
머신러닝 모델을 만드는 과정

1. 과거의 데이터를 준비한다.
2. 모델의 구조를 만든다.
3. 데이터로 모델을 학습(FIT)한다.
4. 모델을 이용한다.
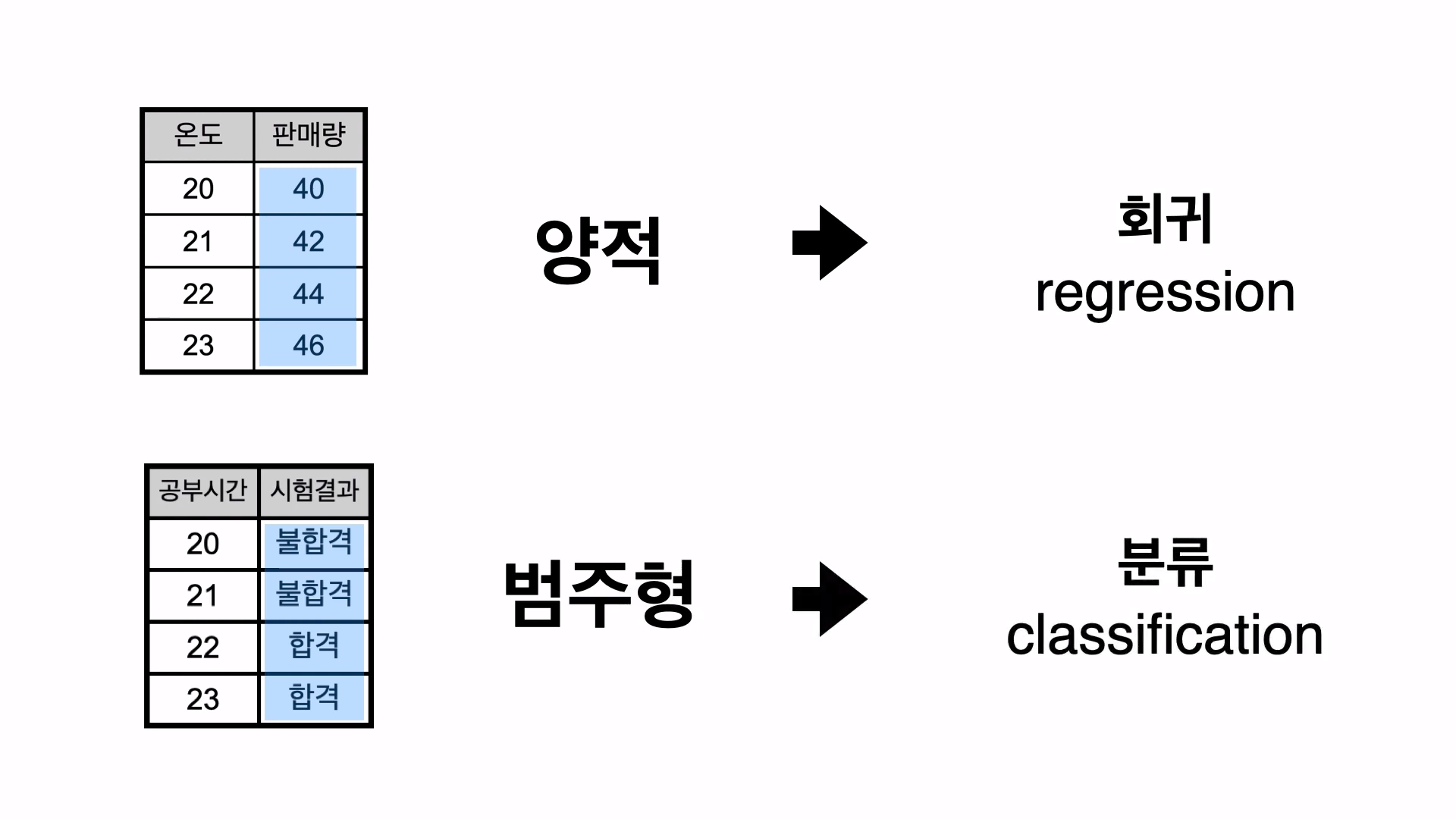
다음과 같이 종속변수가 '양적데이터'일땐 '회귀'를 이용하고 '범주형데이터'일땐 '분류'를 이용한다.
