논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
마인크래프트에서 텍스트 제어를 위한 생성 모델 (요약 버전)
Shalev Lifshitz Keiran Paster Harris Chan Jimmy Ba Sheila McIlraith
초록(Abstract)
텍스트 지시에 반응하는 AI 모델을 구축하는 것은, 특히 순차적 의사결정 작업에 있어서 도전적입니다. 이 연구는 마인크래프트(Minecraft) 를 위한 지시어 튜닝된 비디오 사전학습(Video Pretraining, VPT) 모델인 STEVE-1을 소개하며, DALL 2에서 사용된 unCLIP 접근 방식이 지시어를 따르는 순차적 의사결정 에이전트를 만드는 데에도 효과적임을 보여줍니다. STEVE-1은 두 단계로 훈련됩니다: 사전학습된 VPT 모델을 MineCLIP의 잠재 공간에서 명령을 따르도록 적응시킨 다음, 텍스트에서 잠재 코드를 예측하기 위한 사전을 훈련합니다. 이를 통해 자기 감독적 행동 복제(self-supervised behavioral cloning)와 사후 라벨링(hindsight relabeling)을 통해 VPT를 미세 조정할 수 있으며, 비용이 많이 드는 인간의 텍스트 주석이 필요 없게 됩니다. VPT와 MineCLIP과 같은 사전학습된 모델을 활용하고 텍스트 조건부 이미지 생성에서의 모범 사례를 적용함으로써, STEVE-1은 단지 의 비용으로 훈련할 수 있으며, 마인크래프트에서 다양한 단기간 개방형 텍스트 및 시각적 지시어를 따를 수 있습니다. STEVE-1은 마우스와 키보드와 같은 저수준 제어와 원시 픽셀 입력을 사용하여 마인크래프트에서 개방형 지시어를 따르는 새로운 기준을 설정하며, 이전 기준보다 훨씬 뛰어난 성능을 보여줍니다. 우리는 사전학습, 분류기 없는 안내(classifier-free guidance), 데이터 스케일링을 포함한 하류 성능에 대한 주요 요인을 강조하는 실험적 증거를 제공합니다. 모델 가중치, 훈련 스크립트, 평가 도구를 포함한 모든 자원을 추가 연구를 위해 공개합니다.
1. 서론(Introduction)
텍스트 지시어를 사용하여 강력한 AI 모델을 제어하고 상호작용하는 능력은 이러한 모델들을 대중에게 접근 가능하고 맞춤화할 수 있게 만들었습니다. 이러한 모델에는[^0]
ChatGPT(OpenAI, 2022)가 있으며, 자연어로 작성된 메시지에 반응하고 다양한 작업을 수행할 수 있고, Stable Diffusion(Rombach et al., 2022)은 자연어를 이미지로 변환합니다. 이러한 모델들은 수십만 달러에서 수억 달러의 훈련 비용이 들지만, LLaMA(Touvron et al., 2023)와 같은 강력한 오픈소스 기반 모델들이 놀랍도록 적은 계산과 데이터로 미세 조정되어 지시어를 따르는 모델(e.g., (Taori et al., 2023; Chiang et al., 2023))이 되는 동등하게 흥미로운 추세가 있습니다.
이 논문에서는 이러한 접근 방식이 순차적 의사결정 분야에 적용될 수 있는지를 연구합니다. 텍스트와 이미지 분야와 달리, 순차적 의사결정을 위한 다양한 데이터는 매우 비싸며 종종 이미지에 대한 캡션과 같은 편리한 "지시어" 라벨이 없습니다. 우리는 최근 지시어 튜닝된 LLMs(Large Language Models)인 Alpaca(Taori et al., 2023)에서 본 발전을 반영하여, 사전학습된 행동의 생성 모델을 지시어 튜닝하는 것을 제안합니다.
지난해에는 인기 있는 오픈엔드 비디오 게임 마인크래프트(Minecraft) 를 위한 두 가지 기초 모델(foundation models)이 출시되었습니다: 행동을 위한 기초 모델인 VPT(Baker et al., 2022)와 텍스트와 비디오 클립을 맞추는 모델인 MineCLIP(Fan et al., 2022)입니다. 이는 마인크래프트의 순차적 의사결정 분야에서 지시(instruction)를 따르는 미세조정(fine-tuning)을 탐구하는 흥미로운 길을 열었습니다. VPT는 70k 시간의 마인크래프트 게임 플레이로 훈련되었으므로, 에이전트는 이미 마인크래프트 환경에 대한 방대한 지식을 가지고 있습니다. 그러나 대규모 언어 모델(LLMs)의 엄청난 잠재력이 지시를 따르도록 맞춤으로써 해제되었듯이, VPT 모델도 지시를 따르도록 미세조정(fine-tuned)된다면 일반적이고 제어 가능한 행동을 할 가능성이 있습니다. 특히, 우리의 논문은 단지 의 계산 비용과 약 2,000개의 지시-라벨이 붙은 궤적 세그먼트만을 사용하여 VPT를 짧은 지평선의 텍스트 지시를 따르도록 미세조정하는 방법을 보여줍니다.
우리의 방법은 인기 있는 텍스트-이미지 모델 DALL 를 만드는 데 사용된 접근법인 unCLIP(Ramesh et al., 2022)에서 영감을 받았습니다. 특히, 우리는 지시를 따르는 마인크래프트 에이전트를 만드는 문제를 두 가지 모델로 분해합니다: MineCLIP 잠재 공간에 내재된 시각적 목표를 달성하기 위해 미세조정된 VPT 모델과 텍스트 지시를 MineCLIP 시각 임베딩으로 변환하는 사전 모델입니다. 우리는 행동 복제(behavioral cloning)와 회고적 재라벨링(hindsight relabeling)으로 생성된 자기 감독(self-supervised) 데이터를 사용하여 VPT를 미세조정합니다.
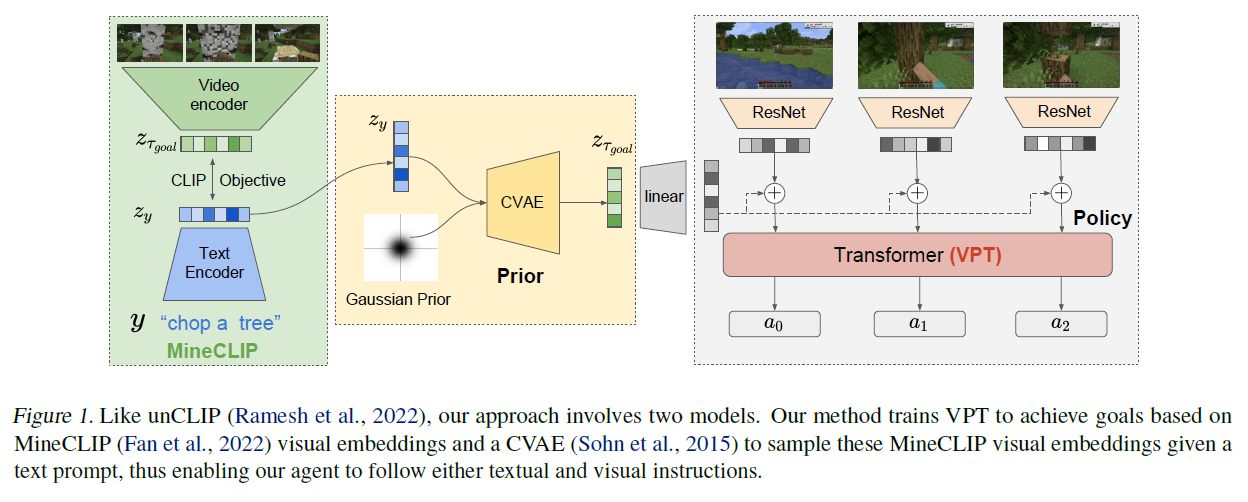
그림 1. unCLIP(Ramesh et al., 2022)과 마찬가지로, 우리의 접근 방식은 두 가지 모델을 포함합니다. 우리의 방법은 VPT를 MineCLIP(Fan et al., 2022) 시각 임베딩을 기반으로 목표를 달성하도록 훈련시키고, 텍스트 프롬프트가 주어졌을 때 이 MineCLIP 시각 임베딩을 샘플링하기 위한 CVAE(Sohn et al., 2015)를 사용함으로써, 우리의 에이전트가 텍스트와 시각적 지시를 따를 수 있도록 합니다.
(Andrychowicz et al., 2017), 비싼 텍스트 지시 라벨을 사용하는 대신 시각적 MineCLIP 임베딩을 선호하여 사용합니다. 우리는 분류기 없는 안내(classifier-free guidance)(Ho and Salimans, 2022)를 사용하여 STEVE-1이라는 우리의 에이전트를 만들었으며, 이는 마우스와 키보드와 같은 저수준 제어와 원시 픽셀 입력을 사용하여 마인크래프트에서 오픈엔드 지시를 따르는 새로운 기준을 설정하고, Baker et al. (2022)에 의해 설정된 기준을 훨씬 뛰어넘습니다.
우리는 STEVE-1의 모델 가중치뿐만 아니라 훈련 스크립트와 평가 코드도 공개하여, 지시 가능한 오픈엔드 순차적 의사결정 에이전트에 대한 연구를 더욱 촉진하고자 합니다. 관련 작업, 어블레이션(ablations), 데이터셋 세부사항, 훈련 세부사항에 대해서는 부록을 참조하십시오. 특히, 부록 B에는 마인크래프트가 AI 연구를 위한 테스트 베드로서의 효과성에 대한 논의가 포함되어 있습니다.
2. 방법
우리의 접근 방식은 최근의 텍스트-이미지 생성 모델인 DALL(Ramesh et al., 2022) 뒤에 있는 unCLIP 방법에서 영감을 받았습니다. 우리의 목표는 텍스트 지시 에 따라 조건화된 마인크래프트(Minecraft) 행동의 생성 모델을 만드는 것입니다. 이를 위해, 일부는 지시 레이블 를 포함하는 마인크래프트 궤적 세그먼트 데이터셋을 활용합니다. 여기서 는 관찰과 행동의 궤적입니다. 또한, 웹에서 마인크래프트 비디오와 대본의 쌍에 대한 대조적 목표를 사용하여 훈련된 사전 훈련된 CLIP 모델인 MineCLIP(Fan et al., 2022)을 사용하여, 정렬된 잠재 변수 를 생성합니다. 여기서 은 궤적에서 연속적인 16개의 타임스텝의 임베딩입니다. 간단한 표기를 위해, 궤적 세그먼트의 마지막 16개 타임스텝의 MineCLIP 임베딩을 로 참조합니다. unCLIP(Ramesh et al., 2022)처럼, 우리는 사전(prior)과 정책(policy)으로 구성된 계층적 모델을 활용합니다:
- 텍스트 지시 에 따라 조건화된 잠재 변수 을 생성하는 사전 .
- 잠재 변수 에 조건화된 궤적을 생성하는 정책 .
이 두 모델은 결합하여 텍스트 지시에 조건화된 행동의 생성 모델을 생성할 수 있습니다:
2.1. 정책(Policy)
우리의 정책을 학습하기 위해, 마인크래프트 행동의 기초 모델인 VPT 를 미세 조정합니다. VPT는 차원이 인 프레임을 처리하는 ResNet(He et al., 2016)과, 프레임 표현을 처리하고 Baker et al. (2022)에서 설명한 공동 계층적 행동 공간을 사용하여 자동 회귀적으로 다음 행동을 예측하는 Transformer-XL(Dai et al., 2019)로 구성됩니다. 목표 정보에 조건을 맞추기 위해 아키텍처를 수정하려면, ResNet의 출력에 의 아핀 변환을 추가하여 트랜스포머로 전달하기 전에 추가합니다:
목표(goal)에 따라 VPT를 미세 조정하기 위해, 우리는 Decision Transformer(Chen et al., 2021), GLAMOR(Paster et al., 2020), GCSL(Ghosh et al., 2021)과 같은 감독된 강화 학습(supervised RL) 접근 방식에서 영감을 받은 방법을 사용하여 모델을 미세 조정합니다. 우리는 회고적 재라벨링(hindsight relabeling)의 변형을 사용하는데
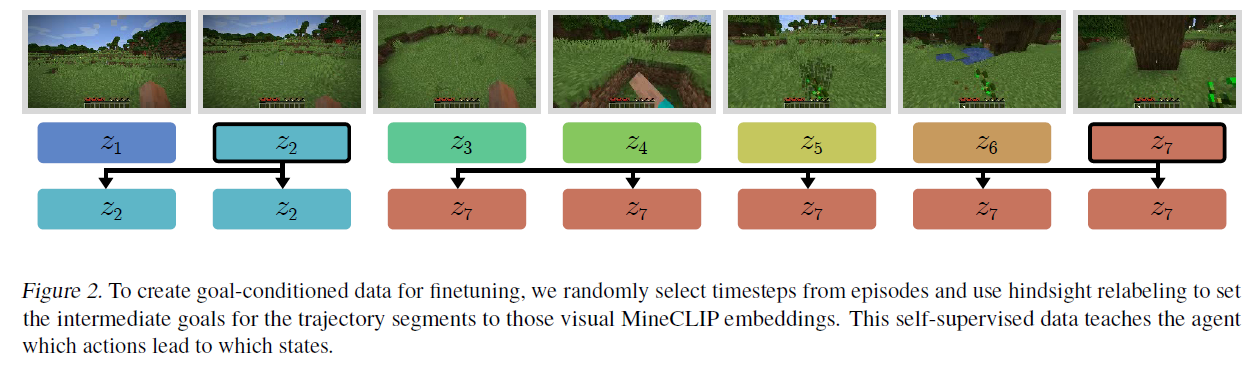
그림 2. 미세 조정을 위한 목표 조건 데이터(goal-conditioned data)를 생성하기 위해, 에피소드에서 무작위로 타임스텝을 선택하고 회고적 재라벨링을 사용하여 궤적 세그먼트의 중간 목표를 해당 시각적 MineCLIP 임베딩으로 설정합니다. 이 자기 감독 데이터(self-supervised data)는 에이전트에게 어떤 행동이 어떤 상태로 이어지는지를 가르칩니다.
