 비지도 학습 방법은 특히 동적 작업 할당을 관리하는 데 있어 조정이 필요할 수 있습니다. 다양한 모달리티에서 라벨이 없는 데이터를 이해하는 것은 여전히 중요합니다. AGI에서는 비지도 학습이 전통적인 기술을 넘어서 더 발전된 자기 발견(self-discovery)과 내재적 학습 메커니즘에 초점을 맞추어 진화할 것으로 예상됩니다.
강화 학습(Reinforcement Learning)은 MoE에서 3점의 여전한 관련성 을 받고, 다중 모달성에서 4점의 방향 전환 요구 를 받으며, AGI에서 5점의 신흥 연구 영역 으로 식별되어 총 12점을 얻습니다. 이 기술은 MoE 모델 구조를 최적화하는 데 계속해서 중요한 역할을 합니다. 다중 모달리티 영역에서는 다양한 모달리티 간의 복잡한 상호작용을 효과적으로 관리하기 위한 전략적 변화가 필요합니다. AGI에서는 강화 학습이 환경에서 학습하는 자율 시스템의 개발에 특히 중요한 영역으로 부상하고 있습니다.
전이 학습(Transfer Learning)은 에서 3점의 일관된 관련성 을 받고, 다중 모달성에서 5점의 신흥 연구 방향 을 받으며, AGI에서 4점의 방향 전환 요구 를 받아 총 12점을 얻습니다. MoE 프레임워크에서는 다양한 전문가 간의 지식을 활용하는 데 여전히 중요합니다. 다중 모달 맥락에서는 다양한 모달리티 간의 학습 전달을 용이하게 함으로써 전이 학습이 점점 더 중요해지고 있습니다. AGI의 진화와 함께 이 기술은 더 넓고 일반화된 지식 응용을 위해 상당한 변화를 겪을 것으로 예상됩니다.
3) 응용 분야에 미치는 영향: 자연어 이해(Natural Language Understanding, NLU)는 MoE와 다중 모달성에서 각각 3점의 안정적인 관련성 을 유지하고, AGI에서 5점의 신흥 방향 을 받아 총 11점을 얻습니다. MoE 모델은 크고 다양한 데이터셋을 처리하는 능력을 통해 NLU의 정밀도와 깊이를 향상시켜 NLU의 관련성을 지지합니다. 다중 모달 AI에서는 다양한 데이터 형식에서 언어를 이해하는 데 있어 NLU가 중요한 구성 요소로 남아 있습니다. AGI의 진보와 함께 NLU는 상당한 확장을 겪을 것으로 예상되며, 더 발전된 인간과 같은 이해와 해석 능력으로 나아갈 것입니다.
자연어 생성(Natural Language Generation, NLG)은 MoE에서 3점의 관련성 유지 를 받고, 다중 모달성에서 4점의 방향 전환 요구 를 받으며, AGI에서 5점의 신흥 연구 영역 으로 식별되어 총 12점을 얻습니다. MoE의 확장성은 NLG를 강화하는 데 중요하며, 다중 모달 맥락에서는 NLG가 다른 모달리티와 효과적으로 조화를 이루기 위한 전략적 조정이 필요할 수 있습니다. AGI가 진화함에 따라 NLG는 특히 인간과 같은 창의성과 적응성을 반영하는 콘텐츠를 생성하는 새로운 연구 분야로 나아갈 것으로 예상됩니다.
대화형 AI는 MoE에서 4점의 재지향 요구 , 다중 모달리티(multimodality)와 AGI에서 각각 5점의 새로운 연구 방향 을 받아 총점 14점을 기록했습니다. MoE는 대화형 AI를 향상시키지만, MoE의 분산된 전문성을 완전히 활용하기 위해서는 전략적인 변화가 필요할 수 있습니다. 다양한 모달리티의 통합은 대화형 AI에 새로운 길을 열어주며, 다양한 감각 데이터를 포함하는 범위를 확장합니다. AGI의 발전은 이 분야에서 혁명적인 진보를 가져올 것으로 예상되며, 더 자율적이고, 맥락을 인식하는, 인간과 같은 상호작용을 위한 길을 마련할 것입니다.
창의적 AI는 MoE에서 4점의 재지향 요구 를 받고, 다중 모달리티와 AGI에서 각각 5점의 새로운 연구 방향 을 받아 총점 14점을 기록했습니다. MoE의 맥락에서 창의적 AI는 MoE의 새로운 콘텐츠 생성 능력을 활용하기 위해 재정렬이 필요할 수 있습니다. 창의적 AI에서 다양한 모달리티의 결합은 흥미로운 새로운 연구 기회를 제공하며, 더 복잡하고 다양한 결과물을 창출할 수 있게 합니다. AGI가 발전함에 따라, 창의적 AI의 능력을 현존하는 경계를 넘어서 확장하고 새로운 창의성의 영역을 탐색할 것으로 기대됩니다.