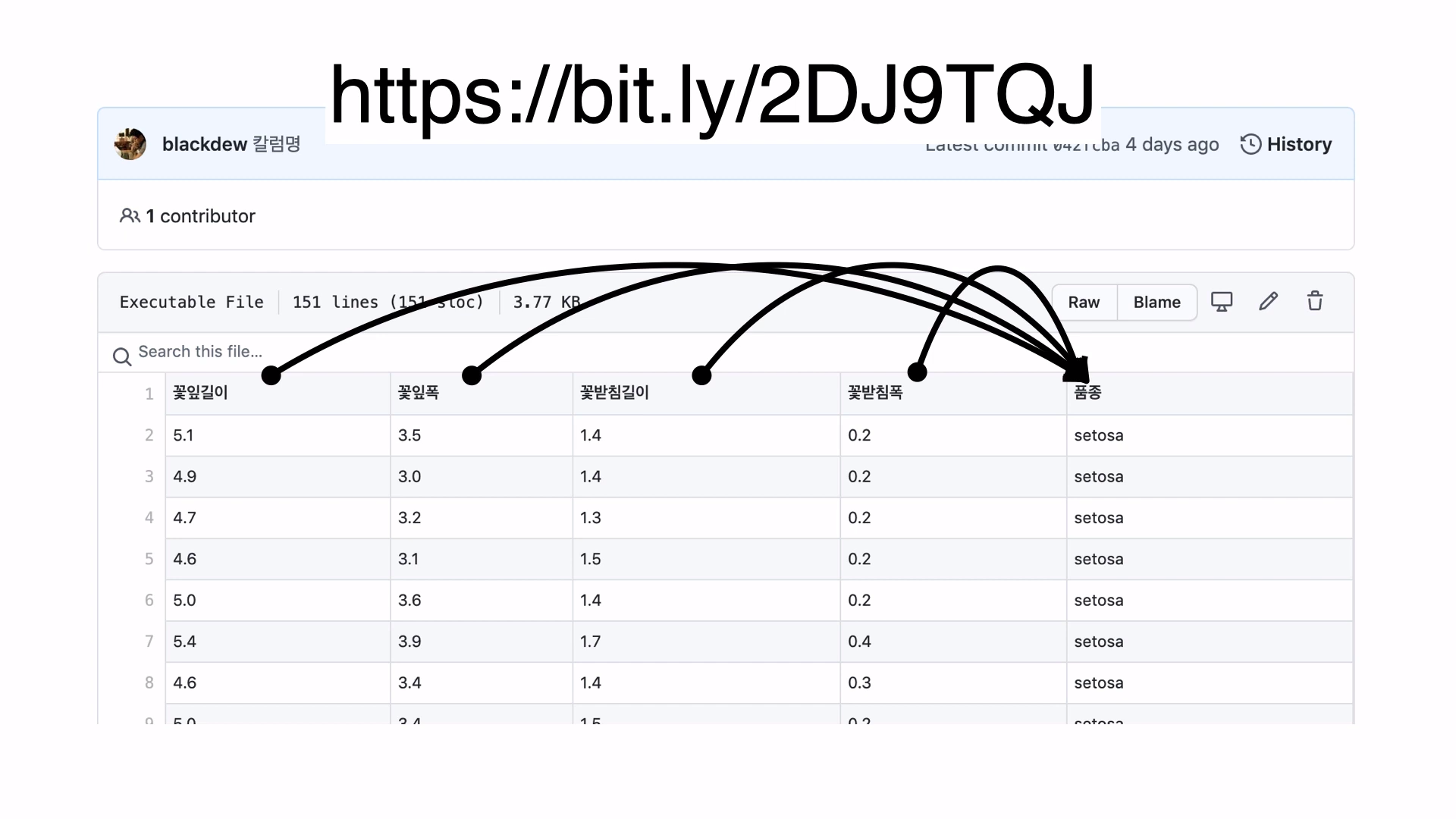
아이리스 데이터도 종속변수가 '범주형데이터'이기 때문에 '분류'를 사용해야 한다.
