- CNN(Convolutional Neural Network)이란?
이미지의 특징을 추출할 때 많이 사용되던 것이 convolution연산이다. 이를 DNN과 결합해서 DNN에서 dense layer(fully-connected-layer)대신 convolution layer를 이용해 딥러닝 시키는 방식이 CNN인 것이다. 즉, 컴퓨터 비전으로 사용되는 DNN이 CNN이라고 생각할 수 있다.
CNN 구조로는 feature 추출 부분과 추론 부분을 모두 convolution layer로 구성한 유형과, feature 추출 부분은 convolution layer로 추론 부분은 dense layer로 구성한 유형이 존재한다. 요즘에는 모두 convolution layer를 쓰는 추세다. 그 이유로는 dense layer로 이미지의 공간적인 구조를 학습하는 것이 어렵기 때문이다. dense layer의 경우 선형회귀의 형태로 이미지를 flatten시키고 학습하게 될 텐데 이러면 width별로 잘라진 이미지가 이어진 형태를 학습하는 식이 될 것이다. 그러면 이미지 상에서 공간적인 구조의 의미가 크게 없어지게 된다.
ex) 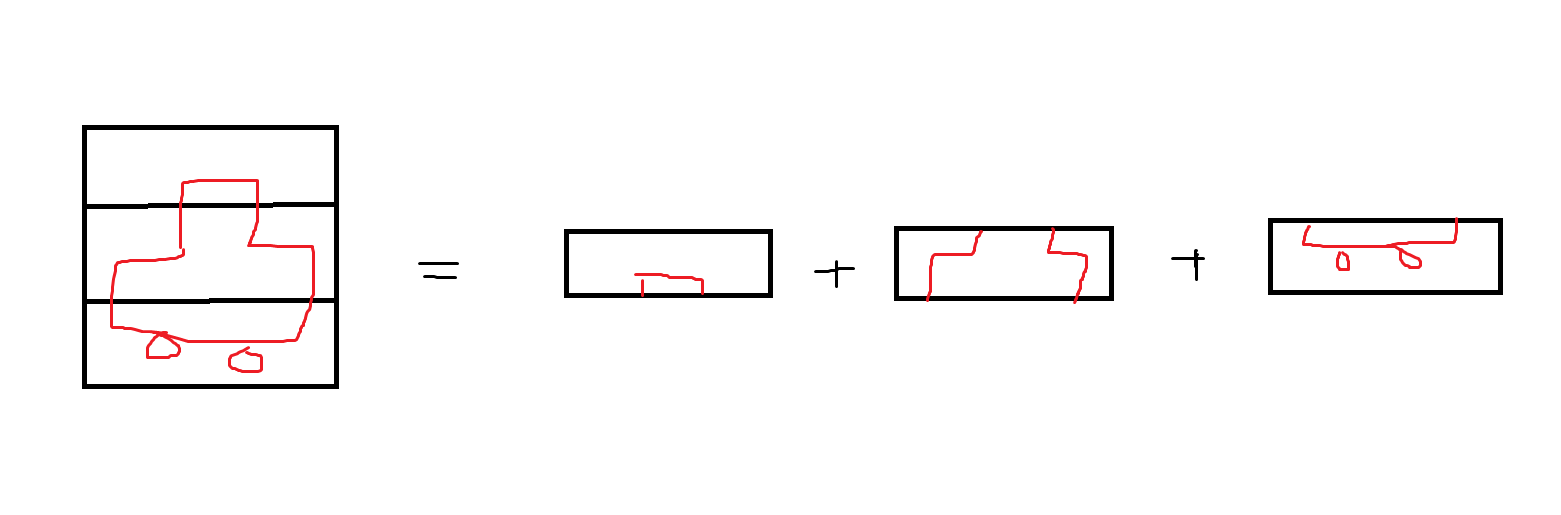
위 이미지를 보면 자동차를 전체적으로 보면 구조적이 특징을 알기 쉽지만 오른쪽 결과처럼 다 잘라서 나열하면 구조의 특징을 알기 어렵다.
