1. Introduction
Object Detection에서 backbone으로부터 추출된 feature들은 Object Detection의 전체 성능을 좌우할 수 있을 만큼 중요합니다. 이는 단순히 backbone 네트워크를 ResNet-50에서 ResNet-101, ResNet-152로 바꾸기만 해도 큰 정확도 향상을 얻은 것으로 증명됩니다. 그러므로 좋은 backbone을 찾아내는 것은, Object Detection의 주요한 과제입니다.
대부분의 backbone 네트워크는 이미지 분류를 위해 설계된 네트워크에 ImageNet을 훈련시켜 사용합니다. 이러한 backbone 네트워크를 설계하는 일은 숙련된 전문가의 수 많은 시도들을 통해서만 얻어질 수 있습니다. 이 논문에서는 위의 문제를 해결하기 위해 NAS를 통해 object detection에 맞는 backbone 네트워크를 찾는 방법을 제안합니다.
NAS의 방법을 곧바로 backbone 네트워크를 찾는 것에 적용하기는 어렵습니다. NAS 시스템은 목표로 하는 task에서의 정확도를 '보상'으로 돌려줘야 하는데, pre-training accuracy는 전체 object detection 과정을 거치는 reward로 보기 어렵다는 점과 ImageNet이라는 큰 데이터셋에 대해서 훈련되어야 하는 점들이 문제입니다.
이를 위해 one-shot NAS의 가중치 훈련과 네트워크 구조 탐색을 decoupling 하는 방법을 가져와서 사용합니다.
DetNAS는 아래의 세 단계로 이루어집니다.
- one-shot supernet을 ImageNet에 대해서 pre-training 합니다.
- 사전훈련된 one-shot supernet을 object detection 데이터셋에 맞게 fine-tuning 합니다.
- 훈련된 supernet에 진화 알고리즘을 적용하여 최적의 candidate network를 찾아냅니다.
2. Methodlogy
NAS에서는 최적의 네트워크를 찾기 위한 search space를 정하게 됩니다. 여기서 search space를 라고 했을 때, 각각의 네트워크 구조는 가 됩니다. NAS의 목표는 search space에서 validation loss 을 최소화하는 네트워크 구조 를 찾는 것입니다. 이를 식으로 나타내면 다음과 같습니다. 여기서 은 네트워크 구조를 , 가중치를 로 가지는 하나의 네트워크 입니다.
위의 식은 일반적인 NAS의 목표를 도식화 한 것입니다. 하지만 여기서 우리가 해야 할 일은 object detection의 backbone 네트워크를 찾는 것이기 때문에 image classification 데이터셋에 대해 pre-training을 진행하고, detection 데이터셋에 대해 fine-tuning을 하는 과정들도 포함이 되어야 합니다.
위의 식은 image classification에 대해서 loss를 최소화 하도록 최적화된 가중치를(ImageNet을 통해) obeject detection의 네트워크를 훈련시키기 위한 초기값으로 가져오는 것을 의미합니다.
one-shot NAS 방법에서는 search space의 모든 구성요소를 포함시킨 supernet을 훈련시켜 여러 subnet들의 공통된 노드들에 대해서 가중치를 공유하는 전략을 사용합니다. 즉 모든 후보 네트워크 가중치 는 supernet 가중치 에 포함됩니다. 위의 식에서는 supernet을 object detection에 맞게 네트워크를 최적화 하는 방법이 도식화 되어 있습니다.
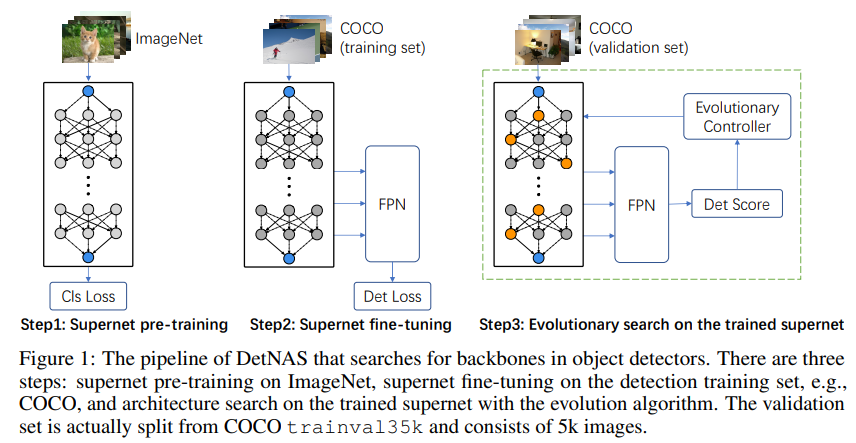

전체 NAS의 pipeline은 다음과 같이 구성되어 있습니다.
