논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
자연어로 그래프 작업을 해결하기 위한 사전 훈련된 언어 모델
Frederik Wenkel Guy Wolf Boris Knyazev
초록
사전 훈련된 대규모 언어 모델(LLMs)은 다양한 언어 작업에서 강력한 학습 능력을 보여줍니다. 그래프가 자연어를 사용하여 설명될 때 LLMs가 그래프 구조 데이터로부터 학습할 수 있는지를 탐구합니다. 우리는 그래프 도메인에 특화된 데이터 증강과 사전 훈련을 탐구하고, GPT-2와 GPT-3과 같은 LLMs가 그래프 신경망(GNNs)에 대한 유망한 대안임을 보여줍니다.
1. 서론
최근 대규모 언어 모델(LLMs)은 언어 작업에서 놀라운 성능을 보여주었습니다(Brown et al., 2020; OpenAI, 2023). 비언어 기계 학습 작업의 경우, 도메인 특화 모델이 지배적이었습니다. 예를 들어, 이미지에 대한 합성곱 신경망(convolutional neural networks)(Wightman et al., 2021)이나 그래프에 대한 그래프 신경망(GNNs)(Kipf & Welling, 2016; Veličković et al., 2017; Rampášek et al., 2022) 등이 있습니다. 그러나 Dinh et al. (2022)은 LLMs, 특히 자동 회귀(auto-regressive) 모델인 GPT-3(Brown et al., 2020)이 표와 이미지 데이터에 대한 분류 및 회귀와 같은 비언어 작업에서도 잘 수행할 수 있음을 보여주었습니다. 이러한 경우에 LLMs는 "픽셀이 인 이미지가 있을 때, 그 클래스는 무엇이어야 하는가?"와 같은 텍스트 프롬프트를 완성하도록 미세 조정됩니다. 이 방향으로, Jablonka et al. (2023)은 LLMs가 화학 도메인에서도 잘 수행될 수 있음을 보여주었습니다. 그들의 경우, IUPAC 이름, SMILES, SELFIES와 같은 화학 형식 중 하나로 제공된 문자열 표현이 LLMs에게 프롬프트로 제공됩니다. 예를 들어, 프롬프트는 "COc 1 cc(N 2 CCN(C) CC 2) c 3 nc \ldots 의 친수성은 무엇인가?"일 수 있고, LLMs는 프롬프트를 분자의 속성 값으로 완성하도록 미세 조정됩니다(Jablonka et al., 2023). 그들은 이 접근 방식이 GNNs를 포함한 다른 일반적인 방법들과 경쟁력이 있다는 것을 보여주었으며, 특히 Wang et al. (2022)에서는 IUPAC 이름, SMILES, SELFIES 표현을 사용하여 강력한 화학적 사전 지식을 활용합니다.
이 연구에서는 IUPAC 이름, SMILES, SELFIES와 같은 도메인 특화 표현을 사용할 수 없을 때 LLMs가 일반적인 그래프 학습자로서 효과적인지를 이해하고자 합니다. Dinh et al. (2022)의 표 데이터 프롬프트에 따라, 우리는 자연어를 사용하여 그래프를 설명하는 프롬프트를 제안합니다. 이를 위해, 그래프를 설명하기 위해 개발된 간단한 언어인 그래프 모델링 언어(Graph Modelling Language, GML)를 Himsolt (1997)이 제안한 것을 다시 살펴봅니다. 예를 들어, 세 개의 노드와 세 개의 엣지를 가진 그래프는 다음과 같이 설명될 수 있습니다:

기여. 우리는 사전 훈련된 LLM(대규모 언어 모델)이 GML(Graph Markup Language) 기반 프롬프트에 미세 조정되어 그래프 학습 작업을 해결하는 데 유망한 접근 방식임을 보여줍니다. 우리의 주요 기여는 두 가지입니다:
-
그래프를 기술하는 GML 기반의 설명을 토큰 당 그래프 수로 2배 이상 압축할 수 있음을 보여주며, 이는 하류 성능에 거의 영향을 주지 않습니다.
-
GPT-2와 세 가지 GPT-3 변형을 CYCLES와 ZINC(Gómez-Bombarelli et al., 2018; Dwivedi et al., 2020)에서 평가함으로써, 더 강력한 LLM을 사용하는 것이 더 나은 하류 그래프 성능을 가져온다는 것을 보여줍니다. 우리의 평가는 현재 GML 기반 프롬프트와 LLM을 사용하는 것이 GNN(그래프 신경망)에 비해 열등하다는 것을 보여주지만, 스케일링 추세는 LLM이 결국 GNN과 경쟁할 수 있을 것임을 시사합니다.