4) 준수 및 윤리적 고려사항에 미치는 영향: MoE, 다중 모달리티, AGI 맥락에서의 편향 완화는 MoE와 다중 모달리티에서 각각 4점의 재지향 요구 를 받고, AGI에서 5점의 새로운 연구 방향 을 받아 총점 13점을 기록했습니다. 아키텍처는 전문가 네트워크의 다양성으로 인해 편향을 증폭시킬 수 있으므로 편향 완화에 새로운 접근이 요구됩니다. 다중 모달 시스템에서는 이미지와 오디오와 같은 비텍스트 형태의 데이터에서 편향을 해결하기 위한 새로운 전략이 필요합니다. AGI의 광범위한 인지 능력으로 인해 다양한 영역에서 편향을 이해하고 해결하는 포괄적인 접근이 중요한 연구 분야로 부상하고 있습니다.
데이터 보안은 MoE, 다중 모달리티, AGI 전반에 걸쳐 일관된 관련성 을 유지하며 각각 3점씩 총점 9점을 기록했습니다. 데이터 보안의 기본 원칙은 MoE의 발전에도 불구하고 중요하며, 분산된 특성에 맞는 맞춤형 전략이 필요할 수 있습니다. 다중 모달 AI에서는 다양한 데이터 유형의 안전한 처리가 계속해서 매우 중요합니다. AGI의 발전에도 불구하고 데이터 보안의 핵심 원칙은 유지되지만, 보안 조치의 복잡성과 범위는 증가할 가능성이 있습니다.
AI 윤리는 MoE와 다중 모달리티에서 각각 4점의 재지향 요구 를 받고, AGI에서는 근본적으로 해결할 수 없는 도전 에 1점을 받아 총점 9점을 기록했습니다. MoE 모델의 의사결정 과정과 투명성은 윤리적 고려사항의 재평가를 필요로 합니다. 다중 모달 AI에서는 다중 모달 데이터의 해석과 사용에 관한 윤리적 문제, 특히 새로운 접근이 필요합니다. AGI에서의 윤리적 도전은 복잡하며 깊은 철학적 및 사회적 함의를 포함할 것으로 예상되며, 완전히 해결하기 어려울 수 있습니다.
개인정보 보호는 MoE, 멀티모달리티(multimodality), 그리고 AGI에서 모두 4의 중요한 재평가 필요성 을 가지며, 전체 점수는 12입니다. 시스템의 분산된 특성은 여러 전문가들이 처리하는 데이터를 다루기 위한 개인정보 보호 기술의 재평가를 요구합니다. 이미지와 소리와 같은 민감한 데이터를 다루는 멀티모달 AI 시스템은 맞춤형 개인정보 보호 전략이 필요합니다. AGI의 광범위한 데이터 처리 능력으로 인해, 고급이고 아마도 새로운 개인정보 보호 접근법이 요구됩니다.
5) 고급 학습에 미치는 영향: MoE의 맥락에서 자기 주도 학습(self-supervised learning)은 진화하는 구조에 적응할 필요성을 나타내며 4의 점수로 재평가가 필요함을 나타냅니다. 멀티모달리티에서는 5의 점수로 새로운 연구 방향 이 확인되었으며, 이는 텍스트, 이미지, 오디오와 같은 다양한 자율적 데이터 유형의 통합을 제안합니다. AGI에서는 자기 주도 학습이 여전히 관련성이 있음을 나타내며 3의 점수를 받았으며, 시스템의 자율성과 적응성에 기여하지만, 더 복잡한 전략과 통합될 가능성이 높습니다. 전체 영향 점수는 12입니다.
메타 학습(meta-learning)은 MoE와 멀티모달리티에서 일관된 관련성 을 유지하며 3의 점수를 받았으며, 의 동적 특성과 멀티모달 맥락에서 다양한 데이터 유형 및 작업에 빠르게 적응하는 데 잘 맞습니다. AGI에서는 새로운 연구 방향 으로 표시되며 5의 점수를 받았으며, 인간과 같은 적응성과 학습 효율성을 달성하기 위한 새로운 연구를 제안합니다. 메타 학습에 대한 총 점수는 11입니다.
파인 튜닝(fine tuning)은 MoE와 멀티모달리티에서 여전히 관련성이 있음을 나타내며 각각 3의 점수를 받았으며, 사전 훈련된 모델을 특정 작업에 맞게 조정하고 멀티모달 모델을 맞춤화하는 데 필수적입니다. 그러나 AGI에서는 전통적인 파인 튜닝 과정에 대한 필요성을 줄이는 광범위한 도메인에 걸쳐 자율적으로 이해하고 학습하는 시스템을 개발하는 AGI의 목표로 인해 불필요해질 가능성이 있으며 2의 점수를 받았습니다. 파인 튜닝의 전체 영향 점수는 8입니다.
AI를 인간의 가치와 일치시키는 것은 MoE, 멀티모달리티, 그리고 AGI 모든 맥락에서 본질적으로 해결할 수 없는 도전과제 를 가지며 1의 점수를 받았습니다. 이는 MoE 모델이 다루는 작업의 복잡성과 다양성, 멀티모달 AI에서 다양한 데이터 유형의 통합, 그리고 AGI에 의해 포괄되는 광범위한 인지 능력을 반영합니다. 이러한 요소들은 AI를 인간의 가치와 일치시키기 위한 지속적인 중대한 도전에 기여하며, 총 점수는 3입니다.