- Supernet pre-training
supernet pre-training 단계에서는 훈련된 supernet이 candidate networks의 상대적인 성능을 나타낼 수 있도록 path-wise 방법을 사용합니다. 즉 supernet의 네트워크 경로들 중에서 한 번에 한 가지의 길로만 feedforward, back propagation을 진행합니다.
- Supernet fine-tuning
supernet fine-tuning 단계에서도 마찬가지로 path-wise방식으로 진행되지만, 여기선 추가로 detection head와 detection metric 그리고 detection 데이터셋을 사용합니다. 추가로 Batch Normalization을 Synchronized Batch Normalization(SyncBN)으로 변경해서 진행했는데, 이는 detection의 경우 고화질의 이미지를 훈련에 사용하기 때문에 메모리 제한으로 인해 기존의 BN이 잘 작동하지 않기 때문입니다.
- Search on supernet with EA
supernet을 통해 최적의 네트워크 구조를 찾는 탐색 방법으로는 Evolutional Algorithm을 사용했습니다. RL-based와 Gradient-based 방법들에 비해 EA 방법이 FLOPS와 inference speed 제한 상황에서 더 stable한 탐색이 가능했기에 EA 방법을 사용했습니다.
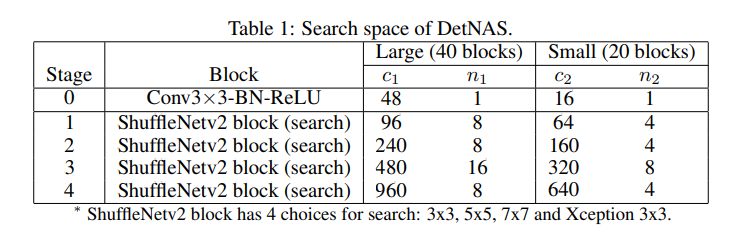
Search space의 경우 channel split과 shuffle operation을 포함하고 있는 ShuffleNetV2의 블럭을 기초로 구성했습니다. Large space의 경우 총 4개의 stage가 각각 8 + 8 + 16 + 8 = 40 개의 블럭으로 구성됩니다. 각 블럭별로 4개의 커널 사이즈{3X3, 5X5, 7X7, Xception}를 선택을 할 수 있습니다. 그렇게 되면 총 후보 네트워크의 수는 개가 됩니다. Small space의 경우에는 20개의 블럭으로 구성하여 개의 후보 네트워크로 구성됩니다. Search space의 크기를 두 개로 나눈 이유는 각각 기존의 hand-crafted 모델과 비교하는 것과 ablation study를 진행하기 위해서 입니다.
3. Results
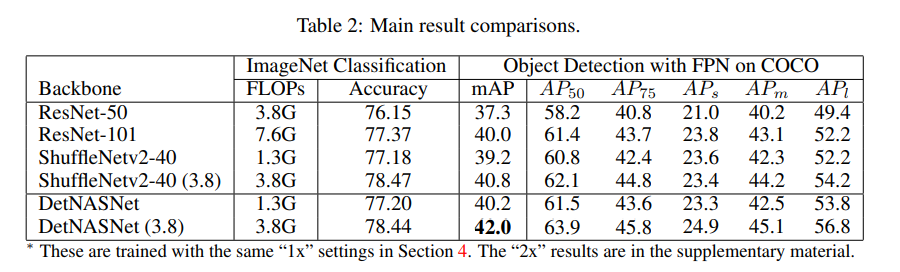
DetNASNet은 FPN을 head로 장착하고 Large search space를 탐색 범위로 지정해 실험을 진행했습니다. object detection에서 사용하는 mAP의 값이 3.8 FLOPs DetNASNet에서 기존의 hand-craft 네트워크를 사용한 것 보다 더 좋은 성능을 보여줌을 확인할 수 있습니다.
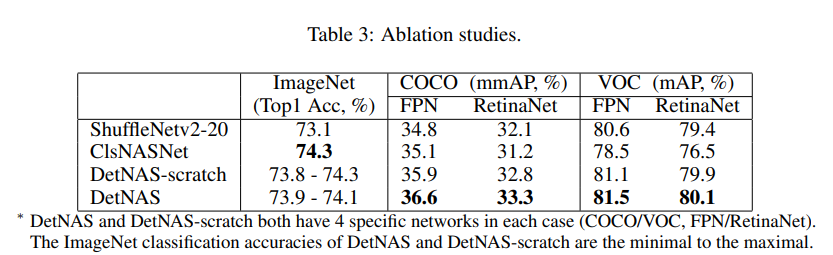
다음으로는 ablation studies의 결과입니다. 여기서는 head를 FPN과 RetinaNet로 바꿔보면서도 실험을 진행 했습니다. ShuffleNetv2-20은 ablation studies의 네트워크들과 비슷한 크기의(FLOPs nuder 300M) hand-craft 네트워크 입니다. ClsNASNet은 object detection에 대한 고려 없이 image classification에 대해서만 최적화된 네트워크를 backbone으로 사용한 경우입니다. DetNAS-scrach는 ImageNet pre-training 없이 DetNAS로 네트워크를 구성한 경우입니다. 결과적으로 해당 논문에서 제안한 DetNAS가 모든 경우에서 가장 좋은 성능을 보여주는 것을 확인할 수 있습니다.
