논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 600토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
고해상도 이미지 합성을 위한 잠재 확산 모델(Latent Diffusion Models)
Robin Rombach Andreas Blattmann Dominik Lorenz Patrick Esser Björn Ommer
뮌헨 대학교(Ludwig Maximilian University of Munich) & 하이델베르크 대학교(IWR, Heidelberg University), 독일 Runway ML
https://github.com/CompVis/latent-diffusion
초록(Abstract)
노이즈 제거 오토인코더(denoising autoencoders)의 순차적 적용을 통해 이미지 형성 과정을 분해함으로써, 확산 모델(DMs)은 이미지 데이터 및 그 이상에서 최첨단 합성 결과를 달성합니다. 또한, 이들의 수식은 재학습 없이 이미지 생성 과정을 제어하는 메커니즘을 가능하게 합니다. 그러나 이 모델들은 일반적으로 픽셀 공간에서 직접 작동하기 때문에, 강력한 DMs의 최적화는 수백 GPU 일을 소모하며, 순차적 평가로 인해 추론이 비용이 많이 듭니다. 제한된 계산 자원에서 DM 학습을 가능하게 하면서 그들의 품질과 유연성을 유지하기 위해, 우리는 강력한 사전 학습된 오토인코더(autoencoders)의 잠재 공간(latent space)에서 그들을 적용합니다. 이전 연구와 달리, 이러한 표현에서 확산 모델을 학습하는 것은 복잡성 감소와 세부 사항 보존 사이의 거의 최적의 지점에 처음으로 도달할 수 있게 하여, 시각적 충실도를 크게 향상시킵니다. 모델 아키텍처에 교차 주의(cross-attention) 계층을 도입함으로써, 우리는 확산 모델을 텍스트나 바운딩 박스(bounding boxes)와 같은 일반적인 조건 입력을 위한 강력하고 유연한 생성기로 변환하고, 고해상도 합성이 합성 방식으로 가능하게 됩니다. 우리의 잠재 확산 모델(LDMs)은 이미지 인페인팅(image inpainting)과 클래스 조건부 이미지 합성(class-conditional image synthesis)에 대해 새로운 최첨단 점수를 달성하고, 텍스트-이미지 합성(text-to-image synthesis), 무조건적 이미지 생성(unconditional image generation) 및 초고해상도(super-resolution)를 포함한 다양한 작업에서 매우 경쟁력 있는 성능을 보이면서, 픽셀 기반 DMs에 비해 계산 요구 사항을 크게 줄입니다.
1. 서론(Introduction)
이미지 합성은 최근 가장 눈부신 발전을 이룬 컴퓨터 비전 분야 중 하나이지만, 동시에 가장 큰 계산 요구를 가진 분야 중 하나입니다. 특히 고해상도의 복잡한 자연 장면의 합성은 현재 우도 기반 모델(likelihood-based models)을 확장하여 지배하고 있으며, 이는 자기회귀(AR) 트랜스포머(transformers)에서 수십억 개의 매개변수를 포함할 수 있습니다[66,67]. 반면에, GANs 의 유망한 결과는 그들의 적대적 학습 절차(adversarial learning procedure)가 복잡하고 다중 모드(multi-modal) 분포를 모델링하는 데 쉽게 확장되지 않기 때문에, 비교적 변동성이 제한된 데이터에 대부분 국한되어 있음이 밝혀졌습니다. 최근에, 노이즈 제거 오토인코더의 계층 구조로 구축된 확산 모델[82]은 인상적인[^0] 결과를 달성했다고 보여주었습니다.

