오늘은 자율주행에 쓰이는 알고리즘들 중 컴퓨터 비전(영상인식)관련 알고리즘들을 알아보려고 한다.
컴퓨터 비전
컴퓨터 비전이란 카메라, 클라우드 기반 컴퓨팅, 소프트웨어 및 인공지능을 결합하여 시스템이 사물을 '확인'하고 식별할 수 있게 하는 기술이다. 컴퓨터 비전은 딥 러닝을 사용하여 이미지, 영상 처리 및 분석 시스템을 안내하는 신경망을 형성한다. 충분히 훈련된 컴퓨터 비전 모델은 사물을 인식하고 사람을 감지하거나 인식하며 움직임도 추적할 수 있다.
Object Detection
Object Detection은 Localization/Detection/Segmentation으로 나눌 수 있다.

Localization : 단 하나의 object 위치를 bounding box로 지정하여 찾는다.
Object Detection : 여러 개의 Object들에 대한 위치를 Bounding box로 지정하여 찾는다.
Segmentation : Detection보다 더 발전한 형태로 pixel 레벨 Detection을 수행한다.
Region Proprosal - Selective Search
영역추정은 object가 있을만한 후보영역을 찾는 행위이다. 이미지상에서 object가 있는지 없는지 모르기 때문에 object가 존재하지 않는 배경영역들을 불필요하게 탐색하면서 자원이 낭비된다. 이를 방지하기 위해 object가 있을 만한 후보 영역을 찾는 것이 영역추정 기법 기법이다.
Selective Search는 빠른 Detection과 높은 Recall 예측 성능을 동시에 만족하는 알고리즘이다. 컬러, 무늬, 크기, 형태에 따라 유사한 Region을 계층적 그룹핑 방법으로 계산한다.
Selective Search의 수행 프로세스

1. 개별 Segment된 모든 부분들을 Bounding box로 만들어서 Region Proposal 리스트로 추가
2. 컬러, 무늬(Texture), 크기(Size), 형태(Shape)에 따라 유사도가 비슷한 Segment들을 그룹핑함.
3. 다시 1번 Step Region Proposal 리스트 추가, 2번 Step 유사도가 비슷한 Segment들 그룹핑을 계속 반복 하면서 Region Proposal을 수행
IoU(Intersection over Union)
모델이 예측한 결과와 실측(Ground Truth) Box가 얼마나 정확하게 겹치는가를 나타내는 지표이다.
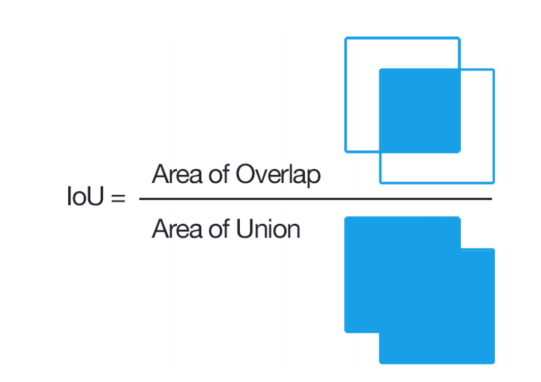
IoU = 개별 Box가 서로 겹치는 영역 / 전체 Box의 합집합 영역
NMS(Non Max Supression)

Object Detection 알고리즘은 Object가 있을 만한 위치에 많은 Detection을 수행하는 경향이 강하다. 이에 반해, NMS는 Detect된 Object의 Bounding Box 중에 비슷한 위치에 있는 box를 제거하고 가장 적합한 box를 선택하는 기법이다.
NMS 수행 로직
- Detected 된 bounding box별로 특정 Confidence threshold 이하
bounding box는 먼저 제거(confidence score < 0.5) - 가장 높은 confidence score를 가진 box 순으로 내림차순 정렬하고
아래 로직을 모든 box에 순차적으로 적용.
• 높은 confidence score를 가진 box와 겹치는 다른 box를 모두
조사하여 IOU가 특정 threshold 이상인 box를 모두 제거(예: IOU Threshold > 0.4 ) - 남아 있는 box만 선택
Confidence score가 높을수록, IoU Threshold가 낮을 수록 많은 Box가 제거된다.
성능 평가 지표 - mAP
실제 Object가 Detect된 재현율의 변화에 따른 정밀도의 값을 평균한 성능 수치이다.
- IoU
- Precision-Recall Curve, Average Precision
- Confidence threshold
정밀도와 재현율
정밀도(Precision)는 예측을 Positive로 한 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율을 뜻한다.
재현율(Recall)은 실제 값이 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율을 뜻한다.
R-CNN
R-CNN 알고리즘은 영역 추정 방식에 기반한 Object Detection 기법이다.

