Abstract
머신러닝의 성능을 향상시키는 간단한 방법중 하나인 앙상블 방법은, 한 데이터셋을 여러 다른 모델에서 훈련한 뒤, 그 결과의 평균을 내어 예측하는 것입니다. 하지만, 여러 모델의 앙상블을 쓰는 방식은 모델을 훈련 할 때도 많은 계산비용이 발생하고 만약 이것을 소비자들에게 서비스 해야 하는 상황이라면, 소비자들이 사용하는 스마트폰과 같은 디바이스에서는 계산이 어려울 것입니다. 저자가 이 논문에서 소개하는 Knowledge Distillation 방법은 앙상블 된 지식을 압축해 단일 모델로 증류함으로써 위와 같은 문제에 대안을 제시합니다.
Introduction
대규모 머신러닝에서 우리는 다른 요구 사항(ex. 음성인식, 객체인식)에도 불구하고 훈련단계와 배포단계에서 비슷한 모델을 사용합니다. 그리고 이는 중복된 데이터셋에서 구조를 뽑아내는 방향으로 훈련되어 많은 시간과 계산능력을 필요로 합니다. 하지만 실시간으로 동작될 필요가 없으므로 큰 계산비용도 감당할 수 있습니다. 그러나 수 많은 사용자에게 모델을 배포하는 일은 지연시간과 계산비용에 대한 제약이 생기게 됩니다. 이 제약을 해결하기 위해 이 논문은, 한 번 훈련된 대규모 머신러닝(혹은 모델)의 "지식"을 소비자들에게 배포하기 적합한 작은 모델에 증류하는 방법을 제안합니다.
여기서 네트워크의 지식이라 하면 일반적으로 각 훈련된 네트워크의 파라미터들을 생각하기 때문에 어떻게 네트워크의 지식을 증류할 수 있을지 고민하게 됩니다. 그러나 단순히 네트워크를 거쳐서 나온 출력 벡터를 지식이라고 생각한다면 지식을 증류한다는 개념이 쉽게 와닿습니다.
일반적으로 모델을 훈련할 때 softmax를 거쳐 나온 logit중 가장 높은 값을 취해서 실제 레이블값 y와 비교하여 loss를 구해 모델을 업데이트 합니다. 즉 가장 높은 값을 가지는 logit 외에는 관심을 가지지 않았습니다. 그러나 Knowledge Distillation에서는 이렇게 소외받던 logit들에게 관심을 가져줍니다. 예를들어 BMW의 사진들이 있다고 한다면, 모델이 이를 쓰레기 수거 트럭이라고 잘못 분류하는 경우는 드물게 있을 수 있습니다. 그러나 트럭이라고 분류하는 것이 BMW 사진을 당근이라고 분류할 확률보다는 상대적으로 현저하게 높게 나타날 것입니다. KD는 이러한 지식(정보)들이 유용하다고 생각하는 것에서 출발합니다.