그림 1. 공격적인 다운샘플링을 줄임으로써 달성 가능한 품질의 상한을 높이기. 확산 모델(diffusion models)은 공간 데이터에 대한 우수한 유도 편향(inductive biases)을 제공하기 때문에, 관련 생성 모델들이 잠재 공간(latent space)에서 사용하는 무거운 공간 다운샘플링이 필요하지 않지만, 적절한 자동인코딩 모델(autoencoding models)을 통해 여전히 데이터의 차원을 크게 줄일 수 있습니다, 3절을 참조하세요. 이미지는 DIV2K [1] 검증 세트에서 가져온 것이며, px에서 평가되었습니다. 우리는 공간 다운샘플링 인자를 로 표시합니다. 재구성 FID(Fr\'echet Inception Distance) [29]와 PSNR(Peak Signal-to-Noise Ratio)은 ImageNet-val [12]에서 계산되었습니다; 또한 표 8을 참조하세요.
이미지 합성 [30,85] 및 그 이상 [7,45,48,57]에서의 결과는 최신 기술을 정의하며, 클래스 조건부 이미지 합성 [15,31]과 초해상도 [72]에서도 마찬가지입니다. 더욱이, 조건이 없는 DMs(unconditional DMs)도 인페인팅(inpainting)과 컬러라이제이션(colorization) [85] 또는 스트로크 기반 합성(stroke-based synthesis) [53]과 같은 작업에 쉽게 적용될 수 있습니다. 이는 다른 유형의 생성 모델들 [19,46,69]과 대조됩니다. DMs는 가능성 기반 모델(likelihood-based models)이기 때문에, GANs처럼 모드 붕괴(mode-collapse)나 훈련 불안정성을 보이지 않으며, 매개변수 공유(parameter sharing)를 대폭 활용함으로써 AR 모델들 [67]처럼 수십억 개의 매개변수를 동원하지 않고도 자연 이미지의 매우 복잡한 분포를 모델링할 수 있습니다. 고해상도 이미지 합성을 대중화하기 DMs는 가능성 기반 모델(likelihood-based models)의 한 분류에 속하며, 모드 커버링(mode-covering) 행동으로 인해 데이터의 미세한 세부 사항을 모델링하는 데 과도한 용량(따라서 계산 자원)을 소비하는 경향이 있습니다 [16,73]. 비록 재가중된 변분 목표(reweighted variational objective) [30]가 초기의 탈잡음 단계(denoising steps)를 언더샘플링(undersampling)함으로써 이를 해결하려고 하지만, DMs는 여전히 계산적으로 요구가 많습니다. 왜냐하면 이러한 모델을 훈련하고 평가하는 것은 RGB 이미지의 고차원 공간에서 반복적인 함수 평가(그리고 기울기 계산)를 필요로 하기 때문입니다. 예를 들어, 가장 강력한 DMs를 훈련하는 데는 수백 GPU 일이 걸립니다(예: [15]에서 150 1000 V100 일). 그리고 입력 공간의 잡음이 있는 버전에 대한 반복 평가는 추론을 비용이 많이 드는 작업으로 만들어, 단일 A100 GPU에서 50k 샘플을 생성하는 데 대략 5일이 걸립니다 [15]. 이것은 연구 커뮤니티와 일반 사용자들에게 두 가지 결과를 가져옵니다: 첫째, 이러한 모델을 훈련하는 데는 소수의 분야에서만 사용할 수 있는 방대한 계산 자원이 필요하며, 큰 탄소 발자국을 남깁니다 . 둘째, 이미 훈련된 모델을 평가하는 것도 시간과 메모리 측면에서 비용이 많이 듭니다. 왜냐하면 동일한 모델 아키텍처가 많은 수의 단계(예: [15]에서 25 - 1000 단계)에 걸쳐 순차적으로 실행되어야 하기 때문입니다.
이 강력한 모델 클래스의 접근성을 높이고 동시에 상당한 자원 소비를 줄이기 위해서는 훈련과 샘플링 모두에 대한 계산 복잡성을 줄이는 방법이 필요합니다. 따라서 DMs의 성능을 손상시키지 않으면서 계산 요구 사항을 줄이는 것이 접근성을 향상시키는 데 있어 핵심입니다.
잠재 공간으로의 출발 우리의 접근법은 이미 훈련된 확산 모델들을 픽셀 공간에서 분석하는 것으로 시작합니다: 그림 2는 훈련된 모델의 비율-왜곡(rate-distortion) 트레이드오프를 보여줍니다. 모든 가능성 기반 모델(likelihood-based model)과 마찬가지로, 학습은 대략 두 단계로 나눌 수 있습니다: 첫 번째는 고주파 세부 사항을 제거하지만 여전히 적은 의미론적 변화를 학습하는 지각적 압축 단계(perceptual compression stage)입니다. 두 번째 단계에서는 실제 생성 모델이 데이터의 의미론적 및 개념적 구성(semantic compression)을 학습합니다. 따라서 우리는 먼저 지각적으로 동등하지만 계산적으로 더 적합한 공간을 찾고자 하며, 이 공간에서 고해상도 이미지 합성을 위한 확산 모델을 훈련할 것입니다.
일반적인 관행을 따라 , 우리는 훈련을 두 개의 별도 단계로 분리합니다: 먼저, 우리는 데이터 공간에 지각적으로 동등한 저차원(그리고 그러므로 효율적인) 표현 공간을 제공하는 오토인코더(autoencoder)를 훈련합니다. 중요하게도, 이전 작업 과는 달리, 우리는 공간적 압축에 과도하게 의존할 필요가 없습니다. 왜냐하면 우리는 공간 차원성에 대해 더 나은 스케일링 특성을 보이는 학습된 잠재 공간에서 DM들을 훈련하기 때문입니다. 감소된 복잡성은 또한 단일 네트워크 패스로 잠재 공간에서 효율적인 이미지 생성을 가능하게 합니다. 우리는 결과 모델 클래스를 잠재 확산 모델(Latent Diffusion Models, LDMs)이라고 부릅니다.
이 접근법의 주목할 만한 장점은 우리가 범용 오토인코딩 단계를 단 한 번만 훈련하면 되므로, 여러 DM 훈련에 재사용하거나 아마도 완전히 다른 작업들을 탐색하는 데 사용할 수 있다는 것입니다 . 이를 통해 다양한 이미지-이미지 및 텍스트-이미지 작업들에 대한 많은 수의 확산 모델들을 효율적으로 탐색할 수 있습니다. 후자의 경우, 우리는 트랜스포머(transformers)를 DM의 유넷(UNet) 백본에 연결하는 아키텍처를 설계하고 임의의 토큰 기반 조건화 메커니즘을 가능하게 하는데, 3.3절을 참조하세요.
요약하자면, 우리의 작업은 다음과 같은 기여를 합니다:
(i) 순수하게 트랜스포머 기반 접근법 과는 대조적으로, 우리의 방법은 더 높은 차원의 데이터에 더 우아하게 스케일링되며, 따라서 (a) 이전 작업보다 더 충실하고 상세한 재구성을 제공하는 압축 수준에서 작동할 수 있고 (b) 효율적으로
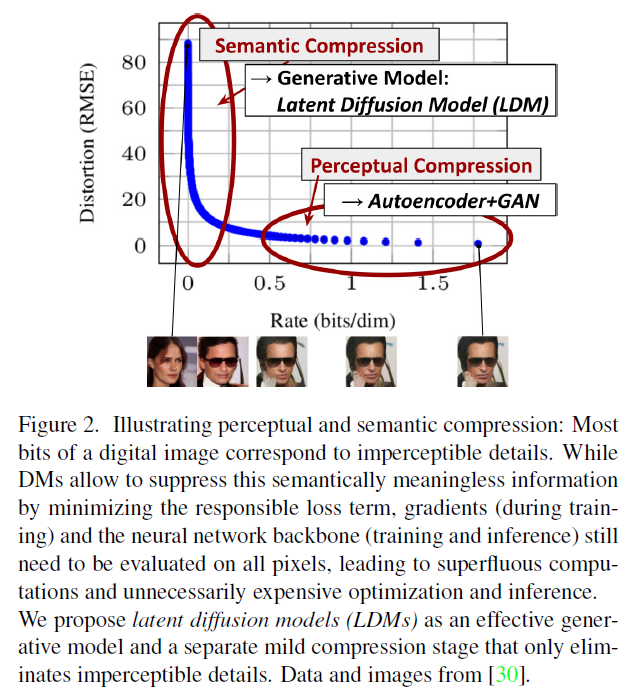
그림 2. 지각적 및 의미론적 압축을 설명함: 디지털 이미지의 대부분의 비트는 감지할 수 없는 세부 사항에 해당합니다. DM들은 책임 있는 손실 항(loss term)을 최소화함으로써 이 의미론적으로 무의미한 정보를 억제할 수 있지만, 그라디언트(훈련 중)와 신경망 백본(훈련 및 추론)은 여전히 모든 픽셀에서 평가되어야 하므로 불필요한 계산과 불필요하게 비싼 최적화 및 추론을 초래합니다. 우리는 잠재 확산 모델(LDMs)을 효과적인 생성 모델로 제안하며, 감지할 수 없는 세부 사항만을 제거하는 별도의 온화한 압축 단계를 제안합니다. 데이터 및 이미지 출처는 입니다.
메가픽셀 이미지의 고해상도 합성에 적용됩니다.
(ii) 우리는 다중 작업(무조건적 이미지 합성, 이미지 복원, 확률적 초고해상도)과 데이터셋에서 경쟁력 있는 성능을 달성하면서 계산 비용을 크게 낮췄습니다. 픽셀 기반 확산 접근법과 비교하여, 우리는 또한 추론 비용을 크게 감소시켰습니다.
(iii) 이전 연구[93]가 인코더/디코더(encoder/decoder) 구조와 점수 기반의 사전 확률(score-based prior)을 동시에 학습하는 것과 달리, 우리의 접근 방식은 재구성 능력과 생성 능력 사이의 섬세한 가중치 조절을 필요로 하지 않습니다. 이는 매우 정확한 재구성을 보장하며 잠재 공간(latent space)의 규제도 거의 필요하지 않습니다.
(iv) 초해상도(super-resolution), 이미지 복원(inpainting), 의미론적 합성(semantic synthesis)과 같이 밀접하게 조건이 부여된 작업에서, 우리의 모델은 합성곱 방식(convolutional fashion)으로 적용될 수 있으며, 일관성 있는 큰 이미지를 px 크기로 렌더링할 수 있습니다.
(v) 또한, 우리는 교차 주의(cross-attention)를 기반으로 한 일반적인 목적의 조건부 메커니즘을 설계하여 다중 모달(multi-modal) 학습을 가능하게 합니다. 이를 사용하여 클래스 조건부(class-conditional), 텍스트-이미지(text-to-image), 레이아웃-이미지(layout-to-image) 모델을 학습합니다.
(vi) 마지막으로, 우리는 https://github.com/CompVis/latent-diffusion 에서 사전 훈련된 잠재 확산(latent diffusion) 및 자동 인코딩(autoencoding) 모델을 공개합니다. 이는 DMs[81]의 훈련 외에도 다양한 작업에 재사용될 수 있습니다.
2. 관련 연구
이미지 합성을 위한 생성 모델 이미지의 고차원적 특성은 생성 모델링에 독특한 도전을 제시합니다. 생성적 적대 신경망(GAN)[27]은 좋은 지각적 품질을 가진 고해상도 이미지의 효율적인 샘플링을 가능하게 합니다 , 하지만 최적화하기 어렵습니다 그리고 전체 데이터 분포를 포착하는 데 어려움을 겪습니다 [55]. 반면, 가능도 기반 방법(likelihood-based methods)은 좋은 밀도 추정을 강조하며, 최적화를 더 잘 행동하게 만듭니다. 변분 오토인코더(VAE)[46]와 흐름 기반 모델(flow-based models)[18,19]은 고해상도 이미지의 효율적인 합성을 가능하게 하지만, 샘플 품질은 GANs에 비해 떨어집니다. 자기 회귀 모델(ARM)[6, 10, 94, 95]은 밀도 추정에서 강력한 성능을 달성하지만, 계산적으로 요구되는 구조[97]와 순차적인 샘플링 과정은 저해상도 이미지로 제한됩니다. 이미지의 픽셀 기반 표현은 거의 인지할 수 없는 고주파 세부 사항을 포함하고 있기 때문에[16,73], 최대 가능도 훈련은 이를 모델링하는 데에 불균형하게 많은 용량을 소비하며, 이로 인해 훈련 시간이 길어집니다. 더 높은 해상도로 확장하기 위해, 몇몇 이단계 접근법들[23,67,101,103]은 원시 픽셀 대신 압축된 잠재 이미지 공간을 모델링하기 위해 ARMs를 사용합니다.
최근 확산 확률 모델(Diffusion Probabilistic Models, DM) [82]은 밀도 추정 [45]과 샘플 품질 [15]에서 최첨단 결과를 달성했습니다. 이 모델들의 생성 능력은 그들의 기본 신경망 구조가 UNet 으로 구현될 때 이미지와 같은 데이터의 귀납적 편향(inductive biases)에 자연스럽게 부합하기 때문에 나옵니다. 일반적으로 재가중 목적 함수(reweighted objective) [30]를 훈련에 사용할 때 최고의 합성 품질을 달성합니다. 이 경우, DM은 손실 압축기(lossy compressor)에 해당하며 이미지 품질과 압축 능력 사이에서 타협을 가능하게 합니다. 그러나 이 모델들을 픽셀 공간에서 평가하고 최적화하는 것은 추론 속도가 낮고 훈련 비용이 매우 높다는 단점이 있습니다. 전자는 고급 샘플링 전략 [47, 75, 84]과 계층적 접근법 [31,93]으로 부분적으로 해결할 수 있지만, 고해상도 이미지 데이터에 대한 훈련은 항상 비싼 그래디언트 계산을 요구합니다. 우리는 제안하는 LDMs로 이 두 가지 단점을 해결합니다. LDMs는 차원이 낮은 압축된 잠재 공간에서 작동하여 훈련을 계산적으로 저렴하게 만들고 합성 품질을 거의 저하시키지 않으면서 추론 속도를 높입니다(그림 1 참조).
이단계 이미지 합성 개별 생성 접근법의 단점을 완화하기 위해, 많은 연구 가 두 단계 접근법을 통해 다양한 방법의 강점을 결합하여 더 효율적이고 성능이 좋은 모델을 만드는 데 힘썼습니다. VQ-VAEs [67, 101]는 이산화된 잠재 공간에 대한 표현력 있는 사전을 학습하기 위해 자기회귀 모델을 사용합니다. [66]은 이 방법을 확장하여 이산화된 이미지와 텍스트 표현에 대한 공동 분포를 학습함으로써 텍스트-이미지 생성을 가능하게 합니다. 더 일반적으로, [70]은 다양한 도메인의 잠재 공간 사이의 일반적인 전환을 제공하기 위해 조건부 가역 네트워크를 사용합니다. VQ-VAEs와 달리, VQGANs [23,103]은 자기회귀 변환기를 더 큰 이미지로 확장하기 위해 적대적이고 지각적 목적을 가진 첫 단계를 사용합니다. 그러나, 실현 가능한 ARM 훈련을 위해 요구되는 높은 압축률은 수십억 개의 훈련 가능한 매개변수 를 도입하며, 전체 성능을 제한하고 덜 압축하는 것은 높은 계산 비용을 초래합니다 . 우리의 작업은 이러한 타협을 방지합니다. 우리가 제안하는 LDMs는 그들의 합성골격(convolutional backbone) 덕분에 더 높은 차원의 잠재 공간으로 부드럽게 확장되기 때문입니다. 따라서 우리는 강력한 첫 단계를 학습하는 동시에 생성 확산 모델에 지각적 압축을 너무 많이 맡기지 않고 고해상도 재구성을 보장하는 최적의 압축 수준을 자유롭게 선택할 수 있습니다(그림 1 참조).
함께 [93] 또는 별도로 [80] 인코딩/디코딩 모델과 점수 기반 사전을 학습하는 접근법이 있지만, 전자는 여전히 재구성과 생성 능력 사이의 어려운 가중치를 요구하며 [11] 우리의 접근법에 의해 능가되고(Sec. 4), 후자는 인간의 얼굴과 같은 고도로 구조화된 이미지에 초점을 맞춥니다.
3. 방법
고해상도 이미지 합성을 위한 확산 모델의 훈련에 대한 계산 요구 사항을 낮추기 위해, 확산 모델이 해당 손실 항을 언더샘플링함으로써 지각적으로 무관한 세부 사항을 무시할 수 있음에도 불구하고 [30], 여전히 픽셀 공간에서 비용이 많이 드는 함수 평가를 요구하며, 이는 계산 시간과 에너지 자원에 엄청난 요구를 야기합니다.
우리는 압축 단계와 생성 단계를 명확히 분리함으로써 이러한 단점을 우회할 것을 제안합니다(그림 2 참조). 이를 위해 우리는 이미지 공간과 지각적으로 동등하지만 계산 복잡성이 크게 줄어든 공간을 학습하는 오토인코더 모델을 활용합니다.
이러한 접근 방식은 여러 가지 장점을 제공합니다: (i) 고차원 이미지 공간을 벗어나면서, 저차원 공간에서 샘플링이 수행되기 때문에 계산적으로 훨씬 더 효율적인 DMs(Deep Models)를 얻을 수 있습니다. (ii) 우리는 UNet 아키텍처[71]에서 유래된 DMs의 귀납적 편향을 활용하여, 공간 구조를 가진 데이터에 특히 효과적이므로 이전 접근 방식들이 요구하는 공격적이고 품질을 저하시키는 압축 수준의 필요성을 완화합니다 . (iii) 마지막으로, 우리는 다양한 생성 모델을 훈련시키고 단일 이미지 CLIP 가이드 합성[25]과 같은 다른 하류 응용 프로그램에도 사용될 수 있는 범용 압축 모델의 잠재 공간을 얻습니다.
3.1. 지각적 이미지 압축
우리의 지각적 압축 모델은 이전 연구[23]에 기반을 두고 있으며, 지각적 손실[106]과 패치 기반[33] 적대적 목표 의 조합으로 훈련된 오토인코더로 구성됩니다. 이는 지역적 리얼리즘을 강제함으로써 재구성을 이미지 매니폴드에 한정시키고 나 목표와 같은 픽셀 공간 손실에만 의존하여 도입된 흐림 현상을 피합니다.
더 정확히 말하면, RGB 공간에서의 이미지 에 대해, 인코더 는 를 잠재 표현 로 인코딩하고, 디코더 는 잠재 공간에서 이미지를 재구성하여 를 제공합니다. 여기서 입니다. 중요한 것은 인코더가 이미지를 의 요소로 다운샘플링하며, 우리는 다양한 다운샘플링 요소 , 여기서 을 조사합니다.
높은 분산을 가진 잠재 공간을 피하기 위해, 우리는 두 가지 다른 종류의 정규화를 실험합니다. 첫 번째 변형인 -정규화는 VAE 와 유사하게 학습된 잠재 공간에 표준 정규 분포에 대한 약간의 KL-페널티를 부과하는 반면, -정규화는 디코더 내에 벡터 양자화 층 [96]을 사용합니다. 이 모델은 VQGAN [23]으로 해석될 수 있지만, 양자화 층이 디코더에 흡수된 형태입니다. 우리의 후속 DM(잠재 확산 모델)이 학습된 잠재 공간 의 이차원 구조와 함께 작동하도록 설계되었기 때문에, 우리는 상대적으로 약한 압축률을 사용하고 매우 좋은 재구성을 달성할 수 있습니다. 이는 이전 연구들 [23,66]이 학습된 공간 의 임의의 1D 순서를 사용하여 그 분포를 자기회귀적으로 모델링하고 의 내재된 구조를 대부분 무시한 것과 대조됩니다. 따라서, 우리의 압축 모델은 의 세부 사항을 더 잘 보존합니다(표 8 참조). 전체 목표와 훈련 세부 사항은 부록에서 찾을 수 있습니다.
3.2. 잠재 확산 모델
확산 모델 [82]은 점진적으로 정규 분포된 변수를 노이즈 제거하는 방식으로 데이터 분포 를 학습하도록 설계된 확률 모델입니다. 이는 고정된 마르코프 체인(Markov Chain)의 역과정을 학습하는 것에 해당하며, 길이가 입니다. 이미지 합성을 위한 가장 성공적인 모델들 은 에 대한 변분 하한(variational lower bound)의 재가중 변형에 의존하며, 이는 노이즈 제거 스코어 매칭 [85]을 반영합니다. 이 모델들은 동일한 가중치를 가진 노이즈 제거 오토인코더의 연속으로 해석될 수 있으며 , 이들은 입력 의 노이즈가 제거된 변형을 예측하도록 훈련됩니다. 여기서 는 입력 의 노이즈 버전입니다. 해당 목표는 (섹션 B)로 간소화될 수 있습니다.
여기서 는 에서 균등하게 샘플링됩니다.
잠재 표현의 생성 모델링. 와 로 구성된 우리의 훈련된 지각 압축 모델을 통해, 이제 우리는 고주파수, 인지할 수 없는 세부 사항이 추상화된 효율적이고 저차원의 잠재 공간에 접근할 수 있습니다. 고차원 픽셀 공간에 비해, 이 공간은 데이터의 중요하고 의미 있는 비트에 집중할 수 있고 (i) 더 낮은 차원에서, 훨씬 더 효율적으로 계산할 수 있기 때문에 (ii) 가능성 기반 생성 모델에 더 적합합니다. 이전 연구들이 자기회귀적인, 주의 기반 변환 모델(attention-based transformer models)을 매우 압축된 이산 잠재 공간 에서 의존했던 것과 달리, 우리는 우리 모델이 제공하는 이미지 특화적인 유도 편향(inductive biases)을 활용할 수 있습니다. 이
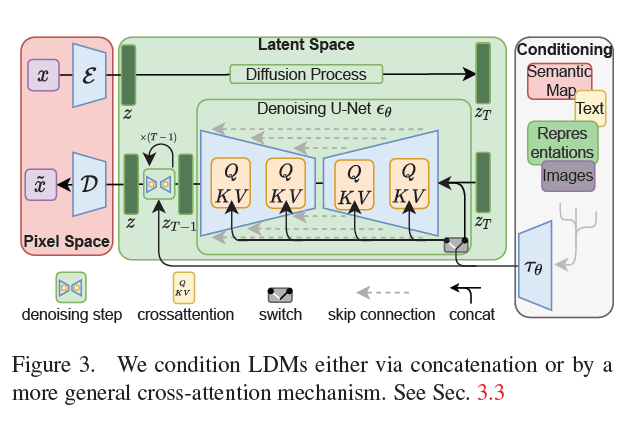
그림 3. 우리는 LDM(Latent Diffusion Models)을 연결(concatenation)을 통해 혹은 더 일반적인 교차 주의(cross-attention) 메커니즘을 통해 조건을 부여합니다. 3.3절을 참조하세요.
이것은 기본적인 UNet을 주로 2D 합성곱(convolutional) 층으로 구축하는 능력을 포함하며, 재가중된 경계(reweighted bound)를 사용하여 지각적으로 가장 관련이 높은 비트에 목표를 더 집중시키는 것을 포함합니다. 이제 이 경계는 다음과 같이 표현됩니다.
우리 모델의 신경망 백본(neural backbone) 은 시간 조건부(time-conditional) UNet [71]으로 구현됩니다. 전방 과정(forward process)이 고정되어 있기 때문에, 는 훈련 중에 로부터 효율적으로 얻을 수 있으며, 에서 샘플을 이미지 공간으로 디코딩하는 것은 를 통한 단일 패스(single pass)로 수행될 수 있습니다.
3.3. 조건부 메커니즘(Conditioning Mechanisms)
다른 유형의 생성 모델들[56,83]과 마찬가지로, 확산 모델(diffusion models)은 원칙적으로 형태의 조건부 분포를 모델링할 수 있습니다. 이는 조건부 제거 오토인코더(conditional denoising autoencoder) 를 사용하여 구현할 수 있으며, 텍스트[68], 의미 지도(semantic maps) 또는 다른 이미지 대 이미지 변환 작업(image-to-image translation tasks) [34]과 같은 입력 를 통해 합성 과정을 제어할 수 있는 길을 엽니다.
그러나 이미지 합성의 맥락에서, 클래스 라벨(class-labels) [15]이나 입력 이미지의 흐릿한 변형(blurred variants) [72]을 넘어서는 다른 유형의 조건을 DM(Diffusion Models)의 생성력과 결합하는 것은 아직 탐구되지 않은 연구 분야입니다.
우리는 DM을 더 유연한 조건부 이미지 생성기로 변환하기 위해, 다양한 입력 모달리티(input modalities) 의 주의 기반 모델을 학습하는 데 효과적인 교차 주의 메커니즘(cross-attention mechanism) [97]으로 그들의 기본 UNet 백본을 확장합니다. 언어 프롬프트(language prompts)와 같은 다양한 모달리티의 를 전처리하기 위해, 우리는 도메인 특화 인코더(domain specific encoder) 를 도입하여 를 중간 표현 으로 투영하고, 이를 교차 주의 층(cross-attention layer)을 통해 UNet의 중간 층에 매핑합니다. 이 층은 Attention 를 구현하며, 다음과 같이 정의됩니다.
.
여기서, 는 를 구현하는 UNet의 (평평한) 중간 표현을 나타내고

