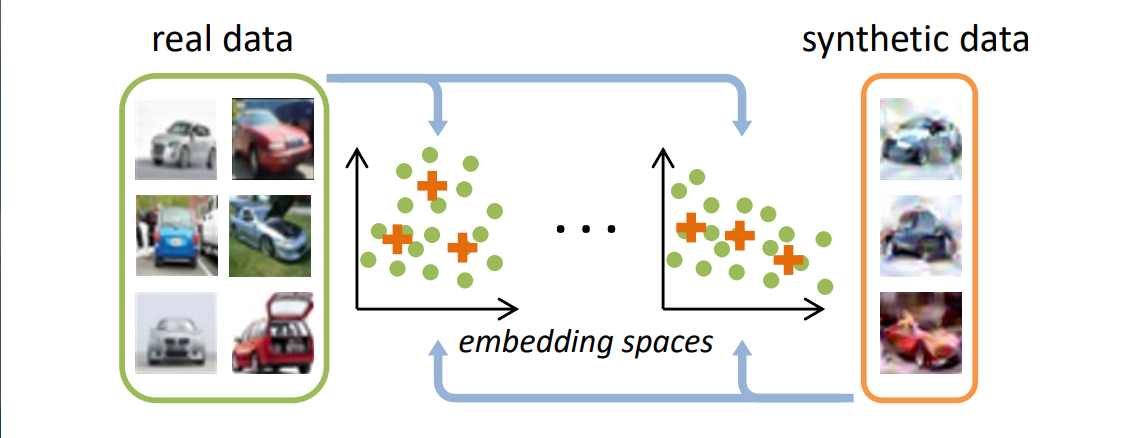
이번에 리뷰해 볼 논문은 Dataset Condensation with Distribution Matching 이라는 논문입니다. 해당 논문은 Dataset Condensation을 처음 제안했던 저자들에 의해서 쓰여진 논문이므로, 계속해서 Dataset Condensation의 후속 연구가 진행되면서 나온 논문이라는 생각이 드네요. 이 논문에서는 기존의 DC가 가진 복잡한 bi-level optimization 문제와 second-order derivative computation 문제를 gradient matching 방법이 아닌 다른 방법으로의 접근을 통해 해결합니다.
Introduction
하나의 최신 딥러닝 모델을 훈련하기 위한 computational cost가 3.4개월마다 2배로 증가하고 있다고 합니다. 이는 매년 2배씩 하드웨어 퍼포먼스가 증가하는 무어의 법칙보다 빠른 성장세로, 날이 갈수록 모델을 훈련하기 위한 비용이 크게 늘어날 것임을 보여줍니다. 더군다나 NAS와 같이 동일한 데이터셋에 대해서 많은 candidate 모델을 평가해야 하는 경우 계산비용은 기하급수적으로 증가하게 됩니다. 따라서 데이터셋의 크기를 줄이는 방법이 절실히 필요합니다.
데이터셋의 크기를 줄이는 전통적인 방법으로는 Coreset Selection이 있습니다. Coreset Selection은 훈련셋 중 중요하게 여겨지는 데이터를 선택하여 훈련셋의 크기를 줄이는 방법입니다. 하지만 Coreset Selection에는 두 가지 큰 문제가 있습니다. 첫 째는, 대부분의 Coreset Selection 방법이 점진적으로, greedy 하게 샘플들을 선택함으로 인해 근시야적(short-sighted)이라는 것입니다. 둘 째는, 줄어든 데이터셋의 효율이 선택된 샘플들에 의해서 성능의 상한(Upper bound)이 정해진다는 것입니다.
데이터셋을 합성하여 작은 데이터셋을 만드는 Synthesizing 방법은 Coreset Selection의 문제점들을 해결해 줍니다. Dataset Condensation은 합성 데이터셋이 원본 데이터셋과 유사한 성능을 가지면서 데이터셋의 크기를 줄일 수 있도록 해줍니다. 하지만 네트워크 파라미터의 최적화를 하는 동시에 합성 데이터셋도 최적화 해야 하므로 계산비용이 많이 발생하는 bi-level optimazation과 second-order derivative 계산이 발생합니다. 예를 들어 CIFAR10 에 대해서 500장의 합성 데이터셋을 만들어 내기 위해서는 GPU한개로 15시간 정도가 소모되는데, 이는 CIFAR10 데이터셋에 대해서 6개의 심층신경망을 훈련하는 시간과 유사합니다.
따라서, 해당 논문에서는 Coreset Selection의 간단한 계산과 Datacet Condensation의 원본 데이터 샘플에 의해 상한선이 정해지지 않는 장점을 결합한 새로운 방법을 제시합니다. 논문에서 제시하는 방법을 사용하면 500장의 CIFAR10 데이터셋을 합성하는데 기존 DC에 비해 45배나 빠른 속도를 보여준다고 합니다. 또한 느린 합성 속도 때문에 toy-set(ex. MNIST, CIFAR10)에서만 가능했던 DC를 TinyImageNet이나 ImageNet-1K에도 적용할 수 있었다고 합니다.
Methodology