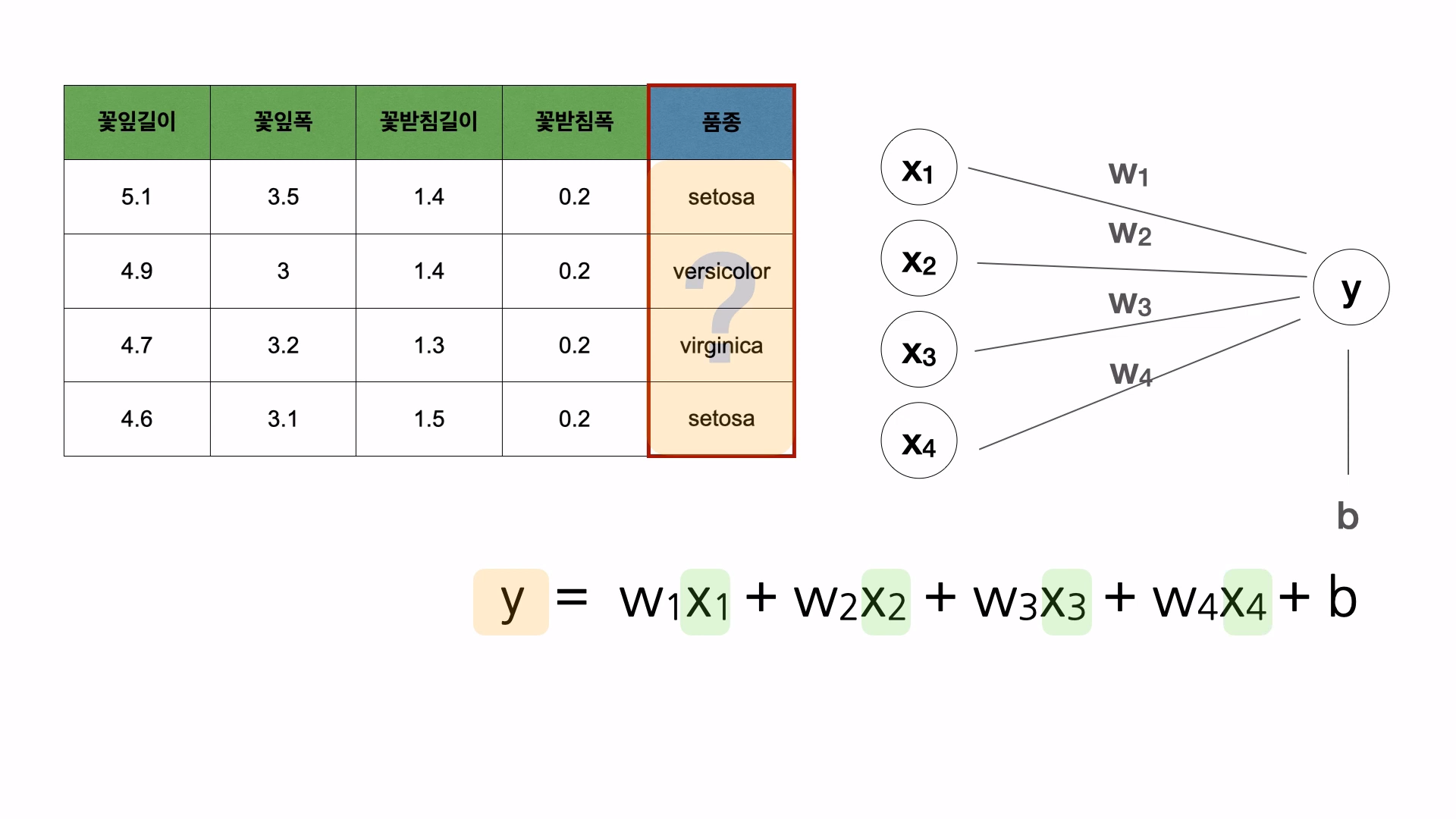
위와 같은 수식에서는 입력이든 출력이든 숫자만 들어갈 수 있다. 종속변수가 '양적 데이터'인 경우에는 수식을 사용할 수 있지만 입력과 출력이 문자인 '범주형 데이터'는 위와 같은 수식을 사용할 수 없다.
