Stack
Stack에서는 LIFO(Last In First Out)라는 개념이 등장한다. 이는 말 그대로 가장 마지막에 들어온 데이터가 가장 먼저 빠진다는 개념이다. 이러한 구조를 Stack 구조라고 한다. 때문에 Stack에 쌓여있는 데이터 중에 중간에 들어있는 데이터를 제거하려 한다면, 쌓여있는 탑의 가장 윗 데이터 부터 따로 빼놓고 제거해야 한다. Stack을 조금 더 쉽게 예시를 들어 보겠다.
Stack 은 마치 아주 무거운 택배 상자가 쌓여 있다고 생각해보자. 공간이 부족해서 위로만 쌓을 수 있는데, 택배 기사는 새로운 택배 상자를 가져와서 이미 쌓인 택배 위에 새롭게 쌓았다. 나는 당장 밑에서 두번째 상자의 물건이 필요한데, 상자는 이미 많이 쌓여 있었고, 하는 수 없이 위에 상자를 하나씩 내려놓았다. 두번째 상자를 빼놓고 나머지 물건은 아직 사용하지 않기 때문에 기존 박스 위에 다른 박스들을 다시 올려놓았다.
Stack은 위의 예제 처럼, 중간에 있는 데이터 'A' 를 제거하기 위해서는 데이터 'A' 보다 위에 있는 값들을 임시로 저장을 해둔 뒤, 데이터 'A'를 제거하고 임시로 저장 했던 데이터들을 Stack으로 다시 넣는다. 이때, Stack에서 데이터를 빼는 행위는 Pop이라고 하며, 데이터를 넣는 행위를 Push라고 한다. 그리고 현재의 Stack에서 가장 위에 있는 데이터를 Top이라고 지칭한다. 추가적으로 len(원소의 개수를 반환)과 is_empty(저장된 원소가 없으면 true, 있다면 false를 반환)라는 연산을 가지고 있다.
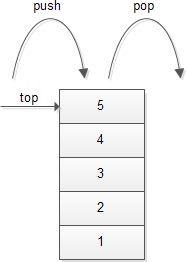
출처: http://www.zentut.com/c-tutorial/c-stack-using-array/
pseudo code
Stack에 있는 데이터의 중간 값을 제거하는 pseudo code는 다음과 같다.
A = [1,2,3,4,5]
먼저 어떤 데이터를 지울지 입력(n)을 받는다.
그리고 임시로 담을 배열도 선언 한다.
Temp = []
for i, A.length, i++
if A.top !== n
A.top.push
A.top.pop
else if A.top == n
A.top.pop 혹은 새로운 변수에 담는다.
break
기존의 데이터 A에 임시 저장했던 데이터를 삽입한다.
for i, temp.length, i++
A.push(temp[i])Queue
Queue에서는 First In First Out(FIFO)라는 개념이 등장한다. 이는 말 그대로 처음 들어왔던 데이터가 가장 먼저 제거 된다는 뜻이다. 기본적으로 데이터를 넣는 행위를 enqueue라고 하며, 제거하는 행위를 dequeue라고 한다. enqueue는 기존의 데이터 위에 추가가 되며, dequeue는 가장 처음 넣었던 데이터가 제거가 된다. 마치 Stack과 같은 그림에서 눌러 밀려나 듯 말이다. 추가적으로 first, len, is_empty의 기능들이 있다. queue가 가득 찬 상태에서 enqueue를 하거나, 빈 queue에서 dequeue, first를 사용하면 Exception이 발생한다. Queue를 쉽게 예시를 들어 보겠다.
Queue는 이미 우리 실생활에서 찾아볼 수 있다. 차량용 블랙박스나, CCTV에 자주 사용 되고 있다. 이들은 저장 공간의 한계가 있기 때문에, 디스크의 용량이 가득 차기 전에 가장 오래된 영상을 먼저 삭제하는 특징을 가졌다. 옛날의 데이터보다 최근의 데이터가 더 가치 있기 때문이다.

출처 : https://www.journaldev.com/21355/swift-queue-data-structure
pseudo code
추가 예정Linked List
Linded List는 Stack과 Queue와는 조금 다르다.~완벽하게 메모리의 공간자체가 연결되어있는~ (JavaScript에서의 메모리 사용법은 조금 다르다고 한다.) Stack과 Queue와는 달리 각각의 데이터는 Node와 Reference를 가지고 있다. Node에는 값과 next라는 다음 데이터의 주소가 들어있고, Reference는 자신이 참조 받고 있음을 가지고있다. 따라서 각 데이터들은 다음 데이터의 주소 값을 기준으로(Node에 있는 next 값) 연결되어 있다.
이때, Reference가 없지만, Node에 next가 연결하는 값이 있는 경우 데이터는 자신보다 앞에 데이터가 없다는 것을 의미하며, 리스트의 시작점이다(Head). 그리고 연결 받는 Node만 있는 경우(Reference) 리스트의 마지막 데이터이다. Linked List를 쉽게 예를 들어보자.
고요 속의 외침 이라는 게임이 있다. 제시하는 문제에 집중하지 말고 전달하는 순서에 초점을 맞춰서 생각해보자. 문제를 제시하는 사람이 Haed, 마지막에 맞추는 사람이 Tail 이다. 문제를 제시하는 Head는 Reference는 없지만 문제를 넘길 다음 사람이(next) 있다. 처음으로 문제를 받은 사람은 자신에게 문제를 전해준 Reference와 다음으로 전달해야 할 next를 가지고 있다. 그리고 마지막에 문제를 받을 Tail은 나에게 문제를 전달해준 Reference는 있지만, 다시 문제를 전달 할 필요가 없기에 next는 가지고 있지 않다.
Linked List에서 중간에 데이터를 삽입하게 될 경우, 삽입하고자 하는 위치의 앞 데이터의 next 값을 변경해야 한다. 먼저 앞 데이터의 next 값을 새로운 데이터의 next에 삽입한다. 그리고 앞 데이터의 next에는 새로운 데이터의 주소를 삽입한다.
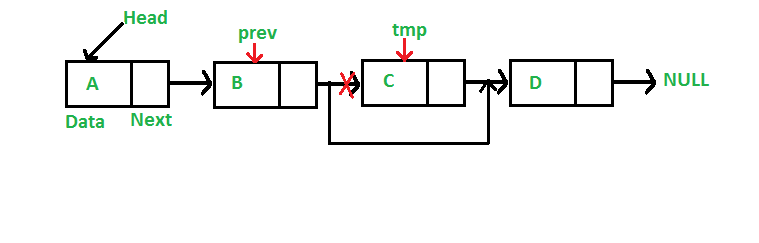
출처 : https://www.geeksforgeeks.org/linked-list-set-3-deleting-node/


출처 : https://opentutorials.org/module/1335/8821
pseudo code
추가 예정