우리는 또한 GNN 접근법의 성공에 중요한 노드 순열 불변성 원칙에 의해 동기를 부여받은 그래프 데이터에 대한 데이터 증강 전략을 제안하여 일반화를 개선합니다. 우리는 또한 LLM과 GNN 사이의 격차를 좁히기 위한 잠재적인 방법으로 그래프 작업에 대한 사전 훈련을 탐구하지만, 이러한 사전 훈련은 초기 미세 조정 반복에서만 도움이 되며, 훈련 끝에 큰 이득을 가져오지 않아 추가 조사가 필요함을 발견했습니다.
2. 관련 연구
우리의 연구는 강력한 그래프 유도 편향을 가진 GNN과 경쟁할 수 있음에도 불구하고 약한 그래프 유도 편향을 가진 순수 트랜스포머(Kim et al., 2022)와 연결되어 있습니다. 순수 트랜스포머는 수백만 개의 샘플이 포함된 대규모 데이터에서 훈련함으로써 이를 달성하는 반면, 우리는 LLM의 사전 훈련 능력을 활용하여 이를 달성하고자 합니다. 그러나 LLM은 명시적으로 정의된 노드와 엣지 식별자가 없기 때문에 순수 트랜스포머보다 더 약한 유도 선행을 가지고 있다는 점을 지적합니다.
최근 Wang et al. (2023)의 연구도 자연어를 사용하여 그래프 작업을 해결하기 위해 LLM(GPT-3/4)을 탐구했습니다. 그들은 예비 그래프 추론 능력이나 다른 프롬프팅 기술의 효과를 연구하기 위해 점차 복잡해지는 인공 그래프 문제들의 컬렉션을 제안합니다. 이는 우리의 작업과 약간 직교적이며, 우리는 ZINC(Dwivedi et al., 2020)와 같은 실제 데이터에 초점을 맞추고 LLM의 능력을 최신 GNN과 비교합니다.
Flam-Shepherd & Aspuru-Guzik (2023)은 분자 그래프에 대한 강력한 생성 능력을 보여주었지만, Jablonka et al. (2023)과 마찬가지로 화학 문자열 표현을 사용했기 때문에 이 접근법은 화학 데이터에만 제한됩니다. 예를 들어, 이는 우리의 작업에서 수행한 것처럼 합성 또는 도메인 외 데이터에 대한 사전 훈련을 허용하지 않습니다.
표 1. GPT-3 (Ada)를 사용하여 ZINC 테스트 그래프에 대한 프롬프트 디자인 접근법 및 각각의 토큰 수 및 평균 절대 오차(MAE).

3. 방법론
3.1. 프롬프트 디자인
프롬프트가 구성되는 정확한 방식은 LLM(Large Language Model)이 프롬프트와 완성 사이의 관계를 파악하는 능력에 영향을 미치고, 또한 토큰의 수와 그에 따른 미세 조정(fine-tuning)의 계산 비용에 영향을 미치기 때문에 중요합니다. 예를 들어, OpenAI의 GPT-3 미세 조정 비용과 모델 사용은 토큰 당 가격이 책정되어 있으며, 예를 들어, 훈련: 토큰, 사용: 토큰 입니다. 따라서, 정보 대비 비용의 균형을 잘 맞추기 위해 두 가지 접근 방식을 고려하고, ZINC 분자 데이터셋(Dwivedi et al., 2020)의 예를 사용하여 설명합니다.
전체 텍스트. 전체 텍스트 접근 방식은 그래프 모델링 언어(Graph Modelling Language)와 매우 유사합니다. 이 방식은 인간에게 더 많은 정보를 제공하는 것처럼 보이지만(다음에 설명할 축소된 텍스트 접근 방식보다), 길이가 길고 다음과 같이 구성됩니다.
프롬프트:

완성:
점수는 -0.2089 입니다.
축소된 텍스트. 필수적인 그래프 정보를 잃지 않으면서 토큰의 수를 줄이기 위해, 우리는 프롬프트를 다음과 같이 구성하는 것을 고려합니다.


프롬프트:
9개의 노드를 가진 그래프: ,[^1]; 엣지: 01 단일, 10 단일, 12 단일, ... , 87 단일.
완성:
점수: .
다양한 프롬프트 디자인과 압축 전략에 대한 추가 연구는 부록의 ?? 섹션에서 찾을 수 있습니다.