따라서 '범주형 데이터'를 수식에 사용할 수 있는 형태로 바꿔주는 과정을 거쳐야 한다.
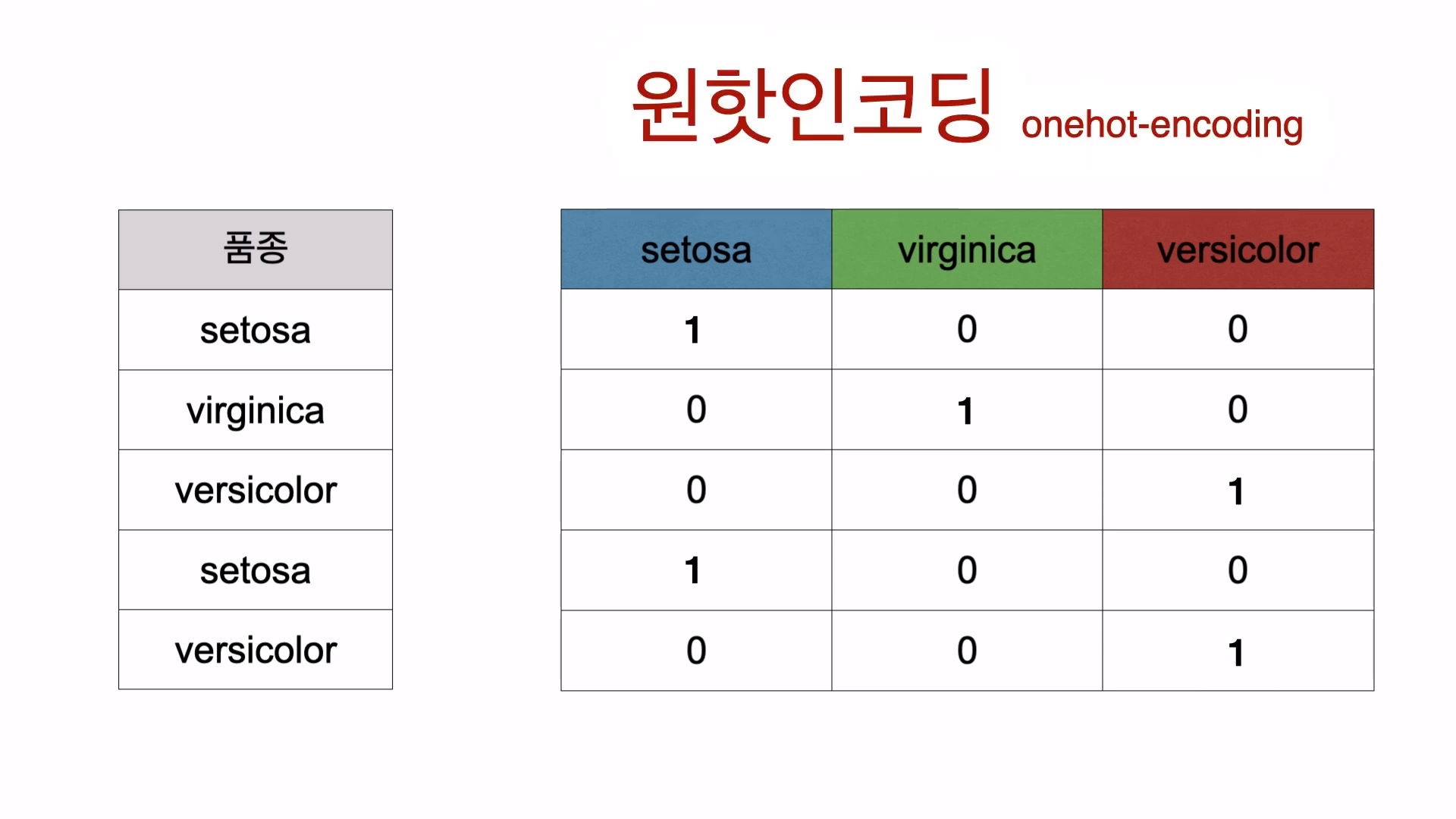
'범주형 데이터'를 수식에 사용할 수 있는 형태로 바꿔주는 과정을 '원핫인코딩'이라고 한다.