6) 신흥 트렌드에 미치는 영향: 멀티모달 학습(multimodal learning)은 MoE와 AGI 맥락에서 모두 5의 점수로 새로운 연구 방향 으로 표시되었으며, 텍스트, 이미지, 오디오와 같은 다양한 데이터 유형을 통합하는 능력을 반영합니다. 이 통합은 MoE에서 특화된 작업과 AGI에서 다양한 형태의 데이터 처리에 중요합니다. 멀티모달리티 영역에서는 핵심 측면 으로 남아 있으며 3의 점수를 받았으며, 지속적인 멀티모달 AI 개발에 필수적입니다. 전체 영향 점수는 13입니다.
대화형 및 협력적 AI는 MoE에서 재지향이 필요하며 점수는 4입니다. 왜냐하면 MoE 모델들이 더 넓은 응용을 위해 더 많은 상호작용 요소를 포함하도록 적응하기 때문입니다. 멀티모달리티(multimodality)에서 상호작용과 협력은 로보틱스(robotics)와 가상 비서(virtual assistants)와 같은 분야에서 중요하게 계속되고 있으며 점수는 3입니다. AGI의 진화는 상호작용 AI에서 중요한 발전을 포함하며, 이는 점수 5로 나타나는 신흥 연구 분야로 표시됩니다. 이 트렌드의 총 점수는 12입니다.
AGI의 발전은 MoE와 멀티모달리티에서 재지향이 필요하며 각각 점수는 4입니다. 이는 더 통합되고 복잡한 시스템이 필요하다는 것을 나타냅니다. AGI는 자체 분야의 최전선에 남아 있으며 점수는 3이며, 각 돌파구는 직접적으로 그 진전에 영향을 미칩니다. AGI 발전의 전체 영향 점수는 11입니다.
AGI 격리는 MoE와 멀티모달리티에서 해결할 필요가 없는 도전으로 식별되며 점수는 1입니다. 왜냐하면 이러한 영역들이 AGI와 관련된 자율성과 복잡성의 수준에 도달할 것으로 예상되지 않기 때문입니다. 그러나 AGI가 진행됨에 따라, 효과적인 격리 전략에 대한 필요성이 신흥적으로 표시되며 점수는 5입니다. 이는 안전하고 통제된 AI 배치를 보장하는 중요성을 강조합니다. 총 영향 점수는 7입니다.
VIII. 생성적 AI에서의 신흥 연구 우선순위
우리가 사용 가능한 AGI의 실현에 한 걸음 더 가까워지는 새로운 시대의 전환점에 접근할 가능성이 높아짐에 따라, 생성적 AI의 연구 환경은 중요한 변화를 겪고 있습니다.
A. MoE에서의 신흥 연구 우선순위
MoE 분야는 두 가지 중요한 영역에 점점 더 집중하고 있습니다:
- 모델 아키텍처에서의 멀티모달 모델: MoE와 AGI의 통합은 멀티모달 모델 연구에 새로운 길을 열고 있습니다. 이러한 발전은 다양한 모달리티로부터 정보를 처리하고 종합하는 능력을 향상시키고 있으며, 이는 전문화된 및 일반화된 AI 시스템 모두에게 중요합니다.
- 신흥 트렌드에서의 멀티모달 학습: MoE는 텍스트, 이미지, 오디오와 같은 다양한 데이터 유형을 통합하는 멀티모달 학습의 최전선에 있습니다. 이 트렌드는 분야의 향상에 직접적인 영향을 미치고 있습니다.
또한, AI 연구의 자금 조달 추세와 투자 패턴 분석은 MoE에서 멀티모달 모델과 같은 영역으로 상당한 변화를 나타낼 수 있습니다. 복잡한 데이터 처리와 자율 시스템을 포함하는 분야로의 증가된 자본 흐름을 특징으로 하는 이 트렌드는 미래 연구 우선순위의 방향을 형성하고 있습니다. 이는 생성적 AI의 잠재력에 대한 증가하는 관심과 투자를 강조하며, 학계 및 산업 주도의 이니셔티브에 모두 영향을 미치고 있습니다.
B. 멀티모달리티에서의 신흥 연구 우선순위
멀티모달리티 영역에서는 여러 영역이 신흥 연구 우선순위로 식별되고 있습니다:
- 모델 아키텍처에서의 MoE(Mixture of Experts): 다양한 데이터 유형을 다루는 멀티모달(multimodal) 맥락에서 MoE 모델이 점점 더 중요해지고 있습니다.
- 트레이닝 기법에서의 전이 학습(Transfer Learning): 다른 모달리티 간의 학습에 특히 중요한 연구 방향으로 부상하고 있는 전이 학습입니다.
- 응용 분야에서의 대화형 AI(Conversational AI) 및 창의적 AI(Creative AI): 대화형 AI와 창의적 AI 모두 시각적, 청각적 및 기타 감각 데이터 통합을 포함하는 멀티모달 맥락에서 확장되고 있습니다.
- 고급 학습에서의 자기 감독 학습(Self-Supervised Learning): 다양한 데이터 유형을 자율적으로 통합하는 데 중점을 둔 자기 감독 학습의 새로운 연구 방향이 등장하고 있습니다.