먼저 Stage 1 에서는 2000개의 영역 추정을 통해 후보군을 추천 받는다. 이 개별 후보군 이미지들을 같은 이미지 크기로 맞춘다. CNN은 같은 크기의 이미지로 모델을 학습시켜야 하기 때문이다.
Stage 2 에서는 CNN 알고리즘을 이용하여 이미지를 분류한다.
CNN에 대한 설명 : https://velog.io/@agapao1234/CNN%EC%9D%B4%EB%AF%B8%EC%A7%80-%EB%B6%84%EB%A5%98
R-CNN의 장단점
장점 : 높은 Detection 정확도
단점 : 너무 느린 Detection 시간과 복잡한 아키텍쳐 및 학습 프로세스
- 하나의 이미지마다 selective search를 수행하여 2000개의 region 영역 이미지들을 도출한다.
- 개별 이미지별로 2000개씩 생성된 region 이미지를 이용해 CNN Feature map을 생성한다.
- Selective search, CNN feature extractor, SVM과 Bounding box regressor로 구성되어 복잡한 프로세스를 거쳐서 학습 및 Object Detection이 되어야 한다.
Fast R-CNN
Fast R-CNN은 R-CNN의 한계점들을 극복하기 위해 탄생되었다. R-CNN은 연산을 공유하지 않고 모든 object 에 각각 convnet을 적용하기 때문에 속도가 굉장히 느리다. Fast R-CNN은 이 단점들을 극복하였다.
Fast R-CNN의 수행 로직
1-1. R-CNN에서와 마찬가지로 Selective Search를 통해 RoI를 찾는다.
1-2. 전체 이미지를 CNN에 통과시켜 feature map을 추출한다.
-
Selective Search로 찾았었던 RoI를 feature map크기에 맞춰서 projection시킨다.
-
projection시킨 RoI에 대해 RoI Pooling을 진행하여 고정된 크기의 feature vector를 얻는다.
-
feature vector는 FC layer를 통과한 뒤, 구 브랜치로 나뉘게 된다.
5-1. 하나는 softmax를 통과하여 RoI에 대해 object classification을 한다.
5-2. bounding box regression을 통해 selective search로 찾은 box의 위치를 조정한다.
Faster R-CNN
Faster R-CNN은 기존의 Fast R-CNN의 한계점을 보완해 Selective Search를 Neural Network 구조로 변경한 기법이다. Region Proposal을 CPU가 아닌 GPU를 활용하여 신경망 구조 안에서 해결했기 때문에 실제 detection 시간이 굉장히 짧다는 장점을 가지고 있다.

Faster R-CNN은 두 개의 모듈로 구성된다. 첫번째는 Region Proposal을 하는 Deep Conv Network 이고, 두 번째는 제안된 영역을 사용하는 Fast R-CNN이다.
RPN
Fast R-CNN의 가장 핵심적인 구조는 RPN이다. RPN은 Conv로 부터 얻은 Feature map의 어떠한 사이즈의 이미지를 input을 받고 출력으로 object가 있을 만한 영역을 추천해준다.
RPN의 구현 이슈는 데이터로 주어질 피처는 pixel 값, Target은 Ground truth Bounding Box 인데 이를 이용해 어떻게 Selective Search 수준의 Region Proposal을 할 수 있을 것인지 이다.
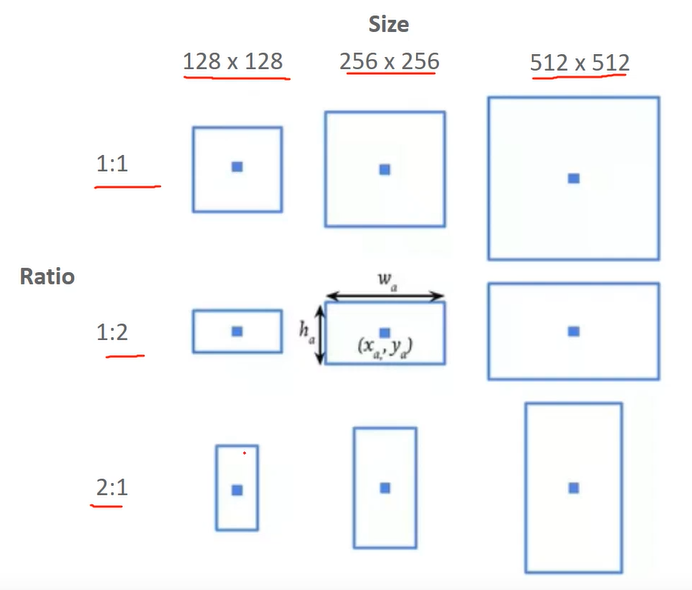
이를 해결하기위해 Anchor Box를 사용한다. Object가 있는지 없는지 후보 Box를 정해준다.
앵커박스는 총 9개로, 3개의 서로 다른크기, 3개의 서로 다른 ratio로 구성되어 있다.
Q-러닝
Q-러닝(Q-learning)은 모델 없이 학습하는 강화 학습 기법 중 하나이다. 현재 상태로부터 시작하여 마르코프 결정 과정에서 Agent가 특정 상황에서 특정 행동을 하라는 최적의 Policy를 배우는 것으로, 현재 상태로부터 시작하여 모든 연속적인 단계들을 거쳤을 때 전체 보상의 예측값을 극대화시킨다. 이것은 한 상태에서 다른 상태로의 전이가 확률적으로 일어나거나 보상이 확률적으로 주어지는 환경에서도 별다른 변형 없이 적용될 수 있다. 또한 'Q'라는 단어는 현재 상태에서 취한 행동의 보상에 대한 quality를 상징한다.
YOLO

YOLO(You Only Look Once)는 입력 이미지를 S X S Grid로 나누고, 각 Grid의 Cell이 하나의 Object에 대한 Detection을 수행한다.
각 Grid Cell 이 2개의 bounding box 후보를 기반으로 object의 bounding box를 예측한다.
하지만 YOLO v1은 앵커박스 기반은 아니여서 object가 있을 만한 곳을 추천받지 않기 때문에 속도는 빠르지만 Detection 성능은 떨어진다. 또한 각 셀이 하나의 object만 detect 하기 때문에 셀 안에 새떼 등 여러가지 object들이 있다면 그들 중 하나만 detect 한다.