우리는 패키지된 회고적 재라벨링(packed hindsight relabeling)이라고 부르는 방법(그림 2 참조)을 사용하여, 주기적으로 전환되는 미래 상태에서 가져온 목표를 가진 새로운 궤적 데이터셋을 생성합니다. 구체적으로, 이 데이터셋을 생성하는 방법은 두 단계로 이루어집니다:
- 타임스텝을 가진 궤적 가 주어졌을 때, 목표를 선택하기 위한 무작위 인덱스를 생성합니다: . 이 인덱스들은 첫 번째 타임스텝에서 시작하여 이전 타임스텝에 무작위 값을 더하여 새로운 타임스텝을 반복적으로 샘플링하여 선택됩니다. 이는 일부 목표가 다른 목표보다 달성하는 데 더 오래 걸릴 수 있다는 데이터를 반영하도록 합니다.
- 타임스텝 에서 선택된 각 목표에 대해, 타임스텝 의 목표를 타임스텝 의 목표인 로 설정합니다.
우리의 최종 데이터셋 은 관측 시퀀스 , 행동 시퀀스 , 그리고 패키지된 회고적 재라벨링 목표 로 구성됩니다. 그런 다음 우리는 인과적 주의 마스크(causal attention mask)를 사용하여 각 행동을 자기 회귀적으로 예측하기 위한 감독된 손실을 사용하여 이 데이터셋에서 VPT를 미세 조정합니다:
2.2. 사전(Prior)
시각적 목표의 임베딩뿐만 아니라 잠재적 목표에도 조건을 부여하기 위해서는 사전(prior), 즉 텍스트 지시 에 기반한 잠재 변수 를 생성하는 모델이 필요합니다. 우리의 모델은 간단한 조건부 변분 오토인코더(Conditional Variational Autoencoder, CVAE) (Sohn et al., 2015; Kingma and Welling, 2014)로, 가우시안(Gaussian) 사전과 가우시안(Gaussian) 사후 확률을 가집니다. 텍스트에 직접 조건을 부여하는 것을 배우기보다는, MineCLIP의 고정된 텍스트 표현 에 조건을 부여하기로 결정했습니다. 우리 CVAE의 인코더와 디코더는 모두 512개의 은닉 유닛을 가진 두 층의 MLP(Multi-Layer Perceptron)로 파라미터화되어 있으며, 레이어 정규화(Layer Normalization) (Ba et al., 2016)를 사용합니다. 우리는 텍스트 레이블 이 있는 데이터셋에서 다음의 손실을 사용하여 모델을 학습합니다:
2.3. 데이터셋(Datasets)
우리의 정책(policy)을 학습하기 위해, 우리는 두 가지 출처에서 Minecraft 게임 플레이의 프레임(달, 20FPS)과 관련된 행동들을 포함한 게임 플레이 데이터셋을 수집했습니다: (1) OpenAI Contractor Dataset (39M 프레임)은 VPT에서 사용된 계약자 데이터셋에서 가져왔고, (2) VPT에서 생성된 데이터셋 (15M 프레임)은 다양한 사전 훈련된 VPT 에이전트들을 사용하여 무작위 궤적을 생성함으로써 만들어졌습니다. 우리의 사전(prior)을 학습하기 위해, 우리는 또한 게임 플레이 데이터셋에서 샘플링된 16 프레임의 비디오와 짝을 이루는 2,000개의 텍스트 지시를 수동으로 수집했습니다. 우리는 MineCLIP에서 텍스트와 비디오 임베딩 사이의 정렬을 사용하여 이 텍스트-비디오 쌍 데이터셋을 확장했습니다. 우리 데이터셋에 대한 더 자세한 내용은 부록 E를 참조하세요.
2.4. 추론(Inference)
추론 시간에는 텍스트 지시문 에서 잠재 목표 을 샘플링하기 위해 사전 확률을 사용합니다. 그런 다음 관측 이력 과 잠재 목표 에 조건을 걸어 정책(policy)을 자동회귀적으로 샘플링하여 행동 을 생성합니다. 또한 이미지 생성 모델에서 사용되는 기술인 분류자-자유 안내(classifier-free guidance) (Ho and Salimans, 2022)를 사용하여, 목표에 조건을 건 정책 과 무조건적인 정책 에 대한 로짓(logits)을 동시에 계산합니다. 그런 다음 두 로짓의 조합을 매개변수를 사용하여 계산하여 두 가지 사이의 균형을 맞춥니다:
의 값을 높게 설정함으로써, 목표에 조건을 건 상황에서 더 가능성이 높은 행동을 따르도록 정책을 장려할 수 있으며, D.2 절에서 보여주듯이 이는 성능을 크게 향상시킵니다. 또한 무조건적인 로짓을 생성하기 위해 정책을 훈련시킬 때, 목표 임베딩 을 정책의 입력에서 드롭아웃(dropout)하기도 합니다(확률 0.1). 이를 통해 추론 시간에 배치 처리를 사용하여 동일한 모델로 조건부 및 무조건부 로짓을 모두 생성할 수 있습니다.
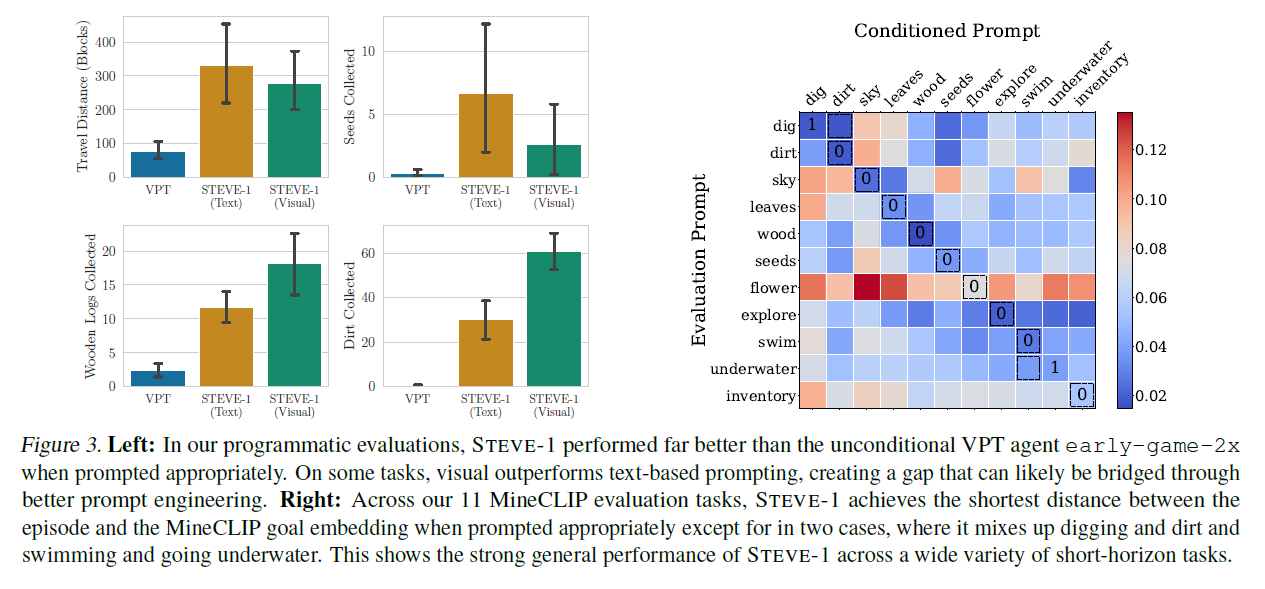
그림 3. 왼쪽: 프로그래밍 평가에서 STEVE-1은 적절한 프롬프트를 사용할 때 초기 게임에서 무조건적인 VPT 에이전트 early-game-2x보다 훨씬 더 나은 성능을 보였습니다. 일부 작업에서는 시각적 프롬프트가 텍스트 기반 프롬프트보다 더 우수한 성능을 보여주며, 이는 더 나은 프롬프트 엔지니어링을 통해 해결될 수 있는 격차를 만들어냈습니다. 오른쪽: 11개의 MineCLIP 평가 작업에서 STEVE-1은 적절한 프롬프트를 사용할 때 두 경우를 제외하고 에피소드와 MineCLIP 목표 임베딩 사이의 가장 짧은 거리를 달성합니다. 여기서는 파기(digging)와 흙(dirt), 수영(swimming)과 물속으로 들어가기(going underwater)를 혼동합니다. 이는 STEVE-1이 다양한 단기 작업에서 강력한 일반적인 성능을 보여준다는 것을 나타냅니다.
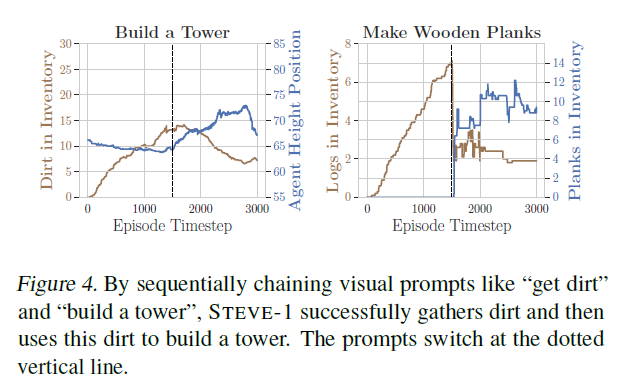
그림 4. "흙을 얻어라(get dirt)"와 "탑을 만들어라(build a tower)"와 같은 시각적 프롬프트를 순차적으로 연결함으로써, STEVE-1은 성공적으로 흙을 모으고 이 흙을 사용하여 탑을 만듭니다. 프롬프트는 점선 수직선에서 전환됩니다.
2.5. 평가
우리는 에이전트의 이동 거리와 초기 게임 아이템 수집(나무, 씨앗, 흙)을 모니터링하여 프로그래매틱 지표(programmatic metrics)를 계산합니다. 또한 에피소드 중 어느 시점에서든 (텍스트 또는 시각적) 목표 임베딩과 MineCLIP 시각 임베딩 사이의 최소 코사인 거리를 기록하여 에이전트의 능력 수준을 평가하기 위한 자동 MineCLIP 지표도 계산합니다. 평가 지표에 대한 자세한 내용은 부록 G를 참조하십시오.
3. 결과
3.1. 텍스트 및 시각적 목표에 대한 성능
우리 모델의 계층적 특성으로 인해, 텍스트 또는 시각적 목표를 달성하는 에이전트의 성능을 단순히 텍스트를 조건으로 사용하거나 사전 조건을 우회하고 MineCLIP 비디오 임베딩을 직접 조건으로 사용하여 평가할 수 있습니다. 우리는 먼저 게임 플레이 첫 2.5분 이내에 달성 가능하고 여러 단계를 요구하지 않는 11가지 작업(예: 나무 자르기 또는 구멍 파기, 하지만 집 짓기는 제외) 세트에서 모델을 테스트했습니다. 그림 3에서, 우리는 프로그래매틱 작업에 대해 텍스트 및 시각적 조건 에이전트와 무조건적인 VPT 에이전트의 성능을 비교합니다. 관련 텍스트 지시를 받았을 때, STEVE-1은 무조건적인 에이전트보다 더 많은 흙, 더 많은 나무, 더 많은 씨앗을 수집하고, 더 멀리 이동합니다. 이는 Baker et al. (2022)의 부록 I에서 보고된 텍스트 조건의 성능을 크게 개선한 것으로, 두 배 긴 에피소드 동안 훨씬 적은 자원을 수집합니다. 우리는 또한 에피소드의 어떤 프레임과도 목표 임베딩의 최소 거리를 측정하여 MineCLIP 임베딩 거리를 사용한 자동 평가를 실행합니다. 그림 14에서 보듯이, 에이전트가 해당 시각적 목표에 조건을 맞추었을 때 목표와 에피소드 사이의 거리가 그렇지 않은 경우보다 현저히 낮습니다. 텍스트 및 시각적 목표를 모두 사용한 STEVE-1의 전체 결과는 부록 H.1에서 찾을 수 있습니다.
STEVE-1의 평가 외에도, 우리는 에이전트와 함께한 여러 샘플 인터랙티브 세션을 기록했습니다(에이전트에게 서면 텍스트 지시를 주거나 특정 시각적 목표를 제시하여 실시간으로 제어). 이 세션들은 STEVE-1이 다양한 상황에서 실시간으로 지시를 민첩하게 따를 수 있는 능력을 보여줍니다. 우리는 이러한 사용 사례가, 인간이 에이전트에게 자연스러운 지시를 주어 작업을 완료할 수 있게 하는 것이 점점 더 중요해지고 가상 세계 캐릭터와 지시 가능한 조수를 만드는 데 실용적인 용도를 가질 것이라고 믿습니다. 이러한 비디오와 평가 작업을 수행하는 우리 에이전트의 비디오는 https://sites.google.com/view/steve-1에서 찾을 수 있습니다.
