Deep learning에 관해 몇몇 학습에 도움이 되고자 하는 글을 번역하려 합니다.
- 이 글은 clova hyperX로 번역되었습니다.
- 논문 번역은 chatGPT로 하고 있으니 정성적인 번역 성능 비교도 될수 있지만, 클로바x로는 별다른 Prompt를 사용하지 않고 번역만 요청했습니다.
- 첫글은 clova로 진행했으나 api가 아닌 챗봇 상에서 few-shot 형태의 추론이 잘 이뤄지지 않은 것 같아서 이후에는 chatGPT로 진행할 예정입니다.
- 원글은 PyTorch Blog의 Understanding GPU Memory 1: Visualizing All Allocations over Time입니다.
- 링크는 다음과 같습니다: https://pytorch.org/blog/understanding-gpu-memory-1/
Understanding GPU Memory 1: Visualizing All Allocations over Time
PyTorch를 GPU에서 사용하는 동안, 다음과 같은 일반적인 오류 메시지에 익숙해질 수 있습니다:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 512.00 MiB. GPU 0 has a total capacity of 79.32 GiB of which 401.56 MiB is free.이 시리즈에서는 메모리 스냅샷(Memory Snapshot), 메모리 프로파일러(Memory Profiler), 참조 사이클 탐지기(Reference Cycle Detector)를 포함한 메모리 도구를 사용하여 메모리 부족 오류를 디버깅하고 메모리 사용을 개선하는 방법을 보여줍니다.
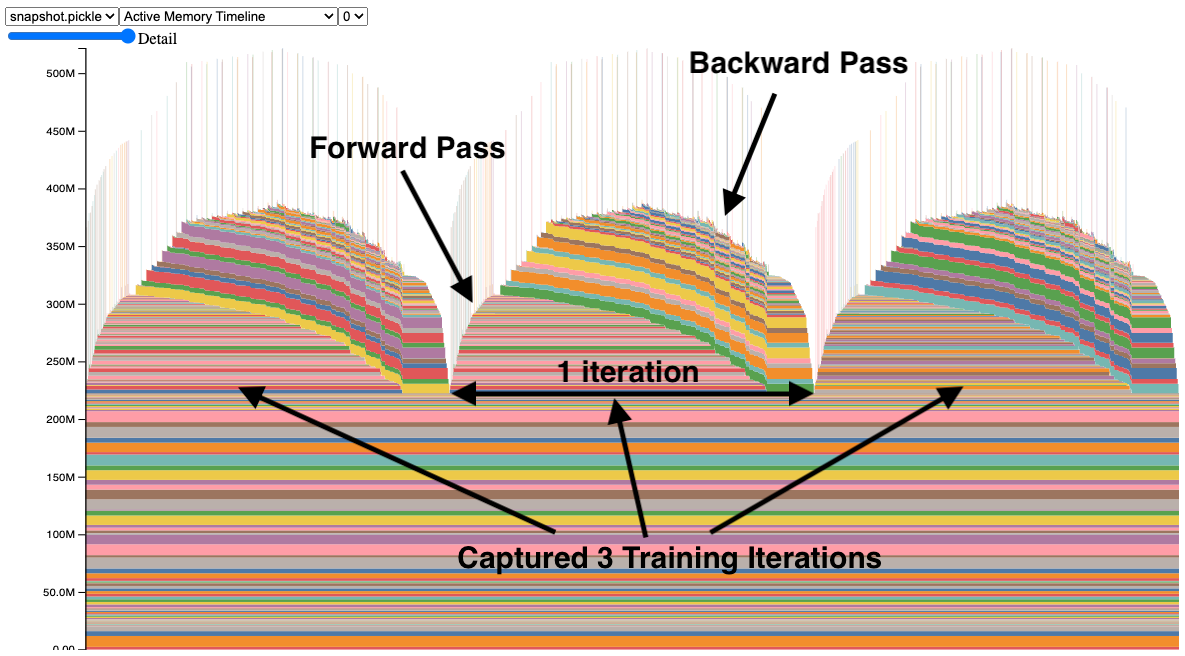
메모리 스냅샷 도구(Memory Snapshot tool)는 GPU OOMs(Out of Memory) 디버깅을 위한 세밀한 GPU 메모리 시각화를 제공합니다. 캡처된 메모리 스냅샷은 할당, 해제 및 OOM 이벤트와 함께 스택 추적을 보여줍니다.