그림 4. CelebAHQ [39], FFHQ [41], LSUN-Churches [102], LSUN-Bedrooms [102] 및 클래스 조건부 ImageNet [12]에서 훈련된 LDMs의 샘플들, 각각 해상도로. 확대해서 보는 것이 좋습니다. 더 많은 샘플은 부록을 참조하세요.
는 학습 가능한 투영 행렬들입니다 [36,97]. 시각적 묘사는 그림 3을 참조하세요.
이미지-조건 쌍을 기반으로, 우리는 조건부 LDM을 다음과 같이 학습합니다.
여기서 와 는 모두 식 3을 통해 공동으로 최적화됩니다. 이 조건부 메커니즘은 유연하며, 는 도메인 특화 전문가들로 파라미터화될 수 있습니다. 예를 들어, 가 텍스트 프롬프트일 때는 (가리지 않은) 트랜스포머(transformers) [97]를 사용합니다(4.3.1절 참조).
4. 실험
LDMs는 다양한 이미지 모달리티에 대한 유연하고 계산적으로 처리 가능한 확산 기반 이미지 합성 수단을 제공합니다. 우리는 다음에서 이를 경험적으로 보여줍니다. 그러나 먼저, 픽셀 기반 확산 모델과 비교하여 우리 모델의 이점을 훈련 및 추론 모두에서 분석합니다. 흥미롭게도, 정규화된 잠재 공간에서 훈련된 는 때때로 더 나은 샘플 품질을 달성하기도 하는데, 이는 정규화된 첫 번째 단계 모델의 재구성 능력이 그들의 연속적인 대응물에 비해 약간 뒤떨어지더라도 그렇습니다, 부록 D.1에서 해상도로 일반화 능력에 대한 첫 번째 단계 정규화 계획의 영향을 비교한 시각적 비교를 찾을 수 있습니다. E. 2에서는 이 섹션에서 제시된 모든 결과에 대한 아키텍처, 구현, 훈련 및 평가에 대한 세부 사항을 나열합니다.
4.1. 지각적 압축 트레이드오프에 대하여
이 섹션에서는 다운샘플링 인자 (이를 로 줄여서 표현하며, 여기서 은 픽셀 기반 DMs에 해당함)를 가진 LDMs의 동작을 분석합니다. 비교 가능한 테스트 필드를 얻기 위해, 이 섹션의 모든 실험에 단일 NVIDIA A100을 고정하여 컴퓨팅 자원을 사용하고, 모든 모델을 동일한 스텝 수와 동일한 파라미터 수로 훈련합니다.
표 8은 이 섹션에서 비교한 LDMs에 사용된 첫 번째 단계 모델의 하이퍼파라미터와 재구성 성능을 보여줍니다. 그림 6은 ImageNet [12] 데이터셋에서 클래스 조건부 모델의 스텝에 대한 훈련 진행에 따른 샘플 품질을 보여줍니다. 우리는 i) 작은 다운샘플링 인자 가 훈련 진행을 느리게 만든다는 것과 ii) 과도하게 큰 값이 비교적 적은 훈련 스텝 후에 정체된 충실도를 초래한다는 것을 확인합니다. 위의 분석(Fig. 1과 2)을 다시 살펴보면, 이는 i) 대부분의 지각적 압축을 확산 모델에 맡기고 ii) 너무 강한 첫 번째 단계 압축으로 인해 정보 손실이 발생하여 달성 가능한 품질을 제한하기 때문입니다. 은 효율성과 지각적으로 충실한 결과 사이의 좋은 균형을 이루며, 이는 훈련 스텝 후 픽셀 기반 확산(LDM-1)과 사이에 38의 상당한 FID [29] 차이로 나타납니다.
그림 7에서는 CelebAHQ [39]와 ImageNet에서 훈련된 모델들을 DDIM 샘플러 [84]를 사용한 다양한 수의 노이즈 제거 스텝에 대한 샘플링 속도 측면에서 비교하고, 이를 FID 점수 [29]와 대조하여 그래프로 나타냅니다. LDM-은 지각적 및 개념적 압축의 부적절한 비율을 가진 모델들을 능가합니다. 특히 픽셀 기반 과 비교할 때, 훨씬 낮은 FID 점수를 달성하면서 동시에 샘플 처리량을 크게 증가시킵니다. ImageNet과 같은 복잡한 데이터셋은 품질을 저하시키지 않기 위해 압축률을 줄여야 합니다. 요약하자면, 와 -8은 고품질 합성 결과를 달성하기 위한 최적의 조건을 제공합니다.
4.2. 잠재 확산을 이용한 이미지 생성
우리는 CelebA-HQ [39], FFHQ [41], LSUN-Churches 및 -Bedrooms [102]에서 이미지의 무조건부 모델을 훈련하고 i) 샘플 품질과 ii) 데이터 매니폴드에 대한 커버리지를 ii) FID [29]와 ii) 정밀도-재현율 [50]을 사용하여 평가합니다. 표 1은 우리의 결과를 요약합니다. CelebA-HQ에서는 이전의 가능성 기반 모델과 GANs를 능가하는 새로운 최첨단 FID 5.11을 보고합니다. 우리는 또한 잠재 확산 모델이 첫 번째 단계와 함께 공동으로 훈련되는 LSGM [93]을 능가합니다. 반면에, 우리는 고정된 공간에서 확산 모델을 훈련합니다.

그림 5. LAION [78] 데이터베이스에서 학습된 텍스트-이미지 합성을 위한 우리 모델 에 대한 사용자 정의 텍스트 프롬프트 샘플들입니다. 샘플들은 200 DDIM 단계와 을 사용하여 생성되었습니다. 우리는 조건 없는 가이드(unconditional guidance) [32]를 으로 사용합니다.
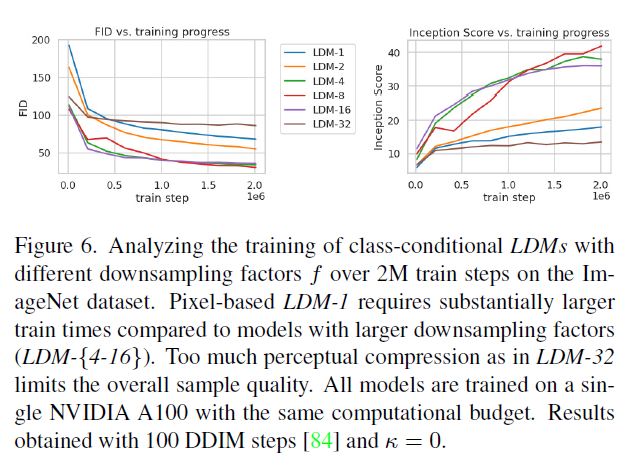
그림 6. ImageNet 데이터셋에서 다운샘플링 인자 가 다른 클래스 조건부 LDM들의 학습을 학습 단계에 걸쳐 분석합니다. 픽셀 기반 은 더 큰 다운샘플링 인자를 가진 모델들(LDM-{4-16})에 비해 상당히 더 많은 학습 시간을 요구합니다. 처럼 지나치게 많은 지각적 압축은 전반적인 샘플 품질을 제한합니다. 모든 모델들은 동일한 계산 예산으로 단일 NVIDIA A100에서 학습되었습니다. 결과는 100 DDIM 단계 [84]와 을 사용하여 얻었습니다.
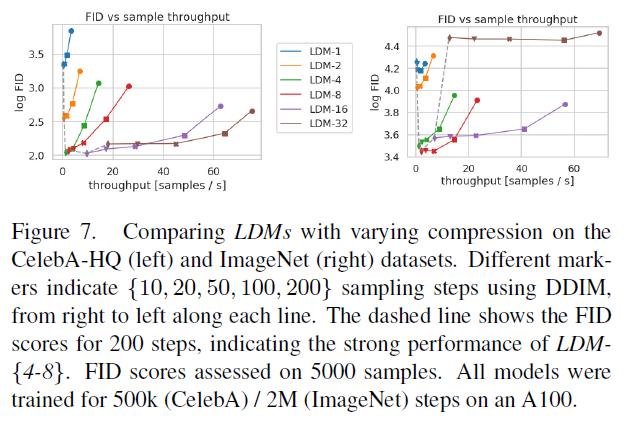
그림 7. CelebA-HQ(왼쪽)와 ImageNet(오른쪽) 데이터셋에서 다양한 압축을 가진 를 비교합니다. 다른 마커들은 DDIM을 사용한 샘플링 단계를 오른쪽에서 왼쪽으로 각 라인을 따라 나타냅니다. 점선은 200 단계에 대한 FID 점수를 보여주며, 의 강력한 성능을 나타냅니다. FID 점수는 5000개의 샘플에서 평가되었습니다. 모든 모델들은 A100에서 500k (CelebA) / 2M (ImageNet) 단계 동안 학습되었습니다.
그리고 잠재 공간에 대한 사전 학습을 재구성 품질과 비교하는 어려움을 피하려면, 그림 1-2를 참조하세요.
우리는 LSUN-Bedrooms 데이터셋을 제외한 모든 데이터셋에서 이전의 확산 기반 접근법들을 능가합니다. 여기서 우리의 점수는 ADM [15]에 가깝지만, 그것의 매개변수의 절반만을 사용하고 4배 적은 학습 자원이 필요함에도 불구하고 (부록 E.3.5 참조).
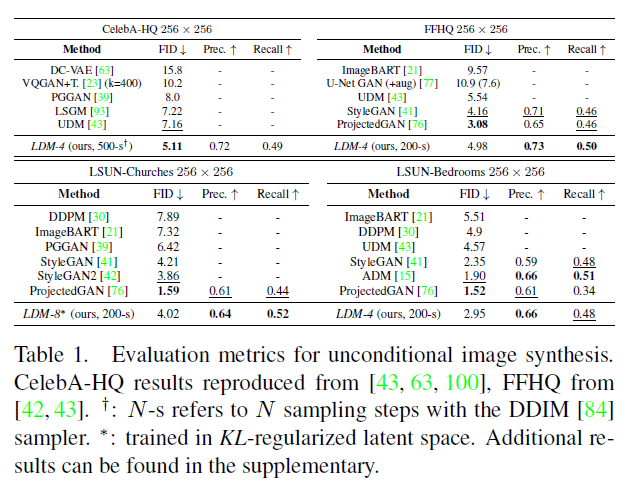
표 1. 조건 없는 이미지 합성을 위한 평가 메트릭. CelebA-HQ 결과는 [43, 63, 100]에서 재현되었고, FFHQ는 [42,43]에서. -s는 DDIM [84] 샘플러를 사용한 샘플링 단계를 의미합니다. *: -규제된 잠재 공간에서 학습되었습니다. 추가 결과는 보충 자료에서 찾을 수 있습니다.
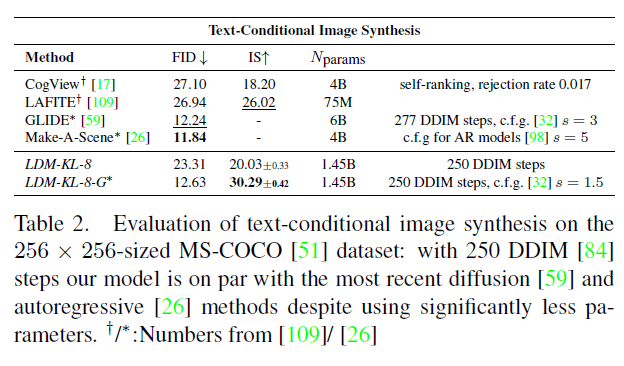
표 2. 크기의 MS-COCO [51] 데이터셋에서 텍스트 조건부 이미지 합성 평가: 250 DDIM [84] 단계를 사용한 우리 모델은 훨씬 적은 파라미터를 사용하면서도 최근의 확산 [59] 및 자동회귀 [26] 방법과 비슷한 수준입니다. : [109]/ [26]에서 가져온 숫자들
게다가, LDM은 정밀도(Precision)와 재현율(Recall)에서 GAN 기반 방법들을 일관되게 개선하여, 적대적 접근법에 비해 그들의 모드 커버링(mode-covering) 가능성 기반 훈련 목표의 장점을 확인시켜 줍니다. 그림 4에서는 각 데이터셋에 대한 질적 결과도 보여줍니다.

그림 8. COCO [4]에서 LDM을 사용한 레이아웃-이미지 합성, 4.3.1절 참조. 보충 자료 D.3에서 정량적 평가.
4.3. 조건부 잠재 확산
4.3.1 LDM을 위한 트랜스포머 인코더(Transformers Encoders)
크로스 어텐션(cross-attention) 기반 조건부 설정을 LDMs에 도입함으로써, 이전에 확산 모델(diffusion models)에서 탐색되지 않았던 다양한 조건부 모달리티를 가능하게 했습니다. 텍스트에서 이미지로의 모델링(text-to-image image modeling)을 위해, 우리는 LAION-400M [78]에서 언어 프롬프트(language prompts)에 조건을 부여한 파라미터의 -정규화된 을 훈련시켰습니다. 우리는 BERT 토크나이저(BERT-tokenizer) [14]를 사용하고, 변형기(transformer) [97]를 구현하여 잠재 코드(latent code)를 추론하고, 이를 (멀티 헤드) 크로스 어텐션을 통해 UNet에 매핑합니다(3.3절 참조). 언어 표현과 시각적 합성을 위한 도메인 특화 전문가들의 결합은 강력한 모델을 만들어내며, 복잡하고 사용자 정의된 텍스트 프롬프트, 에 잘 일반화됩니다. 그림 8과 5를 참조하세요. 정량적 분석을 위해, 우리는 이전 연구를 따라 MS-COCO [51] 검증 세트에서 텍스트-이미지 생성(text-to-image generation)을 평가하며, 여기서 우리의 모델은 강력한 AR [17,66] 및 GAN 기반 방법 [109], 를 개선합니다. 표 2를 참조하세요. 분류기 없는 확산 가이드(classifier-free diffusion guidance) [32]를 적용하는 것이 샘플 품질을 크게 향상시킨다는 점을 주목하며, 이에 따라 가이드된 는 최근의 최신 AR [26] 및 확산 모델(diffusion models) [59]과 텍스트-이미지 합성(text-to-image synthesis)에서 동등한 수준이 되면서, 파라미터 수를 크게 줄입니다. 크로스 어텐션 기반 조건부 설정 메커니즘의 유연성을 더 분석하기 위해, 우리는 OpenImages [49]에서 의미적 레이아웃(semantic layouts)에 기반한 이미지를 합성하기 위한 모델을 훈련시키고, COCO [4]에서 미세 조정(finetune)을 하였습니다. 그림 8을 참조하세요. 정량적 평가와 구현 세부 사항은 D. 3절을 참조하세요.
마지막으로, 이전 연구 [3, 15, 21, 23]를 따라, 우리는 4.1절에서 로 분류된 최고 성능의 ImageNet 모델을 표 3, 그림 4 및 D.4절에서 평가합니다. 여기서 우리는 최신 확산 모델 ADM [15]을 능가하면서, 계산 요구 사항과 파라미터 수를 크게 줄였습니다, . 표 18을 참조하세요.
4.3.2 를 넘어서는 컨볼루셔널 샘플링(Convolutional Sampling)
의 입력에 공간적으로 정렬된 조건부 정보를 연결함으로써, LDMs는 효율적인 일반-
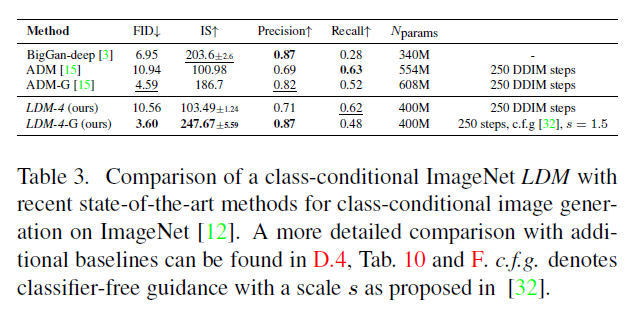
표 3. ImageNet [12]에서 클래스 조건부 이미지 생성을 위한 최신 최고 성능 방법들과의 클래스 조건부 ImageNet 비교. 추가적인 기준선들과의 더 자세한 비교는 D.4, 표(Tab.) 10과 F에서 찾아볼 수 있습니다. c.f.g는 [32]에서 제안된 스케일 를 가진 분류기 없는 가이드(classifier-free guidance)를 의미합니다.
이미지-이미지 변환(image-to-image translation) 모델을 위한 목적입니다. 우리는 이를 사용하여 의미론적 합성(semantic synthesis), 초고해상도(super-resolution) (4.4절), 그리고 이미지 복원(inpainting) (4.5절)을 위한 모델을 훈련합니다. 의미론적 합성을 위해, 우리는 풍경 이미지와 의미 지도(semantic maps) 를 사용하고, 모델(VQ-reg., 참조 Tab. 8)의 잠재 이미지 표현과 의미 지도의 다운샘플 버전을 연결합니다. 우리는 입력 해상도 ( 에서 자른 이미지)로 훈련하지만, 우리의 모델이 더 큰 해상도로 일반화되어 컨볼루셔널 방식으로 평가할 때 메가픽셀 범위까지 이미지를 생성할 수 있다는 것을 발견했습니다(그림 9 참조). 우리는 이러한 행동을 이용하여 4.4절의 초고해상도 모델과 4.5절의 이미지 복원 모델을 에서 사이의 큰 이미지를 생성하는 데에도 적용합니다. 이러한 응용에서는 잠재 공간의 규모에 의해 유발된 신호 대 잡음 비율(signal-to-noise ratio)이 결과에 상당한 영향을 미칩니다. D.1절에서 우리는 (i) 모델(KL-reg., 참조 Tab. 8)에 의해 제공되는 잠재 공간과 (ii) 구성 요소별 표준 편차로 스케일된 버전을 학습할 때 이를 보여줍니다.
후자는 분류기 없는 안내(classifier-free guidance) [32]와 결합하여, 그림 13에서와 같이 텍스트 조건부 에 대한 이미지의 직접 합성을 가능하게 합니다.