3.2. 프롬프트 체이닝
우리는 또한 여러 단계를 요구하는 장기적인 과제들, 예를 들어 제작(crafting)과 건축(building)과 같은 작업들에 대한 실험을 진행했습니다. 우리는 두 가지 다른 프롬프트 방법을 탐구했습니다: 목표를 직접 프롬프트하는 방법과, 과제를 여러 하위 과제로 분해하고 프롬프트를 고정된 수의 단계에 걸쳐 순차적으로 제공하는 간단한 형태의 프롬프트 체이닝(prompt chaining) (Chase, 2022; Wei et al., 2022b; Dohan et al., 2022)입니다. 우리는 두 가지 과제에 대해 시각적 목표를 가진 프롬프트 체이닝을 탐구했습니다: 1) 탑 건축과 2) 나무 판자 만들기입니다. 프롬프트 체이닝을 사용할 때, 우리는 먼저 STEVE-1에게 탑을 건축하기 전에 흙을 모으라고 프롬프트하고, 나무 판자를 제작하기 전에 나무 통나무를 모으라고 프롬프트합니다. 그림 4는 최종 과제로 STEVE-1을 직접 프롬프트하면 성공률이 거의 0에 가까워진다는 것을 보여줍니다. 그러나 프롬프트 체이닝을 통해 STEVE-1은 50%의 확률로 탑을 건축하고 70%의 확률로 나무 판자를 제작할 수 있습니다. 탑 건축 과제의 경우, STEVE-1은 프롬프트가 바뀔 때까지 즉시 흙을 모으기 시작하며, 그 시점에서 평균 높이가 급격히 증가하고 탑을 건축함에 따라 흙의 양이 감소합니다. 마찬가지로 나무 판자 제작 과제의 경우, STEVE-1은 프롬프트가 바뀔 때까지 즉시 많은 양의 나무 통나무를 모으기 시작하고, 이를 빠르게 나무 판자로 변환합니다(이로 인해 인벤토리 내의 나무 통나무 양이 즉시 감소하고 제작하는 판자의 수가 증가합니다). 그림 4는 프롬프트 체이닝 에피소드에 대한 평균 아이템 수와 에이전트 높이를 시각화합니다. 부록의 그림 19와 그림 20에서 구체적인 프롬프트 체이닝 에피소드의 시각화를 확인할 수 있습니다. 부록 C에서는 프롬프트 체이닝 성능이 더 많은 데이터와 함께 잘 확장됨을 보여줍니다.
4. 결론
우리는 unCLIP(Ramesh et al., 2022)과 분류자 없는 안내(classifier-free guidance) (Ho and Salimans, 2022)를 적용하여 Minecraft에서 다양한 단기 과제를 달성할 수 있는 강력한 지시 가능한 에이전트인 STEVE-1을 만드는 접근법의 가능성을 보여줍니다. STEVE-1은 텍스트 또는 시각적 목표에 따라 프롬프트될 수 있으며, 단지 $60의 컴퓨팅 비용과 약 2,000개의 지시-라벨이 붙은 궤적 세그먼트만으로 Minecraft에서 강력한 지시 수행 성능을 달성할 수 있습니다. 우리는 프롬프트 체이닝의 초기 버전이 여러 단계의 추론을 요구하는 장기 과제에서 성능을 향상시키는 유망한 접근법임을 보여주며, 향후 작업에서 성능을 개선하기 위해 더 많은 것을 할 수 있습니다.
우리의 접근법은 원시 픽셀(raw pixels)에서 작동하고 저수준 동작(마우스와 키보드)을 생성하는 일반성을 가지고 있기 때문에, 우리는 STEVE-1이 다른 도메인과 환경에서 지시 가능한 에이전트를 만드는 미래의 작업에 불을 지필 수 있기를 바랍니다. 향후 작업은 LLMs의 사용을 통해 장기 과제에서의 성능을 향상시키는 것을 포함하여 STEVE-1의 한계를 해결하는 것을 포함해야 합니다.
A. 더 넓은 영향(Broader Impact)
인공지능의 능력 수준이 높아짐에 따라 많은 잠재적 이점과 위험이 따릅니다. 긍정적인 측면에서, STEVE-1을 만드는 데 사용된 기술들은 로봇공학, 비디오 게임, 웹을 포함한 다른 순차적 의사결정 분야에서 유용한 에이전트를 만드는 데 적용될 수 있을 것으로 기대합니다. 강력하고 지시를 따르는 모델을 만드는 저비용 접근 방식을 시연한 것은 인공지능의 민주화를 개선할 잠재력도 가지고 있습니다. 그러나 부정적인 측면에서, 대규모 인터넷 데이터셋에 사전 학습된 에이전트들은 인터넷의 편향을 반영하며, 우리의 실험에서 제안된 것처럼, 이러한 사전 학습 편향은 지시 조정 후에도 남아있을 수 있습니다. 주의 깊게 다루지 않으면 이는 사회에 파괴적인 결과를 초래할 수 있습니다. 우리는 위험이 낮은 동안, 우리와 같은 작업들이 순차적 의사결정 분야에서 지시를 따르는 모델에 대한 안전 연구 접근성을 향상시킬 수 있기를 바랍니다.
B. 관련 연구
인공지능(AI) 연구의 벤치마크로서 마인크래프트(Minecraft)의 인기는 복잡하고 동적인 환경으로 인해 강화 학습(reinforcement learning) 및 기타 인공지능 방법들에 대한 풍부한 실험대가 되어왔습니다(예: (Johnson et al., 2016; Guss et al., 2019; Fan et al., 2022; Hafner et al., 2023; Nottingham et al., 2023; Wang et al., 2023; Malato et al., 2022; Cai et al., 2023)). 우리는 MineRL 환경(Guss et al., 2019)을 활용하여 복잡한 시각적 환경에서 마우스와 키보드 같은 저수준 동작만을 사용하여 개방형 지시를 따를 수 있는 에이전트를 연구합니다. 우리는 두 개의 최신 기반 모델 위에 STEVE-1을 구축합니다. 텍스트와 비디오를 정렬하기 위해, 마인크래프트 게임 플레이와 관련 캡션의 짝을 이룬 웹 비디오에서 학습된 CLIP(Radford et al., 2021) 모델인 MineCLIP(Fan et al., 2022)을 사용합니다. STEVE-1의 정책을 학습하기 위해, 마인크래프트의 70k 시간 웹 비디오와 추정된 마우스 및 키보드 동작으로 사전 학습된 마인크래프트 행동의 기반 모델인 VPT(Baker et al., 2022)를 미세 조정합니다. 몇몇 이전 연구들(Volum et al., 2022; Wang et al., 2023)은 지시 가능한 마인크래프트 에이전트를 만드는 데 LLMs(대규모 언어 모델)의 사용을 탐구했습니다. 이러한 연구들은 일반적으로 LLMs를 사용하여 고수준 계획을 만들고, 그 다음에는 저수준 RL(Nottingham et al., 2023; Wang et al., 2023) 또는 스크립트(PrismarineJS and Others, 2023) 정책에 의해 실행됩니다. STEVE-1은 훨씬 더 유연한 저수준 정책이기 때문에, STEVE-1과 LLMs의 결합은 미래 연구에 대한 유망한 방향입니다. Fan et al. (2022)은 12가지 다른 작업에 대해 RL을 사용하여 학습된 에이전트를 소개했으며, MineCLIP-embedded 텍스트 프롬프트에 조건을 부여했습니다. 그러나 이 에이전트는 원래의 작업 세트를 넘어 일반화하는 데 실패했습니다.
연속적 의사결정을 위한 기초 모델(Foundation Models for Sequential Decision-Making) 기초 모델(foundation models)은 방대한 양의 데이터로 사전 학습(pretrained)을 한 후 특정 작업에 맞게 미세 조정(finetuned)되며, 최근 언어(Brown et al., 2020; Chowdhery et al., 2022; Touvron et al., 2023), 시각(Ramesh et al., 2022; Caron et al., 2021; Radford et al., 2021), 로보틱스(Brohan et al., 2022; Shridhar et al., 2022; Jiang et al., 2022; Nair et al., 2022; Xiao et al., 2022) 등 다양한 분야에서 큰 가능성을 보여주고 있습니다. GATO(Reed et al., 2022)와 RT-1(Brohan et al., 2022)은 트랜스포머(transformers)를 학습시켜 시뮬레이션된 로봇 작업과 실제 로봇 작업을 수행할 수 있는 잠재력을 보여주었습니다. Q-러닝(Q-learning)을 사용한 Kumar et al. (2023)을 제외하고, 대부분의 경우(Lee et al., 2022; Brohan et al., 2022; Reed et al., 2022)에서 딥 러닝(deep learning)이 대규모 다작업 오프라인-RL(offline-RL) 데이터셋으로 확장되었을 때 감독된 RL(supervised RL)을 사용했습니다. 감독된 RL(예: (Paster et al., 2020; Ghosh et al., 2021; Chen et al., 2021))은 연속적 의사결정 문제를 예측 문제로 설정하여, 모델이 미래의 결과에 따라 다음 행동을 예측하도록 학습하는 방식으로 작동합니다. 이러한 접근법은 단순하고 대규모의 컴퓨팅 및 데이터와 잘 확장되지만, 감독된 RL과 Q-러닝이나 정책 그라디언트(policy gradient) 기반 방법 사이의 트레이드오프(trade-offs)를 이해하기 위해서는 더 많은 연구가 필요합니다(Paster et al., 2022a;b; Brandfonbrener et al., 2022; Strupl et al., 2022). 최근 연구들은 시각-언어 모델을 사용한 회고적 재라벨링(hindsight relabeling)(Andrychowicz et al., 2017)을 탐구하고 있으며, 자연어 재라벨링 지시사항을 생성합니다(Radford et al., 2021; Alayrac et al., 2022). DIAL(Xiao et al., 2022)은 인간이 라벨링한 궤적에 CLIP(Radford et al., 2021)을 미세 조정하여 후보 세트에서 회고적 지시사항을 선택하는 데 사용됩니다. Sumers et al. (2023)은 Flamingo(Alayrac et al., 2022)를 시각-질문 응답(VQA) 작업으로 설정하여 제로샷(zero-shot)으로 회고적 재라벨링을 사용합니다. 반면, STEVE-1은 MineCLIP(Fan et al., 2022) 시각 임베딩이 제공하는 미래 궤적 세그먼트 임베딩을 사용하여 목표를 재라벨링합니다.
텍스트 조건부 생성 모델(Text-Conditioned Generative Models)
최근 텍스트에서 X로 변환하는 모델들, 즉 텍스트에서 이미지로(text-to-image) (예: (Ramesh et al., 2022; Saharia et al., 2022; Rombach et al., 2022)), 텍스트에서 3D로(text-to-3D) (예: (Jun and Nichol, 2023; Lin et al., 2023)), 심지어 텍스트에서 음악으로(text-to-music) (예: (Agostinelli et al., 2023)) 변환하는 모델들에 대한 관심이 폭발적으로 증가하고 있습니다. 이러한 모델들은 일반적으로 이산 토큰(discrete tokens)의 시퀀스를 모델링하는 자동 회귀 변환기(autoregressive transformers) (Vaswani et al., 2017; Brown et al., 2020) 또는 확산 모델(diffusion models) (Ho et al., 2020) 중 하나입니다. 우리의 연구와 가장 관련이 깊은 것은 DALLE 2 (Ramesh et al., 2022)에 사용된 unCLIP 방법입니다. unCLIP은 CLIP (Radford et al., 2021) 임베딩을 통해 이미지를 샘플링하는 생성 확산 모델을 훈련시키는 방식으로 작동합니다. 텍스트를 시각적인 CLIP 임베딩으로 변환하는 사전 모델(prior)과 결합함으로써, unCLIP은 임의의 텍스트 프롬프트에 대해 사실적인 이미지를 생성할 수 있습니다. unCLIP과 많은 다른 확산 기반 접근법들은 훈련 후 모드 커버리지(mode-coverage)와 샘플 충실도(sample fidelity) 사이의 균형을 조절할 수 있는 분류기-자유 안내(classifier-free guidance)라는 기술을 사용합니다 (Ho and Salimans, 2022). 우리는 STEVE-1을 훈련시키기 위해 unCLIP과 분류기-자유 안내의 기본 절차를 활용합니다.
C. 스케일링(Scaling)
최근 언어 모델링 연구에서는 더 많은 데이터로 훈련하거나 더 많은 매개변수를 가진 모델로 훈련함으로써 사전 훈련 FLOPs를 확장하는 것이 하류 작업(downstream tasks)에서의 성능을 향상시킬 수 있다는 것을 발견했습니다 (Kaplan et al., 2020; Suzgun et al., 2022; Wei et al., 2022a). 정확한 일치(exact-match)와 같은 메트릭으로 성능을 측정할 때, 성능 향상이 "급격하게" 나타날 수 있으며 (Wei et al., 2022a), 이는 모델이 더 많은 컴퓨팅 파워로 훈련됨에 따라 갑자기 나타납니다. 여기서 우리는 더 많은 데이터로 훈련함으로써 STEVE-1의 다양한 작업에 대한 성능이 어떻게 확장되는지에 대한 기본적인 이해를 얻고자 합니다 (적절한 학습률 일정이 선택됩니다).
성능 향상을 평가하기 위해, 우리는 먼저 사전 모델(prior)에서 정책(policy)의 성능을 분리하여 측정했으며, 프로그래밍 작업(programmatic tasks) (여행 거리, 씨앗, 나무, 흙)에 대한 훈련을 통해 에이전트의 성능을 측정했습니다 (그림 6). 컴퓨팅 제약으로 인해, 우리는 248M 매개변수를 가진 2x VPT 모델을 사용하기로 결정했습니다. 우리는 씨앗 수집과 여행 거리가 프레임을 넘어서 크게 향상되지 않는 것을 발견했습니다. 게임 플레이를 검토한 결과, 여행 거리는 VPT의 기본 행동인 주변을 돌아다니며 탐험하는 것과 가까워 상대적으로 쉬운 작업이라고 생각합니다. 씨앗 수집의 경우, 성능이 여전히 최적이 아니어서 추가적인 확장이 유익할 수 있다는 것을 시사합니다. 이 가설은 나무와 흙 수집에 대한 성능이 60M 프레임까지 대략 수평을 유지하다가 그 후에 급격히 향상하기 시작한 관찰을 통해 뒷받침됩니다. 그림 6은 STEVE-1이 각 프로그래밍 작업에 대해 관련 있는 vs. 관련 없는 시각적 프롬프트를 조건으로 할 때의 스케일링 곡선을 보여줍니다.