또한, 특히 멀티모달 맥락에서 생성적 AI(generative AI)의 부상은 교육 과정과 기술 개발에 상당한 영향을 미칠 수 있습니다. 멀티모달 AI 기술에 중점을 둔 포괄적인 AI 리터러시를 포함하여 학술 프로그램을 업데이트할 필요성이 증가하고 있습니다. 이러한 교육의 진화는 미래의 전문가들이 AI의 발전을 효과적으로 활용하고 그 복잡성과 혁신을 탐색하는 데 필요한 기술을 갖추도록 준비하는 것을 목표로 합니다.
C. AGI에서의 긴급 연구 우선 순위
AGI(Artificial General Intelligence) 분야는 여러 영역에서 연구 우선 순위가 급증하고 있습니다:
- 모델 아키텍처에서의 멀티모달 모델(Multimodal Models): MoE와 마찬가지로, 멀티모달 모델은 AGI에서 중요하며, 더 깊고 미묘한 이해를 가능하게 합니다.
- 트레이닝 기법에서의 강화 학습(Reinforcement Learning): AGI에서 중요한 영역으로 부상하고 있는 강화 학습은 환경에서 학습하는 자율 시스템의 개발에 중점을 둡니다.
- 응용 분야: AGI는 자연어 이해 및 생성, 대화형 AI, 창의적 AI의 경계를 확장하고 있으며, 인간과 같은 이해와 창의성에 중점을 둡니다.
- 준수 및 윤리적 고려 사항에서의 편향 완화(Bias Mitigation): AGI의 다양한 분야에서 편향을 해결하기 위한 포괄적 접근에 중점을 둔 편향 완화의 새로운 방향이 나타나고 있습니다.
- 고급 학습에서의 메타 학습(Meta-Learning): 인간과 같은 적응성을 추구하는 AGI는 메타 학습에 대한 새로운 연구로 이어지고 있습니다.
- 신흥 트렌드: 멀티모달 학습, 상호작용 및 협력적 AI, AGI 제어 전략은 AGI가 진행됨에 따라 중요한 연구 영역이 되고 있습니다.
AGI의 이러한 발전에 따라, AI 연구 자금 및 투자 패턴에서 눈에 띄는 경향이 분명해지고 있습니다. 자연어 이해 및 생성, 자율 시스템과 같은 영역에서 특히 AGI의 프로젝트와 연구를 지원하는 경향이 있습니다. 이 자금 조달 추세는 AGI의 능력에 대한 관심이 증가하는 것뿐만 아니라 미래 연구의 궤적을 지시하며, 학문적 탐구와 산업 주도 프로젝트 모두를 형성합니다.
IX. 생성적 AI 기술의 실용적 함의 및 한계
MoE, 멀티모달, AGI를 포함하는 생성적 AI 기술은 독특한 계산적 도전을 제시합니다. 이 섹션에서는 이러한 고급 AI 모델에 내재된 처리 능력 요구 사항, 메모리 사용 및 확장성 문제를 탐구합니다.
A. 생성적 AI 기술의 계산 복잡성 및 실제 응용
1) 계산 복잡성: MoE, 멀티모달, AGI를 포함하는 생성적 AI 기술은 독특한 계산적 도전을 제시합니다. 이 섹션에서는 이러한 고급 AI 모델에 내재된 처리 능력 요구 사항, 메모리 사용 및 확장성 문제를 탐구합니다.
- 처리 성능 요구사항: MoE(Model of Expertise) 구조와 AGI(Artificial General Intelligence) 시스템을 포함한 고급 생성 AI(Generative AI) 모델은 상당한 처리 성능을 요구합니다 [321]. 특히 복잡한 계산과 멀티모달 AI(Multimodal AI) 응용 프로그램에서 흔히 볼 수 있는 큰 데이터셋을 다룰 때, GPU(Graphics Processing Unit)와 TPU(Tensor Processing Unit)에 대한 수요가 두드러집니다.
- AI 모델링에서의 메모리 사용: 대규모 AI 모델, 특히 멀티모달과 AGI 시스템을 GPU에서 실행할 때, 상당한 GPU와 VRAM(Video RAM) 요구사항에 대한 중요한 도전 과제가 있습니다. 컴퓨터 RAM과 달리 VRAM은 많은 플랫폼에서 쉽게 확장할 수 없어 상당한 제약을 초래합니다. 따라서 GPU와 VRAM 최적화 및 효율적인 모델 스케일링 전략을 개발하는 것이 이러한 AI 기술의 실용적인 배치에 매우 중요합니다.
- AI 배치에서의 확장성과 효율성: 생성 AI에서, 특히 MoE와 AGI 맥락에서 확장성 문제를 해결하는 것은 부하 관리와 병렬 처리 기술을 최적화하는 것을 포함합니다. 이는 건강 관리, 금융, 교육과 같은 분야에서의 실용적인 응용을 위해 필수적입니다.
2) 생성 AI 기술의 실제 세계 응용 예시: 생성 AI 모델의 실제 시나리오에서의 응용은 다양한 분야에서 그들의 변혁적 잠재력과 도전을 보여줍니다.
- 건강 관리: 건강 관리 분야에서 생성 AI는 진단 영상과 개인 맞춤 의학의 발전을 촉진하지만, 데이터 개인 정보 보호와 민감한 건강 정보의 잠재적 오용에 대한 상당한 우려를 불러일으킵니다 [322].