스냅샷에서 각 텐서의 메모리 할당은 별도의 색상으로 표시됩니다. x축은 시간을 나타내며, y축은 MB 단위의 GPU 메모리 양입니다. 스냅샷은 상호 작용이 가능하므로, 마우스를 올려놓음으로써 어떤 할당의 스택 추적을 관찰할 수 있습니다. 직접 시도해 보세요: https://github.com/pytorch/pytorch.github.io/blob/site/assets/images/understanding-gpu-memory-1/snapshot.html.
이 스냅샷에서는 3회의 학습 반복 동안 메모리 할당을 보여주는 3개의 피크가 있습니다(이는 설정 가능합니다). 피크를 보면, 순전파(forward pass)에서 메모리가 증가하고 역전파(backward pass)에서 그래디언트(gradients)가 계산됨에 따라 감소하는 것을 쉽게 볼 수 있습니다. 프로그램이 반복마다 동일한 메모리 사용 패턴을 가지고 있다는 것도 관찰할 수 있습니다. 눈에 띄는 것 중 하나는 메모리의 많은 작은 스파이크인데, 마우스를 올려놓음으로써 이것들이 합성곱 연산자에 의해 일시적으로 사용되는 버퍼임을 알 수 있습니다.
메모리 스냅샷(Memory Snapshots) 캡처하기
메모리 스냅샷을 캡처하는 API는 상당히 간단하며 torch.cuda.memory에서 사용할 수 있습니다:
- Start:
torch.cuda.memory._record_memory_history(max_entries=100000) - Save:
torch.cuda.memory._dump_snapshot(file_name) - Stop:
torch.cuda.memory._record_memory_history(enabled=None)
코드 스니펫(Code Snippet) (전체 코드 샘플은 부록 A를 참조하세요):
# Start recording memory snapshot history, initialized with a buffer
# capacity of 100,000 memory events, via the `max_entries` field.
torch.cuda.memory._record_memory_history(
max_entries=MAX_NUM_OF_MEM_EVENTS_PER_SNAPSHOT
)
# Run your PyTorch Model.
# At any point in time, save a snapshot to file for later.
for _ in range(5):
pred = model(inputs)
loss_fn(pred, labels).backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
# In this sample, we save the snapshot after running 5 iterations.
# - Save as many snapshots as you'd like.
# - Snapshots will save last `max_entries` number of memory events
# (100,000 in this example).
try:
torch.cuda.memory._dump_snapshot(f"{file_prefix}.pickle")
except Exception as e:
logger.error(f"Failed to capture memory snapshot {e}")
# Stop recording memory snapshot history.
torch.cuda.memory._record_memory_history(enabled=None)스냅샷 파일을 시각화하기 위해서, 우리는 https://pytorch.org/memory_viz 에 호스팅된 도구를 가지고 있습니다. 거기에서, 저장된 스냅샷 파일을 드래그 앤 드롭할 수 있으며, 이 도구는 시간에 따른 각 할당을 그래프로 그려줍니다. 개인정보 보호 주의사항: 이 도구는 사용자의 스냅샷을 저장하지 않습니다.

또 다른 방법으로, pytorch/torch/cuda/_memory_viz.py 에 있는 스크립트를 사용하여 .pickle 파일에서 HTML을 생성할 수 있습니다. 다음은 그 예시입니다:
python torch/cuda/_memory_viz.py trace_plot snapshot.pickle -o snapshot.htmlCUDA OOMs 디버깅(DEBUGGING CUDA OOMs)
메모리 스냅샷 도구(Memory Snapshot Tool)를 사용하여 다음과 같은 질문에 대한 답을 어떻게 찾을 수 있는지 살펴봅시다:
- CUDA OOM이 왜 발생했나요?