우리는 또한 프롬프트 체이닝(prompt chaining)의 유무에 따른 STEVE-1의 멀티스텝(multi-step) 작업에 대한 스케일링(scaling) 특성을 평가했습니다(그림 5). 프롬프트 체이닝 없이는, 작업들은 STEVE-1에게 훈련하는 동안 계속 도전적인 상태로 남아 있습니다. 그러나 우리는 60M 프레임 이후, STEVE-1이 타워를 만들라는 지시를 받았을 때 나무 로그를 모으고 작은 타워를 건설하는 것을 배웠다는 것을 알아차렸습니다. 이는 아마도 우리의 타워 건설에 대한 시각적 프롬프트가 나무 로그로 만들어진 타워가 건설되는 비디오를 보여주기 때문일 것입니다. 프롬프트 체이닝을 사용하면, STEVE-1의 성능은 더 많은 데이터와 함께 꾸준히 증가합니다. 우리는 이것이 체인된 프롬프트의 성공이 체인 내의 각 요소의 성공을 필요로 하기 때문이라고 추측합니다.
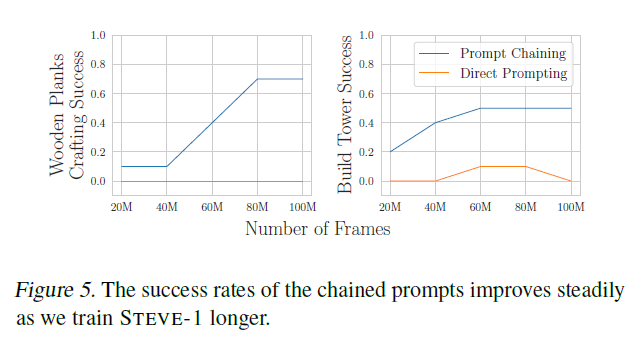
그림 5. STEVE-1을 더 오래 훈련시킬수록 체인된 프롬프트의 성공률이 꾸준히 향상됩니다.
다양한 능력이 다른 규모에서 나타나기 때문에, 체인된 프롬프트는 이러한 하위 목표들이 더 신뢰성 있게 완료됨에 따라 점점 더 신뢰할 수 있게 될 것으로 예상됩니다. 나무 판자를 만드는 경우, 우리는 크래프팅(crafting)이 더 많은 데이터로 에이전트를 훈련시킬수록 훨씬 더 신뢰할 수 있게 되는 작업 중 하나라는 것을 알아차렸습니다. 그림 5는 프롬프트 체이닝 작업에 대한 STEVE-1의 스케일링 곡선을 보여줍니다.
D. Ablations
이 섹션에서는, 우리의 방법에 대한 설계 선택에 대한 제거 실험(ablations)을 설명합니다. 여기에는 사용된 사전 훈련된 모델, 프롬프트 엔지니어링(prompt engineering), 분류자 없는 안내(classifier-free guidance), 텍스트 증강 전략(text augmentation strategies), VAE 훈련, 그리고 파인튜닝(finetuning) 동안의 다양한 청크 크기(chunk sizes)가 포함됩니다. 우리는 프로그래매틱 평가 메트릭스(programmatic evaluation metrics)를 사용하여 다양한 제거 실험의 성능을 비교합니다.
D.1. Pretraining
Baker et al. (2022)은 마인크래프트(Minecraft)에 대한 인터넷 규모의 데이터셋에서 모방 학습(imitation learning)으로 행동 선행 모델(behavioral prior)을 사전 훈련함으로써, 학습된 정책(policy)을 사전 훈련 없이는 불가능한 작업을 수행하도록 효과적으로 파인튜닝할 수 있다는 것을 발견했습니다. 이 섹션에서는, 우리는 마인크래프트에서의 지시 튜닝(instruction-tuning)에 대해서도 사전 훈련이 엄청나게 유익하다는 것을 보여줍니다. 우리는 STEVE-1의 강력한 성능과 지시 파인튜닝에 사용된 상대적으로 적은 계산량( 추가 계산량) 때문에, 우리 에이전트의 대부분의 능력이 파인튜닝보다는 사전 훈련에서 비롯된다고 가설을 세웁니다. 이 가설을 테스트하기 위해, 우리는 다양한 사전 훈련된 가중치로부터 여러 버전의 STEVE-1을 파인튜닝합니다: foundation-2x, bc-early-game-2x,
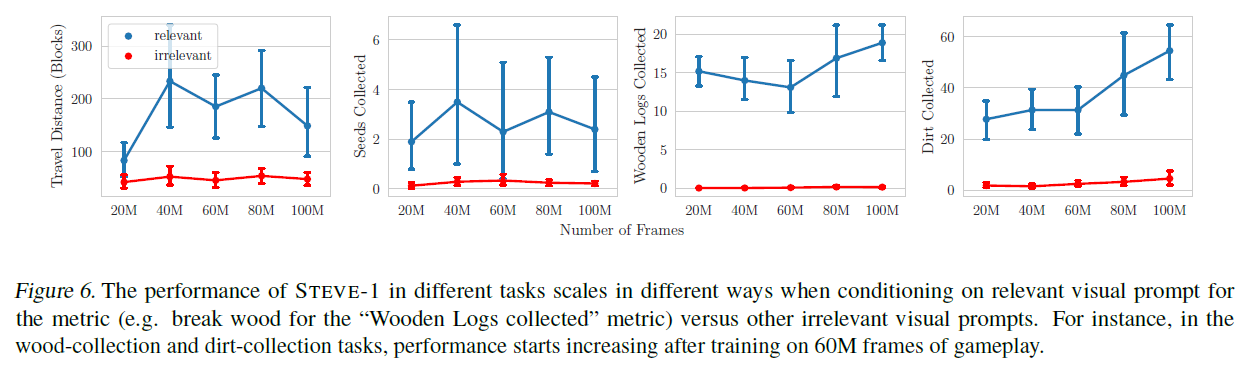
그림 6. STEVE-1의 성능은 관련 시각적 프롬프트(예: "나무 기록 수집" 메트릭에 대한 나무 부수기)에 따라 다르게 조절될 때와 다른 관련 없는 시각적 프롬프트에 따라 다르게 조절될 때 다양한 방식으로 달라집니다. 예를 들어, 나무 수집과 흙 수집 작업에서는 게임 플레이의 프레임 이후에 성능이 증가하기 시작합니다.
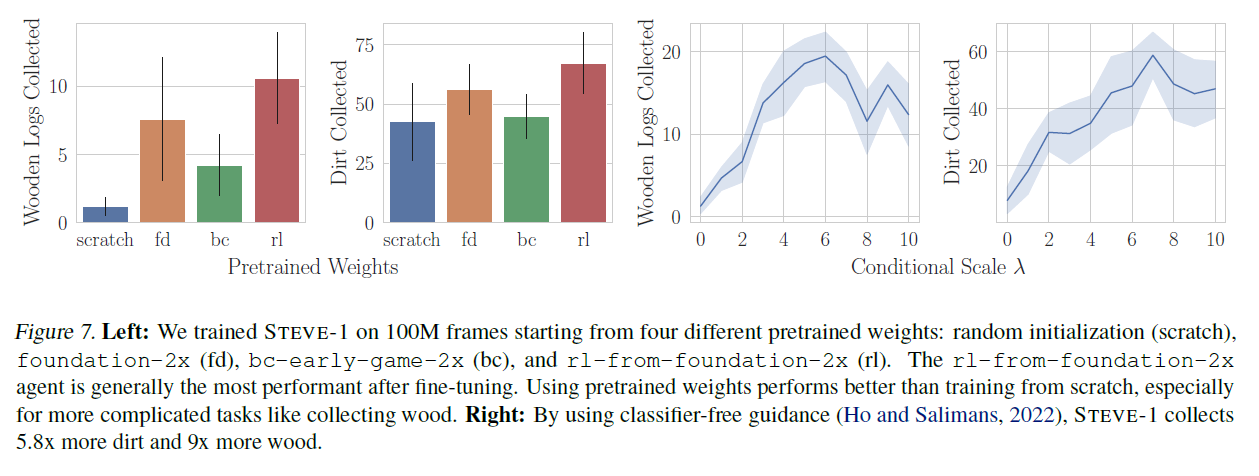
그림 7. 왼쪽: 우리는 STEVE-1을 네 가지 다른 사전 훈련된 가중치로 100M 프레임에서 훈련시켰습니다: 무작위 초기화(처음부터), foundation-2x(fd), bc-early-game-2x(bc), 그리고 rl-from-foundation-2x(rl). rl-from-foundation-2x 에이전트는 일반적으로 미세 조정 후 가장 높은 성능을 보입니다. 사전 훈련된 가중치를 사용하는 것이 처음부터 훈련하는 것보다 더 나은 성능을 보이며, 특히 나무 수집과 같은 더 복잡한 작업에서 그렇습니다. 오른쪽: 분류자 없는 안내(classifier-free guidance)(Ho and Salimans, 2022)를 사용함으로써, STEVE-1은 5.8배 더 많은 흙과 더 많은 나무를 수집합니다.
rl-from-foundation-2x, 그리고 무작위로 초기화된 가중치로. 이 실험에서, 각 모델은 프레임에 미세 조정되었습니다.
그림 7은 이 모델들이 시각적 목표를 가진 프로그래밍 작업에서의 성능을 보여줍니다. 주목할 점은, 우리 데이터셋에서 처음부터 훈련된 에이전트는 흙 수집과 같은 기본적인 작업을 꽤 잘 수행할 수 있지만, 사전 훈련된 에이전트와 달리 나무를 찾아 베는 능력이 없다는 것입니다. 이는 사전 훈련으로 인해 에이전트에 존재하는 능력이 미세 조정된 에이전트로 성공적으로 전달되었음을 보여줍니다. 우리가 시도한 모든 사전 훈련된 가중치 중에서, -from-foundation-가 가장 좋은 성능을 보였으며, 나무 만들기와 베기와 같은 작업에서 질적으로 더 나은 성능을 보였습니다. 실제로, 그림 7은 이 모델이 강력한 성능을 보이며, 이는 RL 훈련 중에 사용된 엄청난 양의 계산 능력 때문일 가능성이 높습니다(Baker et al., 2022).
D.2. 분류자 없는 안내(Classifier-Free Guidance)
Baker et al. (2022)은 에이전트가 텍스트에 따라 조건을 부여받을 때, 지시를 무시하고 대신 사전 훈련 중에 배운 이전 행동을 수행하는 경향이 있다고 관찰했습니다. 2.4절에서 논의한 바와 같이, 분류자 없는 안내는 목표 조건화된 행동과 이전 행동 사이의 균형을 조절하는 노브를 제공합니다. 그림 7은 이 매개변수 가 통나무와 흙 수집 작업에 미치는 영향을 보여줍니다. 에이전트의 성능은 에서 사이에서 최대에 도달한 후 감소하기 시작합니다. 이 결과들은 분류자 없는 안내의 중요성을 보여주며, 이는 STEVE-1의 성능을 수십 배 향상시킵니다.
D.3. 프롬프트 엔지니어링(Prompt Engineering)
프롬프트 엔지니어링(prompt engineering)이라는 분야는 지난해 급속도로 등장했는데, 이는 텍스트-투-X(text-to-X) 모델의 출력 품질이 프롬프트에 따라 극적으로 변할 수 있다는 관찰 때문입니다(Zhou et al., 2023). 예를 들어, 부록의 표 3은 안정적 확산(Stable Diffusion)에 대한 프롬프트가 어떻게 작성될 수 있는지 보여줍니다(Rombach et al., 2022). 이미지의 다양한 속성들을 나열함으로써, 예를 들어 시각적 매체, 스타일, 그리고 "ArtStation에서 인기 있는(trending on ArtStation)"이라는 문구를 사용함으로써, 사용자는 더 높은 품질의 이미지를 얻을 수 있습니다(Gustavosta, 2023; Liu and Chilton, 2022). 이 섹션에서는, 이와 같은 스타일의 프롬프트 엔지니어링이 STEVE-1의 성능을 향상시키는 방법을 탐구합니다. 그림 8은 "흙을 얻어라(get dirt)"라는 간단한 프롬프트가 원하는 행동 유형을 더 정확하게 지정하기 위해 어떻게 변경될 수 있는지 보여줍니다. 이미지 생성 모델에서와 마찬가지로, 이런 식으로 프롬프트를 수정함으로써 STEVE-1의 성능이 크게 향상됩니다. 더 복잡한 프롬프트로 변경함으로써 STEVE-1은 나무를 더 많이, 흙을 더 많이, 그리고 씨앗을 더 많이 수집할 수 있습니다.

그림 8. 이미지 생성에서와 마찬가지로, 더 길고 구체적인 프롬프트로 전환하면 STEVE-1의 성능이 극적으로 향상됩니다.
D.4. 훈련 중 분류기-자유 안내(Classifier-Free Guidance During Training)
우리는 훈련 중에 분류기 없는 가이드(classifier-free guidance)를 사용하는 것의 중요성을 조사하기 위해 목표 임베딩 을 정책(policy)의 입력에서 제외하지 않는 가이드가 없는 모델(no guidance)을 미세 조정(finetuning)하고, 가이드를 사용하는 버전()과 비교합니다. 청크 크기(chunk size)는 15에서 50의 범위로 설정됩니다. 그림 9에서, 우리는 조건부 스케일 을 사용하는 가이드가 없는 모델과 조건부 스케일 및 을 사용하는 가이드 모델의 성능을 비교합니다. 가이드가 없는 모델이 몇몇 지표에서 에서 가이드 모델을 약간 능가하는 것을 관찰하지만, 조건부 스케일을 으로 늘릴 때(가이드가 없는 모델에서는 할 수 없음), 가이드가 있는 에이전트(agent)는 인벤토리 수집 작업에서 가이드가 없는 에이전트보다 2~3배 더 뛰어난 성능을 보입니다. 이동 거리 지표(travel distance metric)의 경우, 두 가이드 버전 모두 가이드가 없는 버전과 비슷한 성능을 보입니다.
