Cuda
-
병렬 컴퓨팅 플랫폼 및 API 모델로, GPU(Graphic Processing Unit)를 사용하여 복잡한 계산 작업을 병렬로 수행할 수 있도록 설계
CUDA는 그래픽 처리 장치에서 수행하는 알고리즘을 C 프로그래밍 언어를 비롯한 산업 표준 언어를 사용하여 작성할 수 있도록 하는 GPGPU 기술이다. CUDA는 엔비디아가 개발해오고 있으며 이 아키텍처를 사용하려면 엔비디아 GPU와 특별한 스트림 처리 드라이버가 필요하다.
-
cuDNN
cuDNN(CUDA® Deep Neural Network library) : cuDNN은 엔비디아 CUDA 딥 뉴럴 네트워크 라이브러리, 즉 딥 뉴럴 네트워크를 위한 GPU 가속화 라이브러리의 기초 요소로 컨볼루션(Convolution), 풀링(Pooling), 표준화(Nomarlization), 활성화(Activation)와 같은 일반적인 루틴을 빠르게 이행할 수 있도록 하는 라이브러리입니다.
!ls : 현재 디렉토리의 내용을 보여준다.
%cd dir: dir 디렉토리로 이동한다.
%pwd: 현재 위치한 디렉토리 위치를 보여준다.
!git: git 명령어를 실행시킨다.
!nvidia-smi: 현재 사용하고 있는 GPU의 스펙과 작동 상황을 보여준다.
!nvcc: Nvidia CUDA Compiler를 실행시킨다.-
프로그램이 "스레드"와 "블록"이라는 기본 단위로 구성되어 병렬 처리를 수행
-
스레드(Thread)
스레드는 병렬 작업을 수행하는 기본 실행 단위입니다. GPU에서 각 스레드는 독립적으로 실행되어 특정 작업을 수행합니다. 다수의 스레드가 병렬로 실행되므로, 대규모 데이터 처리 및 계산 작업을 빠르게 처리할 수 있습니다.
-
블록(Block)
블록은 여러 개의 스레드를 포함하는 그룹입니다. 블록 내의 모든 스레드는 동시에 실행되며, 블록의 스레드들은 서로 협력하여 작업을 수행할 수 있습니다. 각 블록은 1차원, 2차원 또는 3차원으로 구성될 수 있으며, 이로 인해 복잡한 데이터 구조를 쉽게 매핑할 수 있습니다.
%%writefile hello_cuda.cu
# include <stdio.h>
__global__ void helloCUDA(void)
{
printf("Hello thread %d in block %d\n", threadIdx.x, blockIdx.x);
}
int main()
{
helloCUDA<<<2, 3>>>();
cudaDeviceReset();
return 0;
}
!nvcc ./hello_cuda.cu -o hello_cuda
!./hello_cuda# 결과
Hello thread 0 in block 0
Hello thread 1 in block 0
Hello thread 2 in block 0
Hello thread 0 in block 1
Hello thread 1 in block 1
Hello thread 2 in block 1양자화
- 일정 범위의 수를 하나의 수로 간주주하여 bit수를 낮추는 기법
신경망의 가중치(weight)와 활성화 함수(activation function) 출력을 더 작은 비트 수로 표현하도록 변환하는 기술
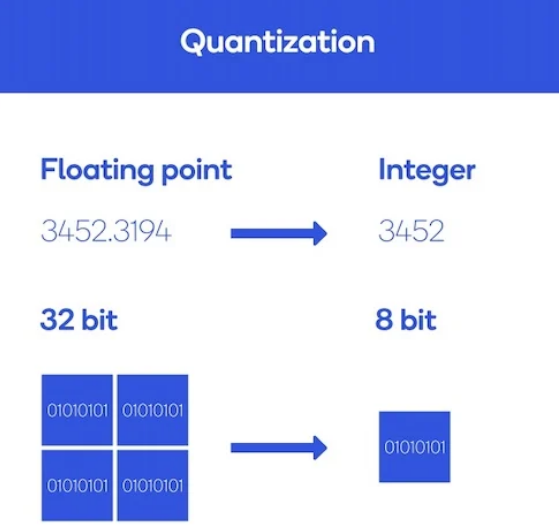
- 일반적으로 LLM은 32bit 실수로 표현되는 paramter들의 집합
- 8B 모델 -> 8B 32bit = 8B 4byte = 32GB 용량
- 이를 half-precision인 16bit로 저장하면 절반인 16GB
- 점점 bit수를 낮춰가면 성능이 떨어질 가능성은 높지만, 그에 비례해 용량과 메모리 필요량이 줄어들게 되고, 연산량도 낮아져서 token 생성 속도가 빨라짐(trade-off)
- 양자화를 하게 되면 성능은 떨어지지만(PPL값을 봄), 모델의 기본 성능이 좋거나 크기가 크면 양자화를 하더라도 성능이 크게 낮아지지 않는 것으로 알려져 있음
PPL
- 언어 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 의미
- 가령, 언어 모델에 어떤 테스트 데이터을 주고 측정했더니 PPL이 10이 나왔다면 해당 언어 모델은 테스트 데이터에 대해서 다음 단어를 예측하는 모든 시점(time step)마다 평균 10개의 단어를 가지고 어떤 것이 정답인지 고민하고 있음을 의미
llama.cpp
LLM 모델에 양자화를 통해 필요한 메모리의 양을 크게 감소시켜 고성능 GPU가 없는 환경에서도 동작하며 빠른 추론 결과를 얻을 수 있게 해주는 package
- Meta의 llama 모델은 처음에 huggingface 포맷으로 배포되었기 때문에 huggingface의 라이브러리가 필요
- llama.cpp는 이 llama 모델의 레이어를 pure C/C++로 구현하는 것을 목표하여 개발되었으나, 현재는 대부분의 LLM 지원하고 있음
- pure C/C++로 구현되었으므로 속도가 빠르고, GPU가 없어도 구동됨: 현재는 CUDA나 등 다양한 백엔드를 지원하여 가속 가능
- 더불어 여러가지 양자화 옵션을 사용핛 수 있으므로, 2bit나 3bit부터 8bit int까지 상황에 따라 다른 양자화 모델을 사용
- ggml로 시작하여 현재는 gguf라는 포맷을 사용
gguf
- 양자화 라이브러리
- GGUF 는 Georgi Gerganov(@ggerganov)란 개발자가 만든, 딥러닝 모델 저장 용도의 단일 파일 포맷
ollma
- LLM 모델을 Local 환경에서 손쉽게 수행하기 위한 프레임워크
- CUDA 뿐만 아니라, GPU가 없는 경우 CPU만으로 inference 가능
- ‘ollama pull’ 명령으로 ollama.com에서 제공하는 이미지들을 가져와서 사용가능
- Dockerfile과 유사한 modelfile을 사용하여 custom 이미지를 만들 수 있으며, 일단 만들어진 이미지는 언제든지 모델명을 지정해서 사용할 수 있음
- ‘ollama run’으로 직접 LLM에 프롬프트를 줄 수도 있고, 전용 포트(11434)에 REST API call을 전달 가능
- OpenAI와 호환되는 API(11434/v1)에 openai call을 던질 수 있음
- 구동용 이미지는 gguf를 사용하는 것이 일반적