- GPU 메모리는 어디에 사용되고 있나요?
버그가 있는 ResNet50
첫 번째 스냅샷에서 제대로 작동하는 모델을 살펴보았습니다. 이제, 버그가 있는 트레이닝 예제를 살펴보겠습니다, 스냅샷을 보세요:
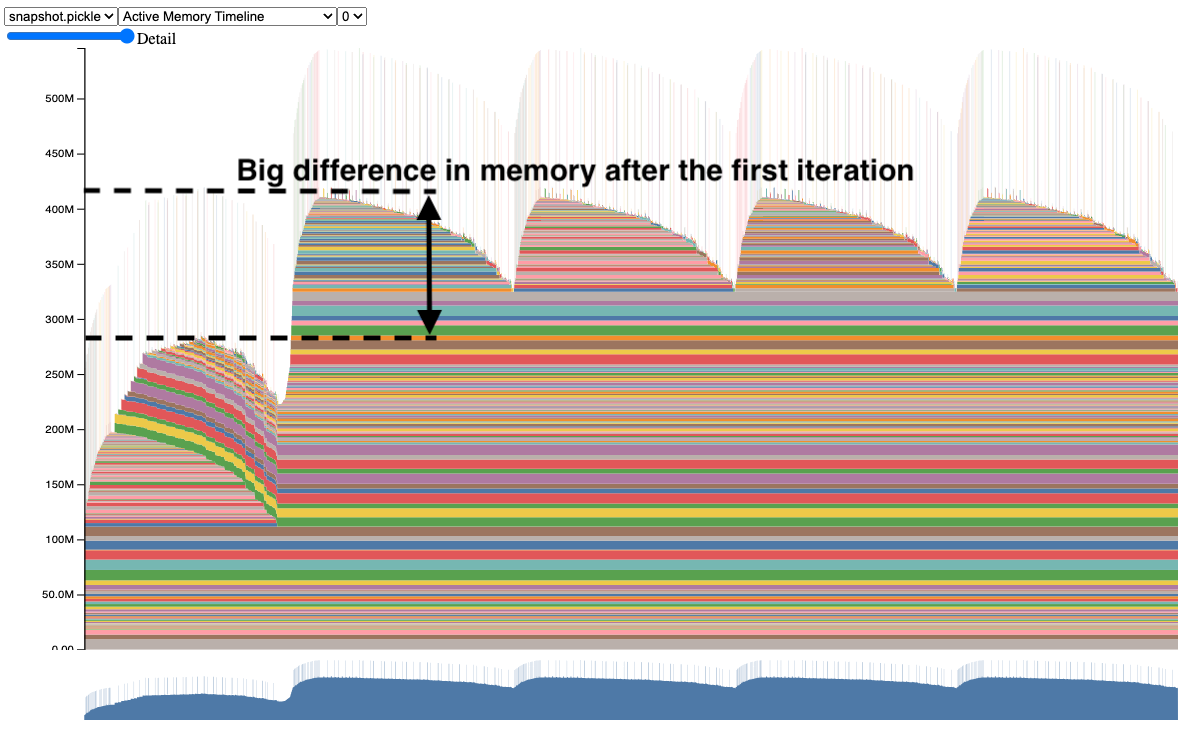
두 번째 반복이 첫 번째 반복보다 훨씬 더 많은 메모리를 사용하는 것을 주목하세요. 이 모델이 훨씬 더 크다면, 왜 그런지에 대한 더 많은 통찰 없이 두 번째 반복에서 CUDA OOM(Out of Memory)이 발생할 수 있었을 것입니다.