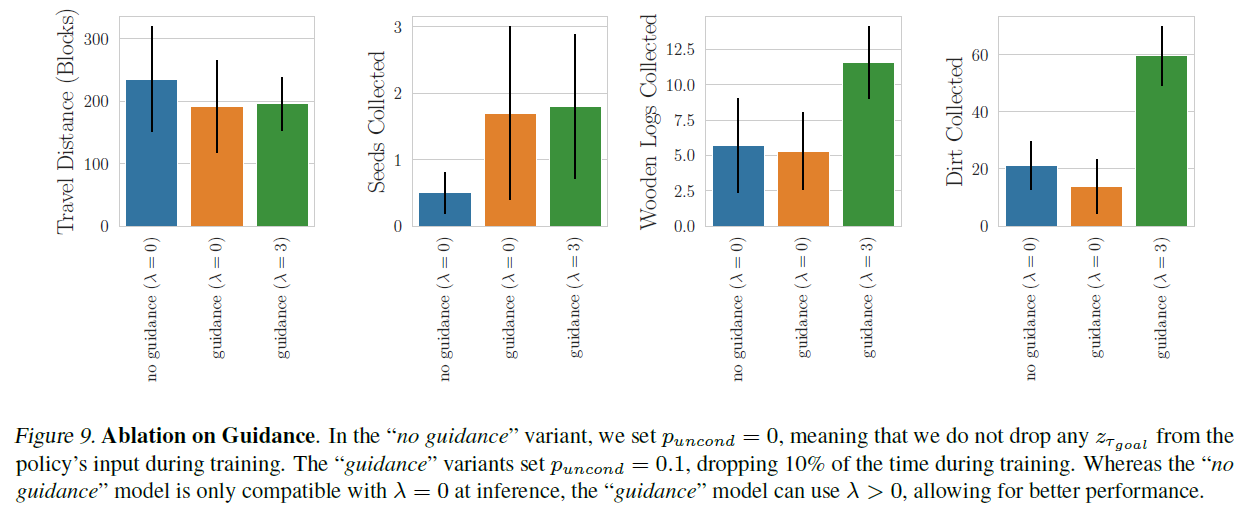
그림 9. 가이드에 대한 절제 실험(Ablation on Guidance). "가이드 없음" 변형에서는 으로 설정하여, 훈련 중에 정책의 입력에서 을 전혀 제외하지 않습니다. "가이드" 변형은 로 설정하여, 훈련 중에 10%의 시간 동안 제외합니다. "가이드 없음" 모델은 추론 시 만 호환되는 반면, "가이드" 모델은 을 사용할 수 있어 더 나은 성능을 낼 수 있습니다.
D.5. 텍스트 증강(Text Augmentation)
미세 조정 중에는 미래의 MineCLIP 비디오 임베딩을 목표로 하는 자기 감독(self-supervision)만 사용하는 대신, 2,000개의 인간이 라벨링한 궤적 세그먼트에서 텍스트 임베딩을 목표 임베딩으로 사용하거나 자기 감독 비디오 임베딩에 추가하여 사용하는 것을 고려했습니다. CVAE 이전 접근법과 더 공정하게 비교하기 위해, 부록 F.2에서 설명한 대로 추가적인 텍스트-게임플레이 쌍을 인간 라벨 데이터에 증강합니다. 이 실험은 알고리즘 1에서 재라벨링에 사용된 시각적 임베딩을 텍스트 임베딩으로 대체하여 구현하며, 가능할 때 90%의 확률로 사용합니다. 시각적 임베딩을 전혀 사용하지 않는 것을 실험하기 위해, 시각적 임베딩을 같은 방식으로 0으로 대체할 수 있습니다. 그림 10에서, 우리는 훈련 중에 시각적 임베딩만 사용하고 CVAE와 결합하는 것이 다른 두 베이스라인에서 직접 MineCLIP 텍스트 임베딩을 사용하는 것보다 더 나은 성능을 낼 수 있음을 관찰합니다.
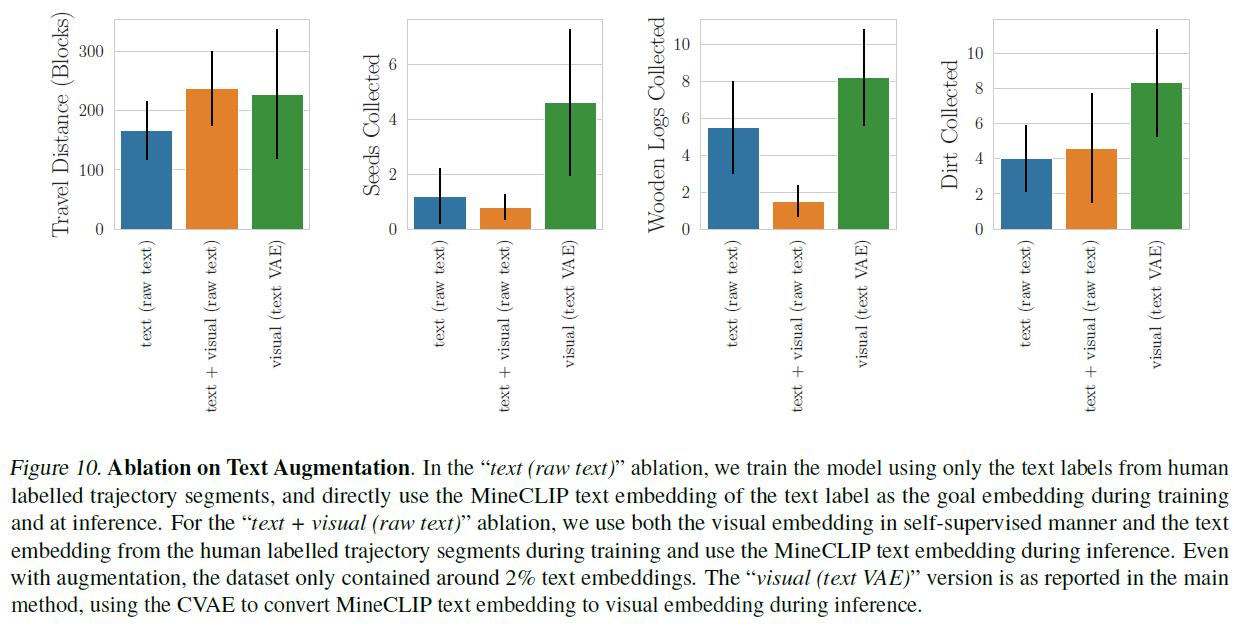
그림 10. 텍스트 증강에 대한 소거 실험(Ablation on Text Augmentation). "텍스트(원본 텍스트)" 소거 실험에서는 인간이 레이블링한 궤적 부분의 텍스트 레이블만을 사용하여 모델을 훈련하고, 훈련 및 추론 시 MineCLIP 텍스트 임베딩을 목표 임베딩으로 직접 사용합니다. "텍스트 + 시각적(원본 텍스트)" 소거 실험에서는 자기지도 방식(self-supervised manner)의 시각적 임베딩과 인간이 레이블링한 궤적 부분의 텍스트 임베딩을 훈련 시 사용하고, 추론 시 MineCLIP 텍스트 임베딩을 사용합니다. 증강을 사용하더라도 데이터셋에는 약 의 텍스트 임베딩만 포함되어 있습니다. "시각적(텍스트 VAE)" 버전은 주요 방법론에서 보고된 것처럼, 추론 시 MineCLIP 텍스트 임베딩을 시각적 임베딩으로 변환하기 위해 CVAE를 사용합니다.
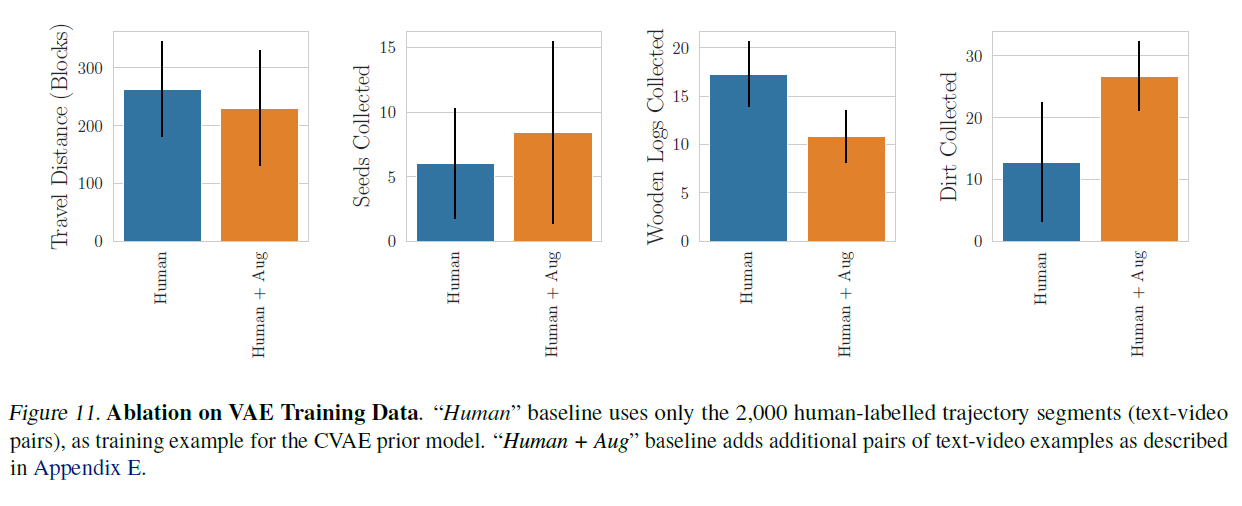
그림 11. VAE 훈련 데이터에 대한 소거 실험(Ablation on VAE Training Data). "인간(Human)" 기준선은 CVAE 사전 모델(prior model)의 훈련 예제로 2,000개의 인간이 레이블링한 궤적 부분(텍스트-비디오 쌍)만을 사용합니다. "인간 + 증강(Human + Aug)" 기준선은 부록 E에서 설명한 대로 추가적인 텍스트-비디오 예제 쌍을 추가합니다.
D.6. VAE 변형(Variants)
CVAE 사전 모델을 훈련하기 위해 사용된 데이터셋을 연구합니다. 그림 11에서, 증강이 흙과 씨앗 수집 작업과 같은 일부 프로그래밍 작업에서 도움이 되지만, 나무 로그 수집과 이동 거리 메트릭에서는 약간의 해를 끼친다는 것을 관찰합니다. 같은 정책(1억 프레임에 대해 훈련된)에서 이 소거 실험을 수행하고 각 CVAE 변형에 대해 조건부 스케일 를 조정했다는 점에 유의하세요.
D.7. 청크 크기(Chunk Size)
미세조정(finetuning) 동안, 우리는 min_btwn_goals=15를 유지하면서 max_btwn_goals= 를 변화시키며 다른 목표 청크 크기를 비교합니다. 자세한 내용은 알고리즘 1을 참조하세요. 더 큰 max_btwn_goals는 더 많은 노이즈를 도입하며, 더 먼 목표를 달성하는 데 이르게 한 행동이 해당 목표 청크에 있는 행동과 덜 상관관계가 있습니다. 그림 12에서, 최적의 max_btwn_goals 청크 크기는 약 200 주변이며, 그 이상으로 청크 크기를 늘리면 성능이 떨어지는 것을 관찰합니다.
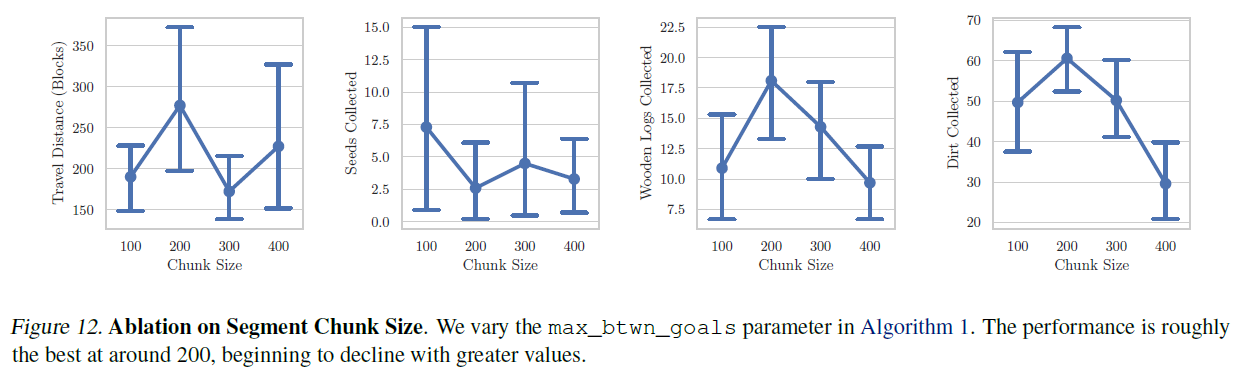
그림 12. 세그먼트 청크 크기에 대한 소거 실험(Ablation on Segment Chunk Size). 우리는 알고리즘 1에서 max_btwn_goals 매개변수를 변화시킵니다. 성능은 대략 200 주변에서 가장 좋으며, 더 큰 값으로 갈수록 감소하기 시작합니다.
E. 데이터셋 세부 사항(Dataset Details)
E.1. 게임플레이 데이터셋(Gameplay Dataset)
우리의 게임플레이 데이터셋은 두 가지 유형의 에피소드로 구성됩니다: Baker et al. (2022)에서 제공된 계약자 데이터셋(contractor dataset)의 7,854 에피소드( 프레임)와 다양한 사전 훈련된 VPT 에이전트들을 실행하여 생성된 2,267 에피소드(14.96M 프레임)입니다.
OpenAI 계약자 데이터셋(VPT) 대부분의 데이터는 VPT를 훈련시키기 위해 사용된 계약자 데이터에서 왔습니다(Baker et al., 2022). OpenAI는 계약자 데이터의 다섯 개 부분집합을 공개했습니다: 6.x, 7.x, 8.x, 9.x, 그리고 10.x. 우리는 8.x, 9.x, 그리고 10.x의 균등한 혼합을 사용하는데, 이는 각각 "처음부터 집 짓기", "무작위 시작 재료로 집 짓기", 그리고 "다이아몬드 곡괭이 얻기"에 해당합니다. 계약자들은 화면, 마우스, 키보드가 기록되는 동안 이 목표들을 최선으로 달성하기 위해 10분에서 20분 사이의 시간을 주어졌습니다.