해당 논문에서는 합성 데이터셋이 원본 데이터셋의 distribution 즉 분포를 따라 가는것을 목표로 제시합니다. 일반적으로 데이터셋은 높은 차원을 가지고 있습니다. 그러므로 원본 데이터셋의 높은 차원의 분포 를 그대로 따라가려고 하면 비효율적이며 정확한 분포를 따라갈 수도 없습니다. 따라서 원본 데이터셋을 저차원으로 임베딩하여 저차원상에서 원본 데이터셋의 분포를 합성 데이터셋 분포가 따라 가도록 합니다. 임베딩에는 embedding 함수 를 사용합니다. 여기서 는 네트워크 파라미터 입니다.
저차원 임베딩으로 인해서 원본 데이터셋과 합성 데이터셋의 분포 차이를 일반적으로 사용하는 MMD(Maximum Mean Discrepancy) 방법으로 구할 수 있게 되었습니다. 하지만 데이터 분포의 groud-truth를 알 수 없기에, 경험적으로 근사시킨 MMD 방법을 사용합니다.
근사시킨 MMD 방법에 데이터 증강 기법인 Differentiable Siame Augmentation 방법을 적용하여 전개한 식은 다음과 같이 됩니다. 여기서 는 이미지 회전 각과 같은 augmentation parameter 입니다.
위의 식을 보면 데이터 증강 기법을 적용한 데이터셋을 로 임베딩하여 전체 셋에 걸쳐서 원본 데이터 분포와 합성 데이터 분포의 차이를 줄이는 방향으로 합성 데이터셋 를 업데이트 하는 것으로 확인할 수 있습니다.
중요한점은 위에서 제시한 식은 만 최적화 하면 되므로 이전 DC의 값비싼 bi-level optimization 과정이 필요 없다는 것입니다.

위의 알고리즘 그림에는 전체 합성 과정이 나와있습니다. 원본 데이터셋과 합성 데이터셋은 각 배치별로 합성합니다. 네트워크 파라미터는 네트워크 파라미터의 분포에 따라 매 iteration 마다 다른 파라미터로 업데이트하여 합성을 진행합니다.
Randomly Initialized Networks : 위의 식과 알고리즘에서 나온 임베딩을 위한 함수 는 여러가지 방법이 있을 수 있습니다. 해당 논문에서는 임베딩 함수 로 랜덤하게 초기화된 심층 신경망을 사용합니다. 여기서 랜덤하게 초기화된 심층신경망보다 데이터셋에 대해서 pre-trained 된 네트워크를 쓰는게 더 성능이 좋지 않을까 라는 의문이 드는데, 해당 논문에서는 랜덤하게 초기화된 네트워크를 쓰는 것이 pre-trained 된 네트워크를 사용하는것 보다 성능이 더 잘 나왔다고 합니다.
랜덤하게 초기화된 네트워크를 사용하면 여러 computer vision task에 강한 representations를 얻을 수 있다고 합니다. 또한 랜덤하게 초기화된 네트워크는 데이터를 임베딩 할 시에 같은 클래스 간의 거리는 가깝게, 다른 클래스 간의 거리는 멀게끔 데이터 간의 거리를 더 잘 보존해준다고 합니다.
Experiments
논문에서는 기본적으로 합성 데이터셋으로 훈련된 네트워크의 원본 데이터셋의 테스트셋에 대한 classification 성능을 평가 기준으로 삼았습니다. 데이터셋으로는 MNIST, CIFAR10, CIFAR100, TinyImageNet, ImageNet-1K를 사용했습니다. TinyImageNet 과 ImageNet-1K는 64X64 로 resizing하여 실험을 진행했습니다. 데이터셋 합성에 사용된 심층 신경망은 기본적으로 ConvNet을 사용했습니다.