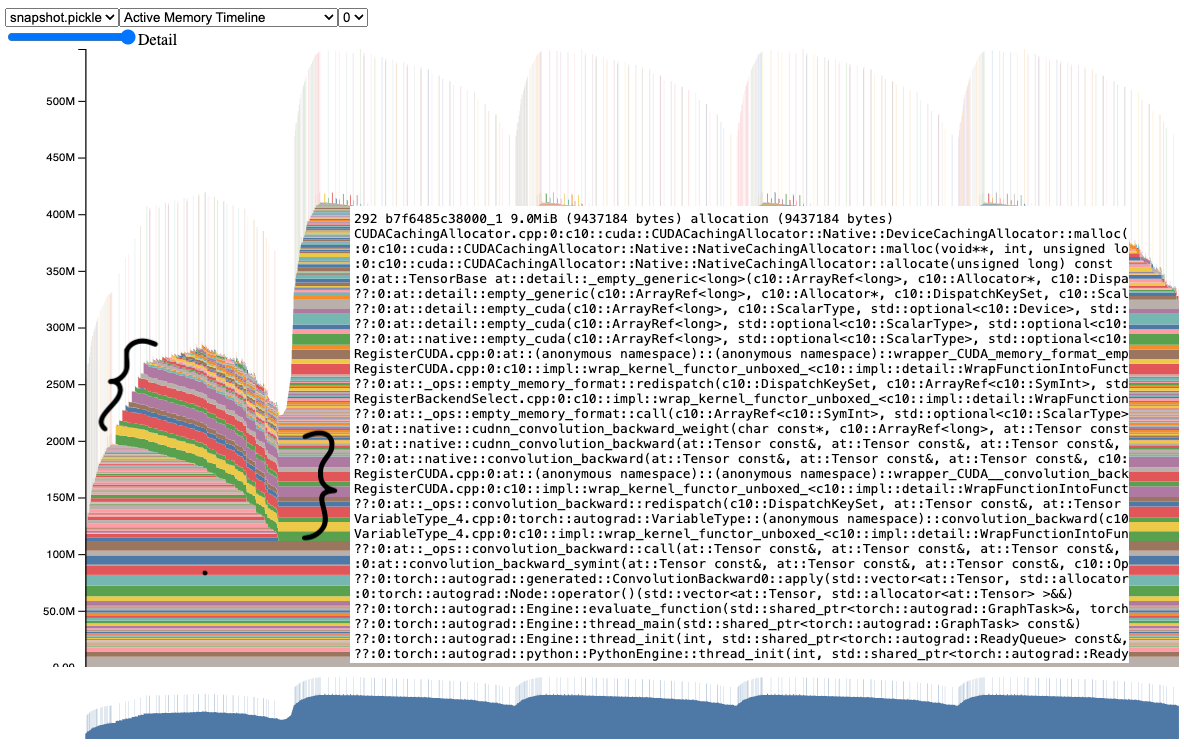
이 스냅샷을 더 자세히 살펴보면, 여러 텐서들이 첫 번째 반복에서 두 번째 및 이후 반복까지 계속 살아있는 것을 명확하게 볼 수 있습니다. 이러한 텐서 중 하나에 마우스를 올려놓으면, 이것들이 그래디언트 텐서(gradient tensors)임을 제안하는 스택 추적을 보여줍니다.
실제로 코드를 살펴보면, 순전파(forward) 전에 그래디언트 텐서를 지워야 함에도 불구하고 지우지 않는 것을 볼 수 있습니다.
Before:
for _ in range(num_iters):
pred = model(inputs)
loss_fn(pred, labels).backward()
optimizer.step()After:
for _ in range(num_iters):
pred = model(inputs)
loss_fn(pred, labels).backward()
optimizer.step()
# Add this line to clear grad tensors
optimizer.zero_grad(set_to_none=True)우리는 간단히 optimizer.zero_grad(set_to_none=True) 명령어를 추가하여 반복마다 그래디언트 텐서(gradient tensors)를 지울 수 있습니다 (그래디언트를 0으로 만들어야 하는 이유에 대한 자세한 내용은 여기에서 확인하세요: https://pytorch.org/tutorials/recipes/recipes/zeroing_out_gradients.html).
