WIL - Weekly I Learned
-
양자화(Quantization)
- 양자화를 사용하는 경우
- 양자화 사용 시 발생할 수 있는 문제점
- 양자화의 종류
찾아보게 된 계기
딥다이브 시작 직전까지, 졸업필수 과목인 안드로이드 앱 개발 강의를 수강하고 있었다. 딥러닝과 머신러닝에 대해 열심히 공부하고 있었어서 이를 활용하고 싶은 마음이 컸었다.
그래서 해당 강의의 해커톤이 진행될 때, 어플리케이션에 딥러닝 모델을 넣겠다는 일념 하에 진행했다가 모델의 정확도가 tflite파일로 전환된 뒤 매우 떨어지는 것을 확인했다.
다른 분들께 자문을 구했더니 ios보다 Android가 모델을 임베드 시켰을 때, 손실이 일어나서 정확도가 떨어진다는 피드백을 받았다. 일단 무엇보다 양자화를 뭣도 모르고 시켰으나, 대부분 QAT를 사용하는데 QAT를 시키지 않아서 정확도가 심하게 떨어졌을 수도 있다는 피드백을 받았다. 물론 팀원분께 전달받은 피드백 사항이라 내가 오해했을 수도 있다.
💡 도대체 양자화(Quantization)은 무엇이고, 양자화 Aware Training(QAT)는 또 뭐가 다른 거지?
어플리케이션 제작 프로젝트가 다 끝났고, 계속 마음 한 켠 찜찜했던 이 마음을 달래보고자 양자화에 대해서 공부해볼 계획이다.
때마침 딥다이브에서 WIL 컨텐츠를 써야하기도 했고, 벨로그도 이번 기회에 처음 써보는 것이라, 겸사겸사 벨로그를 꾸리며 차근차근 양자화에 대해서 정리하고 양자화 종류에 대해서 하나씩 공부할 것이다.
양자화에 대해 공부한 후에, 어플리케이션에 또 딥러닝 모델을 임베디드 할 일이 생겼을 때 정확도의 손실을 덜 일으키고 성공적으로 마무리할 수 있으면 좋겠다.
양자화(Quantization)란?
양자화란, 모델의 실행 성능과 효율성을 향상을 위해 신경망의 가중치(weight)와 활성화 함수(activation function) 출력을 더 작은 비트 수로 표현하도록 변환하는 기술을 말한다.
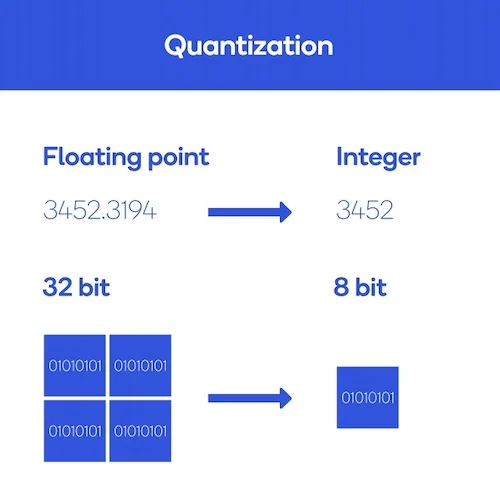
이는 신경망의 모델 크기를 줄이고, 계산 속도를 높이며, 메모리 사용량을 감소시켜 효율적인 모델 배포와 실행을 가능하게 해주는 중요한 방법이다.
양자화의 주요 목표는 모델을 손상시키지 않으면서 모델의 크기를 줄이고 계산 비용을 낮추는 것이다.
여기서 양자화는 가중치, 활성화 함수의 파라미터 값을 정수나 적은 비트 수로 표현하거나, 연산 중에 정밀도를 감소시켜 계산 복잡성을 낮추는 방식으로 이루어진다. 보통 tensorflow나 pytorch의 파라미터는 보통 32비트 부동 소숫점 연산으로, fp32(FLOAT32)의 형태로 저장된다. 이 모델의 파라미터를 lower bit로 표현하여, 8비트 정수(int8)로 저장하는 것이다.
정밀도가 더 낮은 비트 수로 표현해서 얻는 이점은 (pytorch 정리 참고)
- 모델 크기 4배 감소
- 메모리 대역폭 2-4배 감소
- 32비트에서 8비트로 이동해서, 메모리가 4배 감소
- 메모리 대역폭 절약 및 int8 산술을 통한 더 빠른 계산으로 인해 2-4배 더 빠른 추론이 가능 (정확한 속도 향상은 하드웨어, 런타임 및 모델에 따라 다름).