VPT 생성 데이터셋(VPT-Generated Dataset) 우리는 다양한 사전 훈련된 VPT 에이전트들을 사용하여 에피소드를 생성함으로써 추가 데이터를 생성했습니다. 데이터의 다양성을 증가시키고, 에피소드 중간에 에이전트가 임의로 작업을 전환하는 데이터를 얻기 위해, 에피소드 동안 다른 사전 훈련된 에이전트들 사이에서 임의로 전환하는 것을 추가했습니다. 구체적으로, 에피소드의 시작에서 우리는 (foundation_model_2x, bc_early_game_2x, bc_house_3x, rl_from_foundation_2x, rl_from_house_2x) 중 두 VPT 에이전트를 임의로 샘플링하고 각 타임스텝에서 의 확률로 그들 사이를 전환합니다. RL 에이전트들은 모두 비슷하게 행동하기 때문에, 우리는 두 RL 에이전트를 동시에 샘플링하지 않습니다. 추가적으로, 각 타임스텝에서 의 확률로, 우리는 에이전트가 임의의 각도로 회전하게 합니다. 이는 에이전트가 임의로 작업을 변경하는 데이터를 더 많이 추가하여, 다운스트림 조종성(downstream steerability)을 증가시킵니다.
E.2. 지시 데이터셋(Instruction Dataset)
우리는 우리 데이터셋에서 게임 플레이를 수동으로 라벨링하여 2,000개의 인간이 라벨링한 궤적 세그먼트(텍스트-비디오 쌍)로 구성된 작은 데이터셋을 수집했습니다. 우리는 사용자에게 임의로 샘플링된 에피소드에서 16 프레임의 비디오를 보여주는 간단한 웹 앱을 사용했습니다. 이는 라벨링된 데이터의 32,000 프레임에 해당하며, 전체 데이터셋의 또는 27분의 라벨링된 데이터에 해당합니다. 그러나 F.2 절에서 논의된 바와 같이, 이것을 MineCLIP을 사용한 자동 라벨링 데이터와 결합하면 강력한 사전 모델이 됩니다.
F. 훈련 세부사항(Training Details)
F.1. 정책 훈련(Policy Training)
STEVE-1은 PyTorch에서 분산 데이터 병렬(distributed data parallel)을 사용하여 훈련되었습니다(Paszke et al., 2019). 훈련 중에는 데이터셋에서 640 타임스텝의 세그먼트가 샘플링되었습니다. 메모리 제약으로 인해, 이 세그먼트들은 64의 청크로 더 나누어져 순차적으로 처리되었습니다. VPT가 Transformer-XL(Dai et al., 2019)을 사용하기 때문에, 이 순차적 처리는 정책이 그것의 컨텍스트 길이의 한계까지 이전 배치들에 주의를 기울일 수 있게 합니다. 우리는 AdamW(Loshchilov and Hutter, 2019)를 사용하여 가중치를 최적화했으며, 최대 학습률은 4e-5이고 처음 10M 프레임 동안 선형 웜업(linear warmup)이 뒤따른 후 원래 학습률의 로 감소하는 코사인 학습률 감소 스케줄(cosine learning rate decay schedule)을 사용했습니다. 훈련 중 사용된 하이퍼파라미터의 전체 목록은 표 2를 참조하십시오.

학습하는 동안 우리는 포장된 힌트사이트 재라벨링(packed hindsight relabeling)을 사용하여 데이터를 샘플링합니다(그림 2). 이것은 에피소드의 일부분을 샘플링하고, 목표를 변경할 일부 타임스텝을 무작위로 선택한 다음, 해당 에피소드 전체에 대한 목표 임베딩을 해당 목표 세그먼트의 임베딩으로 채우는 것을 포함합니다. 알고리즘 1은 이 알고리즘을 자세히 설명합니다.
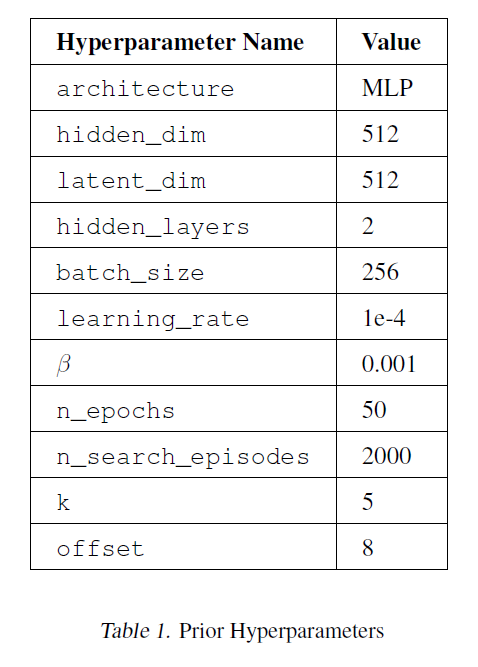
표 1. 사전 하이퍼파라미터
F.2. 사전 학습
사전 모델은 MineCLIP(Fan et al., 2022) 텍스트 임베딩에 조건을 걸고 해당 텍스트 임베딩이 주어졌을 때 시각적 임베딩의 조건부 분포를 모델링하는 간단한 CVAE(Sohn et al., 2015)입니다. 사전을 구현하기 위한 다른 접근법에 대한 조사는 미래의 작업으로 남겨둡니다. 이 모델은 약 2,000개의 수작업으로 라벨링된 궤적 세그먼트와 게임플레이 데이터셋에서 자동으로 검색된 텍스트-게임플레이 쌍을 추가하여 학습됩니다. 다음 단계를 사용하여 이 작업을 수행합니다:
- 2,000개의 텍스트 라벨과 gpt-3.5-turbo를 쿼리하여 생성된 추가 8,000개의 라벨을 결합합니다.
- 이 10,000개의 텍스트 라벨 각각에 대해, 게임플레이 데이터셋에서 샘플링된 1,000개의 에피소드를 검색하여 텍스트 라벨의 텍스트 임베딩에 가장 가까운 상위 5개의 시각적 MineCLIP 임베딩을 찾습니다.
이렇게 자동으로 채굴된 50,000개의 텍스트-비디오 쌍은 원래의 2,000개의 수작업으로 라벨링된 예시에 추가되어 사전 학습에 사용되는 최종 데이터셋을 형성합니다.
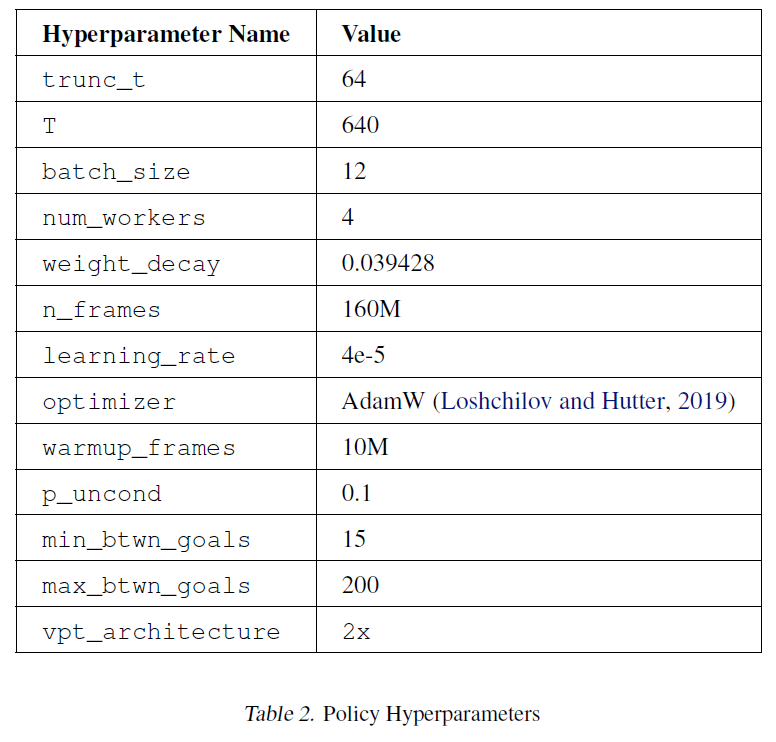
표 2. 정책 하이퍼파라미터
시각적 목표를 사용하여 STEVE-1을 프롬프트할 때, 시각적 목표가 에이전트가 블록을 치지만 끝까지 부수지 않는 것을 보여줄 때 STEVE-1이 실제로 블록을 부수는 것을 피한다는 것을 알아차렸습니다. 불행히도, 자동으로 발견된 많은 텍스트-게임플레이 클립들이 이런 종류의 게임플레이를 포함하고 있습니다. 이 문제를 방지하기 위해, 우리는 이런 방식으로 찾은 임베딩에 오프셋을 추가했습니다. 원래 선택된 타임스텝 이후에 오프셋 단계의 타임스텝에서 임베딩을 선택함으로써, 에이전트가 블록을 부수는 행동을 더 잘 따르게 됩니다.
우리는 이 데이터셋에서 사전 모델(prior model)을 50 에포크(epoch) 동안 훈련시켰고, 작은 검증 세트(validation set)를 사용하여 조기 종료(early-stopping)를 적용했습니다. 사전 모델을 만드는 데 사용된 하이퍼파라미터(hyperparameters)의 전체 목록은 표 1(Table 1)에서 찾을 수 있습니다.
G. 평가 세부 사항
우리 에이전트(agent)의 성능을 평가하는 것은 가능한 지시 사항의 다양성과 에이전트가 성공적으로 임무를 달성했는지 평가하는 어려움 때문에 도전적인 과제입니다. 우리는 프로그래매틱 평가 메트릭(programmatic evaluation metrics)과 자동 MineCLIP 평가 메트릭(automatic MineCLIP evaluation metrics)의 조합을 사용하여 에이전트의 능력 수준에 대한 감을 얻습니다.
프로그래매틱 평가(Programmatic Evaluation) 우리는 각 평가 에피소드(episode) 동안 MineRL(Guss et al., 2019) 환경 상태를 모니터링하여 프로그래매틱 평가 메트릭을 계산합니다. VPT(Baker et al., 2022)에서 수행한 것처럼, 우리는 이동 거리(travel distance)와 초반 게임 아이템 수집(early-game item collection)을 포함한 여러 프로그래매틱 메트릭을 계산합니다. 이동 거리는 수평(X-Z) 평면에서 초기 스폰 지점으로부터 에이전트의 최대 이동 거리를 측정한 것입니다. 초반 게임 인벤토리 수(inventory counts)에 대해서는 에피소드 동안 에이전트의 인벤토리에서 본 나무(log), 씨앗(seed), 흙(dirt) 아이템의 최대 수를 저장합니다.
MineCLIP 평가(MineCLIP Evaluation) 우리는 어떤 궤적(trajectory) 에 대해서도 MineCLIP 임베딩의 텍스트-비주얼 정렬(text-visual alignment)을 사용하여 16 프레임의 세그먼트가 주어진 임무에 해당하는지 대략적으로 평가할 수 있습니다(Fan et al., 2022). 우리는 프로그래매틱 평가가 실용적이지 않은 더 다양한 임무에서 우리 에이전트를 평가하기 위해 궤적과 텍스트 또는 비주얼 목표 사이의 MineCLIP 잠재 공간(latent space)에서의 정렬을 사용하는 것을 탐구합니다. 에피소드 동안 어느 시점에서든 임무가 전혀 완료되었는지를 결정하기 위해, 우리는 에피소드 동안 어떤 타임스텝에서든 (텍스트 또는 비주얼) 목표 임베딩 사이의 최소 코사인 거리(cosine distance)를 기록합니다.
H. 추가 시각화
H.1. MineCLIP 평가
우리는 텍스트와 비주얼 프롬프트(visual prompts)에 대해 MineCLIP 평가를 실행했습니다. MineCLIP 평가 결과는 그림 15(Figure 15)에서 찾을 수 있습니다.