이것은 이 도구를 사용하여 더 복잡한 프로그램에서 발견한 버그의 단순화된 예시입니다. GPU 메모리 문제에 대해 메모리 스냅샷(Memory Snapshot)을 사용해 보고 어떻게 되는지 알려주세요.
버그 수정 후 ResNet50
수정을 적용한 후, 스냅샷은 이제 그래디언트를 지우는 것으로 보입니다.
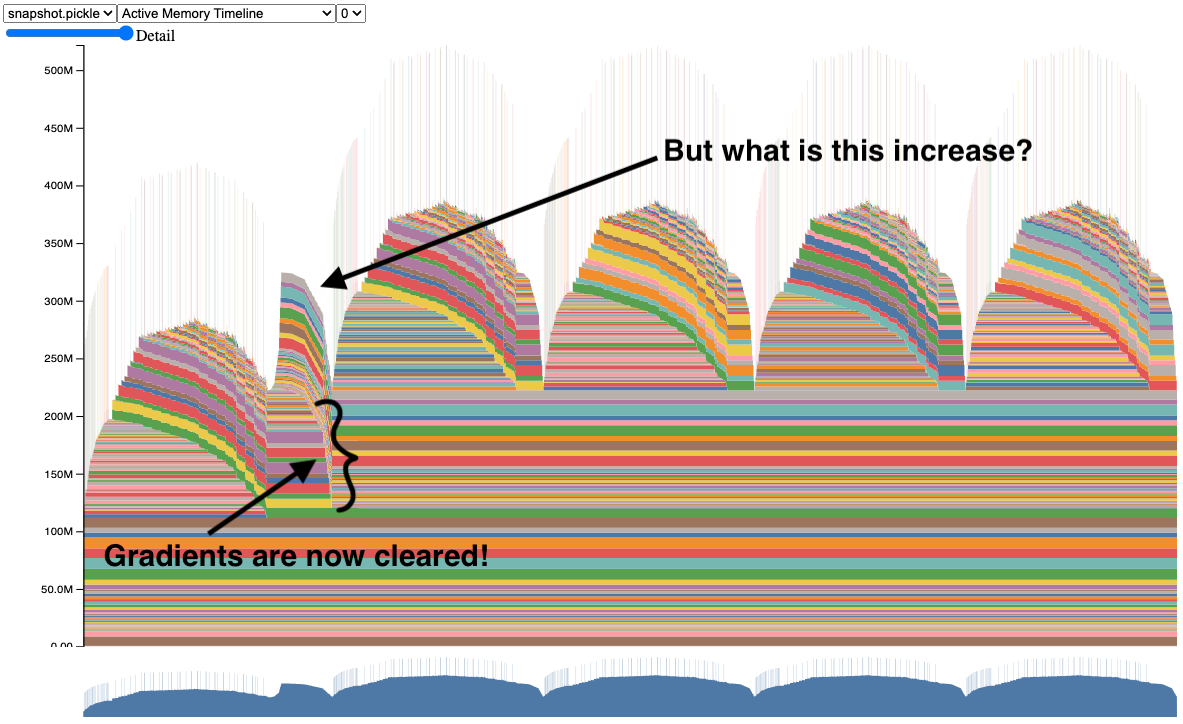
이제 우리는 제대로 작동하는 ResNet50 모델의 스냅샷을 가지고 있습니다. 코드를 직접 시도해 보세요 (부록 A에서 코드 샘플을 참조하세요).
하지만 첫 번째 반복 후에도 메모리가 여전히 증가하는 이유가 궁금할 수 있습니다. 이에 대한 답을 얻기 위해, 다음 섹션의 메모리 프로파일러(Memory Profiler)를 살펴봅시다.