이정도로 추릴 수 있다.
앞에서 설명한대로 이점도 있지만, 이 양자화가 결국 일으키는 문제가 있다.
 int8에 매핑된 작은 범위의 float32 값은 int8에 255개의 정보 채널만 있기 때문에 손실 변환
int8에 매핑된 작은 범위의 float32 값은 int8에 255개의 정보 채널만 있기 때문에 손실 변환
여기 삽입된 이미지를 보면 알겠지만, 양자화는 작은 범위의 부동 소수점 값을 고정된 수의 정보 버킷으로 압축한다.
이 압축되는 과정에서, 채널의 수가 줄어드는 만큼 정보가 손실된다. 모델의 매개 변수나 가중치는 이제 작은 값 집합만 취할 수 있으며 이들 사이의 미세한 차이가 손실되는 거다.
예를 들어, 2에서 2.3 사이의 숫자들을 생각해보자. 범위로는 [2.0, 2.3] 정도 될 것이다. 이제 이 숫자들을 작은 정보 버킷으로 표현하려한다고 할 때, 2.0부터 저 모든 숫자들을 같은 버킷에 넣어서 표현할 수 있다.
그렇게 된다면, 숫자 2.1, 2.15, 2.25도 모두 같은 버킷으로 표현된다. 이렇게 하면 작은 차이가 무시되고, 원래 숫자들 사이의 미묘한 차이가 사라진다. 마치 분수 값을 정수로 표시할 때 반올림의 오류와 비슷하게 말이다.
또한 손실의 다른 원인도 있다. 이러한 손실 수가 여러 번의 곱셈 계산에 사용되면 이러한 손실이 누적된다. 또한 int32 정수로 누적되는 int8 값은 다음 계산을 위해 int8 값으로 재조정되어야 하므로 더 많은 계산 오류가 발생한다.
결국, 기본적으로 양자화는 근사치를 도입하는 것을 의미해서, 정확도가 기존 모델에 비해 약간 떨어지게 될 수밖에 없다. 그래서, 전체 부동 소수점 정확도와 양자화된 정확도 사이의 차이를 최소화하기 위해 여러 양자화 종류로 시도를 진행한다.
양자화를 사용하는 경우
양자화를 굳이 시키는 이유는 다음과 같다.
- 모바일 기기나 에지 디바이스와 같이 계산 자원이 제한적인 환경에서 사용
- 실시간 추론이 필요한 시스템에서 빠른 모델 실행 속도를 요구할 때 사용
- 대규모 모델을 배포하거나 저장할 때 메모리 사용량을 줄이는데 도움
양자화의 종류
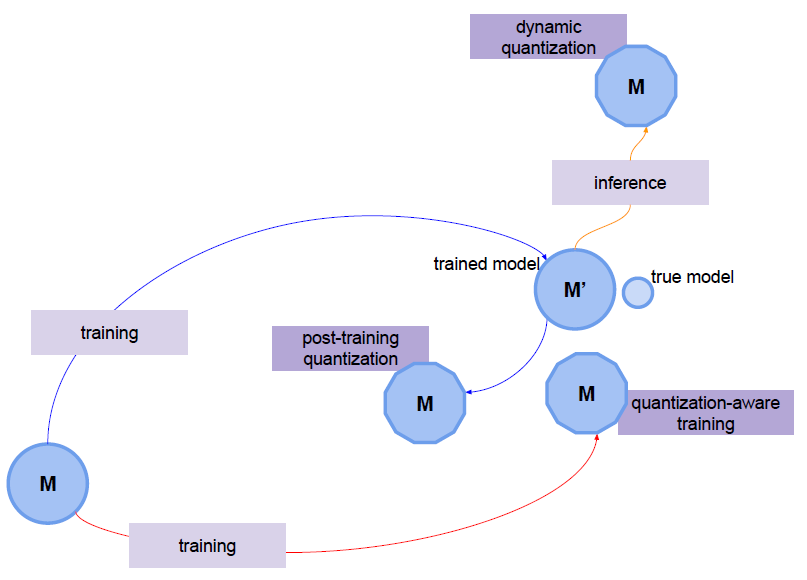
- Dynamic Quantization(동적 양자화)
- 가중치는 미리 양자화 되지만, 활성화는 inference 동안 동적으로 양자화가 됨
- Static Quantization(정적 양자화)