- 금융: 금융에서 AI를 사기 탐지와 알고리즘 거래에 사용하는 것은 그 효율성과 정확성을 강조하지만, 동시에 특히 투명성과 책임성이 결여될 수 있는 자동화된 의사결정 과정에서 윤리적 우려를 제기합니다 [323].
- 교육: 생성 AI가 개인화된 학습 경험을 만드는 데 있어서의 역할은 교육 접근성과 맞춤형 지도 측면에서 엄청난 이점을 제공합니다. 그러나 기술에 대한 공정한 접근, AI 생성 콘텐츠(AIGC)의 잠재적 편향, 그리고 인간 교육자에 대한 수요 감소 등의 도전을 제기합니다. 또한, 전통적인 교수법과 교육자의 역할을 약화시킬 수 있다고 우려하는 교육자들에 대한 우려가 커지고 있습니다.
B. 생성 AI 기술의 상업적 타당성과 산업 솔루션
1) 시장 준비 상태: 생성 AI 기술의 시장 준비 상태를 평가하는 것은 비용, 접근성, 배치 도전 과제 및 사용자 채택 추세를 분석하는 것을 포함합니다.
- 비용 분석: MoE, 멀티모달, AGI를 포함한 생성 AI 배치의 재정적 측면은 시장 채택에 중요합니다.
- 접근성 및 배치: 이 기술들을 기존 시스템에 통합하고 필요한 기술 전문성은 그 채택에 영향을 미치는 주요 요소입니다.
- 사용자 채택 추세: 현재 채택 패턴을 이해하는 것은 시장 수용과 사용자 신뢰 및 인식된 이점의 역할에 대한 통찰을 제공합니다.
2) 기존 산업 솔루션: 생성 AI는 혁신적인 솔루션을 제공하고 시장 역학을 변화시키면서 다양한 산업을 재편하고 있습니다.
- 부문별 배치: 디지털 콘텐츠 생성에서 프로세스 간소화에 이르기까지 생성 AI의 다양한 응용은 원작성과 지적 재산권에 대한 질문도 제기합니다.
- 시장 역학에 미치는 영향: 전통적인 산업 구조에 대한 AI 솔루션의 영향과 새로운 비즈니스 모델의 도입은 중요한 고려 사항입니다.
- 도전과 제약: 확장성, 데이터 관리 복잡성, 개인 정보 보호 우려, 윤리적 함의와 같은 제한 사항을 해결하는 것은 견고한 거버넌스 프레임워크를 위해 필수적입니다.
C. 생성 AI 기술의 한계와 미래 방향
1) 기술적 한계: 생성 AI 모델의 기술적 한계를 식별하고 해결하는 것은 그들의 발전과 신뢰성을 위해 중요합니다.
- 맥락 이해(Contextual Understanding): 특히 자연어 처리(natural language processing)와 이미지 인식(image recognition)에서 AI가 맥락을 이해하고 해석하는 능력을 향상시키는 것은 개선이 필요한 주요 영역입니다.
- 모호한 데이터 처리(Handling Ambiguous Data): 모호하거나 불완전한 데이터 세트를 처리하기 위한 더 나은 알고리즘을 개발하는 것은 의사결정의 정확성과 신뢰성에 필수적입니다.
- 인간 판단의 탐색(Navigating Human Judgment): 정책과 절차를 해석하는 데 있어 생성적 AI(generative AI)의 정확성에도 불구하고, 인간 판단을 대체하는 데 있어 그 영향은 제한적입니다. 이는 특히 법적 및 정치적 맥락에서 의사결정자들이 AIGC를 선택적으로 사용할 수 있어 편향된 결과를 초래할 수 있기 때문에 사실입니다. 따라서 이러한 시나리오에서 생성적 AI의 효과는 현실적으로 평가되어야 합니다.
2) 생성적 AI의 실용성을 향상시키기 위한 미래 연구 방향: 생성적 AI의 미래 연구는 현재의 한계를 해결하고 실용적인 응용 분야를 확장하는 데 중점을 두어야 합니다.
- 개선된 맥락 이해(Improved Contextual Understanding): 연구는 특히 복잡한 자연어 및 이미지 처리 작업에서 더 나은 맥락 인식을 가진 모델을 개발하는 것을 목표로 해야 합니다.
- 모호한 데이터의 강력한 처리(Robust Handling of Ambiguous Data): 모호한 데이터를 효과적으로 처리하는 기술을 조사하는 것은 AI 모델의 의사결정 능력을 발전시키는 데 중요합니다.
- 법적 및 정치적 영역에서의 AIGC의 윤리적 통합(Ethical Integration of AIGC in Legal and Political Arenas): 미래 연구는 법적 및 정치적 의사결정 과정에 AI 생성 콘텐츠를 윤리적으로 통합하는 데 중점을 두어야 하며, 이는 AIGC를 지원적 역할로 활용하는 프레임워크를 개발하는 것을 포함합니다. 이는 인간 판단을 강화하고 투명성과 공정성에 기여하도록 보장해야 합니다 [324]. 중요하게, 연구자들은 AI의 내재된 편향과 한계 [324]뿐만 아니라 인간의 오류 가능성, 윤리적 복잡성, 그리고 이러한 영역에서의 가능한 부패를 고려해야 합니다.