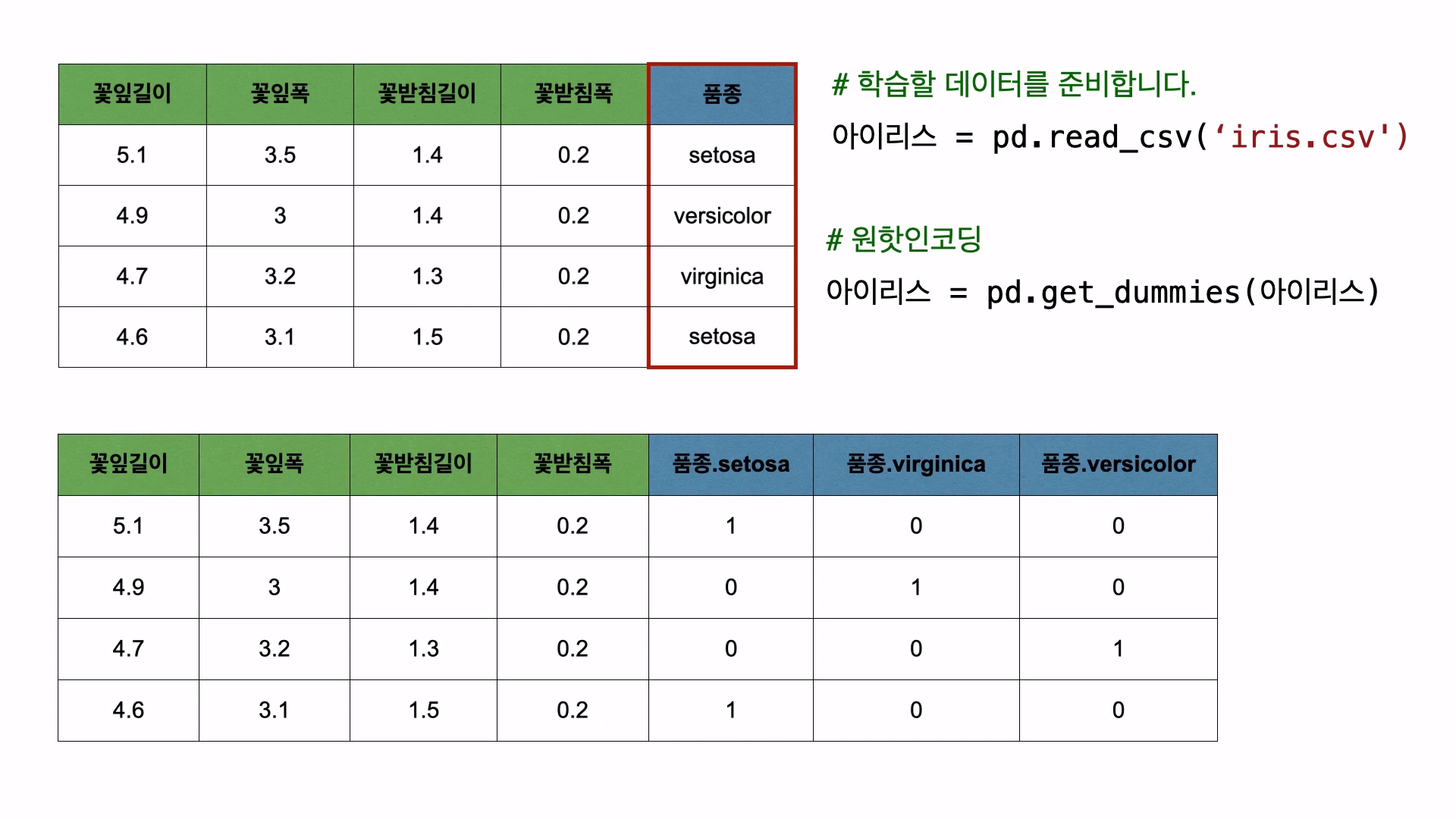
원핫인코딩은 위와 같이 진행한다.