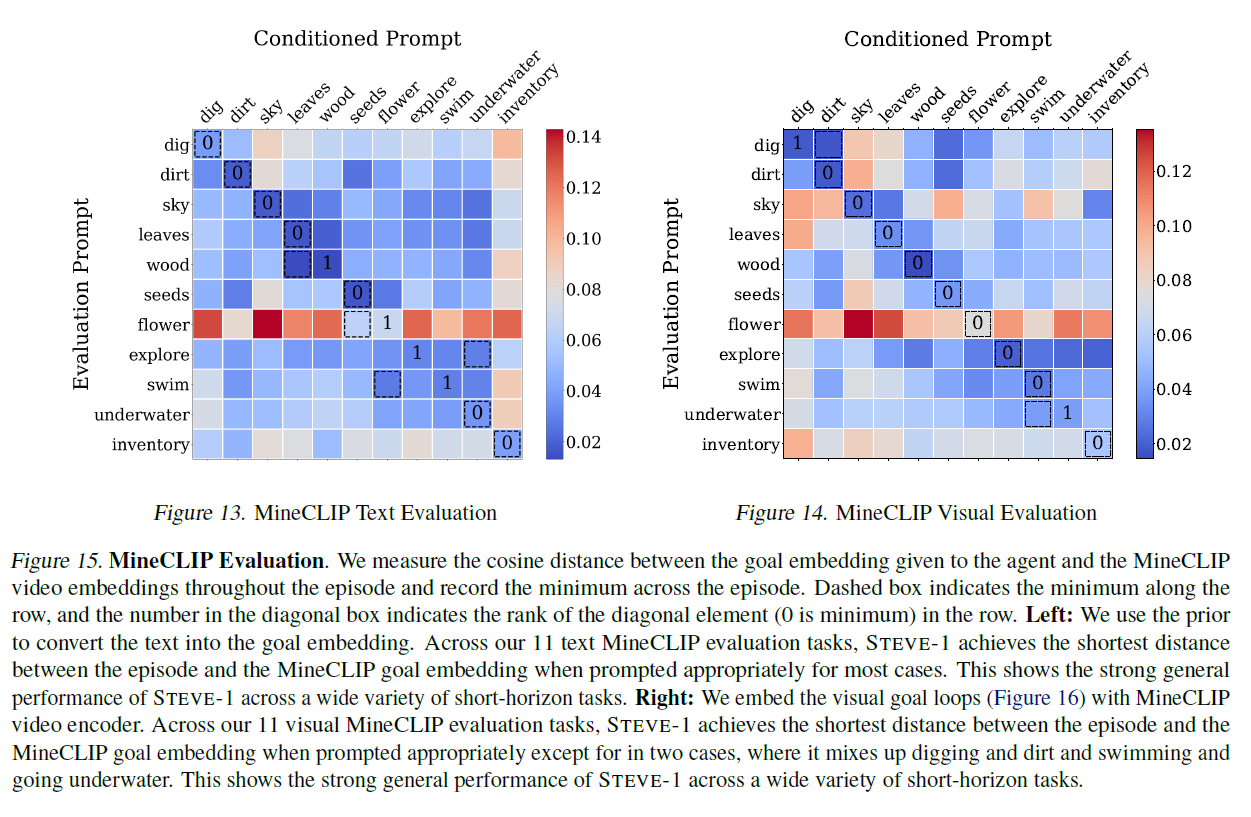
그림 13. MineCLIP 텍스트 평가(Figure 13. MineCLIP Text Evaluation)
그림 14. MineCLIP 비주얼 평가(Figure 14. MineCLIP Visual Evaluation)
그림 15. MineCLIP 평가. 에이전트에게 주어진 목표 임베딩과 에피소드 전반에 걸쳐 MineCLIP 비디오 임베딩 사이의 코사인 거리를 측정하고 에피소드에서 최소값을 기록합니다. 점선 상자는 행에서 최소값을 나타내며, 대각선 상자 안의 숫자는 대각선 요소의 행에서의 순위를 나타냅니다(0이 최소값). 왼쪽: 우리는 사전(prior)을 사용하여 텍스트를 목표 임베딩으로 변환합니다. 11개의 텍스트 MineCLIP 평가 작업에서 STEVE-1은 대부분의 경우 적절한 프롬프트를 사용할 때 에피소드와 MineCLIP 목표 임베딩 사이의 거리가 가장 짧습니다. 이는 STEVE-1이 다양한 단기 목표 작업에서 강력한 일반적인 성능을 보여줍니다. 오른쪽: 우리는 MineCLIP 비디오 인코더를 사용하여 시각적 목표 루프(그림 16)를 임베딩합니다. 11개의 시각적 MineCLIP 평가 작업에서 STEVE-1은 두 경우를 제외하고 적절한 프롬프트를 사용할 때 에피소드와 MineCLIP 목표 임베딩 사이의 거리가 가장 짧습니다. 여기서는 파기(digging)와 흙(dirt), 수영(swimming)과 물속으로 들어가기(going underwater)를 혼동합니다. 이는 STEVE-1이 다양한 단기 목표 작업에서 강력한 일반적인 성능을 보여줍니다.
H.2. 프로그래매틱 메트릭스(Programmatic Metrics)를 통한 조종성(Steerability)
VPT 부록(Baker et al., 2022)의 그림 20과 유사하게, 우리는 시각적 프롬프트(그림 17)와 CVAE 사전을 사용한 텍스트 프롬프트(그림 18) 조건을 사용하여 다양한 목표 프롬프트 조건에 따른 프로그래매틱 메트릭 성능(평균 및 95% 신뢰 구간)을 플롯합니다. 이는 표 2의 하이퍼파라미터로 훈련된 정책과 조건부 스케일링 (시각적 프롬프트용) 및 (CVAE 사전을 사용한 텍스트 프롬프트용)을 사용하여 수행됩니다. 각 조건 변형은 10번의 시도로 실행되며, 각 시도는 다른 환경 시드를 사용하고 에피소드 길이는 3000 타임스텝(2.5분 게임플레이)입니다. 조건 변형에 걸쳐, 우리는 동일한 환경 시드 세트를 사용합니다. 비교를 위해, 우리는 조건이 없는 VPT(early_game) 에이전트("VPT (uncond)")와 VPT 부록(Baker et al., 2022)에서 조사된 텍스트 조건의 에이전트("VPT (text)*")의 메트릭스도 플롯합니다. 시각적 목표 조건을 사용할 때, 우리는 MineCLIP 비디오 인코더를 사용하여 우리의 훈련 데이터셋에서 가져온 16프레임 클립을 임베딩하여 에이전트가 원하는 작업을 수행하는 것을 임베딩합니다. 각 시각적 목표의 예시 프레임은 그림 16에 나와 있습니다. 텍스트 VAE 목표 조건을 사용할 때, 우리는 MineCLIP 텍스트 인코더를 사용하여 텍스트 프롬프트(표 4)를 인코딩하고 CVAE 사전을 사용하여 MineCLIP 텍스트 임베딩에서 목표 임베딩을 샘플링합니다.
우리는 VPT(Baker et al., 2022)의 실험 설정과 비교하여 몇 가지 차이점을 지적합니다. 우리는 평가 에피소드를 VPT 논문에서의 5분에 비해 3000 타임스텝, 즉 게임 플레이로는 2.5분 동안만 실행합니다. 제한된 계산 예산으로 인해, 우리는 조건부 변형(variant)당 10개의 에피소드를 생성하고, 조건 없는 경우("VPT (uncond)")에 대해서는 110개의 에피소드를 생성합니다. 이는 VPT의 1000개 에피소드에 비교됩니다. 마지막으로, 인벤토리 수를 측정할 때, 우리는 에피소드 전체에서 본 최대 인벤토리 수를 기록하는데, 이는 에이전트가 나중에 해당 아이템을 버리거나, 놓거나, 또는 크래프트하는 데 사용할 수 있기 때문에 수집된 잠재적인 아이템 수의 하한선입니다. 이러한 주의 사항들로 인해, 우리는 그림 17과 그림 18에서 "VPT (text)*" 범례를 별표로 표시하며, 비교를 위해 (Baker et al., 2022)에서 직접 보고된 결과를 사용합니다.

그림 16. 11개의 시각적 목표 각각에서 샘플 프레임. 프레임 위에 겹쳐진 텍스트는 MineCLIP 비디오 인코더로 16프레임 클립을 인코딩할 때는 나타나지 않으며, 그림 시각화를 위해서만 나타납니다.
우리는 몇 가지 관찰을 합니다. 첫째, 우리의 에이전트는 더 조종 가능하다는 것을 관찰합니다: 특정 아이템(굵게 표시됨)을 수집하도록 조건을 부여받았을 때, 에이전트는 그 아이템과 관련 없는 다른 지시사항에 조건을 부여받았을 때나 조건 없는 VPT에 비해 해당 아이템을 (상대적으로) 훨씬 더 많이 수집합니다. 아이템과 관련 없는 작업(예: 수집된 원목을 측정하는 데 관심이 있을 때 꽃을 깨는 것)에 조건을 부여받았을 때, 우리는 에이전트가 조건 없는 에이전트보다 그 아이템을 덜 추구한다는 것도 관찰합니다. 둘째, 우리는 우리가 두드러지게 표시한 지시사항에 대해, 에피소드 롤아웃에서 시간이 절반밖에 되지 않음에도 VPT 성능(파선 파란색 선)을 능가한다는 것을 관찰합니다(Baker et al., 2022). 이는 우리의 에이전트가 조건 없는 VPT 에이전트와 VPT 부록(Baker et al., 2022)에서 조사된 텍스트 조건부 VPT 에이전트에 비해 더 조종 가능하다는 것을 시사합니다.
H.3. 프롬프트 체이닝 시각화
우리는 섹션 3.2에서 프롬프트 체이닝 실험의 특정 에피소드 두 개를 그림 19와 그림 20에서 시각화합니다.
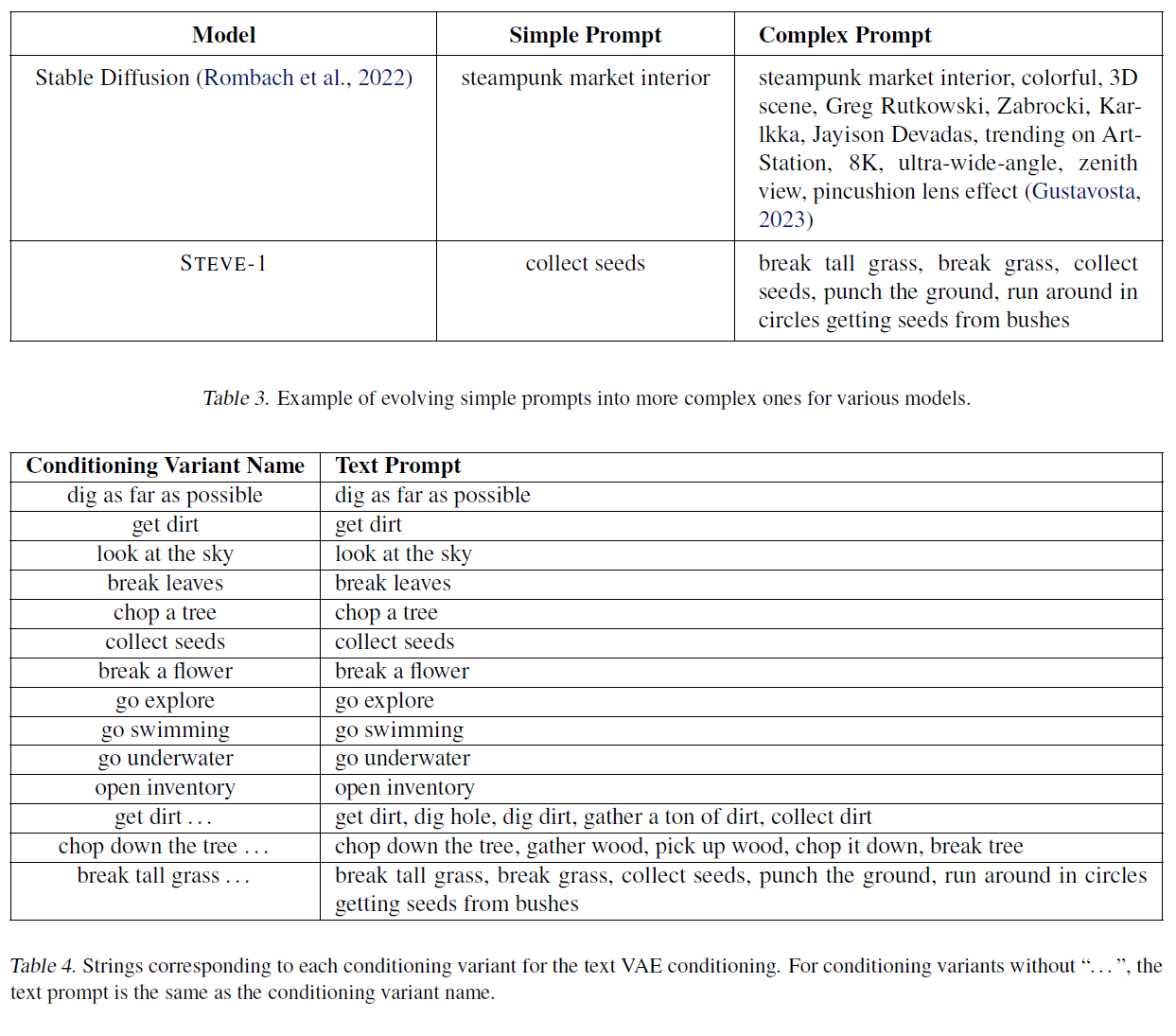
표 3. 다양한 모델에 대해 단순한 프롬프트를 더 복잡한 것으로 발전시키는 예시.
표 4. 텍스트 VAE 조건부 변형에 해당하는 문자열. "..."이 없는 조건부 변형의 경우, 텍스트 프롬프트는 조건부 변형 이름과 동일합니다.
