차원 축소를 사용한 데이터 압축
차원 축소를 하는 이유는?
많은 Feature를 사용하는 것 보다 설명력이 높은 Feature를 사용하는 것이 중요. 설명력 높은 모델을 생성하기 위함
주성분 분석을 통한 비지도 차원 축소
주성분 분석(Principal Component Analysis, PCA)이란?
가장 널리 사용되는 차원 축소 기법 중 하나로, 원 데이터의 분포를 최대한 보존하면서 고차원 공간의 데이터들을 저차원 공간으로 변환한다.
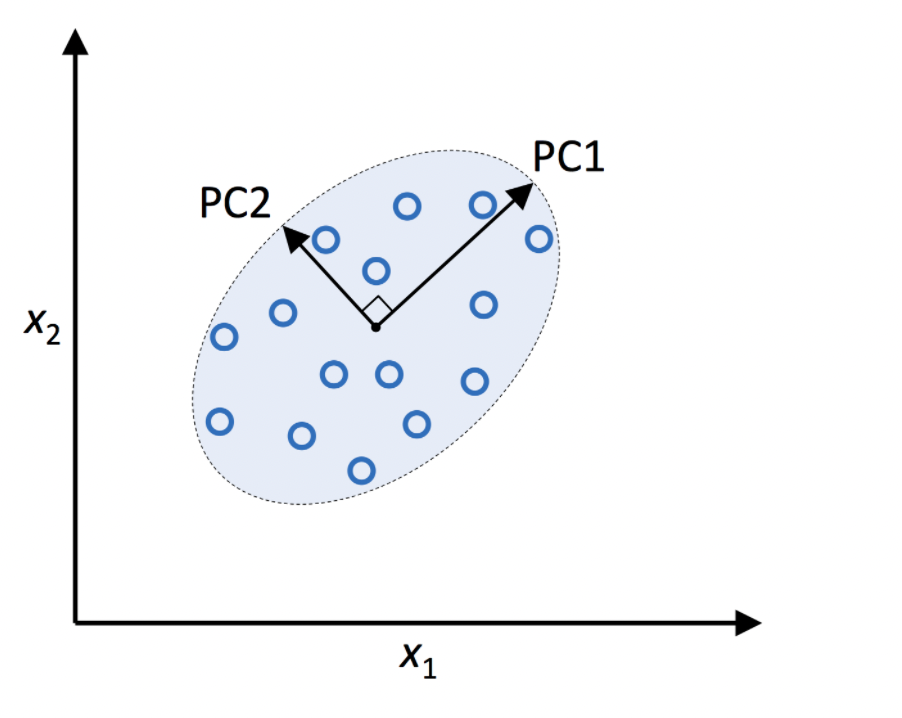
첫번째 축은 원 데이터의 분포가 가장 큰 방향으로 정한다. 그리고 이 때 정사영된 데이터들이 PC1을 이루게 된다. 그리고 두번째 축은 첫번째 축과 섞이지 않도록 첫번째 축과 수직인 방향 중 그 다음으로 분산이 큰 방향으로 설정한다. (주성분들 사이에는 서로 관계가 없도록 하기 위하여). 그래서 PC1이 원 데이터의 분포를 가장 많이 보존하고, PC2가 그 다음으로 원 데이터의 분포를 많이 보존하게 된다.
xW = z
여기서 x는 원본 데이터, W는 주성분, z는 변환된 데이터를 표현함.
주성분을 원본 차원 갯수 만큼 사용하지 않기 때문에 차원 축소가 가능해짐.
고윳값이란?
설명된 분산의 비율이다. (=즉 주성분의 순서를 나타냄)
사이킷런의 주성분 분석
from sklearn.decomposition import PCA
pca = PCA()
X_train_pca = pca.fit_transform(X_train_std)
pca.explained_variance_ratio_
plt.bar(range(1, 14), pca.explained_variance_ratio_, alpha=0.5, align='center')
plt.step(range(1, 14), np.cumsum(pca.explained_variance_ratio_), where='mid')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal components')
plt.show()
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train_std)
X_test_pca = pca.transform(X_test_std)
plt.scatter(X_train_pca[:, 0], X_train_pca[:, 1])
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.show()선형 판별 분석을 통한 지도 방식의 데이터 압축
주성분 분석 vs 선형 판별 분석
선형 판별 분석은 class label을 사용하는 지도학습 같은 방식을 사용함
[선형 판별 분석의 내부 동작 방식]
1. 표준화 전처리
2. 각 클래스별 평균 벡터
3. 클래스 간 산포 행렬 S_B, 클래스 내 산포 행렬 S_W
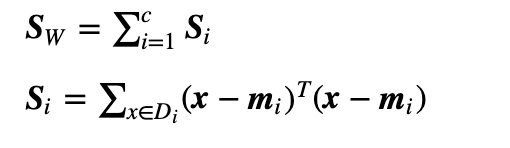
4. S^−1_W*S_B 행렬의 고윳값
5. 고윳값을 내림차순 정렬
6. 고윳값이 가장 큰 k개의 고유 벡터 선택
7. 고유 벡터로 만든 변환 행렬로 데이터셋 투영
커널 PCA를 사용하여 비선형 매핑
커널(Kernel) 기법이란?
비선형 함수인 커널 함수를 ㅣ용하여 비선형 데이터를 고차원 공간으로 맵핑하는 기술
from scipy.spatial.distance import pdist, squareform
from scipy.linalg import eigh
import numpy as np
from distutils.version import LooseVersion as Version
from scipy import __version__ as scipy_version
# scipy 2.0.0에서 삭제될 예정이므로 대신 numpy.exp를 사용합니다.
if scipy_version >= Version('1.4.1'):
from numpy import exp
else:
from scipy import exp
def rbf_kernel_pca(X, gamma, n_components):
"""
RBF 커널 PCA 구현
매개변수
------------
X: {넘파이 ndarray}, shape = [n_samples, n_features]
gamma: float
RBF 커널 튜닝 매개변수
n_components: int
반환할 주성분 개수
반환값
------------
X_pc: {넘파이 ndarray}, shape = [n_samples, k_features]
투영된 데이터셋
"""
# MxN 차원의 데이터셋에서 샘플 간의 유클리디안 거리의 제곱을 계산합니다.
sq_dists = pdist(X, 'sqeuclidean')
# 샘플 간의 거리를 정방 대칭 행렬로 변환합니다.
mat_sq_dists = squareform(sq_dists)
# 커널 행렬을 계산합니다.
K = exp(-gamma * mat_sq_dists)
# 커널 행렬을 중앙에 맞춥니다.
N = K.shape[0]
one_n = np.ones((N, N)) / N
K = K - one_n.dot(K) - K.dot(one_n) + one_n.dot(K).dot(one_n)
# 중앙에 맞춰진 커널 행렬의 고윳값과 고유벡터를 구합니다.
# scipy.linalg.eigh 함수는 오름차순으로 반환합니다.
eigvals, eigvecs = eigh(K)
eigvals, eigvecs = eigvals[::-1], eigvecs[:, ::-1]
# 최상위 k 개의 고유벡터를 선택합니다(결과값은 투영된 샘플입니다).
X_pc = np.column_stack([eigvecs[:, i]
for i in range(n_components)])
return X_pc