또한 flatten된 이미지는 너무 많은 weight(가중치)를 필요로 하게 된다. 예를 들어 30x30픽셀의 이미지만 해도 flatten시킬 경우 900이 된다. 즉 900개의 가중치를 필요하게 되는 것이다. 만약 여기에 rgb까지 생각한다면 900x3개의 가중치가 생긴다. 이런식으로 이미지를 dense layer로 학습하려면 너무 많은 가중치를 학습해야 하는 문제가 생긴다.
1.Convolution(합성곱)을 이미지에 사용하는 이유
이미지에 특정 필터(마스크/윈도우/커널이라고도 부름)을 사용해 합성곱을 해주었을 때 필터와 부분 이미지의 합성곱 결과가 값이 나온다는 것은 그 부분 이미지에 필터가 표현하는 이미지특성이 존재한다는 것이다.
합성곱을 진행하는 방식이 같은 위치에 있는 값들을 곱하고 그 값들을 모두 더하는 식이므로, 필터를 적용한 부분 이미지가 필터와 유사한 위치에 유사한 값들을 가지고 있다면 합성곱 결과가 클 것이다.
2.Convolution(합성곱) 원리와 Convolutional Layer
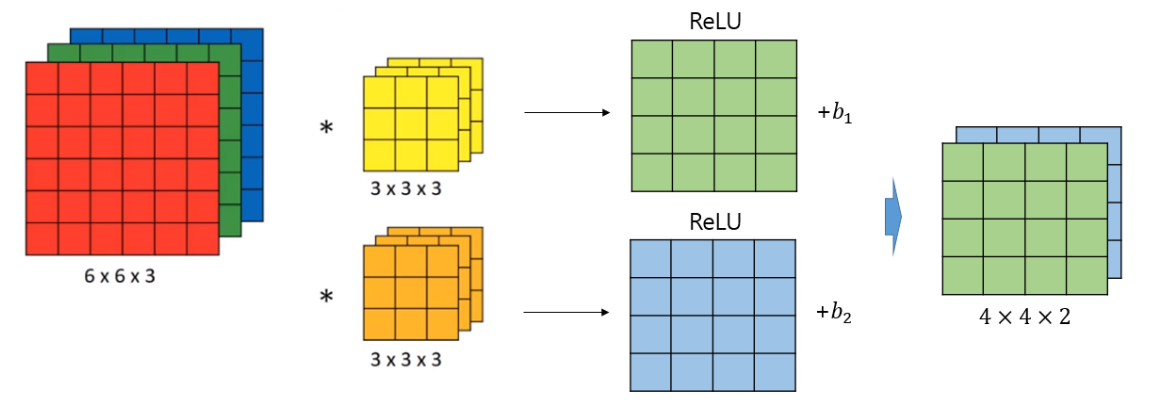
합성곱이란 위 이미지처럼 필터가 본 이미지 위를 이동하며 같은 위치에 있는 값을 곱한 값들을 다 더하는 연산을 실행하는 것이다.
- 용어
- padding : 기본적으로 합성곱은 이미지를 사이즈를 줄이게 된다. 이때 합성곱을 연속해서 사용하면 결국 이미지가 너무 작아지는 문제가 발생하고 이를 해결하기 위한 방법이 패딩이다. 패딩이란 본 이미지 가장자리에 추가 픽세들을 넣어주어 합성곱 결과로 이미지 사이즈가 작아지지 않게 하는 방법을 의미한다.
- same padding : input과 output의 이미지 사이즈가 동일하게 되도록 padding을 주는 설정
- valid padding : padding 적용하지않음(합성곱 결과 이미지 사이즈 줄게 됨)
- stride : 합성곱 필터가 움직이는 단위 거리를 의미한다. 기본적으로는 필터가 한칸씩 이동한다.
- padding : 기본적으로 합성곱은 이미지를 사이즈를 줄이게 된다. 이때 합성곱을 연속해서 사용하면 결국 이미지가 너무 작아지는 문제가 발생하고 이를 해결하기 위한 방법이 패딩이다. 패딩이란 본 이미지 가장자리에 추가 픽세들을 넣어주어 합성곱 결과로 이미지 사이즈가 작아지지 않게 하는 방법을 의미한다.