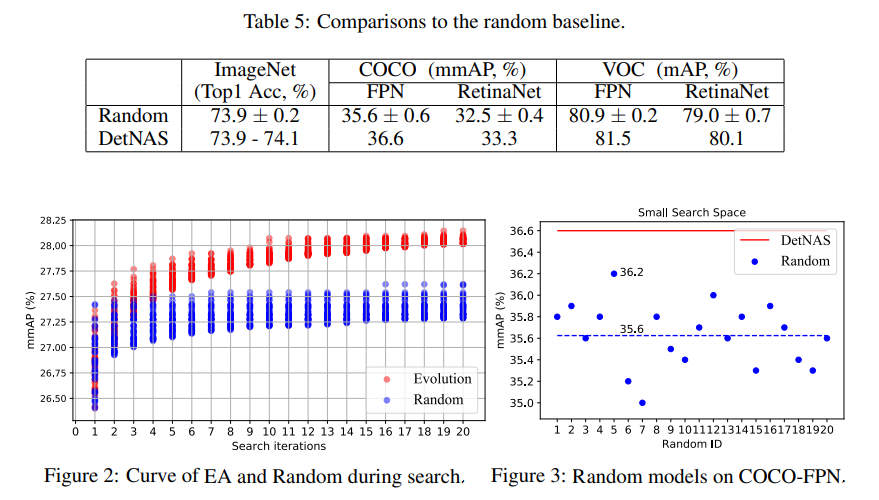
마지막으로 search strategy에서 random 방법과 EA방법을 비교한 결과입니다. DetNAS의 경우 EA 방법을 사용했습니다. 표와 그림에서 모두 DetNAS의 Evolution Algorithm이 더 안정적인 결과를 보여주는 것을 확인할 수 있습니다.
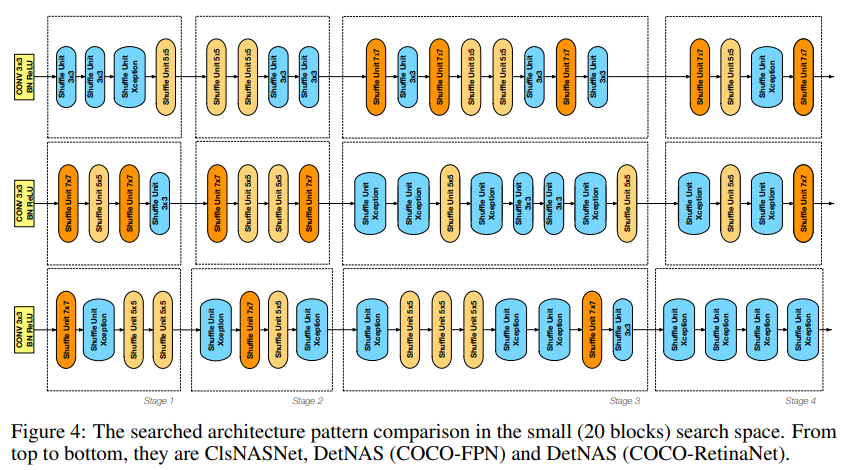
위의 그림은 각각 ClsNASNet, DetNAS(COCO-FPN), DetNAS(COCO-RetinaNet)의 네트워크 구조를 보여줍니다. DetNAS 구조에서는 얕은 층(stage1, stage2)에서 큰 사이즈의 커널을 사용하고 ClsNASNet은 깊은 층(stage3, stage4)에서 큰 사이즈의 커널을 사용하는 모습을 확인할 수 있습니다. ClsNASNet의 네트워크 패턴은 ImageNet에 대해서 최고의 성능을 내는 image classification 네트워크를 찾는 ProxylessNAS 에서도 발견할 수 있는 패턴입니다. 이러한 관찰들을 통해서 image classification에 적합한 네트워크 패턴과 object detection에 적합한 네트워크의 패턴에는 차이가 있음을 발할 수 있습니다.
4. Conclusion
해당 논문은 object detection을 위한 backbone 네트워크를 기존의 Image Classification의 네트워크를 그대로 가져와서 사용하는 것이 아니라, NAS를 통해 object detection에 맞는 네트워크를 찾아내는 방법을 제안했습니다. 해당 논문의 main contribution은 detection의 backbone에 맞는 최적의 네트워크를 NAS를 통해서 찾았다는 점이라고 생각합니다.
논문 출처 : https://proceedings.neurips.cc/paper/2019/file/228b25587479f2fc7570428e8bcbabdc-Paper.pdf
잘못된 내용이 있다면 댓글로 남겨주세요. 감사합니다 :)