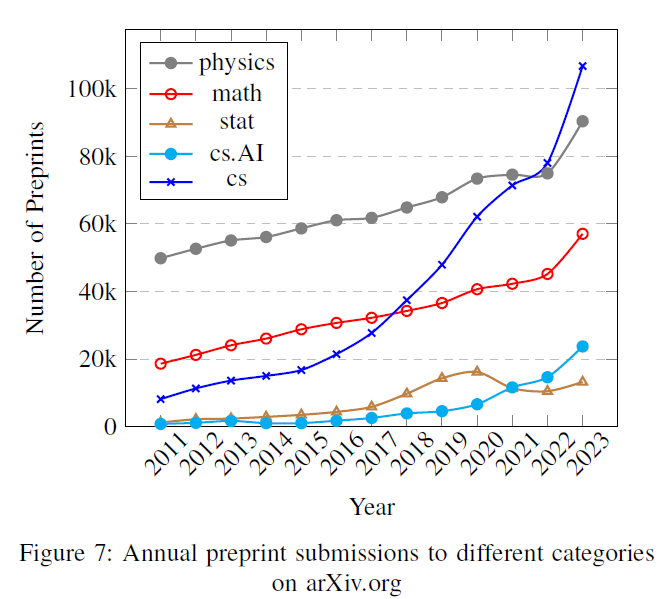
그림 7: arXiv.org의 다양한 카테고리에 대한 연간 프리프린트(preprint) 제출 현황
X. 학문 분야별 생성적 AI의 프리프린트에 대한 영향
이 섹션에서 자세히 설명된 도전 과제들은 생성 AI(generative AI) 내의 지식 영역과 직접적으로 관련이 있는 것은 아니지만, 특히 ChatGPT의 상업화로 인한 생성 AI의 성공에 의해 촉발되었습니다. AI 분야의 사전 인쇄물(preprints)의 증가(Fig. 7), 특히 arXiv와 같은 플랫폼에서의 cs.AI 카테고리는 신중한 고려와 전략적 대응이 필요한 학술적 도전 과제들을 제시하고 있습니다. ChatGPT와 같은 도구의 빠른 상업화와 채택은 상업화된 지 단 한 해 만에 Google Scholar에서 "ChatGPT"를 언급하는 55,700개 이상의 항목으로 입증되었으며, 이는 분야가 발전하는 가속화된 속도를 예시합니다. 이러한 빠른 발전은 전통적인 동료 평가(peer-review) 과정에서는 반영되지 않으며, 이 과정은 상당히 느립니다. 동료 평가 과정은 이제 ChatGPT(또는 다른 LLMs)로 생성되었거나, 이러한 LLMs에 의해 글쓰기 과정이 상당히 가속화된 원고들로 인해 압도되고 있는 것으로 보입니다. 이는 학술 커뮤니케이션의 병목 현상에 기여하고 있습니다 [325], [326]. 이 상황은 컴퓨터 과학 외의 다른 학문 분야의 많은 저널들도 더 긴 리뷰 시간과 더 높은 데스크 거절률(desk rejections)을 경험하고 있다는 사실에 의해 더욱 복잡해집니다. 또한, ChatGPT와 같은 도구를 사용하여 생성되었거나, 현저하게 가속화된 원고와 사전 인쇄물의 번성하는 추세는 컴퓨터 과학을 넘어 다양한 학문 분야로 확장되고 있습니다. 이 추세는 전통적인 동료 평가 과정과 번성하는 사전 인쇄물 생태계를 압도할 수 있는 잠재적인 도전 과제를 제시하며, 항상 확립된 학술 기준을 준수하지 않을 수 있는 작업의 양으로 인해 발생합니다.
사전 인쇄물의 엄청난 양은 연구를 선택하고 검토하는 작업을 매우 요구하는 것으로 만들었습니다. 현재의 연구 시대에서, 과학 문헌의 탐색은 지식이 계속해서 기하급수적으로 확장되고 전파되는 동안 점점 더 복잡해지고 있으며, 동시에 이 방대한 문헌을 정제하려는 통합적인 연구 노력이 더 작은 핵심 기여들을 식별하고 이해하려고 시도하고 있습니다 [327]. 따라서 다양한 분야에서 학술 문헌의 빠른 확장은 점점 더 방대해지는 지식의 본체에 대한 증거 종합을 수행하려는 연구자들에게 상당한 도전을 제시합니다 [328]. 또한, 출판량의 폭발은 문헌 검토와 조사에 대한 독특한 도전을 제기하며, 여기서 수동으로 선택하고 이해하며 비판적으로 평가하는 인간의 능력이 점점 더 긴장되고 있으며, 포괄적인 지식 풍경을 종합하는 데에 있어서 격차를 초래할 수 있습니다. 결과의 재현은 이론적으로 가능하지만, 기술적 전문 지식, 계산 자원의 부족 또는 독점 데이터셋에 대한 접근의 부족과 같은 실제 제약 조건은 엄격한 평가를 방해합니다. 이는 우려되는 상황이며, 사전 인쇄물 연구를 철저히 평가할 수 없다는 것은 과학적 신뢰성과 타당성의 기반을 약화시킵니다. 더욱이, 학문적 엄격함의 기초인 동료 평가 시스템은 더욱 압도될 위험에 처해 있습니다 [325], [329]. 잠재적인 결과는 중대하며, 검증되지 않은 사전 인쇄물이 과학 커뮤니티 내부와 외부에서 편견이나 오류를 지속적으로 전파할 수 있습니다. 출판된 기사에 대한 것과 유사한 확립된 철회 메커니즘이 사전 인쇄물에는 없는 것은 결함이 있는 연구의 지속적인 전파 위험을 증가시킵니다.