3.2. 데이터 증강
Dinh et al. (2022)에서 보여준 것처럼, LLMs의 일반화 성능을 향상시키기 위해 데이터 증강 전략을 사용하는 것이 유익합니다. 우리도 이 접근 방식을 따라 LLMs에 전달되는 노드 식별자(위의 예시에서는 숫자 0부터 8까지)와 관련된 엣지 소스 및 타겟을 순열로 바꾸어 사용합니다. 이는 두 가지 목적을 달성합니다: (i) 모델이 개별 분자를 "지문"으로 사용하는 것을 방지하고, (ii) LLMs가 노드(식별자) 순열 불변 표현을 학습하도록 장려하는 것으로, 이는 그래프 학습에서 기본적인 실천(Wu et al., 2020)이며 대부분의 GNNs는 설계상 만족합니다.
4. 실험
설정. 우리는 주로 GPT-2를 실험에 사용합니다(Radford et al., 2019). 이는 계산적으로 실행 가능하며 미세 조정하기가 간단하기 때문입니다. 우리는 ZINC 데이터셋의 표준 훈련, 검증, 테스트 분할을 따르며, 훈련, 검증 및 테스트 그래프를 사용합니다(Dwivedi et al., 2020). CYCLES 데이터셋의 경우, 훈련, 검증 및 테스트 그래프를 사용합니다.
우리는 다양한 훈련 체제를 실험합니다: GPT-2와 GPT-3은 각각 언어 데이터에 사전 훈련된 GPT 모델의 반복입니다. 우리는 제안된 증강 전략이 사용된 경우 +aug를 추가하고, CYCLES 데이터셋(Dwivedi et al., 2020)에서 추가 사전 훈련이 수행된 경우 를 추가합니다. 완전성을 위해, 전혀 사전 훈련되지 않은 바닐라 GPT2 모델, GPT-2-scratch도 포함합니다.
GPT-3 미세 조정을 위해 공식 지침 을 사용하고 세 가지 변형(ada, babbage, curie)을 미세 조정합니다.
결과. 표 2에서는 CYCLES 및 ZINC 데이터셋(Dwivedi et al., 2020)에 대한 LLM 아키텍처의 선택과 인기 있는 GNN 모델의 선택을 비교하여 결과를 보고합니다.
ZINC 데이터셋에서, 우리는 GPT 모델의 후속 반복이 점점 더 잘 수행되는 것을 관찰하며, GPT-3 (Curie)는 GIN(Xu et al., 2019)과 같은 전문 그래프 학습 접근법에 근접합니다. 또한, 더 큰 GPT-3 변형(Babbage)을 축소된 프롬프트에서 훈련시키면[^2]
표 2. CYCLES(정확도; 높을수록 좋음) 및 ZINC(MAE; 낮을수록 좋음)의 주요 결과. 더 많은 결과는 표 ??에서 확인할 수 있습니다.
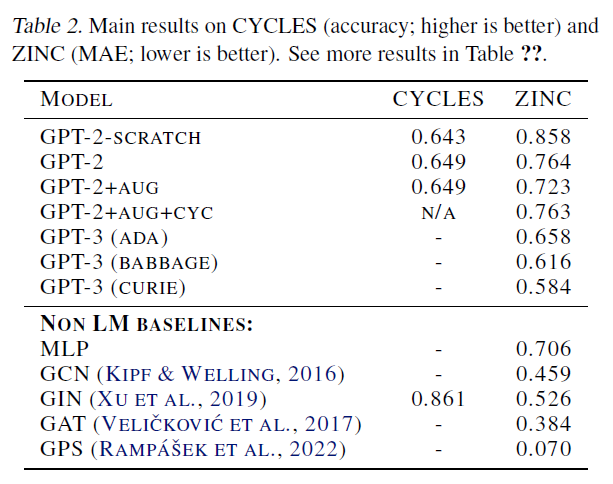
작은 GPT-3 변형체(Ada)를 전체 텍스트 프롬프트에서 학습하는 것과 같은 결과(0.616)를 얻으면서도 더 저렴한 비용( $$ 15.59)으로 가능합니다. 따라서 프롬프트 크기를 더 줄이면서 모델의 용량을 늘리는 것이 결과를 개선하는 실현 가능한 접근법일 수 있습니다.
우리는 GPT-2의 경우, 대규모 언어 모델(LLM) 성능을 향상시키기 위한 여러 전략의 장점을 추가로 조사했습니다. 우리는 먼저 언어 사전학습(language pretraining)을 거친 GPT-2가 처음부터 모델을 학습하는 것(GPT2-scratch)보다 확실히 더 나은 성능을 보인다는 것을 관찰했는데, 이는 언어 사전학습을 거친 LLM이 그래프 학습 작업(graph learning tasks)에 미세조정(fine-tuned)되기에 좋은 후보임을 나타냅니다.