3.Max Pooling Layer
Pooling이란 기본적으로 이미지에서 대표값을 추출해 이미지 사이즈를 줄이는 layer라고 생각하면 쉽다. 이런 pooling layer로 가장 많이 쓰이는 것이 max pooling layer다. max pooling layer는 특정 구역마다 가장 큰 값을 찾아내어 downsampling하는 layer다. 이를 통해 feature map의 사이즈를 줄일 수 있다.
ex)
2x2크기에 stride 2일 경우
1,2,5,6 중 가장 큰 수 6
3,4,7,8 중 가장 큰 수 8
9,10,13,14 중 가장 큰 수 14
11,12,15,16 중 가장 큰 수 16
1 2 3 4 6 8
5 6 7 8 ==>
9 10 11 12 14 16
13 14 15 16pooling layer로 feature map 사이즈를 줄이는, 즉 이미지 사이즈를 줄이는 것이 의미하는 것은 무엇일까?
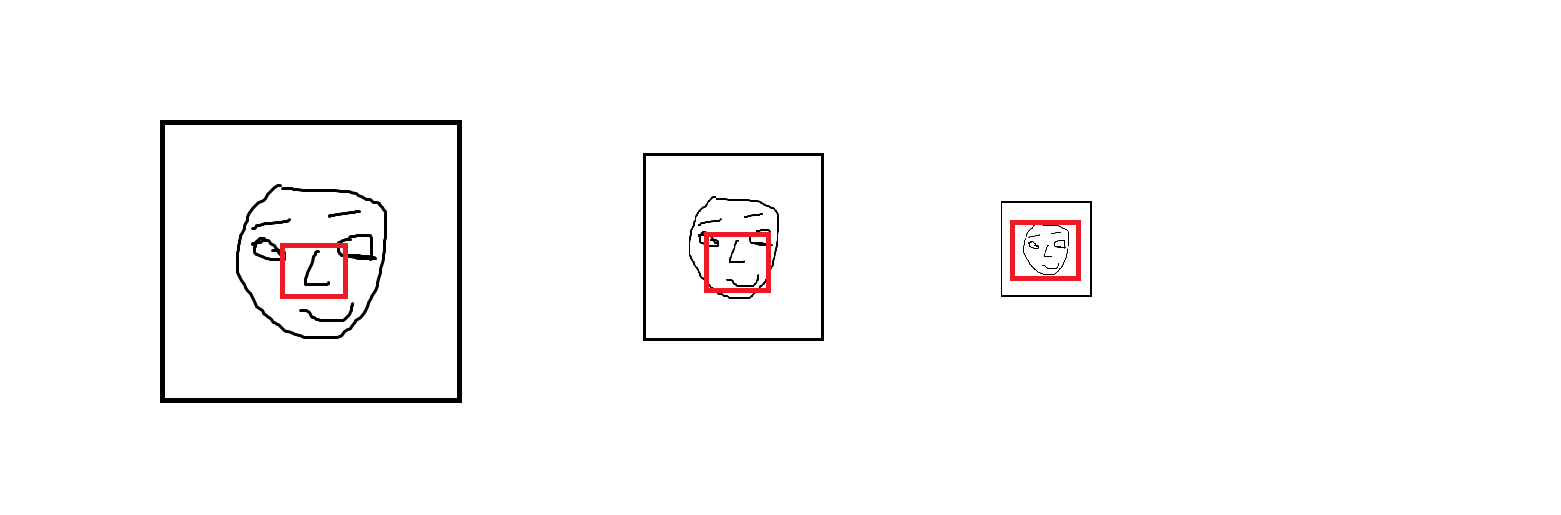
위 사진에서 빨간색 박스는 고정된 크기의 필터라고 가정한다. 위 그림과 같이 얼굴 이미지가 downsampling되어서 점점 줄게 되면 처음에는 필터로 코 한 부분만 볼 수 있었지만, 점점 얼굴 전체를 확인할 수 있게 되었다. 즉, 지역적인 특성에서 전체적인 특성을 알 수 있게 변형되는 것이다. 이것이 바로 max pooling layer의 역할이다.