그림 9. 해상도로 훈련된 은 공간적으로 조건이 부여된 작업, 예를 들어 풍경 이미지의 의미론적 합성과 같은 더 큰 해상도(여기서: )로 일반화될 수 있습니다. 4.3.2절을 참조하세요.
4.4. 잠재 확산을 이용한 초고해상도
잠재 확산 모델(LDMs)은 저해상도 이미지에 직접 조건을 부여함으로써 연결(concatenation)을 통해 초고해상도를 위해 효율적으로 훈련될 수 있습니다(3.3절 참조). 첫 번째 실험에서, 우리는 SR3을 따릅니다.

그림 10. ImageNet 초고해상도 ImageNet-Val에서. LDM-SR은 현실적인 질감을 렌더링하는 데에 장점이 있지만, SR3은 더 일관된 미세 구조를 합성할 수 있습니다. 추가 샘플과 크롭아웃을 위한 부록을 참조하세요. SR3 결과는 [72]에서 나온 것입니다.
[72]에 따라 이미지 품질 저하를 4배 다운샘플링된 바이큐빅 보간(bicubic interpolation)으로 고정하고 SR3의 데이터 처리 파이프라인을 따라 ImageNet에서 학습합니다. 우리는 OpenImages에서 사전 학습된 자동인코딩 모델(VQ-reg., cf. 표 8)을 사용하고 저해상도 조건 와 UNet에 입력되는 것을 연결합니다. 즉, 는 항등 함수입니다. 우리의 질적 및 양적 결과(그림 10 및 표 5 참조)는 경쟁력 있는 성능을 보여주며 LDM-SR은 FID에서 SR3을 능가하지만 SR3은 IS에서 더 좋습니다. 간단한 이미지 회귀 모델은 가장 높은 PSNR과 SSIM 점수를 달성하지만; 이러한 메트릭은 인간의 인식과 잘 일치하지 않습니다[106]고 고주파 세부 사항이 완벽하게 정렬되지 않은 흐림을 선호합니다[72]. 또한, 우리는 픽셀-기준선과 LDM-SR을 비교하는 사용자 연구를 수행합니다. SR3[72]를 따라 저해상도 이미지가 두 개의 고해상도 이미지 사이에 표시되고 선호도에 대해 물어보는 인간 대상자들에게 보여줍니다. 표 4의 결과는 LDM-SR의 좋은 성능을 확인시켜 줍니다. PSNR과 SSIM은 사후 안내 메커니즘을 사용하여 높일 수 있습니다[15] 그리고 우리는 이 이미지 기반 가이더를 지각 손실을 통해 구현합니다, D.6절을 보세요.

표 4. 작업 1: 대상자들은 실제 이미지와 생성된 이미지를 보고 선호도를 물어봤습니다. 작업 2: 대상자들은 두 개의 생성된 이미지 중 하나를 선택해야 했습니다. E.3.6절에 더 자세한 내용이 있습니다.
바이큐빅 저하 과정이 이러한 사전 처리를 따르지 않는 이미지에 잘 일반화되지 않기 때문에, 우리는 더 다양한 저하를 사용하여 일반적인 모델, 을 학습합니다. 결과는 D.6.1절에 나와 있습니다.
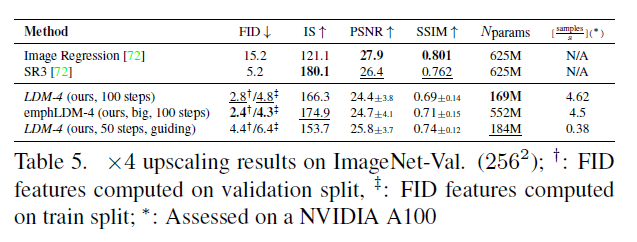
표 5. ImageNet-Val에서의 업스케일링 결과. 검증 분할에서 계산된 FID 특징, : 훈련 분할에서 계산된 FID 특징; *: NVIDIA A100에서 평가됨
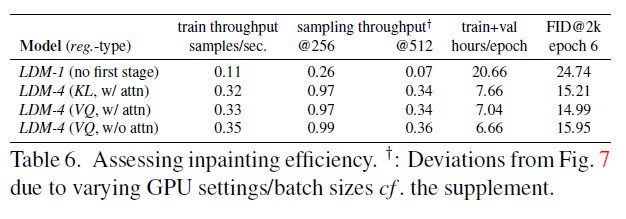
표 6. 이미지 복원 효율성 평가. : GPU 설정/배치 크기의 변화로 인한 그림 7과의 차이 . 부록 참조.
4.5. 잠재 확산을 이용한 이미지 복원
이미지 복원은 이미지의 마스크된 부분을 새로운 내용으로 채우는 작업으로, 이미지의 일부가 손상되었거나 이미지 내의 원치 않는 내용을 대체하기 위해 수행됩니다. 우리는 조건부 이미지 생성을 위한 일반적인 접근 방식이 이 작업을 위한 더 전문화된 최신 접근 방식과 어떻게 비교되는지 평가합니다. 우리의 평가는 LaMa [88]의 프로토콜을 따릅니다. LaMa는 최근에 Fast Fourier Convolutions [8]에 의존하는 전문화된 아키텍처를 도입한 이미지 복원 모델입니다. Places [108]에서의 정확한 훈련 및 평가 프로토콜은 Sec. E.2.2에 설명되어 있습니다.
우리는 먼저 첫 단계를 위한 다양한 디자인 선택의 영향을 분석합니다. 특히, (즉, 픽셀 기반 조건부 DM)과 및 정규화를 적용한 , 그리고 첫 단계에서 주의력을 사용하지 않는 (표 8 참조)의 이미지 복원 효율성을 비교합니다. 후자는 고해상도에서 디코딩 시 GPU 메모리를 줄입니다. 비교를 위해 모든 모델의 매개변수 수를 고정합니다. 표 6은 해상도 와 에서의 훈련 및 샘플링 처리량, 에포크당 총 훈련 시간(시간), 그리고 6 에포크 후 검증 세트에서의 FID 점수를 보고합니다. 전반적으로, 픽셀 기반과 잠재 기반 확산 모델 간에 최소 의 속도 향상을 관찰하며, FID 점수는 최소 향상되었습니다.
탭(Tab) 7에서 다른 이미지 복원 방법들과의 비교는 우리의 모델이 주의 기능(attention)을 사용함으로써 [88]보다 전반적인 이미지 품질을 FID로 측정했을 때 향상시킨다는 것을 보여줍니다. 마스크가 없는 이미지와 우리 샘플 사이의 LPIPS는 [88]의 것보다 약간 높습니다. 이는 [88]이 단일 결과만을 생성하는데, 이는 우리의 LDM 가 생성하는 다양한 결과들에 비해 더 평균적인 이미지를 복구하는 경향이 있기 때문이라고 생각합니다. 그림 21. 또한 사용자 연구(Tab. 4)에서 사람들은 [88]의 결과보다 우리의 결과를 선호합니다.
이러한 초기 결과를 바탕으로, 우리는 또한 주의 기능 없이 로 정규화된 첫 단계의 잠재 공간에서 더 큰 확산 모델(big in Tab. 7)을 훈련시켰습니다. [15]를 따라 이 확산 모델의 UNet은 특징 계층의 세 레벨에서 주의 기능을 사용하고, BigGAN [3]의 잔여 블록(residual block)을 업샘플링과 다운샘플링에 사용하며, 의 파라미터를 가집니다.

그림 11. 우리의 큰 모델(big), 를 사용한 이미지 복원 모델로 객체 제거에 대한 질적 결과. 더 많은 결과는 그림 22를 참조하세요.
215M 대신에 사용합니다. 훈련 후, 우리는 와 해상도에서 생성된 샘플의 품질에 차이가 있음을 발견했으며, 이는 추가된 주의 기능 모듈 때문일 것으로 추측합니다. 그러나 모델을 해상도에서 반 에포크 동안 미세 조정(fine-tuning)하면 모델이 새로운 특징 통계에 맞춰 조정되고 이미지 복원에서 새로운 최고의 FID를 설정합니다(big, w/o attn, in Tab. 7, Fig. 11.).
5. 한계점 & 사회적 영향
한계점 LDM은 픽셀 기반 접근법에 비해 계산 요구 사항을 크게 줄이지만, 그들의 순차적 샘플링 과정은 여전히 GAN보다 느립니다. 또한, 고정밀도가 요구될 때 LDM의 사용은 의문의 여지가 있습니다: 비록 우리의 자동인코딩 모델에서 이미지 품질의 손실이 매우 작다고 해도(그림 1 참조), 픽셀 공간에서 미세한 정확도가 요구되는 작업에 대한 그들의 재구성 능력은 병목 현상이 될 수 있습니다. 우리는 우리의 초해상도 모델(4.4절)이 이미 이런 면에서 다소 제한적이라고 가정합니다.
사회적 영향 이미지와 같은 미디어를 위한 생성 모델은 양날의 검입니다: 한편으로는,
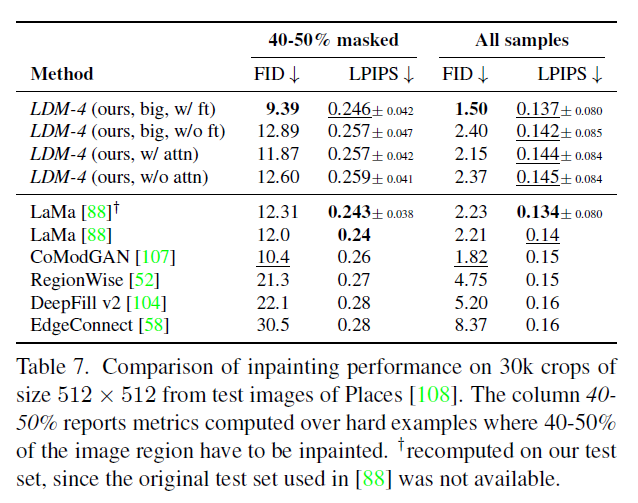
표 7. Places [108]의 테스트 이미지에서 추출한 크기의 크롭(crops)에 대한 이미지 복원(inpainting) 성능 비교. 40-50% 열은 이미지 영역의 를 복원해야 하는 어려운 예시에 대해 계산된 메트릭(metrics)을 보고합니다. 원래 [88]에서 사용된 테스트 세트가 사용할 수 없었기 때문에, 우리의 테스트 세트에서 다시 계산되었습니다.
창의적인 응용 프로그램을 가능하게 하고, 특히 훈련과 추론의 비용을 줄이는 접근 방식과 같은 우리의 방법은 이 기술에 대한 접근성을 촉진하고 그 탐색을 민주화하는 잠재력을 가지고 있습니다. 반면에, 이는 조작된 데이터를 만들고 퍼뜨리거나 잘못된 정보와 스팸을 확산하기가 더 쉬워진다는 것을 의미합니다. 특히 이미지의 고의적인 조작("딥 페이크")은 이 맥락에서 흔한 문제이며, 특히 여성들이 이로 인해 불균형하게 영향을 받습니다 [13,24].
생성 모델은 또한 그들의 훈련 데이터를 드러낼 수 있습니다 , 이는 데이터가 민감하거나 개인적인 정보를 포함하고 명시적인 동의 없이 수집되었을 때 큰 우려가 됩니다. 그러나 이것이 이미지의 DMs에도 어느 정도 적용되는지는 아직 완전히 이해되지 않았습니다.
마지막으로, 딥 러닝(deep learning) 모듈은 이미 데이터에 존재하는 편향을 재현하거나 악화시키는 경향이 있습니다 , 91]. 확산 모델(diffusion models)은 예를 들어 GAN 기반 접근법보다 데이터 분포를 더 잘 커버하지만, 적대적 훈련과 가능성 기반 목표를 결합하는 우리의 두 단계 접근 방식이 데이터를 얼마나 잘못 표현하는지는 중요한 연구 질문으로 남아 있습니다.
딥 생성 모델의 윤리적 고려에 대한 더 일반적이고 상세한 논의는 예를 들어 [13]을 참조하십시오.
6. 결론
우리는 잠재 확산 모델(latent diffusion models)을 제시했으며, 이는 노이즈 제거 확산 모델(denoising diffusion models)의 훈련 및 샘플링 효율성을 크게 향상시키는 동시에 그 품질을 저하시키지 않는 간단하고 효율적인 방법입니다. 이와 우리의 교차주의 조건화 메커니즘(crossattention conditioning mechanism)을 기반으로, 우리의 실험은 특정 작업에 특화된 아키텍처 없이도 다양한 조건부 이미지 합성 작업에서 최신 방법들과 비교하여 유리한 결과를 보여줄 수 있었습니다.
이 작업은 'KI-Absicherung - 자동 운전을 위한 안전한 AI' 프로젝트와 독일 연구 재단(DFG) 프로젝트 421703927에 의해 독일 연방 경제 에너지부의 지원을 받았습니다.
부록

그림 12. 4.3.2절에서 설명한 것처럼 의미 있는 풍경 모델에서의 합성 샘플, 이미지에 미세 조정됨.