둘째, 제안된 데이터 증강 전략(data augmentation strategy) (3.2절)이 성능을 눈에 띄게 향상시킨다는 것을 관찰했는데, 이는 LLM이 순열 불변성(permutation invariance)의 개념을 학습을 통해 "이해"하도록 장려하는 것이 유익하다는 것을 제안합니다.
또한, 사이클 데이터셋(CYCLES dataset)을 사용하여 그래프 데이터(graph data)에 대한 추가 사전학습(GPT-2+aug+cyc)을 실험했습니다(Dwivedi et al., 2020). 이 작업은 징크(ZINC)에 대한 사전학습에 유익할 것으로 기대합니다. 왜냐하면 목표인 제한된 용해도(constrained solubility)는 다른 값들 외에도 최소 길이가 여섯 개의 원자로 이루어진 사이클의 수에 의존하기 때문입니다. 이 특정 사전학습은 최종 테스트 성능에 부정적인 영향을 미쳤지만(표 2), 모델 미세조정은 처음에는 더 빠르게 진행되었습니다(예를 들어, 더 낮은 학습 손실을 더 빠르게 달성함) 그림 1에서 볼 수 있듯이. Dwivedi et al. (2020)에서와 마찬가지로, 여기서는 노드가 56개인 그래프와 길이가 여섯인 사이클만 실험했으며, 그래프 사전학습 작업을 정제하는 것(예를 들어, 다양한 길이의 사이클을 포함시킴)이 징크(ZINC)에서의 성능을 더 향상시킬 수 있을 것이라고 가설을 세웠습니다.
사이클 데이터셋(CYCLES dataset)의 경우, 최종 테스트 정확도 측면에서 언어 사전학습 모델 GPT-2가 GPT-scratch보다 약간 개선된 것을 관찰할 수 있습니다. 그러나 언어 사전학습 모델 학습은 더 빠르게 수렴합니다.
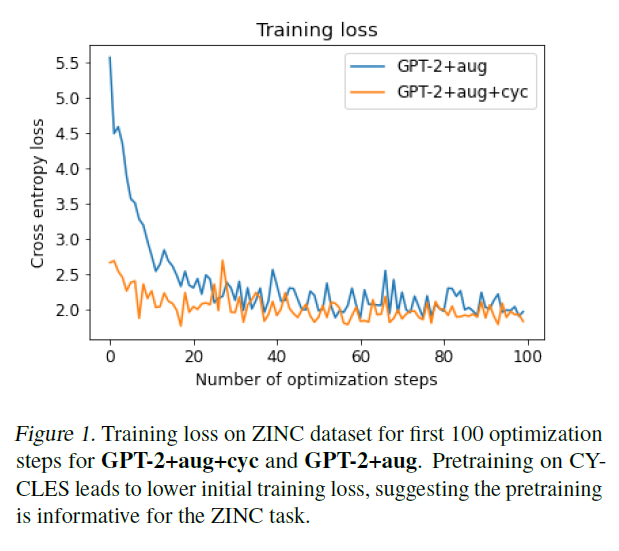
그림 1. ZINC 데이터셋에서 GPT-2+aug+cyc 및 GPT-2+aug에 대한 처음 100개 최적화 단계의 훈련 손실. CYCLES에서의 사전 훈련은 초기 훈련 손실을 낮추는데, 이는 사전 훈련이 ZINC 작업에 유익하다는 것을 시사합니다.
5. 결론
GPT 모델의 상대적으로 낮은 성능에도 불구하고, 자연어를 사용하여 대규모 언어 모델(LLMs)을 미세 조정하는 접근 방식은 많은 가능성을 가지고 있다고 믿습니다. 특히, 이 접근 방식은 LLMs의 방대한 지식을 활용할 수 있게 합니다. 제시된 결과는 ZINC 데이터셋에서 오래된 GPT 모델에서 새로운 GPT 모델로 넘어갈 때 명확한 스케일링 추세를 보여주며, 더 새로운 버전으로 넘어갈 때 더 많은 발전이 있을 것을 약속합니다. 또한, 다양한 그래프 작업에서의 사전 훈련을 통해 노드와 엣지 특성 불일치 문제를 완화할 수 있습니다. 그러나 이러한 사전 훈련의 최선의 방법을 개발하기 위해서는 더 많은 연구가 필요합니다. 또 다른 흥미로운 방향은 추가적인 프롬프트 압축, 그래프를 설명하기 위한 대안적인 "언어" 탐색 및 더 큰 그래프를 가진 데이터셋에서의 작업을 해결할 수 있게 하는 것입니다.