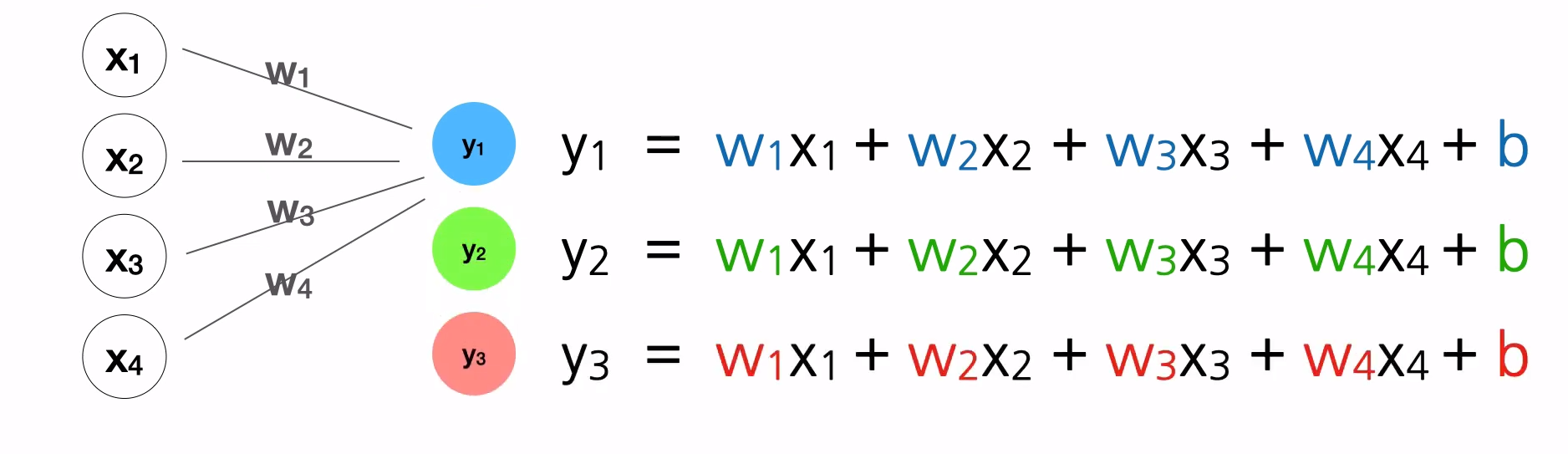
종속변수가 총 3개이므로 3개의 수식이 필요하다.
소프트맥스
우리가 만든 모델이 하는 일은 분류를 추측하는 일이다. 'Sigmoid'와 'Softmax'라는 도구는 분류를 추측한 것을 0% ~ 100% 사이의 퍼센트에이지로 표현한다.
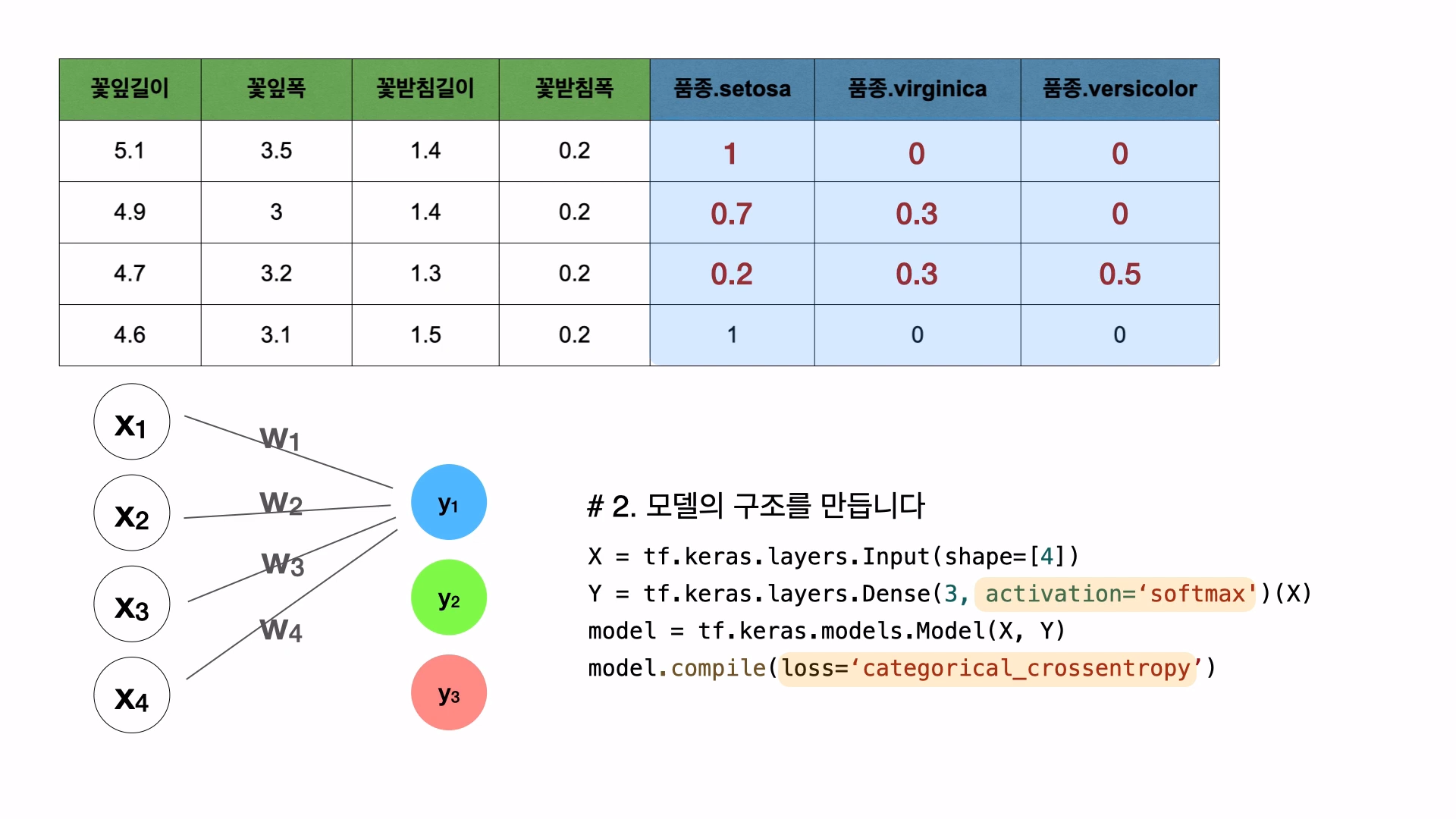
softmax는 위와 같은 코드로 사용하고, 상단의 표에서 종속변수의 값인 0, 0.3, 0.5, 1은 각각 0%, 30%, 50%, 100%를 나타내는 수치이다.