학계는 긴급하고 신중한 논의가 필요한 기로에 서 있으며, 이는 "혼돈"이라는 새로운 상황을 탐색하는 것입니다. 이 상황은 주소하지 않으면 제어 불가능한 상태로 빠질 위험이 있습니다. 이러한 맥락에서, 동료 평가(peer review)의 역할은 더욱 중요해지고 있습니다. 왜냐하면 이것은 품질과 타당성을 위한 중요한 검사 지점으로서, AI 연구의 빠른 생산이 과학적 정확성과 관련성에 대해 철저히 연구되도록 보장하기 때문입니다. 그러나, 전통적인 동료 평가의 현재 운영 방식은 주로 AI 테마 연구와 생성 AI(Generative-AI) 가속화된 연구 제출의 지수적 성장을 따라잡을 수 없는 능력 때문에 지속 가능하지 않은 것으로 보입니다. 또한 점점 더 전문화되는 신흥 AI 주제들 [325], [326]의 특성 때문에 그렇습니다. 이 상황은 한정된 숙련된 리뷰어 풀로 인해 지연, 잠재적 편견, 그리고 학술 커뮤니티에 대한 부담을 초래합니다. 이 현실은 AI의 빠른 발전과 발맞춰 갈 수 있는 동료 평가와 연구 전파의 새로운 패러다임을 탐색할 것을 요구합니다. 커뮤니티 주도 검증 과정, 강화된 재현성 검사, 그리고 출판 후 검토 및 수정을 위한 동적 프레임워크와 같은 혁신적인 모델이 필요할 수 있습니다. 자동화 도구와 AI 보조 리뷰 프로세스를 통합하는 노력도 인간 리뷰어의 부담을 줄이기 위해 탐색될 수 있습니다.
이 빠르게 변화하는 환경에서, 전통적인 동료 평가 시스템과 번성하는 프리프린트(preprint) 생태계 사이의 융합을 상상해보세요. 이것은 프리프린트가 커뮤니티 기반 리뷰를 거치는 하이브리드 모델(Fig. 8)을 만드는 것을 포함할 수 있으며, 여기서 학계의 집단 전문 지식과 빠른 피드백을 활용합니다. 이는 제품 리뷰 웹사이트와 트위터(Twitter) [330]와 유사합니다. 이 접근법은 초기 검증의 레이어를 제공할 수 있으며, 제한된 수의 동료 평가자들이 간과할 수 있는 문제에 대한 추가적인 통찰력을 제공할 수 있습니다. 편집장(Editors-in-Chief, EICs)은 커뮤니티 기반 리뷰에서 기사에 대한 주요 비판과 제안을 고려할 수 있으며, 이를 통해 더욱
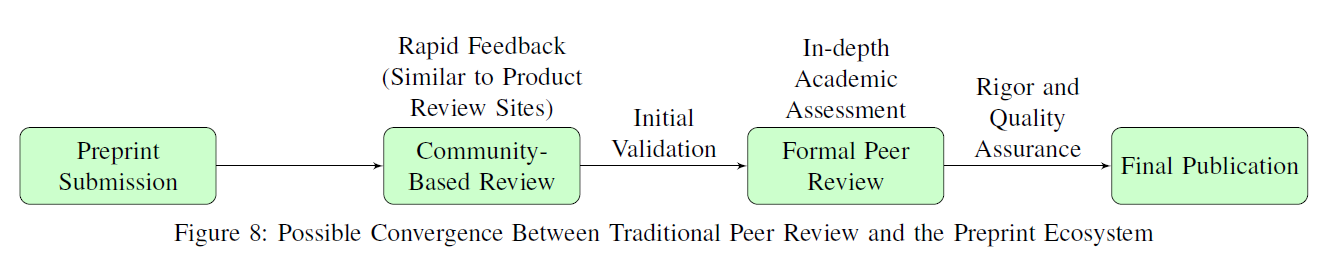
그림 8: 전통적인 동료 평가와 프리프린트 생태계 사이의 가능한 융합
철저하고 다양한 평가를 보장합니다. 이후에 더 정식의 동료 평가 과정은 이러한 프리프린트를 학문적 엄격함과 품질 보증을 위해 정제하고 승인할 수 있습니다. 이 하이브리드 모델은 강력한 기술적 지원을 요구할 것이며, 초기 스크리닝과 적합한 리뷰어 식별을 돕기 위해 AI와 머신 러닝(machine learning) 도구를 활용할 수 있습니다. 목표는 빠른 전파에서 검증된 출판까지의 원활한 연속체를 구축하는 것이며, 이를 통해 프리프린트의 속도와 동료 평가된 연구의 신뢰성을 모두 보장합니다. 프리프린트의 이점을 활용하는 균형 잡힌 접근 방식이 필요합니다. 예를 들어, 연구 결과의 빠른 전파와 오픈 액세스(open access) 등의 이점을 활용하면서 단점을 완화해야 합니다. 새로운 인프라와 규범의 개발은 학계를 생성 AI 시대의 과학 연구의 무결성과 신뢰성을 유지하는 지속 가능한 모델로 이끄는 데 중요할 수 있습니다.
