서포트 벡터 머신을 사용한 최대 마진 분류
SVM (Support Vector Machine) : 결정경계와 샘플들 간의 거리(margin)를 최대로
서포트 벡터 (Support Vector): 마진의 폭을 결정하게 하는 샘플로 결정경계와 가장 가까운 샘플
마진 (Margin): 결정경계와 서포트 벡터 사이의 거리
- 결정경계보다 크면 양성 샘플, 작으면 음성 샘플
하드 마진 (Hard Margin): 매우 엄격하게 두 개의 클래스를 분리하는 분리초평면을 구하는 방법, 모든 튜플은 이 초평면을 사이에 두고 무조건 한 클래스에 속해야 한다.
소프트 마진 (Soft Margin): 하드마진 방법을 기반으로 하지만 서포트 벡터가 위치한 경계선에서 약간의 여 변수를 두는 것
- 이 책에서는 Linear SVM 모델만 다룸
Linear 모델 설정 코드
svm = SVM(kernek = 'linear', C=1.0, random_state=1)결정 트리 학습
목표: 리프 노드를 순수노드로 만드는 것 (=즉 복잡성(entropy)이 낮도록 만드는 것)
용어: 루트 노드, 리프 노드, 부모 노드, 자식 노드, 질문 노드, 브랜치
마지막 노드에 한 종류의 클래스만 있으면 '순수 노드' 라고 부름.
부모 노드의 정보이득과 자식 노드의 정보이득이 최대화 되도록 찾는 것이 결정트리
정보이득이란?
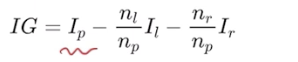
- 부모노드의 불순도보다 자식노드의 불순도가 작아야함
불순도란?
복잡성을 의미하며 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지를 뜻함. 다양한 개체가 섞여 있을수록 불순도가 높아짐
불순도의 종류: 지니 지수(Gini), 엔트로피 지수(Entropy)
불순도 지정 코드
tree_model = DecisionTreeClassfier(criterion='gini', max_depth=4, random_state=1)max_depth 지정 숫자 만큼 루트노드를 제외하고 아래 n단계까지 성장할 수 있음
때문에 결정트리 함수는 max_depth를 지정하지 않으면 계속해서 늘어날 수 있기 때문에 주의해야함ㄱ
사이킷런에 tree 시각화하는 함수
tree.plot_tree(tree_model)과대적합(Over-fitting)이란?
훈련 데이터에 대해서는 높은 성능을 보여주지만 테스트 데이터에 대해서는 높은 성능을 보여줄 확률이 낮음 (교수님이 말씀하신 우리 모델 예상 문제가 이거였네,,,,,,,,,,,,,,,,,,,,,,,,,,) 복잡도가 필요 이상으로 높기 때문에 발생하는 문제
과대적합 해결 방법
1. 훈련 데이터를 더 많이 모으기
2. 정규화
3. 훈련 데이터 노이즈 줄이기
과소적합(Under-fitting)이란?
과대적합의 반대로 모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 발생
과소적합 해결 방법
1. 파라미터가 더 많은 복잡한 모델 선택
2. 모델의 제약(규제 하이퍼 파라미터 값) 줄이기
3. 조기종료 시점(과대적합 되기 전의 시점) 까지 충분히 학습

응원할게요! 다음 글 기대합니다 🐆🐆