그림 13. 4.3.2절에서 설명한 분류기 없는 확산 안내(classifier free diffusion guidance)와 합성 샘플링 전략을 결합하여, 우리의 1.45B 매개변수 텍스트-이미지 모델은 모델이 훈련된 원래의 해상도보다 큰 이미지를 렌더링하는 데 사용될 수 있습니다.
A. 변경 사항
여기서는 이 버전(https://arxiv.org/abs/2112.10752v2)의 논문과 이전 버전, 즉 https://arxiv.org/abs/2112.10752v1 사이의 변경 사항을 나열합니다.
-
Sec. 4.3에서 텍스트-이미지 합성(text-to-image synthesis) 결과를 업데이트했습니다. 이는 새롭고 더 큰 모델(14억 5천만 개의 매개변수)을 훈련하여 얻은 결과입니다. 이에는 우리의 연구가 발표된 동시에 arXiv에 게시된 매우 최근의 경쟁 방법들과의 새로운 비교도 포함되어 있습니다( 및 [26]).
-
Sec. 4.1, Tab. 3(또한 Sec. D.4 참조)에서 ImageNet의 클래스 조건부 합성(class-conditional synthesis) 결과를 더 큰 배치 크기로 모델을 재훈련하여 업데이트했습니다. 해당하는 질적 결과인 Fig. 26과 Fig. 27도 업데이트되었습니다. 업데이트된 텍스트-이미지 및 클래스 조건부 모델은 이제 시각적 충실도를 높이기 위한 조치로 분류자 없는 안내(classifier-free guidance) [32]를 사용합니다.
-
Saharia et al [72]이 제안한 방식을 따라 사용자 연구를 수행했으며, 이는 우리의 인페인팅(inpainting) (Sec. 4.5) 및 초해상도(superresolution) 모델(Sec. 4.4)에 대한 추가적인 평가를 제공합니다.
-
본문에 Fig. 5를 추가하고, Fig. 18을 부록으로 옮기고, Fig. 13을 부록에 추가했습니다.
B. 노이즈 감소 확산 모델에 대한 자세한 정보
확산 모델은 신호 대 잡음비(signal-to-noise ratio) 를 통해 정의될 수 있으며, 이는 데이터 샘플 에서 시작하여 순방향 확산 과정 를 정의하는 시퀀스 와 로 구성됩니다.
에 대한 마르코프 구조(Markov structure)는 다음과 같습니다:
노이즈 감소 확산 모델(denoising diffusion models)은 이 과정을 시간을 거슬러 비슷한 마르코프 구조로 되돌리는 생성 모델 입니다. 즉, 다음과 같이 정의됩니다.
이 모델과 관련된 증거 하한(evidence lower bound, ELBO)은 이산 시간 단계에 걸쳐 분해됩니다.
사전 확률 은 일반적으로 표준 정규 분포(standard normal distribution)로 선택되며, ELBO의 첫 번째 항은 최종 신호 대 잡음비 에만 의존합니다. 남은 항들을 최소화하기 위해, 를 매개변수화하는 일반적인 방법은 진짜 사후 확률 을 사용하지만, 알려지지 않은 을 현재 단계 를 기반으로 한 추정치 로 대체하는 것입니다. 이것은 다음과 같이 제시됩니다 [45]
여기서 평균은 다음과 같이 표현될 수 있습니다
이 경우, ELBO의 합은 단순화됩니다
[30]을 따라서, 우리는 재매개변수화(reparameterization)
를 사용하여 복원 항을 노이즈 제거 목표(denoising objective)로 표현합니다,
그리고 각 항에 동일한 가중치를 부여하는 재가중(reweighting)을 통해 식 (1)의 결과를 얻습니다.
C. 이미지 가이딩 메커니즘(Image Guiding Mechanisms)

그림 14. 풍경에서, 조건 없는 모델(unconditional models)을 사용한 합성 샘플링(convolutional sampling)은 균질하고 비일관적인 전역 구조(homogeneous and incoherent global structures)를 초래할 수 있습니다(2열 참조). 저해상도 이미지를 사용한 -가이딩은 일관된 전역 구조를 재정립하는 데 도움을 줄 수 있습니다.
확산 모델(diffusion models)의 흥미로운 특징 중 하나는 조건 없는 모델(unconditional models)이 테스트 시간(test-time)에 조건을 부여할 수 있다는 것입니다 [15,82,85]. 특히, [15]는 ImageNet 데이터셋에서 학습된 조건 없는 모델과 조건 있는 모델을 분류기 로 가이드하는 알고리즘을 제시했습니다. 이 분류기는 확산 과정의 각 에 대해 학습됩니다. 우리는 이 공식을 직접 활용하여 사후 이미지 가이딩(post-hoc image-guiding)을 도입합니다:
고정된 분산을 가진 엡실론-매개변수화된 모델(epsilon-parameterized model)에 대해, [15]에서 소개된 가이딩 알고리즘은 다음과 같이 읽힙니다:
이것은 조건부 분포 를 사용하여 "점수" 를 수정하는 업데이트로 해석될 수 있습니다.
지금까지 이 시나리오는 단일 클래스 분류 모델에만 적용되었습니다. 우리는 가이딩 분포 를 목표 이미지 가 주어진 일반적인 이미지-이미지 변환 작업으로 재해석합니다. 여기서 는 항등 함수, 다운샘플링 연산 또는 유사한 것과 같이 이미지-이미지 변환 작업에 적용된 어떤 차별화 가능한 변환도 될 수 있습니다.
예를 들어, 고정된 분산 을 가진 가우시안 가이더를 가정할 수 있으며, 이 경우
는 회귀 목표가 됩니다.
그림 14는 이 공식이 어떻게 이미지로 훈련된 무조건부 모델의 업샘플링 메커니즘으로 사용될 수 있는지 보여줍니다. 여기서 크기의 무조건부 샘플이 이미지의 합성을 가이드하고 는 바이큐빅 다운샘플링입니다. 이 동기를 바탕으로 우리는 또한 지각적 유사성 가이딩을 실험하고 목표를 LPIPS [106] 메트릭으로 대체합니다. 4.4절을 참조하세요.
D. 추가 결과
D.1. 고해상도 합성을 위한 신호 대 잡음비 선택

그림 15. 여기서는 풍경에 대한 의미론적 이미지 합성을 위한 잠재 공간 재조정의 효과를 보여줍니다. 4.3.2절 및 D.1절을 참조하세요.
4.3.2절에서 논의한 바와 같이, 잠재 공간의 분산에 의해 유도된 신호 대 잡음비(즉, )는 합성 샘플링 결과에 큰 영향을 미칩니다. 예를 들어, KL규제 모델의 잠재 공간에서 직접 LDM을 훈련할 때(8번 표 참조), 이 비율이 매우 높아서 모델이 역 노이즈 제거 과정에서 초기에 많은 의미론적 세부 사항을 할당합니다. 반면에, G절에서 설명한 것처럼 잠재 변수의 성분별 표준 편차로 잠재 공간을 재조정하면 SNR이 감소합니다. 우리는 그림 15에서 의미론적 이미지 합성을 위한 합성 샘플링의 효과를 보여줍니다. VQ-규제 공간은 분산이 거의 1에 가까워 재조정할 필요가 없다는 점에 유의하세요.
D.2. 모든 첫 번째 단계 모델의 전체 목록
우리는 Tab. 8에 OpenImages 데이터셋에서 훈련된 다양한 오토인코딩(autoencoding) 모델들의 전체 목록을 제공합니다.
D.3. 레이아웃-이미지 합성(Layout-to-Image Synthesis)
여기서 우리는 Sec. 4.3.1에서 언급된 레이아웃-이미지 모델들에 대한 정량적 평가와 추가 샘플들을 제공합니다. 우리는 COCO [4] 데이터셋과 OpenImages [49] 데이터셋에서 각각 모델을 훈련시킨 후, COCO에서 추가로 미세 조정(finetune)을 진행했습니다. Tab 9는 그 결과를 보여줍니다. 우리의 COCO 모델은 해당 훈련 및 평가 프로토콜 [89]을 따랐을 때 최근의 최신 레이아웃-이미지 합성 모델들의 성능에 도달합니다. OpenImages 모델에서 미세 조정을 할 때, 우리는 이러한 연구들을 뛰어넘습니다. 우리의 OpenImages 모델은 FID 측면에서 Jahn 등[37]의 결과를 거의 11의 차이로 능가합니다. Fig. 16에서는 COCO에서 미세 조정된 모델의 추가 샘플들을 보여줍니다.
D.4. ImageNet에서의 클래스 조건부 이미지 합성(Class-Conditional Image Synthesis)
Tab. 10에는 FID와 인셉션 점수(Inception score, IS)로 측정된 우리의 클래스 조건부 LDM(Latent Diffusion Models)의 결과가 포함되어 있습니다. LDM-8은 매우 경쟁력 있는 성능을 달성하기 위해 훨씬 적은 파라미터와 계산 요구 사항이 필요합니다(see Tab. 18 참조). 이전 연구와 마찬가지로, 우리는 각 노이즈 스케일에 대한 분류기를 훈련시키고 이를 가이드하여 성능을 더욱 향상시킬 수 있습니다.
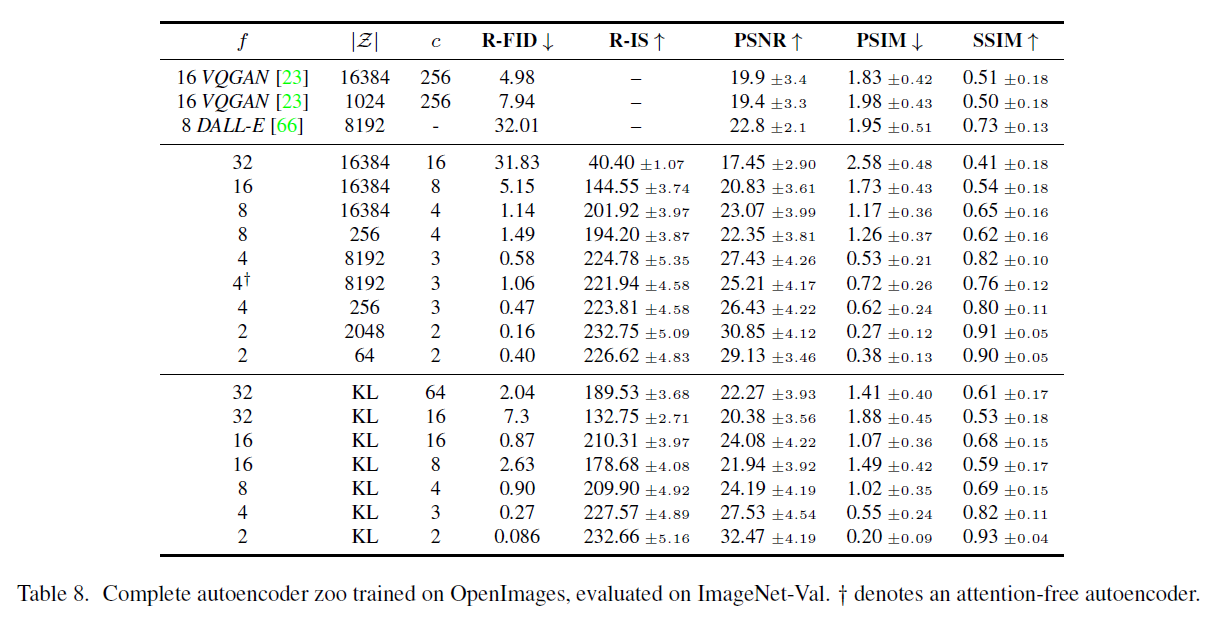
표 8. OpenImages에서 학습된 완전한 오토인코더(autoencoder) 동물원이 ImageNet-Val에서 평가되었습니다. 는 주의 기능이 없는 오토인코더를 나타냅니다.