학습이 제대로 되게하려면 문제의 유형에 맞게 loss를 지정해줘야 한다. 이것을 도와주는 것이 'categorical_crossentropy'이다. 분류에서는 'categorical_crossentropy'를 사용하고 회귀에서는 'mse'를 사용한다.
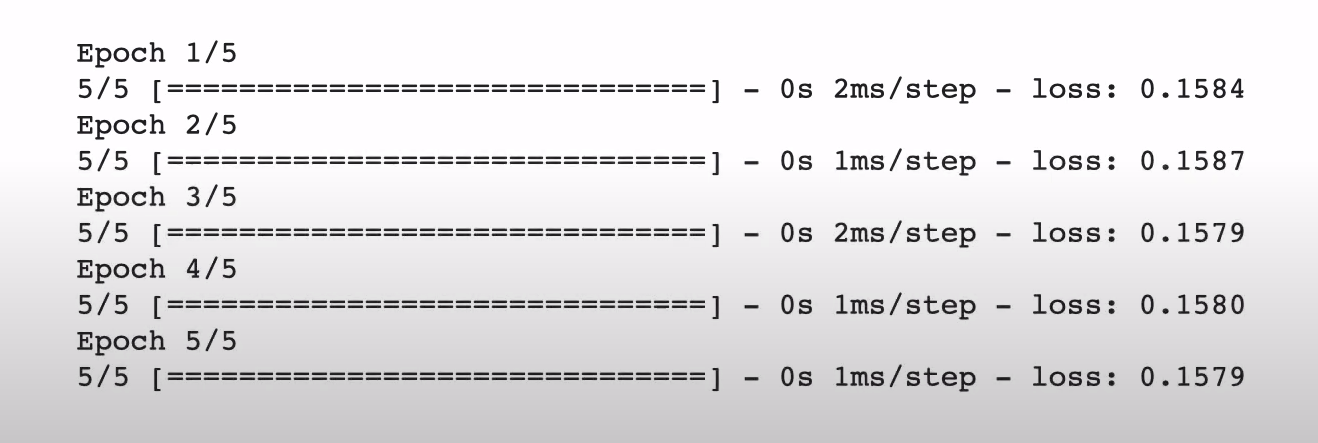
위의 loss값이 crossentropy를 통해 계산된 차이값을 이용한 수치이다.