4.텐서플로우 기본 흐름
간단한 CNN예제를 통해 텐서플로우 기본 흐름을 확인해본다.
1. 데이터 로딩
(train_image, train_label), (test_image, test_label) = keras.datasets.mnist.load_data()2. 전처리
X_train = train_image.astype("float32")/255.
X_test = test_image.astype("float32")/255.
X_train = X_train[..., np,newaxis] # (28, 28) --> (28, 28, 1)
X_test = X_test[..., np,newaxis]
y_train = keras.utils.to_categorical(train_label, num_classes=10)
y_test = keras.utils.to_categorical(test_label, num_classes=10)3. dataset 만들어주기
import tensorflow as tf
# train 데이터를 dataset 형식으로 만들고, train 데이터 개수만큼 섞기, 배치 개수 설정, 배치로 나눠지지 않은 나머지 데이터 처리 방식 설정 등을 해준다.
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train)).shuffle(X_train.shape[0]).batch(N_EPOCHS, drop_remainder=True)
test_dataset = tf.data.Dataset.from_tensor_slieces((X_test, y_test)).batch(N_BATCHS)4. 모델 구현
model = keras.Sequential()
# Input Layer
model.add(layers.InputLayer((28,28,1)))
# Feature Extractor(Backbone) : Conv + Pooling
# Conv로 특징 추출 -> Pooling으로 사이즈 줄이기 -> filter수로 channel 증가시키기
model.add(layers.Conv2D(filters=16, # 필터 개수
kernel_size=(3,3), # 필터 사이즈 (h, w)
padding="same", # 패딩 방식 설정(valid:패딩안함 / same:input, output사이즈변동없도록패딩추가)
stride=(1,1), # 필터 이동 간격 설정 (h, w)
activation="relu" # 활성함수 설정
))
model.add(layers.MaxPool2D(pool_size=(2,2), # Max값 추출할 영역 크기 설정 (h, w)
strides=(2,2), # 이동 간격 (h, w)
padding="same", # 패딩 방식 설정(valid:pool_size보다 작은 부분 버리기 / same:pool_size보다 작은 부분있으면 패딩 채워서 계산)
))
model.add(layers.Conv2D(filters=32, kernel_size=3,
padding="same",
activation="relu"
))
model.add(layers.MaxPool2D(padding="same"))
model.add(layers.Conv2D(filters=64, kernel_size=3, padding="same", activation="relu"))
model.add(layers.MaxPool2D(padding="same"))
# Estimator : Dense(Fully Connected Layer)
model.add(layers.Flatten())
model.add(layers.Dense(units=256, activation="relu"))
# Output Layer
model.add(layers.Dense(units=10, activation="softmax"))5. 컴파일하기
# optimizer 설정, 손실함수 설정, 평가지표 설정을 해준다.
model.compile(optimizer=keras.optimizers.Adam(learning_rate=LEARNING_RATE),
loss="categorical_crossentropy",
metrics=["accuracy"])- 손실함수
- 이진분류 : binary_crossentropy
- 다중분류 : categorical_crossentropy
- 평가지표
- 정확도 : accuracy
6. 학습하기
hist = model.fit(train_dataset, # 위에서 batch size는 따로 지정해 줘서 생략가능
epochs=100,
validation_data=test_dataset # dataset을 사용할때는 validation_split말고 validation_data 사용한다.
)8. 확인하기
plt.subplot(1,2,1)
plt.plot(hist.epoch, hist.history["loss"], label="Train loss")
plt.plot(hist.epoch, hist.history["val_loss"], label="Validation loss")
plt.legend()
plt.subplot(1,2,2)
plt.plot(hist.epoch, hist.history["accuracy"], label="Train Accuracy")
plt.plot(hist.epoch, hist.history["val_accuracy"], label="Validation Accuracy")
plt.legend()
plt.tight_layout()
plt.show()
9. 평가하기
loss, acc = model.evaluate(test_dataset)
print(loss, acc)