XI. 결론
이 로드맵 조사는 생성적 AI(Generative AI) 연구의 변혁적 추세를 탐구하며, 특히 와 같은 추측된 발전과 AGI(Artificial General Intelligence)로의 진보적인 발걸음에 중점을 두고 있습니다. 우리의 분석은 MoE(Mixture of Experts), 다중 모달 학습(multimodal learning), 그리고 AGI 추구와 같은 혁신에 의해 주도되는 중요한 패러다임 변화를 강조합니다. 이러한 발전은 AI 시스템이 추론, 문맥 이해, 창의적 문제 해결 능력을 크게 확장할 수 있는 미래를 시사합니다. 이 연구는 AI가 전 세계적인 공평성과 정의에 기여하거나 방해할 수 있는 이중적 잠재력을 반영합니다. AI 혜택의 공정한 분배와 의사결정 과정에서의 역할은 공정성과 포괄성에 대한 중요한 질문을 제기합니다. 사회 구조에 AI를 신중하게 통합하여 정의를 강화하고 격차를 줄이는 것이 필수적입니다. 이러한 발전에도 불구하고, 여전히 많은 미해결 질문과 연구 공백이 남아 있습니다. 이러한 문제에는 인간의 가치와 사회적 규범과의 윤리적 조화를 보장하는 고급 AI 시스템의 윤리적 정렬이 포함되며, 이는 그들의 증가하는 자율성에 의해 복잡해집니다. 다양한 환경에서 AGI 시스템의 안전성과 견고성도 중요한 연구 공백으로 남아 있습니다. 이러한 도전을 해결하기 위해서는 윤리적, 사회적, 철학적 관점을 포함하는 다학제적 접근이 필요합니다.
우리의 조사는 AI의 미래 다학제 연구 분야를 강조하며, 윤리적, 사회적, 기술적 관점의 통합을 강조합니다. 이러한 접근은 기술 발전과 사회적 필요 사이의 격차를 메우는 협력적 연구를 촉진하며, AI 개발이 인간의 가치와 전 세계 복지와 일치하도록 보장합니다. MoE, 다중 모달, 그리고 AGI가 생성적 AI를 재구성하는 데 중요한 역할을 하고 있으며, 그 발전은 모델 성능과 다재다능함을 향상시킬 수 있고, 윤리적 AI 정렬과 AGI와 같은 분야에서의 미래 연구를 위한 길을 열 수 있습니다. 우리가 나아가면서, AI 발전과 인간의 창의성 사이의 균형은 단순한 목표가 아니라 필수적이며, AI가 우리의 혁신 능력과 복잡한 도전을 해결하는 능력을 증폭시키는 보완적인 힘으로서의 역할을 보장합니다. 우리의 책임은 이러한 발전을 인간 경험을 풍부하게 하고, 기술적 진보를 윤리적 기준과 사회적 복지와 일치시키는 방향으로 안내하는 것입니다.
면책 조항(DISCLAIMER)
저자들은 이해 상충(conflict of interest)이 없음을 선언합니다.
약어(ABBREVIATIONS)
| AGI | 인공 일반 지능(Artificial General Intelligence) |
|---|---|
| AI | 인공 지능(Artificial Intelligence) |
| AIGC | AI 생성 콘텐츠(AI-generated content) |
| BERT | 양방향 인코더 표현(Bidirectional Encoder Representations from Transformers) |
| CCPA | 캘리포니아 소비자 개인정보 보호법(California Consumer Privacy Act) |
| DQN | 딥 Q-네트워크(Deep Q-Networks) |
| EU | 유럽 연합(European Union) |
| GAN | 생성적 적대 신경망(Generative Adversarial Network) |
| GDPR | 일반 데이터 보호 규정(General Data Protection Regulation) |
| GPT | 생성적 사전 훈련 변환기(Generative Pre-trained Transformers) |
| GPU | 그래픽 처리 장치(Graphics Processing Unit) |
| LIDAR | 라이다(Light Detection and Ranging) |
| LLM | 대규모 언어 모델(Large Language Model) |
| LSTM | 장단기 기억(Long Short-Term Memory) |
| MCTS | 몬테카를로 트리 탐색(Monte Carlo Tree Search) |
| ML | 기계 학습(Machine Learning) |
| MoE | 전문가 혼합(Mixture of Experts) |
| NLG | 자연어 생성(Natural Language Generation) |
| NLP | 자연어 처리(Natural Language Processing) |
| NLU | 자연어 이해(Natural Language Understanding) |
| NN | 신경망(Neural Network) |
| PPO | 근접 정책 최적화(Proximal Policy Optimization) |
| RNNs | 순환 신경망(Recurrent Neural Networks) |
| VNN | 가치 신경망(Value Neural Network) |
| VRAM | 비디오 랜덤 액세스 메모리(Video Random Access Memory) |
참고 문헌(REFERENCES)