metrics값으로 'accuracy'를 추가하면 정확도까지 알 수 있다. 1은 정확도가 100%란 뜻이다.
실습
라이브러리 사용
import tensorflow as tf
import pandas as pd1.과거의 데이터를 준비합니다.
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv'
아이리스 = pd.read_csv(파일경로)
아이리스.head()실행결과
원핫인코딩
인코딩 = pd.get_dummies(아이리스)
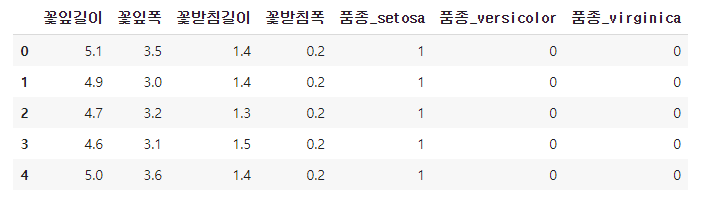
인코딩.head()실행결과
칼럼이름 출력
print(인코딩.columns)실행결과
Index(['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭', '품종_setosa', '품종_versicolor', '품종_virginica'], dtype='object')
독립변수, 종속변수
독립 = 인코딩[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
종속 = 인코딩[['품종_setosa', '품종_versicolor', '품종_virginica']]
print(독립.shape, 종속.shape)2. 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[4])
Y = tf.keras.layers.Dense(3, activation='softmax')(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')3.데이터로 모델을 학습(FIT)합니다.
model.fit(독립, 종속, epochs=1000, verbose=0)
model.fit(독립, 종속, epochs=10)실행결과
Epoch 1/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1263 - accuracy: 0.9800 Epoch 2/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1261 - accuracy: 0.9800 Epoch 3/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1267 - accuracy: 0.9867 Epoch 4/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1263 - accuracy: 0.9800 Epoch 5/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1262 - accuracy: 0.9800 Epoch 6/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1259 - accuracy: 0.9800 Epoch 7/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1261 - accuracy: 0.9867 Epoch 8/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1257 - accuracy: 0.9800 Epoch 9/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1263 - accuracy: 0.9800 Epoch 10/10 5/5 [==============================] - 0s 2ms/step - loss: 0.1258 - accuracy: 0.9800 <tensorflow.python.keras.callbacks.History at 0x7f068b73ebe0>정확도가 98%에 도달한 것을 알 수 있다.
모델을 이용합니다.
#맨 처음 데이터 5개
print(model.predict(독립[0:5]))
print(종속[0:5])실행결과
[[9.9968970e-01 3.1028493e-04 1.5116044e-09] [9.9815089e-01 1.8490498e-03 2.3181773e-08] [9.9934810e-01 6.5187435e-04 7.1573996e-09] [9.9807125e-01 1.9287227e-03 4.6842064e-08] [9.9977940e-01 2.2056155e-04 1.1390902e-09]] 품종_setosa 품종_versicolor 품종_virginica 0 1 0 0 1 1 0 0 2 1 0 0 3 1 0 0 4 1 0 0정답에 거의 근접하도록 예측한 것을 알 수 있다.
학습한 가중치
model.get_weights()실행결과
[array([[ 1.1206117 , 1.0070976 , -0.76022446], [ 3.6882255 , 0.16067708, -1.0229104 ], [-4.57068 , -0.96101767, 1.532893 ], [-4.1812778 , -1.1235818 , 2.1811411 ]], dtype=float32), array([ 2.22937 , 1.4119343, -1.8166612], dtype=float32)]