그림 16. OpenImages 데이터셋에서 학습되고 COCO 데이터셋에서 미세 조정된 우리의 최고 모델 로부터의 레이아웃-이미지 합성(layout-to-image synthesis) 샘플들입니다. 샘플들은 100 DDIM 단계와 으로 생성되었습니다. 레이아웃은 COCO 검증 세트에서 가져왔습니다.
C절을 참조하세요. 픽셀 기반 방법들과 달리, 이 분류기는 잠재 공간(latent space)에서 매우 저렴하게 학습됩니다. 추가적인 질적 결과는 그림 26과 그림 27을 참조하세요.
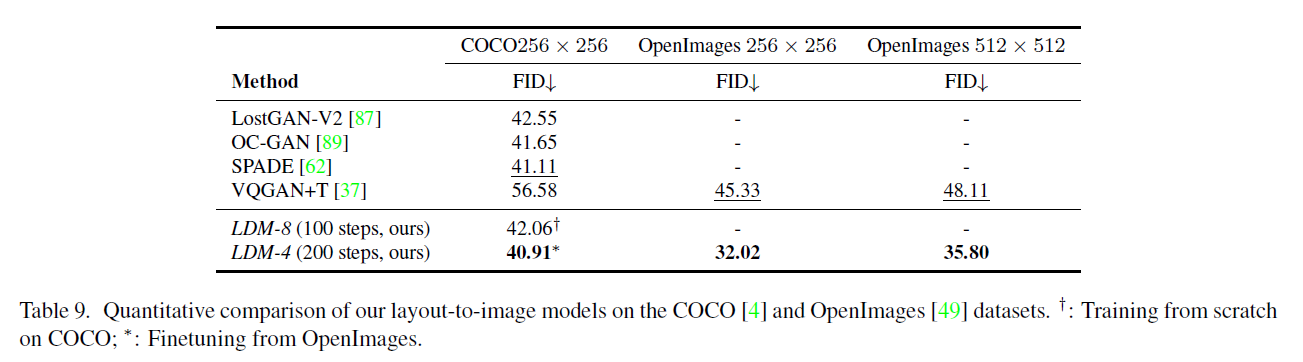
표 9. COCO [4] 및 OpenImages [49] 데이터셋에서 우리의 레이아웃-이미지 모델들의 정량적 비교. : COCO에서 처음부터 학습; : OpenImages에서 미세 조정.
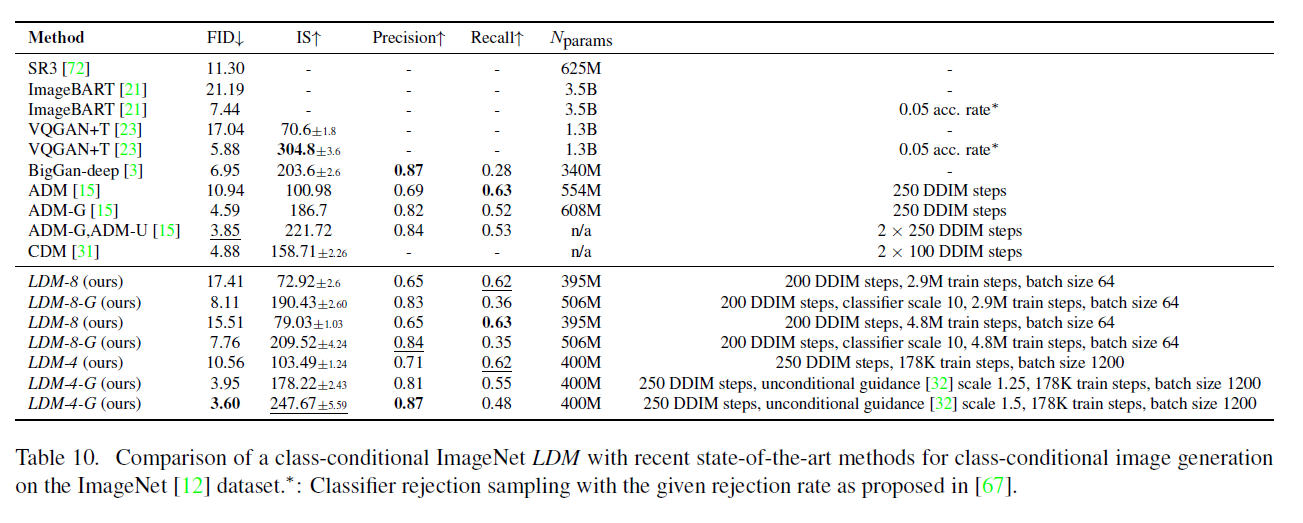
표 10. ImageNet [12] 데이터셋에서 클래스 조건부 이미지 생성을 위한 최신 기술과의 비교: 클래스 조건부 ImageNet . *: [67]에서 제안된 거부율을 가진 분류기 거부 샘플링(classifier rejection sampling).
D.5. 샘플 품질 대비 V100 일수 (4.1절에서 계속)
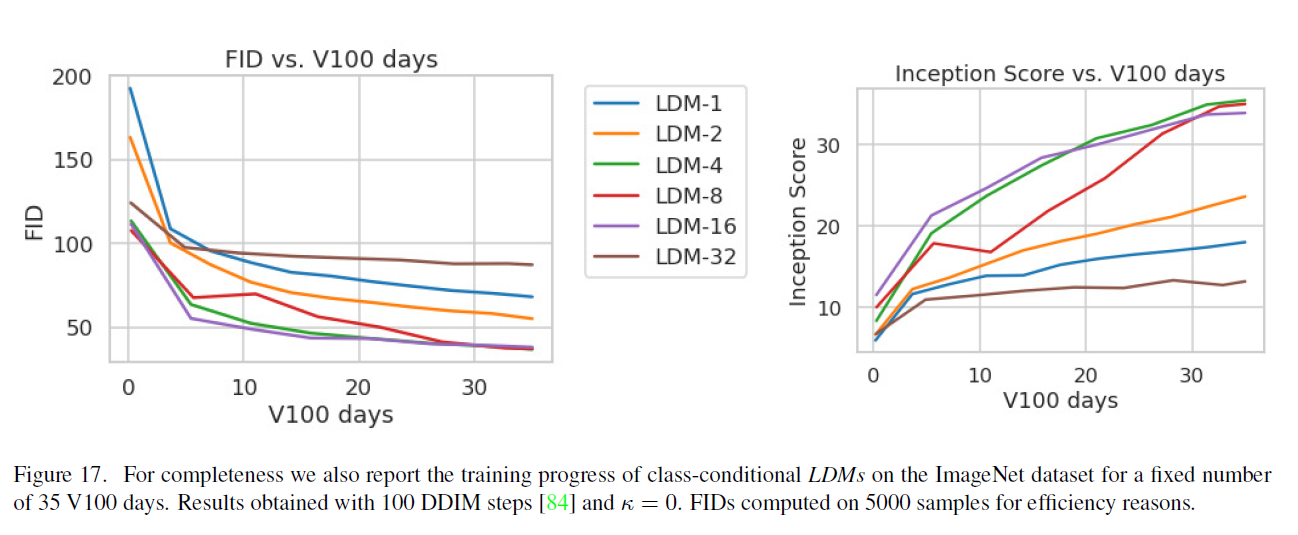
그림 17. 완전성을 위해 우리는 또한 35 V100 일수로 고정된 기간 동안 ImageNet 데이터셋에서 클래스 조건부 의 훈련 진행 상황을 보고합니다. 결과는 100 DDIM 단계 [84]와 을 사용하여 얻었습니다. 효율성을 위해 5000개의 샘플에서 계산된 FIDs.
4.1절에서 훈련 진행에 따른 샘플 품질 평가를 위해, 우리는 훈련 단계에 따른 FID와 IS 점수를 함수로 보고했습니다. 다른 가능성은 이러한 메트릭을 V100 일수로 사용된 자원에 대해 보고하는 것입니다. 이러한 분석은 그림 17에서 추가적으로 제공되며, 질적으로 유사한 결과를 보여줍니다.
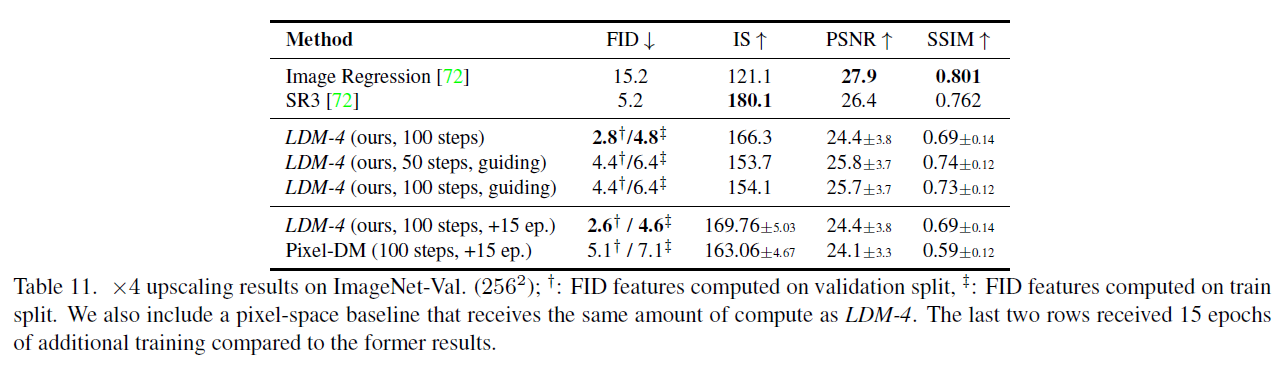
표 11. ImageNet-Val에서의 업스케일링 결과. : 검증 분할에서 계산된 FID 특징, : 훈련 분할에서 계산된 FID 특징. LDM-4와 동일한 계산량을 받는 픽셀 공간 기준선도 포함합니다. 마지막 두 행은 이전 결과에 비해 15 에폭의 추가 훈련을 받았습니다.
D.6. 초해상도(Super-Resolution)
LDM과 픽셀 공간에서의 확산 모델(diffusion models) 간의 비교 가능성을 높이기 위해, Tab. 5에서의 분석을 확장하여 동일한 수의 스텝으로 훈련되고 비슷한 수의 매개변수를 가진 확산 모델과 우리의 LDM을 비교했습니다. 이 비교의 결과는 Tab. 11의 마지막 두 행에 나타나 있으며, LDM이 더 나은 성능을 달성하면서도 훨씬 빠른 샘플링을 가능하게 한다는 것을 보여줍니다. Fig. 20은 LDM과 픽셀 공간에서의 확산 모델 모두에서 무작위 샘플을 보여주며 질적 비교를 제공합니다.
D.6.1 LDM-BSR: 다양한 이미지 열화를 통한 범용 SR 모델