- Post Training Quantization 또는 PTQ라고 불림
- 학습된 모델을 quantization 하는 Post Training Quantization
- Traning한 후에 양자화를 적용하는 기법
- 파라미터 size 큰 모델에서 정확도 하락 폭이 작음
→ 파라미터 size 작은 소형 모델에서는 적합하지 않음
- Post Training Quantization 또는 PTQ라고 불림
- Quantization aware training(양자화 인식 교육)
- training 시점에서 양자화가 됐을 때 loss가 어떻게 될 지 시뮬레이션을 같이 돌린다
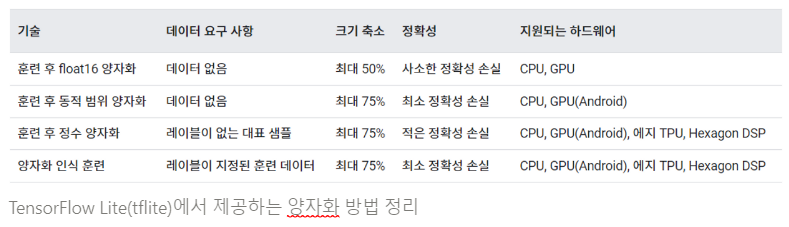
▽ 딥러닝 모델의 양자화 기법들의 주요 특징을 간단히 정리한 표
| 양자화 기법 | 설명 |
|---|---|
| Dynamic Quantization (DQ) | - 미리 학습된 모델의 가중치와 활성화 함수의 비트 수를 줄이는 기법 - 런타임 시 양자화되며, 가중치와 활성화 함수의 분포에 따라 크기가 다양하게 조절 - 인퍼런스 중 성능 저하가 덜 발생하며, 변환 비용이 낮음 |
| Static Quantization (PTQ) | - 훈련 후, 가중치와 활성화 함수의 비트 수를 줄이는 기법 - 가중치와 활성화 함수의 분포를 분석하여 고정된 양자화 스케일과 오프셋을 결정하고 모델을 양자화 - 인퍼런스 시 성능 저하가 발생할 수 있음 |
| Quantization Aware Training (QAT) | - 훈련 중에 양자화를 고려하여 모델을 조정하는 기법 - 가중치 양자화에 대한 학습을 포함하여 원본 모델을 보다 양자화에 robust하게 만듦 - 일반적으로 인퍼런스 시 성능 저하가 적음 |
하지만, 양자화 기법을 선택할 때는 모델의 성능과 메모리/연산 요구 사항 등을 고려하여 적절한 기법을 선택하는 것이 중요하다.
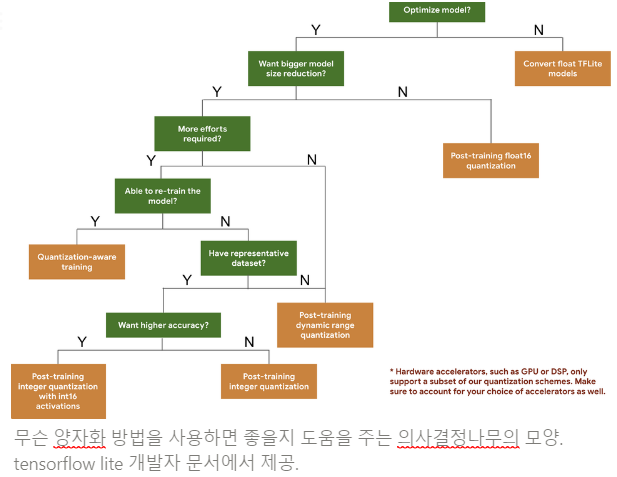
양자화는 모델의 성능과 효율성 사이의 균형을 맞추는 과정이며, 적절한 양자화 방법과 비트 수 선택이 중요하다. 양자화는 최적의 설정을 찾는 과정이므로 실험과 조정을 통해 모델의 성능을 유지하면서 효율성을 높이는 것이 필요하다.
참고 자료
다음 WIL은 양자화의 종류들을 차례대로 정리해야겠다.


좋은 글 감사합니다. 자주 방문할게요 :)