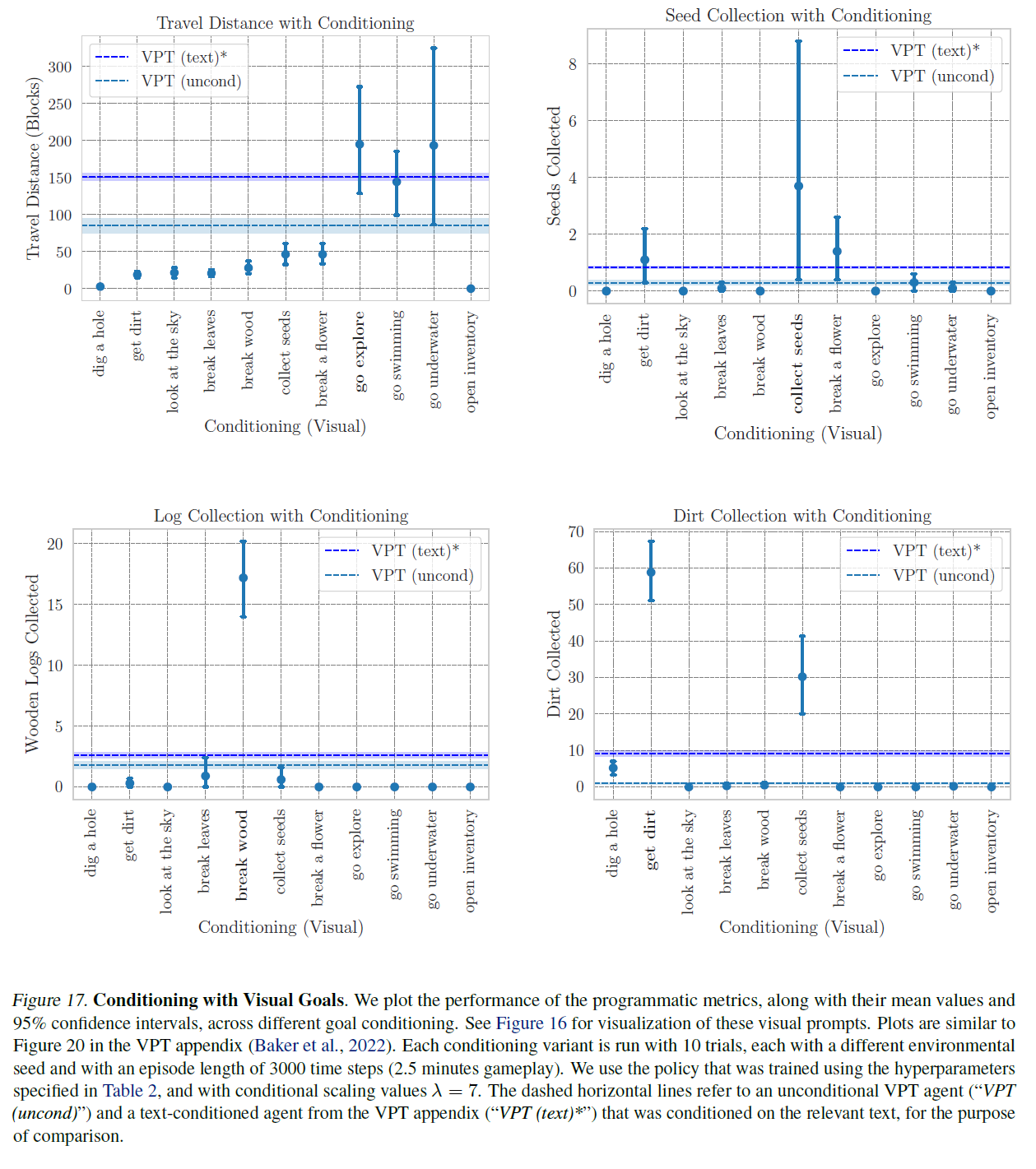
그림 17. 시각적 목표를 가진 조건부. 우리는 다양한 목표 조건부에서 프로그래밍 메트릭의 성능을 그래프로 나타내고, 그 평균값과 95% 신뢰 구간을 함께 표시합니다. 이러한 시각적 프롬프트의 시각화는 그림 16을 참조하세요. 그래프는 VPT 부록(Baker et al., 2022)의 그림 20과 유사합니다. 각 조건부 변형은 10번의 시도로 실행되며, 각각 다른 환경 시드를 가지고 있고 에피소드 길이는 3000 타임 스텝(게임 플레이 2.5분)입니다. 우리는 표 2에 명시된 하이퍼파라미터를 사용하여 훈련된 정책을 사용하고, 조건부 스케일링 값 을 사용합니다. 점선 수평선은 비조건부 VPT 에이전트("VPT (uncond)")와 VPT 부록에서 관련 텍스트에 조건을 부여한 텍스트 조건부 에이전트("VPT (text)*")를 비교하기 위한 것입니다.
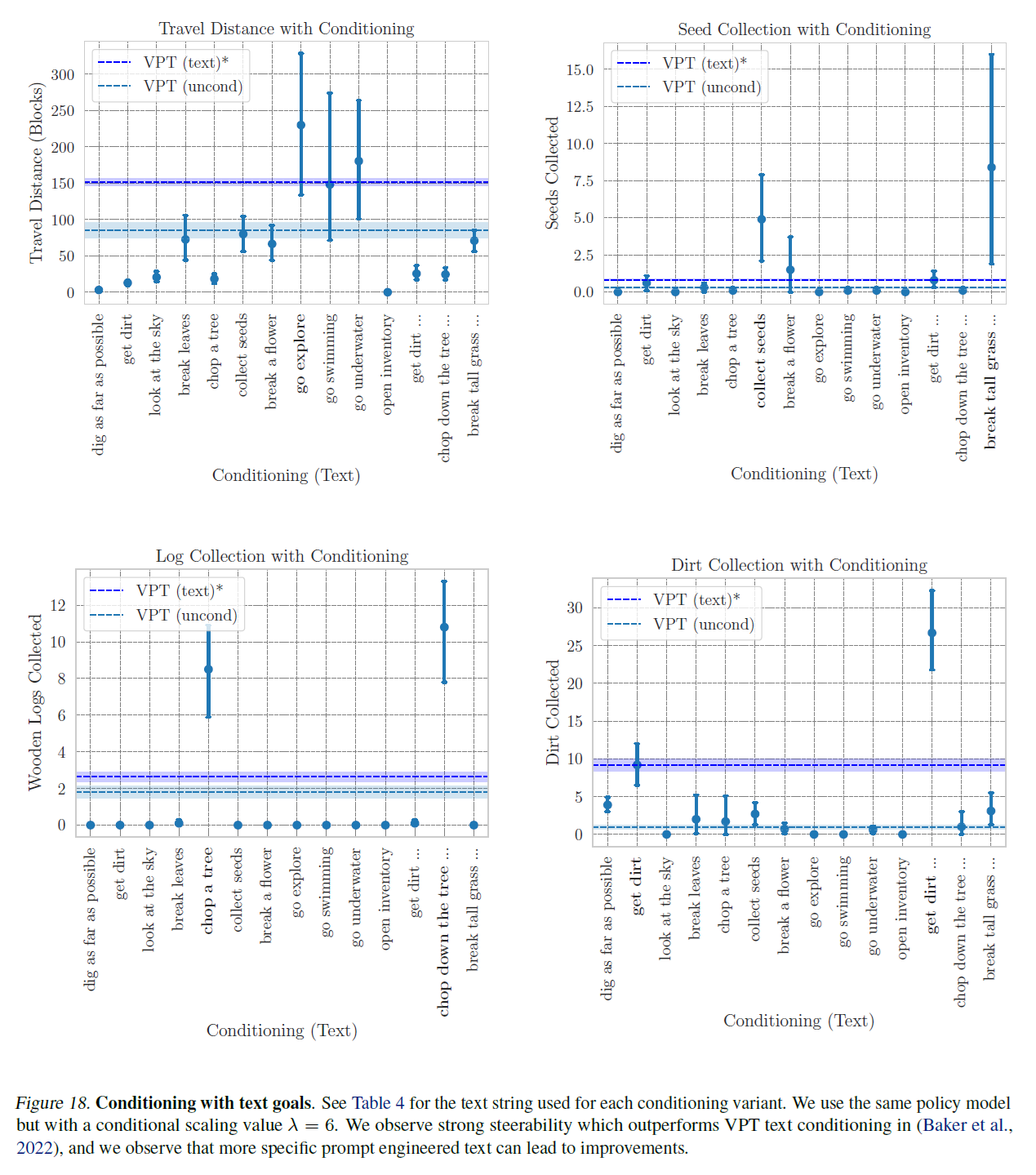
그림 18. 텍스트 목표를 이용한 조건화. 각 조건화 변형에 사용된 텍스트 문자열은 표 4에서 확인할 수 있습니다. 우리는 동일한 정책 모델을 사용하지만 조건부 스케일링 값 을 적용했습니다. 우리는 VPT 텍스트 조건화(Baker et al., 2022)보다 우수한 조종성을 관찰했으며, 더 구체적인 프롬프트 엔지니어링된 텍스트가 개선으로 이어질 수 있음을 관찰했습니다.
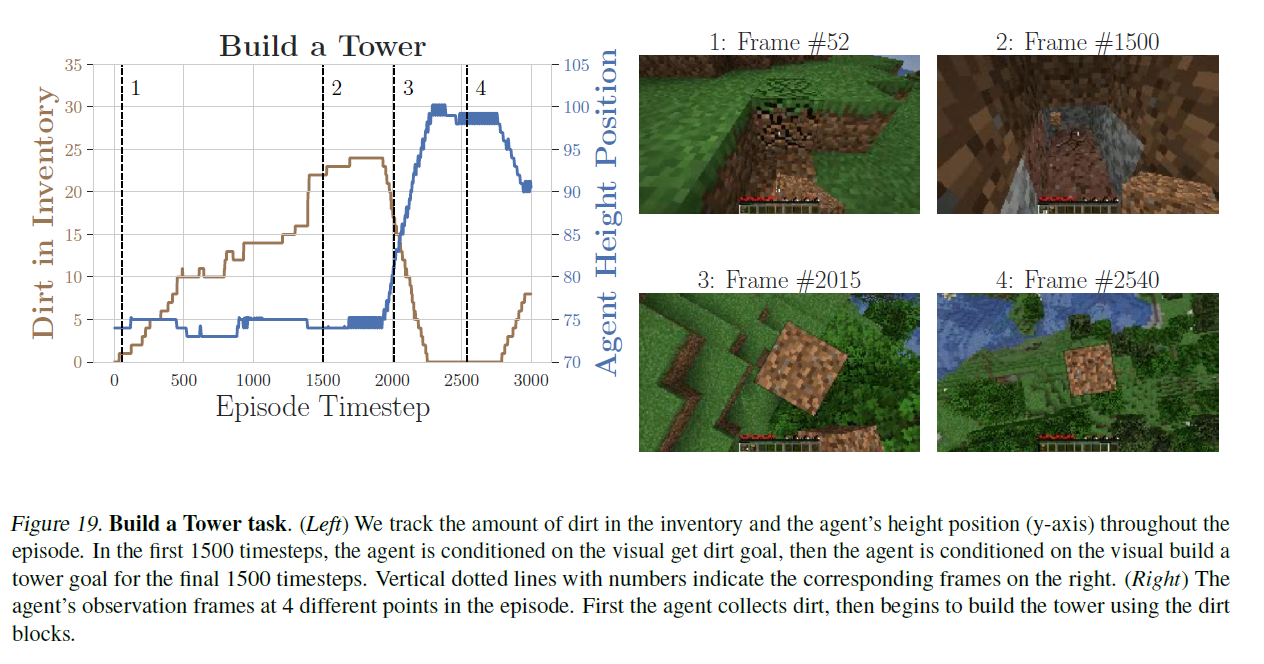
그림 19. 타워 건설 작업. (왼쪽) 에피소드 동안 인벤토리에 있는 흙의 양과 에이전트의 높이 위치(y축)를 추적합니다. 처음 1500 타임스텝 동안 에이전트는 시각적으로 흙을 얻는 목표에 조건화되고, 마지막 1500 타임스텝 동안 에이전트는 시각적으로 타워를 건설하는 목표에 조건화됩니다. 수직 점선과 숫자는 오른쪽에 해당하는 프레임을 나타냅니다. (오른쪽) 에피소드 중 4가지 다른 시점에서의 에이전트 관찰 프레임. 에이전트는 먼저 흙을 수집한 다음 흙 블록을 사용하여 타워를 건설하기 시작합니다.
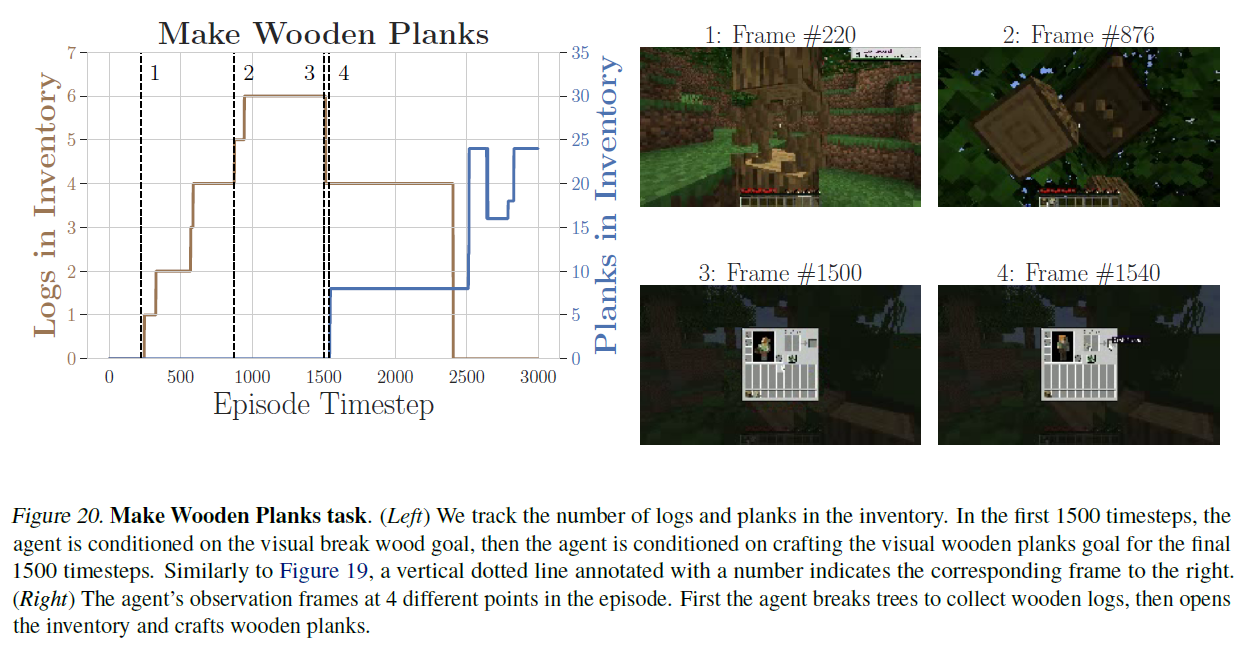
그림 20. 나무 판자 만들기 작업. (왼쪽) 인벤토리에 있는 로그와 판자의 수를 추적합니다. 처음 1500 타임스텝 동안 에이전트는 시각적으로 나무를 부수는 목표에 조건화되고, 마지막 1500 타임스텝 동안 에이전트는 시각적으로 나무 판자를 제작하는 목표에 조건화됩니다. 그림 19와 유사하게, 수직 점선과 숫자는 오른쪽에 해당하는 프레임을 나타냅니다. (오른쪽) 에피소드 중 4가지 다른 시점에서의 에이전트 관찰 프레임. 에이전트는 먼저 나무를 부수어 나무 로그를 수집한 다음 인벤토리를 열고 나무 판자를 제작합니다.