먼저 최신 Coreset Selection 및 Training set Synthesis 기술과의 classification 성능 비교표 입니다. 기존의 DSA에 비해 DM은 적은 폭으로 성능이 떨어집니다. 절대적인 성능은 떨어졌지만, DM은 복잡한 bi-level optimization 과정이 없기 때문에 빠른 합성 속도를 보여줍니다. 따라서 빠른 합성속도를 가지며 기존의 DC와 비슷한 성능을 가진다는 것은 개인적으로는 의미가 있다고 생각합니다. 빠른 합성 속도 덕분에 32X32 해상도의 이미지 셋만을 합성했던 DC와 달리 DM에서는 64X64 이미지의 TinyImageNet에서의 결과도 확인할 수 있습니다.
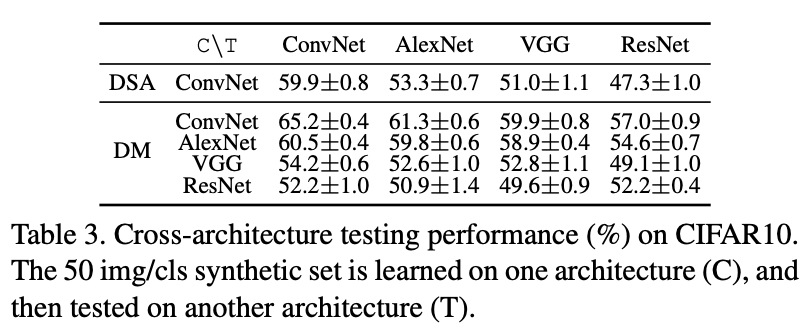
다음으로는 네트워크 일반화 성능 비교입니다. C로 나와있는 네트워크는 데이터셋을 합성하는데 사용된 네트워크이고, T로 나와있는 네트워크는 테스트 하는데 사용된 네트워크입니다. DSA 방법과 비교해 봤을 때, 네트워크 일반화 성능은 확실한 성능 향상이 있었음을 확인할 수 있습니다. 제 개인적인 추측으로는 네트워크의 파라미터를 사전학습시켜 사용하지 않고 랜덤하게 초기화해서 사용함으로 인해서 일반화 성능이 좋아지지 않았나 하는 생각이 들었습니다.

DM을 사용해서 MNIST와 CIFAR10 이미지를 합성한 결과입니다. 각 클래스당 10개의 이미지를 합성했습니다. CIFAR10 에서 체스판처럼 나타나는 무늬의 형태가 있음을 확인할 수 있습니다.

위 그림은 데이터의 분포를 시각화한 것입니다. 작은 점은 원본 데이터이고, 별모양은 합성 데이터입니다. 색깔별로 각 클래스를 나타내며, 그림에는 총 3개의 클래스에 대한 데이터 분포가 시각화 되어 있습니다. DC와 DSA에 비해 DM이 합성 데이터의 분포가 고르게 되어 있는 것을 확인할 수 있습니다. 전체 데이터셋에 대해서 훈련된 네트워크를 사용해 특징(분포)을 추출했고, t-SNE 방법을 사용해서 추출된 특징들을 시각화 했습니다.
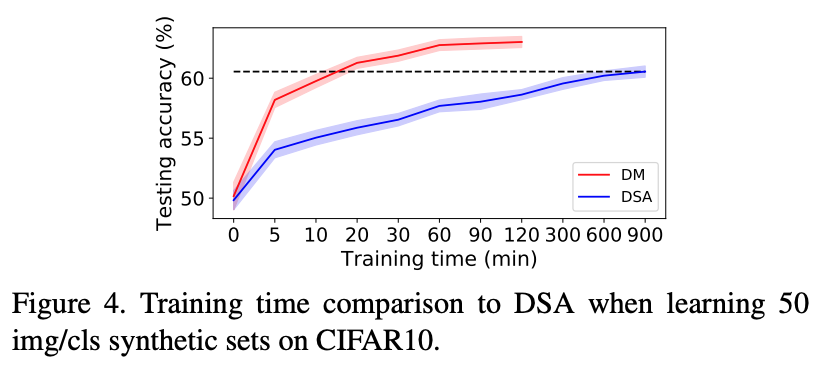
DSA와 DM의 훈련시간 비교 표 입니다. 하나의 GTX1080 GPU를 사용해서 작업한 결과이며, 점선으로 되어있는 부분을 보면, DM이 20분 정도 걸려서 도달한 성능을 DSA는 900여분(약45배)이 되어서야 도달하는 것을 확인할 수 있습니다.
Conclusion
해당 논문에서는 기존 DC의 복잡한 bi-level optimization을 피하기 위해, 원래 사용하던 gradient-matching 방법을 심층 신경망을 통과시키는 저차원 맵핑을 사용하여 원본 데이터와 합성 데이터 간의 분포 거리를 줄이는 방법으로 대체하여 기존의 방법과 유사한 성능을 달성했습니다. 원본 데이터셋으로부터 합성 데이터셋을 만드는 새로운 방법을 제시한 것은 위 논문의 좋은 contribution이라고 생각합니다. 하지만 SOTA보다 떨어지는 절대 성능과, real world image라고 생각하기에는 너무나 작은 64X64 이미지를 합성한 부분은 아직 많은 발전이 필요한 부분이라고 생각됩니다.
[1] Bo Zhao, Hakan Bilen. Dataset Condensation with Distribution Matching.
[2] Bo Zhao, Hakan Bilen. Dataset Condensation with Gradient Matching. ICLR 2021