분류된 메모리 사용량(CATEGORIZED MEMORY USAGE)
메모리 프로파일러는 PyTorch 프로파일러(PyTorch Profiler)의 추가 기능으로, 시간에 따른 메모리 사용량을 분류합니다. 메모리 할당에 대한 심층 분석을 위한 스택 추적을 위해 여전히 메모리 스냅샷(Memory Snapshot)에 의존합니다.
메모리 타임라인을 생성하기 위한 코드 스니펫은 다음과 같습니다 (전체 코드 샘플은 부록 B에 있음):
# Initialize the profiler context with record_shapes, profile_memory,
# and with_stack set to True.
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1),
record_shapes=True,
profile_memory=True,
with_stack=True,
on_trace_ready=trace_handler,
) as prof:
# Run the PyTorch Model inside the profile context.
for _ in range(5):
prof.step()
with record_function("## forward ##"):
pred = model(inputs)
with record_function("## backward ##"):
loss_fn(pred, labels).backward()
with record_function("## optimizer ##"):
optimizer.step()
optimizer.zero_grad(set_to_none=True)
# Construct the memory timeline HTML plot.
prof.export_memory_timeline(f"{file_prefix}.html", device="cuda:0")더 자세한 참고를 위해, https://pytorch.org/docs/main/profiler.html 을 확인하세요.
메모리 프로파일러(Memory Profiler)는 프로파일링 중에 기록된 텐서 연산의 그래프에 기반하여 자동으로 카테고리를 생성합니다.
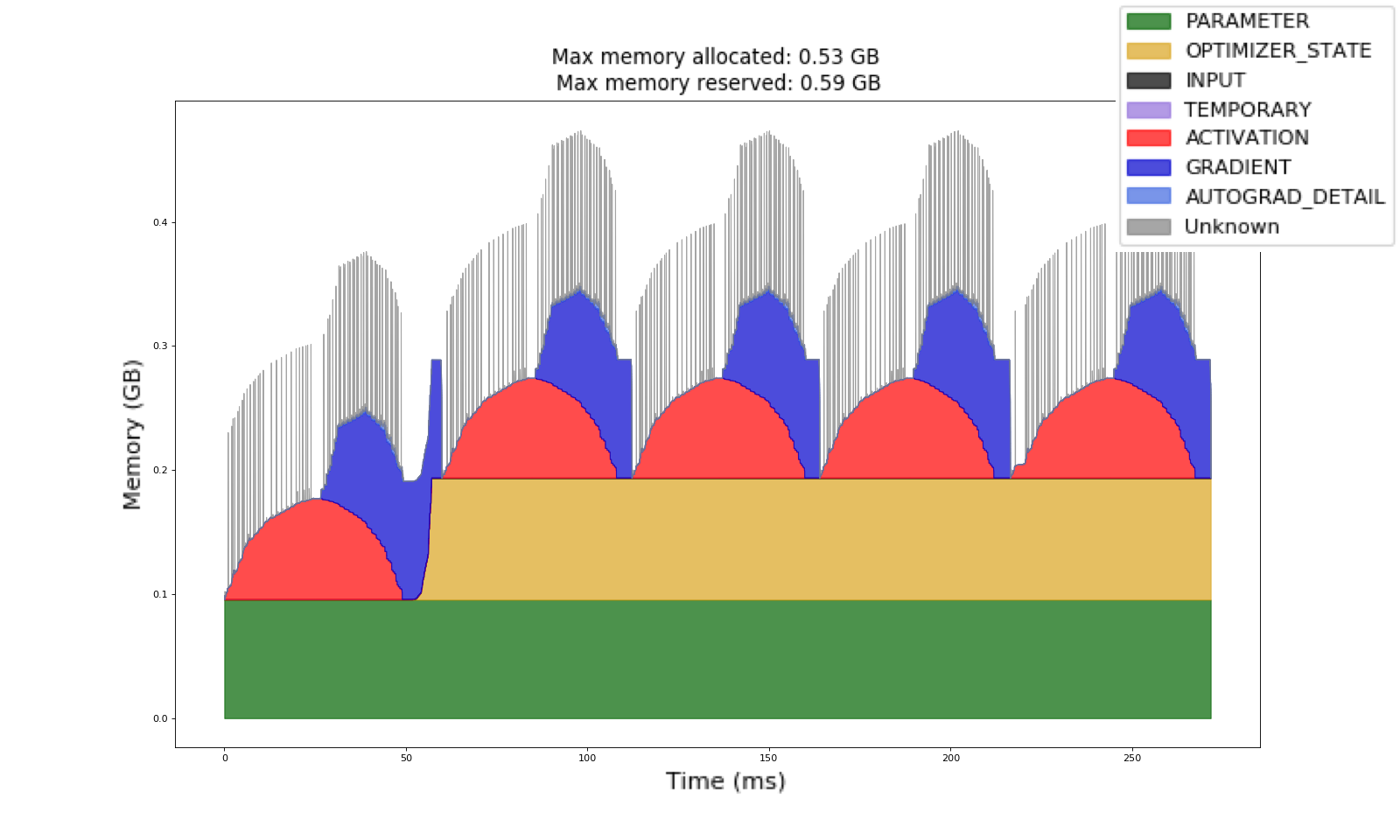
