[신경망 해석의 한계]
현재 우리는 언어 모델 내의 신경 활동을 이해하지 못합니다.
자동차 엔지니어는 구성 요소의 사양을 기반으로 자동차를 직접 설계, 평가 및 수리하여 안전과 성능을 보장할 수 있으나, 신경망은 직접 설계되지 않습니다.
AI 엔지니어는 인공신경망을 훈련시키는 알고리즘을 설계합니다. 예전 포스팅에서도 말씀드렸듯이 이것은 블랙박스로 표현됩니다. 논문에 따르면, 자동차 안전과 같은 것에 대해 추론하는 것과 같은 방식으로 AI 안전에 대해 추론할 수 없다는 것을 의미합니다. 즉 우리가 설계한 인공신경망이 어떤 대답을 내놓을지는 현재로서는 미지수입니다.
뱅크웨어글로벌에서 다루는, 금융을 포함한 여러 도메인에서 아직 LLM의 상용화가 본격적으로 이루어지지 않는 것도 이러한 이유라고 생각합니다.(개인적으로)
[과제]
따라서 수많은 파라미터 중 신경 계산에 유용한 구성 요소를 찾아야 합니다. 다만 LLM 내부의 신경 활성화는 예측할 수 없는 패턴으로 활성화되기 때문에, 각 입력에서 활성화되는 기능을 식별해야 합니다.
openai에서 식별한 기능으로는
- 인간 불완전성
- 가격 인상
- 훈련 로그
등이 있으며, 여기에는 sparse autoencoder를 활용한 방법론을 언급합니다.
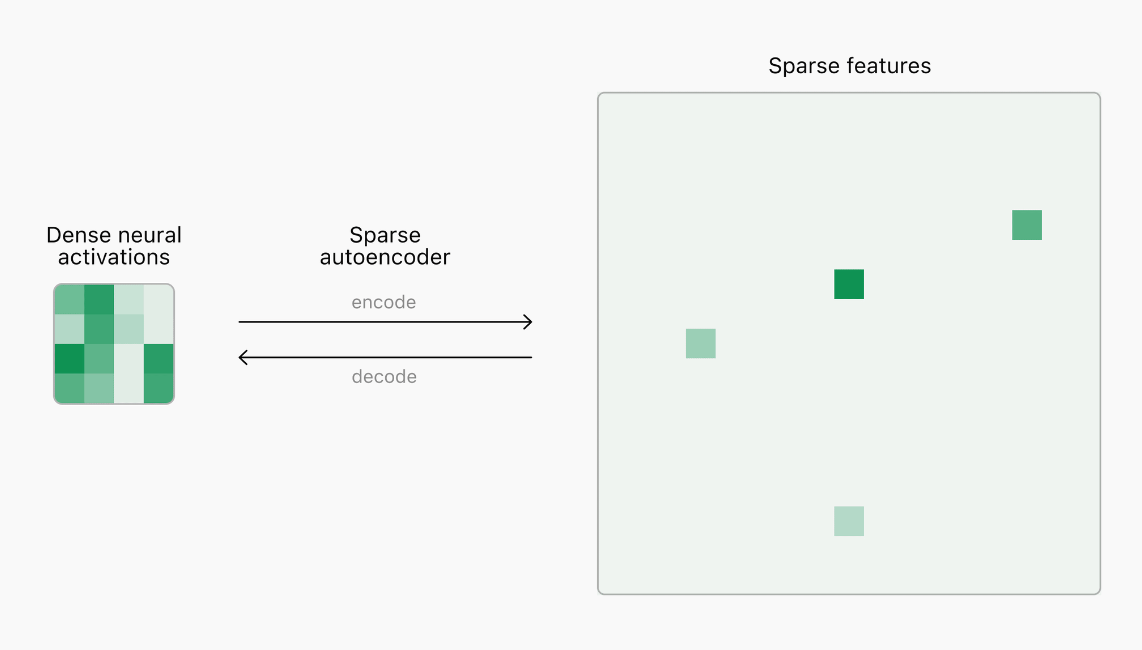
[Sparse Autoencoder]
Sparse AutoEncoder 를 통해 sparse(0이 많은) 한 노드들을 만들고, 그 중에서 0과 가까운 값들은 전부 0으로 보내버리고 0 이 아닌값들만 사용하여 네트워크 학습을 진행한다.
오토인코더는 기본적으로 representation learning 작업에 신경망을 활용하도록 하는 비지도 학습 방법입니다. 데이터를 Encoder-Decoder에 넣어 중간의 감소된 차원의 데이터 latent vector 특징을 추출합니다. Sparse autoencoder는 오히려 hidden layer 속의 노드 수가 더 많은 유형입니다.
[결론]
오토인코더 학습을 통해 여러 기능으로 확장할 수 있는 openai의 방법론에 대해서는 논문의 내용이 너무 어렵기 때문에(...) 당장은 이해가 되지 않지만, 블랙박스를 이해하는데 조금씩 다가가고 있는 느낌입니다.
[URL]
포럼 https://openai.com/index/extracting-concepts-from-gpt-4/
Sparse autoencoder https://velog.io/@jochedda/%EB%94%A5%EB%9F%AC%EB%8B%9D-Autoencoder-%EA%B0%9C%EB%85%90-%EB%B0%8F-%EC%A2%85%EB%A5%98
논문 https://arxiv.org/abs/2406.04093