그림 18. 은 임의의 입력에 일반화되며, 일반적인 업샘플러로 사용될 수 있으며, 클래스 조건부 에서 샘플을 해상도로 업스케일링합니다(이미지 . 그림 4). 반면에, 고정된 열화 과정(4.4절 참조)을 사용하면 일반화가 어렵습니다.
우리의 LDM-SR의 일반화를 평가하기 위해, 클래스 조건부 ImageNet 모델(4.1절)에서 합성된 LDM 샘플과 인터넷에서 크롤링한 이미지에 모두 적용해 보았습니다. 흥미롭게도, [72]에서와 같이 바이큐빅(bicubic) 다운샘플링 조건만으로 훈련된 LDM-SR은 이러한 전처리를 따르지 않는 이미지에 잘 일반화되지 않는 것을 관찰했습니다. 따라서, 카메라 노이즈, 압축 아티팩트, 흐림 및 보간과 같은 복잡한 중첩을 포함할 수 있는 다양한 실제 이미지에 대한 초해상도 모델을 얻기 위해, LDM-SR에서 바이큐빅 다운샘플링 작업을 [105]의 열화 파이프라인으로 대체했습니다. BSR-열화 과정은 JPEG 압축 노이즈, 카메라 센서 노이즈, 다운샘플링을 위한 다양한 이미지 보간, 가우시안 블러 커널 및 가우시안 노이즈를 이미지에 무작위 순서로 적용하는 열화 파이프라인입니다. [105]에서와 같은 원래 매개변수를 사용한 bsr-열화 과정은 매우 강력한 열화 과정을 초래한다는 것을 발견했습니다. 우리의 응용에 더 적당한 온건한 열화 과정이 필요해 보였기 때문에, bsr-열화의 매개변수를 조정했습니다(우리가 조정한 열화 과정은 https://github.com/CompVis/latent-diffusion에서 찾을 수 있습니다). 그림 18은 과 을 직접 비교하여 이 접근법의 효과를 보여줍니다. 후자는 고정된 전처리에 국한된 모델들보다 훨씬 더 선명한 이미지를 생성하여 실제 세계의 응용에 적합합니다. 의 추가 결과는 그림 19에서 LSUN-cows에 대해 보여줍니다.[^1]
E. 구현 세부 사항 및 하이퍼파라미터
E.1. 하이퍼파라미터
Tab. 12, Tab. 13, Tab. 14 및 Tab. 15에서 훈련된 모든 LDM 모델의 하이퍼파라미터 개요를 제공합니다.
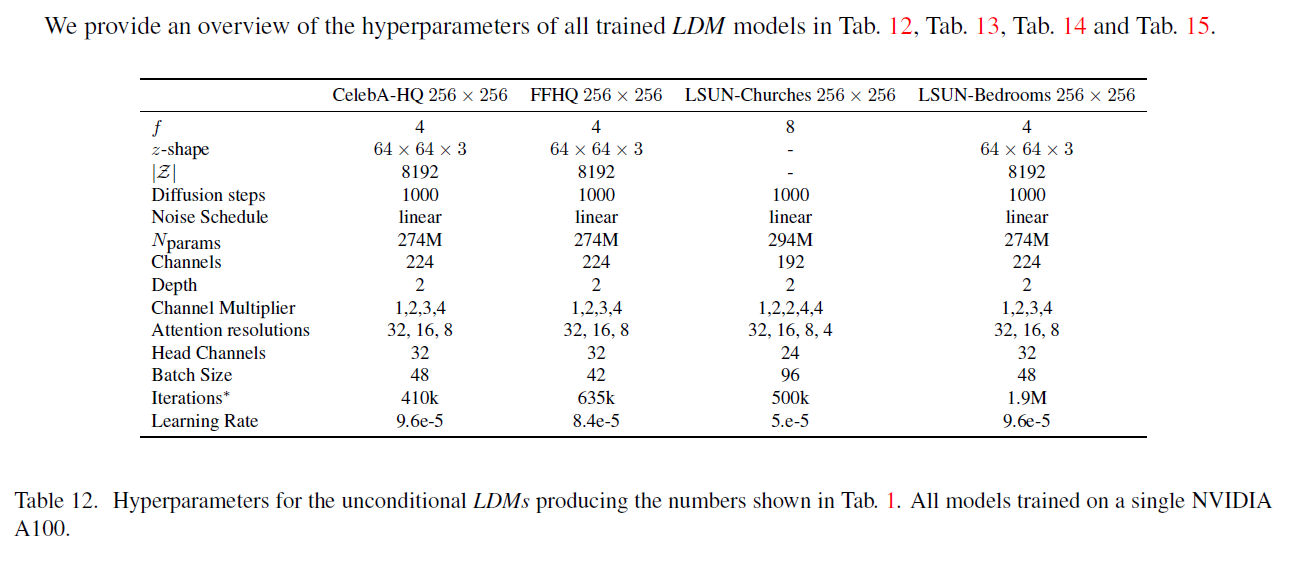
표 12. 조건 없는 LDM(Latent Diffusion Models)이 표 1에 나타낸 결과를 생성하기 위한 하이퍼파라미터들입니다. 모든 모델은 단일 NVIDIA A100에서 훈련되었습니다.
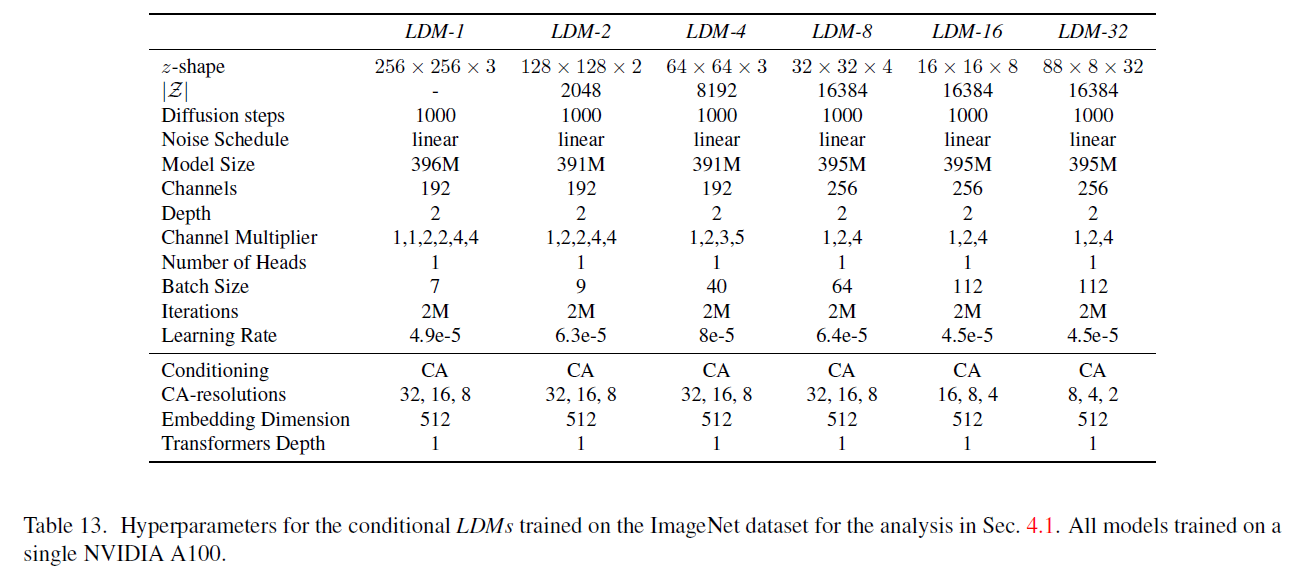
표 13. 4.1절 분석을 위해 ImageNet 데이터셋에 대해 학습된 조건부 LDMs(conditional LDMs)의 하이퍼파라미터. 모든 모델은 단일 NVIDIA A100에서 학습됨.
E.2. 구현 세부 사항
E.2. 1 조건부 에 대한 의 구현
텍스트-이미지(text-to-image) 및 레이아웃-이미지(layout-to-image) 합성(Sec. 4.3.1) 실험을 위해, 우리는 조건자(conditioner) 를 입력 의 토큰화된 버전을 처리하고 출력 를 생성하는 마스크되지 않은 트랜스포머(unmasked transformer)로 구현합니다. 여기서 입니다. 더 구체적으로, 트랜스포머(transformer)는 전역 셀프-어텐션(global self-attention) 레이어, 레이어-노멀라이제이션(layer-normalization), 위치별 MLPs(position-wise MLPs)로 구성된 개의 트랜스포머 블록(transformer blocks)으로 구현됩니다²:[^2]
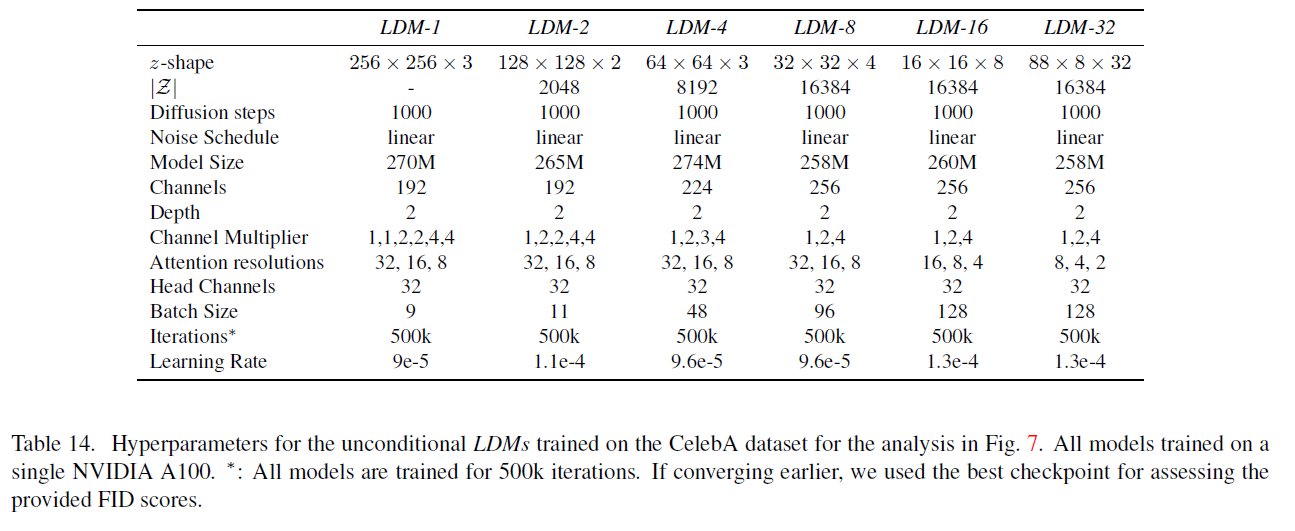
표 14. 그림 7의 분석을 위해 CelebA 데이터셋에서 훈련된 조건 없는 LDM들의 하이퍼파라미터. 모든 모델은 단일 NVIDIA A100에서 훈련됨. *: 모든 모델은 500k 반복으로 훈련됩니다. 더 일찍 수렴하는 경우, 제공된 FID 점수를 평가하기 위해 최고의 체크포인트를 사용했습니다.
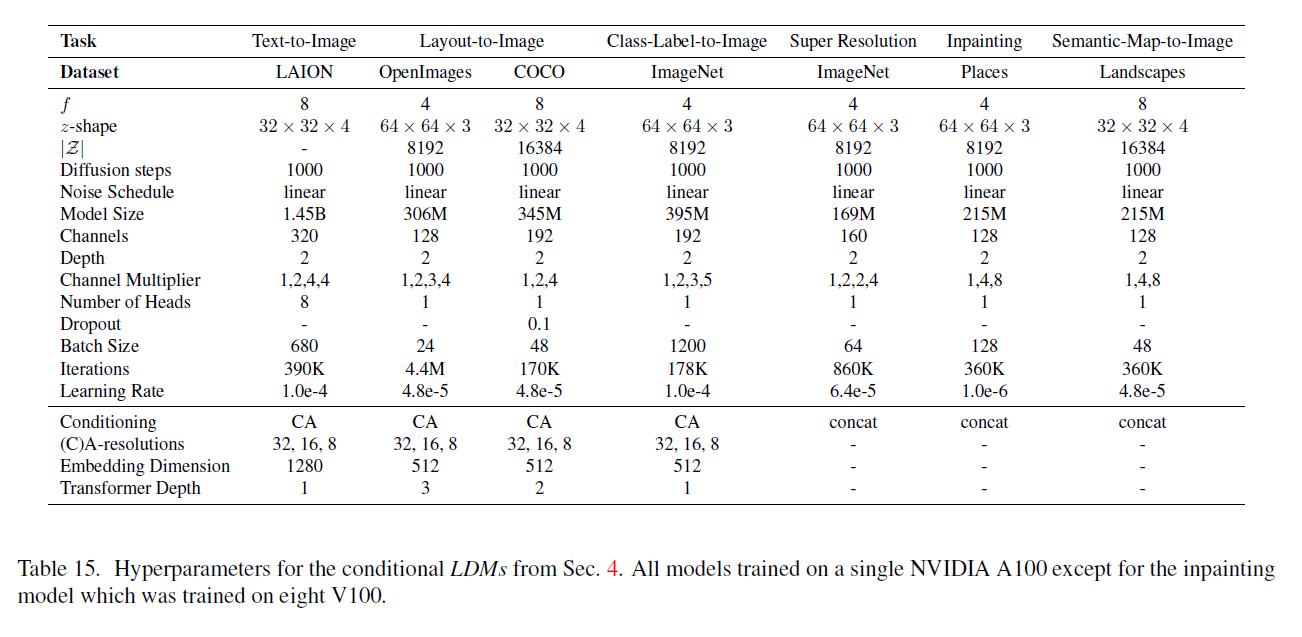
표 15. 4절에서 언급된 조건부 LDM(Latent Diffusion Models)의 하이퍼파라미터입니다. 모든 모델은 단일 NVIDIA A100에서 훈련되었으며, 인페인팅(inpainting) 모델만 8개의 V100에서 훈련되었습니다.
가 준비되면, 조건부 정보는 그림 3에서 보여지는 것처럼 UNet(유넷)에 크로스-어텐션(cross-attention) 메커니즘을 통해 매핑됩니다. 우리는 "ablated UNet" [15] 아키텍처를 수정하고 자기 주의(self-attention) 계층을 얕은 (마스크되지 않은) 트랜스포머(transformer)로 대체합니다. 이 트랜스포머는 (i) 자기 주의, (ii) 위치별 MLP(position-wise MLP), 그리고 (iii) 크로스-어텐션 계층을 번갈아 가며 블록으로 구성됩니다; 표 16을 참조하세요. (ii)와 (iii)가 없다면, 이 아키텍처는 "ablated UNet"와 동일합니다.
시간 단계 에 추가적으로 조건을 부여함으로써 의 표현력을 높일 수 있겠지만, 이는 추론 속도를 늦추기 때문에 우리는 이 선택을 추구하지 않습니다. 이 수정에 대한 더 자세한 분석은 미래의 연구로 남겨둡니다.
텍스트-이미지(text-to-image) 모델의 경우, 공개적으로 사용 가능한 토크나이저(tokenizer) [99]에 의존합니다. 레이아웃-이미지(layout-to-image) 모델은 바운딩 박스의 공간 위치를 이산화하고 각 박스를 -튜플로 인코딩합니다. 여기서 은 (이산적인) 좌상단 위치를, 는 우하단 위치를 나타냅니다. 클래스 정보는 에 포함됩니다.
의 하이퍼파라미터는 표 17을, 위의 두 작업에 대한 UNet의 하이퍼파라미터는 표 13을 참조하세요.
4.1절에서 설명된 클래스 조건부(class-conditional) 모델도 크로스-어텐션을 통해 구현되며, 여기서 는 512의 차원을 가진 단일 학습 가능한 임베딩(embedding) 계층으로, 클래스 를 로 매핑합니다.