메모리 프로파일러(Memory Profiler)를 사용하여 수집된 이 메모리 타임라인(Memory Timeline)에서, 우리는 이전과 같은 트레이닝 예제를 가지고 있습니다. 이제 반복마다 파란색으로 표시된 그래디언트(gradients)가 지워지는 것을 관찰할 수 있습니다. 또한 첫 번째 반복 이후에 할당된 노란색의 옵티마이저 상태(optimizer state)가 일관되게 유지되는 것을 볼 수 있습니다.
이 옵티마이저 상태는 첫 번째 반복에서 두 번째 반복으로 GPU 메모리가 증가하는 이유입니다. 코드를 직접 시도해 보세요 (부록 B에서 코드 샘플을 참조하세요). 메모리 프로파일러는 트레이닝 메모리 이해를 향상시켜 모델 작성자가 GPU 메모리를 가장 많이 사용하는 카테고리를 파악할 수 있도록 도와줍니다.
이 도구들은 어디에서 찾을 수 있나요? (WHERE CAN I FIND THESE TOOLS?)
이 도구들은 CUDA OOMs를 디버깅하고 카테고리별 메모리 사용을 이해하는 능력을 크게 향상시킬 것이라고 기대합니다.
메모리 스냅샷(Memory Snapshot)과 메모리 프로파일러는 PyTorch의 v2.1 릴리스에서 실험적 기능으로 제공됩니다.
- More information about the Memory Snapshot can be found in the PyTorch Memory docs here.
- More details about the Memory Profiler can be found in the PyTorch Profiler docs here.
피드백 (FEEDBACK)
우리 도구들이 해결한 향상, 버그 또는 메모리 이야기에 대해 듣고 싶습니다! 항상 그렇듯, PyTorch의 Github 페이지에 새로운 이슈를 열어주시기 바랍니다.
우리는 OSS 커뮤니티의 기여에도 열려 있으며, Github PR에 Aaron Shi와 Zachary DeVito를 태그하여 리뷰를 요청할 수 있습니다.
감사의 말 (ACKNOWLEDGEMENTS)
이 글을 검토하고 가독성을 향상시켜 준 콘텐츠 검토자 Mark Saroufim과 Gregory Chanan에게 진심으로 감사합니다.
Adnan Aziz와 Lei Tian의 코드 리뷰와 피드백에도 진심으로 감사합니다.