표 16. 표준 "ablated UNet" 아키텍처(architecture) [15]의 셀프 어텐션(self-attention) 레이어를 대체하는 변형기(transformer) 블록의 구조를 Sec. E.2.1에서 설명한 것입니다. 여기서 는 어텐션 헤드(attention heads)의 수를 나타내고 는 헤드 당 차원을 나타냅니다.
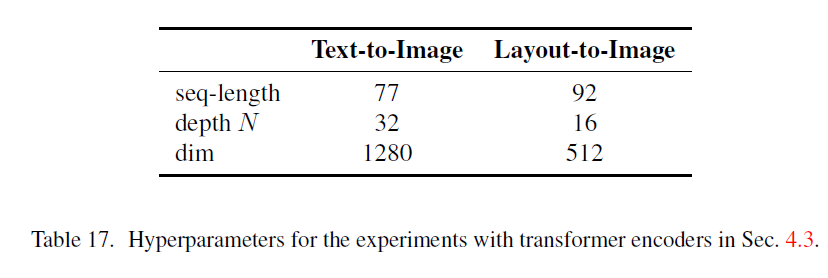
표 17. Sec. 4.3에서 변형기 인코더(transformer encoders) 실험을 위한 하이퍼파라미터(hyperparameters).
E.2.2 이미지 인페인팅(Inpainting)
Sec. 4.5에서 이미지 인페인팅(image-inpainting)에 대한 실험을 위해, 우리는 [88]의 코드를 사용하여 합성 마스크(synthetic masks)를 생성했습니다. 우리는 Places [108]에서 2k의 검증(validation) 샘플과 30k의 테스트(testing) 샘플을 고정된 세트로 사용합니다. 훈련 중에는 크기의 무작위 크롭(random crops)을 사용하고, 크기의 크롭으로 평가합니다. 이는 [88]에서의 훈련 및 테스트 프로토콜을 따르며, 그들이 보고한 메트릭(metrics)을 재현합니다(표 7의 참조). 우리는 Fig. 21에 attn의 추가적인 질적 결과(qualitative results)와 Fig. 22에 , w/o attn, big, 의 결과를 포함합니다.
E.3. 평가 세부 사항(Evaluation Details)
이 섹션은 Sec. 4에서 보여준 실험들에 대한 평가를 위한 추가적인 세부 사항을 제공합니다.
E.3.1 무조건적(Unconditional) 및 클래스 조건부(Class-Conditional) 이미지 합성에서의 정량적 결과(Quantitative Results)
우리는 일반적인 관행을 따라 Tab. 1과 10에 표시된 FID(Frechet Inception Distance)-, Precision- 및 Recall-점수를 계산하기 위한 통계를 우리 모델의 50k 샘플과 각각의 데이터셋의 전체 훈련 세트를 기반으로 추정합니다. FID 점수를 계산하기 위해 우리는 torch-fidelity 패키지[60]를 사용합니다. 그러나, 다른 데이터 처리 파이프라인이 다른 결과를 초래할 수 있기 때문에[64], 우리는 또한 Dhariwal과 Nichol[15]이 제공한 스크립트로 우리 모델을 평가합니다. 우리는 결과[^3]가 주로 일치한다는 것을 발견했지만, ImageNet과 LSUN-Bedrooms 데이터셋에서는 7.76(torch-fidelity) 대 7.77(Nichol과 Dhariwal)과 2.95 대 3.0으로 약간 다른 점수를 관찰했습니다. 미래를 위해, 우리는 샘플 품질 평가를 위한 통일된 절차의 중요성을 강조합니다. Precision과 Recall 또한 Nichol과 Dhariwal이 제공한 스크립트를 사용하여 계산됩니다.
E.3.2 텍스트-이미지 합성(Text-to-Image Synthesis)
[66]의 평가 프로토콜을 따라, 우리는 Tab. 2의 텍스트-이미지 모델들에 대해 MS-COCO 데이터셋[51]의 검증 세트에서 30000개의 샘플과 비교하여 FID와 Inception Score를 계산합니다. FID와 Inception Score는 torch-fidelity로 계산됩니다.
E.3.3 레이아웃-이미지 합성(Layout-to-Image Synthesis)
COCO 데이터셋에서 Tab. 9의 레이아웃-이미지 모델들의 샘플 품질을 평가하기 위해, 우리는 일반적인 관행 을 따라 COCO Segmentation Challenge 분할의 2048개의 비증강 예시를 기반으로 FID 점수를 계산합니다. 더 나은 비교를 위해, 우리는 [37]에서와 동일한 샘플을 사용합니다. OpenImages 데이터셋에 대해서도 비슷한 프로토콜을 따라 검증 세트에서 중앙을 자른 2048개의 테스트 이미지를 사용합니다.
E.3.4 초고해상도(Super Resolution)
우리는 [72]에서 제안된 파이프라인을 따라 ImageNet에서 초고해상도 모델을 평가합니다. 즉, 짧은 크기가 미만인 이미지는 제거됩니다(훈련 및 평가 모두에 대해). ImageNet에서 저해상도 이미지는 안티앨리어싱을 포함한 바이큐빅 보간법(bicubic interpolation)을 사용하여 생성됩니다. FID는 torch-fidelity[60]를 사용하여 평가되며, 우리는 검증 분할에서 샘플을 생성합니다. FID 점수의 경우, 우리는 추가적으로 훈련 분할에서 계산된 참조 특징과 비교합니다. Tab. 5와 Tab. 11을 참조하세요.
E.3.5 효율성 분석(Efficiency Analysis)
효율성을 위해, 우리는 Fig. 6, 17, 그리고 7에 표시된 샘플 품질 메트릭을 5k 샘플을 기반으로 계산합니다. 따라서, 결과는 Tab. 1과 10에 표시된 것과 다를 수 있습니다. 모든 모델은 Tab. 13과 14에 제공된 것처럼 비교 가능한 매개변수 수를 가지고 있습니다. 우리는 개별 모델의 학습률을 안정적으로 훈련할 수 있을 만큼 최대화합니다. 따라서, 학습률은 다른 실행 사이에서 약간 변동합니다. Tab. 13과 14를 참조하세요.
E.3.6 사용자 연구(User Study)
Tab. 4에 제시된 사용자 연구 결과에 대해, 우리는 [72]의 프로토콜을 따랐고, 두 가지 구별되는 작업에 대한 인간의 선호도 점수를 평가하기 위해 2-대안 강제 선택 패러다임(two-alternative forced-choice paradigm)을 사용했습니다. 작업-1에서는 참가자들에게 저해상도/마스킹된 이미지와 해당하는 고해상도/마스킹되지 않은 원본 이미지, 그리고 중간 이미지를 조건으로 사용하여 생성된 합성 이미지를 보여주었습니다. 초해상도(SuperResolution) 작업에서는 참가자들에게 '중간의 저해상도 이미지의 고품질 버전으로 더 나은 것은 두 이미지 중 어느 것입니까?'라고 물었습니다. 이미지 복원(Inpainting)에서는 '중간 이미지의 복원된 영역이 더 현실적인 것은 두 이미지 중 어느 것입니까?'라고 물었습니다. 작업-2에서는 인간에게 저해상도/마스킹된 버전을 보여주고 두 가지 경쟁 방법으로 생성된 두 이미지 사이의 선호도를 물었습니다. [72]에서와 마찬가지로, 인간은 응답하기 전에 3초 동안 이미지를 봤습니다.
F. 계산 요구 사항
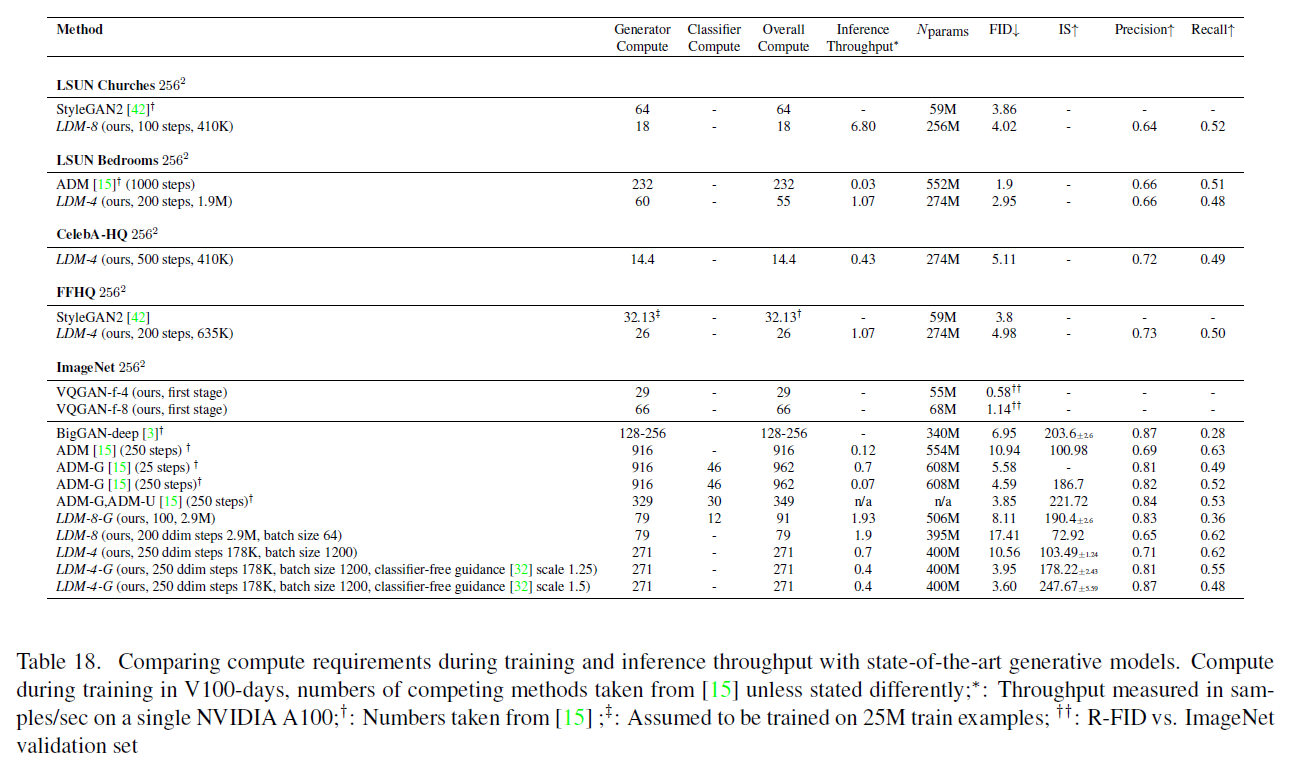
표 18. 훈련 중 컴퓨팅 요구 사항과 최신 생성 모델들과의 추론 처리량 비교. 훈련 중 컴퓨팅은 V100-일로, 경쟁 방법들의 숫자는 [15]에서 가져왔으며 다르게 명시되지 않았습니다;*: 처리량은 단일 NVIDIA A100에서 샘플/초로 측정됨; : 숫자는 [15]에서 가져옴; 훈련 예제에서 훈련된 것으로 가정; : R-FID 대 ImageNet 검증 세트
표 18에서는 우리가 사용한 컴퓨팅 자원에 대한 더 자세한 분석을 제공하고, 제공된 숫자를 사용하여 CelebA-HQ, FFHQ, LSUN 및 ImageNet 데이터셋에서 최고 성능을 내는 모델들을 최근의 최신 모델들과 비교합니다, . [15]. 그들은 사용한 컴퓨팅을 V100 일로 보고하고 있으며, 우리는 모든 모델을 단일 NVIDIA A100 GPU에서 훈련시키기 때문에, A100 대 V100의 속도 향상을 가정하여 A100 일을 V100 일로 변환합니다 [74] . 샘플 품질을 평가하기 위해, 보고된 데이터셋에서 FID 점수도 추가로 보고합니다. 우리는 StyleGAN2 [42] 및 ADM [15]과 같은 최신 방법들의 성능에 근접하면서도 필요한 컴퓨팅 자원을 크게 줄였습니다.[^4]
G. 오토인코더 모델에 대한 상세 정보
우리는 [23]을 따라 모든 오토인코더 모델을 적대적 방식으로 훈련시키므로, 패치 기반 판별자 가 원본 이미지와 재구성 )을 구별하도록 최적화됩니다. 임의로 조정된 잠재 공간을 피하기 위해, 우리는 잠재 가 0 중심이 되고 작은 분산을 얻도록 정규화 손실 항 을 도입합니다.
우리는 두 가지 다른 정규화 방법을 조사합니다: (i) 표준 변분 오토인코더[46,69]에서처럼 와 표준 정규 분포 사이의 낮은 가중치의 쿨백-라이블러 항, 그리고 (ii) 개의 다른 예시들로 구성된 코드북을 학습함으로써 잠재 공간을 정규화하는 벡터 양자화 층 [96].
고해상도 재구성을 얻기 위해, 우리는 두 시나리오 모두 매우 작은 정규화만을 사용합니다, 즉 항을 약 의 요소로 가중하거나 높은 코드북 차원성 를 선택합니다.
오토인코딩 모델 을 훈련하기 위한 전체 목표는 다음과 같습니다:
잠재 공간에서의 DM 훈련(diffusion models training)에 대해, 학습된 잠재 공간에서 확산 모델을 훈련할 때, 우리는 다시 두 가지 경우를 구분합니다. 또는 를 학습할 때 (4.3절 참조): (i) KL-규제 잠재 공간(KL-regularized latent space)의 경우, 우리는 를 샘플링합니다. 여기서 입니다. 잠재 공간을 재조정할 때, 우리는 구성 요소별 분산을 추정합니다.
여기서 입니다. 이는 데이터의 첫 번째 배치에서 계산됩니다. 의 출력은 재조정된 잠재 공간이 단위 표준 편차를 갖도록 스케일링됩니다. 즉, . (ii) VQ-규제 잠재 공간(VQ-regularized latent space)의 경우, 우리는 양자화 계층 이전에 를 추출하고 양자화 연산을 디코더에 통합합니다. 즉, 이것은 의 첫 번째 계층으로 해석될 수 있습니다.
H. 추가적인 질적 결과
마지막으로, 우리는 우리의 풍경 모델(그림 12, 23, 24, 25), 클래스 조건부 ImageNet 모델(그림 26 - 27) 및 CelebA-HQ, FFHQ, LSUN 데이터셋을 위한 무조건부 모델(그림 28 - 31)에 대한 추가적인 질적 결과를 제공합니다. 4.5절의 인페인팅 모델(inpainting model)과 마찬가지로, 우리는 4.3.2절의 의미 있는 풍경 모델(semantic landscapes model)을 직접 이미지에서 미세 조정하고 그림 12와 그림 23에서 질적 결과를 묘사합니다. 비교적 작은 데이터셋에서 훈련된 우리 모델들의 경우, 우리는 VGG [79] 특징 공간에서 우리 모델의 샘플에 대한 가장 가까운 이웃을 그림 32 - 34에서 추가로 보여줍니다.

그림 19. 은 임의의 입력에 일반화될 수 있으며, LSUNCows 데이터셋의 샘플을 해상도로 업스케일링하는 범용 업샘플러로 사용될 수 있습니다.

그림 20. LDM-SR과 기준-확산모델(baseline-diffusionmodel) 간의 픽셀공간(Pixelspace)에서의 무작위 샘플 두 개에 대한 질적 초해상도 비교. 같은 훈련 단계 후 imagenet 검증 세트에서 평가됨.

그림 21. 이미지 인페인팅(image inpainting)에 대한 질적 결과. [88]과 달리, 우리의 생성적 접근법은 주어진 입력에 대해 다양한 샘플을 생성할 수 있습니다.

그림 22. 그림 11에서와 같이 객체 제거(object removal)에 대한 더 많은 질적 결과.

그림 23. 4.3.2절에서 언급된 것처럼 의미론적 풍경(semantic landscapes) 모델에서의 합성곱 샘플들, 이미지에 미세조정됨.

그림 24. 해상도에서 훈련된 은 의미론적 합성(semantic synthesis)과 같은 공간적으로 조건화된 과제에서 더 큰 해상도로 일반화될 수 있습니다. 4.3.2절을 참조하세요.

그림 25. 의미론적 지도(semantic map)를 조건으로 제공할 때, 우리의 는 훈련 중에 본 것보다 훨씬 큰 해상도로 일반화됩니다. 이 모델은 크기의 입력으로 훈련되었지만, 여기에 표시된 것과 같은 고해상도 샘플을 생성하는 데 사용될 수 있으며, 이 샘플들은 해상도입니다.

그림 26. ImageNet 데이터셋에서 훈련된 의 무작위 샘플들. 분류기 없는 가이드(classifier-free guidance) [32] 스케일 과 200 DDIM 단계, 으로 샘플링됨.

그림 27. ImageNet 데이터셋에서 훈련된 의 무작위 샘플들. 분류기 없는 가이드(classifier-free guidance) [32] 스케일 과 200 DDIM 단계, 으로 샘플링됨.

그림 28. CelebA-HQ 데이터셋에서 가장 성능이 좋은 모델 의 무작위 샘플들. 500 DDIM 단계와 으로 샘플링됨 .

그림 29. FFHQ 데이터셋에서 가장 성능이 좋은 모델 의 무작위 샘플들. 200 DDIM 단계와 로 샘플링됨 (FID ).

그림 30. LSUN-Churches 데이터셋에서 가장 성능이 좋은 모델 LDM-8의 무작위 샘플들. 200 DDIM 단계와 으로 샘플링됨 (FID = 4.48).

그림 31. LSUN-Bedrooms 데이터셋에서 가장 성능이 좋은 모델 의 무작위 샘플들. 200 DDIM 단계와 로 샘플링됨 (FID = 2.95).

그림 32. VGG-16 [79]의 특징 공간에서 계산된 우리의 최고 CelebA-HQ 모델의 가장 가까운 이웃들. 가장 왼쪽의 샘플은 우리 모델에서 나온 것입니다. 각 행에 남은 샘플들은 그것의 10개의 가장 가까운 이웃들입니다.

그림 33. VGG-16 [79]의 특징 공간에서 계산된 우리의 최고 FFHQ 모델의 가장 가까운 이웃들. 가장 왼쪽의 샘플은 우리 모델에서 나온 것입니다. 각 행에 남은 샘플들은 그것의 10개의 가장 가까운 이웃들입니다.

그림 34. VGG-16 [79]의 특징 공간에서 계산된 우리의 최고 LSUN-Churches 모델의 가장 가까운 이웃들. 가장 왼쪽의 샘플은 우리 모델에서 나온 것입니다. 각 행에 남은 샘플들은 그것의 10개의 가장 가까운 이웃들입니다.
[^0]: *첫 두 저자는 이 작업에 동등하게 기여했습니다.
[^1]: 확산 모델은 픽셀 공간에서 작동하기 때문에 두 아키텍처를 정확히 일치시키는 것은 불가능합니다
[^2]: https://github.com/lucidrains/x-transformers 에서 변형되었습니다
[^3]: https://huggingface.co/transformers/model_doc/bert.html\#berttokenizerfast
[^4]: 이 요소는 [74]의 그림 1에서 정의된 대로 A100이 V100에 대해 U-Net의 속도를 높이는 것에 해당합니다