부록(APPENDIX)
부록(Appendix) A - ResNet50 Memory Snapshot Code Example
# (c) Meta Platforms, Inc. and affiliates.
import logging
import socket
from datetime import datetime, timedelta
import torch
from torchvision import models
logging.basicConfig(
format="%(levelname)s:%(asctime)s %(message)s",
level=logging.INFO,
datefmt="%Y-%m-%d %H:%M:%S",
)
logger: logging.Logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
TIME_FORMAT_STR: str = "%b_%d_%H_%M_%S"
# Keep a max of 100,000 alloc/free events in the recorded history
# leading up to the snapshot.
MAX_NUM_OF_MEM_EVENTS_PER_SNAPSHOT: int = 100000
def start_record_memory_history() -> None:
if not torch.cuda.is_available():
logger.info("CUDA unavailable. Not recording memory history")
return
logger.info("Starting snapshot record_memory_history")
torch.cuda.memory._record_memory_history(
max_entries=MAX_NUM_OF_MEM_EVENTS_PER_SNAPSHOT
)
def stop_record_memory_history() -> None:
if not torch.cuda.is_available():
logger.info("CUDA unavailable. Not recording memory history")
return
logger.info("Stopping snapshot record_memory_history")
torch.cuda.memory._record_memory_history(enabled=None)
def export_memory_snapshot() -> None:
if not torch.cuda.is_available():
logger.info("CUDA unavailable. Not exporting memory snapshot")
return
# Prefix for file names.
host_name = socket.gethostname()
timestamp = datetime.now().strftime(TIME_FORMAT_STR)
file_prefix = f"{host_name}_{timestamp}"
try:
logger.info(f"Saving snapshot to local file: {file_prefix}.pickle")
torch.cuda.memory._dump_snapshot(f"{file_prefix}.pickle")
except Exception as e:
logger.error(f"Failed to capture memory snapshot {e}")
return
# Simple Resnet50 example to demonstrate how to capture memory visuals.
def run_resnet50(num_iters=5, device="cuda:0"):
model = models.resnet50().to(device=device)
inputs = torch.randn(1, 3, 224, 224, device=device)
labels = torch.rand_like(model(inputs))
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)
loss_fn = torch.nn.CrossEntropyLoss()
# Start recording memory snapshot history
start_record_memory_history()
for _ in range(num_iters):
pred = model(inputs)
loss_fn(pred, labels).backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
# Create the memory snapshot file
export_memory_snapshot()
# Stop recording memory snapshot history
stop_record_memory_history()
if __name__ == "__main__":
# Run the resnet50 model
run_resnet50()부록(Appendix) B - ResNet50 Memory Profiler Code Example
# (c) Meta Platforms, Inc. and affiliates.
import logging
import socket
from datetime import datetime, timedelta
import torch
from torch.autograd.profiler import record_function
from torchvision import models
logging.basicConfig(
format="%(levelname)s:%(asctime)s %(message)s",
level=logging.INFO,
datefmt="%Y-%m-%d %H:%M:%S",
)
logger: logging.Logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
TIME_FORMAT_STR: str = "%b_%d_%H_%M_%S"
def trace_handler(prof: torch.profiler.profile):
# Prefix for file names.
host_name = socket.gethostname()
timestamp = datetime.now().strftime(TIME_FORMAT_STR)
file_prefix = f"{host_name}_{timestamp}"
# Construct the trace file.
prof.export_chrome_trace(f"{file_prefix}.json.gz")
# Construct the memory timeline file.
prof.export_memory_timeline(f"{file_prefix}.html", device="cuda:0")
def run_resnet50(num_iters=5, device="cuda:0"):
model = models.resnet50().to(device=device)
inputs = torch.randn(1, 3, 224, 224, device=device)
labels = torch.rand_like(model(inputs))
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)
loss_fn = torch.nn.CrossEntropyLoss()
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1),
record_shapes=True,
profile_memory=True,
with_stack=True,
on_trace_ready=trace_handler,
) as prof:
for _ in range(num_iters):
prof.step()
with record_function("## forward ##"):
pred = model(inputs)
with record_function("## backward ##"):
loss_fn(pred, labels).backward()
with record_function("## optimizer ##"):
optimizer.step()
optimizer.zero_grad(set_to_none=True)
if __name__ == "__main__":
# Warm up
run_resnet50()
# Run the resnet50 model
run_resnet50()