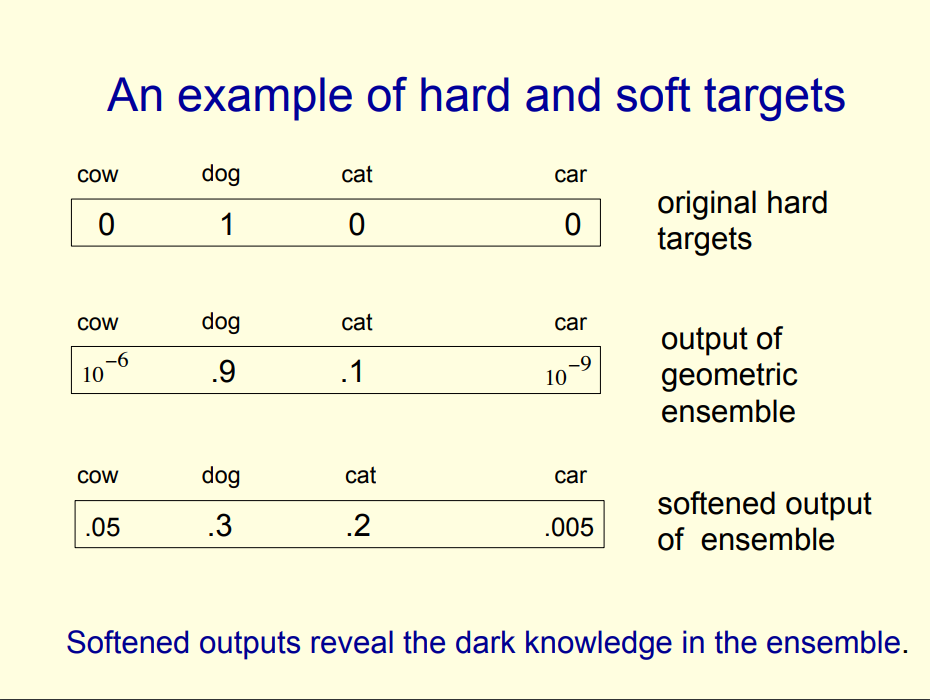
지식을 증류할 때, 큰 모델과 작은 모델은 같은 데이터셋을 사용합니다. 큰 모델의 일반화 능력을 작은 모델에 전수하는 방법은, 복잡한 모델의 클래스 확률을 사용하여 작은 모델을 훈련하는 "soft targets"를 사용합니다. 높은 엔트로피의 "soft targets"를 사용하면 "hard targets"를 사용할 때보다 더 많은 정보를 제공받을 수 있습니다.
MNIST의 경우로 예를 들자면, 숫자 "2" 이미지에 대해서 예측을 진행했다고 가정합니다. 이 때 이를 숫자 "3" 으로 예측한 확률이 , 숫자 "7"로 예측한 확률이 이라고 하면 이는 다른 말로 숫자 "2"가 숫자 "3"이나 "7"처럼 보일 확률이라는 말이 됩니다. 하지만 기존의 "hard targets"를 사용하게 된다면 이 값들은 거의 0에 가까우므로 모델에 영향을 미치기 어렵게 됩니다. 그래서 sigmoid 함수에 (temparature)가 포함된 "soft targets"를 사용하여 다른 logit의 지식도 함께 사용해 더 많은 정보를 작은 모델에게 전달해 주도록 합니다.
Distillation
신경망은 전형적으로 "softmax"를 사용해서 각 클래스별 확률값을 만들어냅니다. logit을 , 각 클래스의 확률을 라고 할 때, 다음과 같이 표현됩니다.
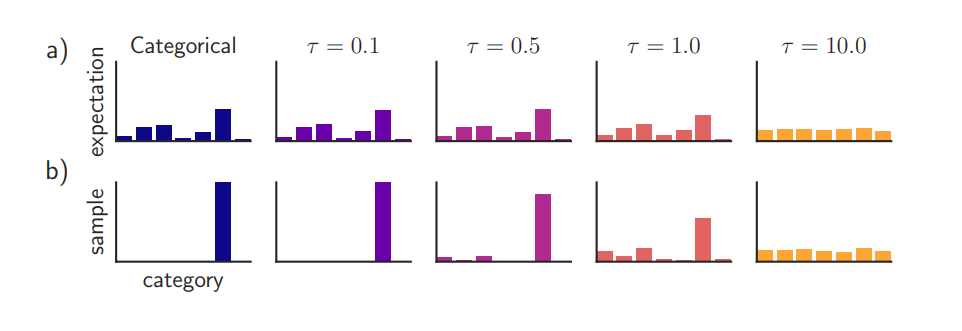
Temperature에 따른 softmax 확률값 (출처 : https://arxiv.org/pdf/1611.01144.pdf)
는 temperature 값인데 일반적으로 1로 주어집니다. 각 클래스별로 soft한 확률값을 내고싶으면 이 값을 높이면 됩니다.
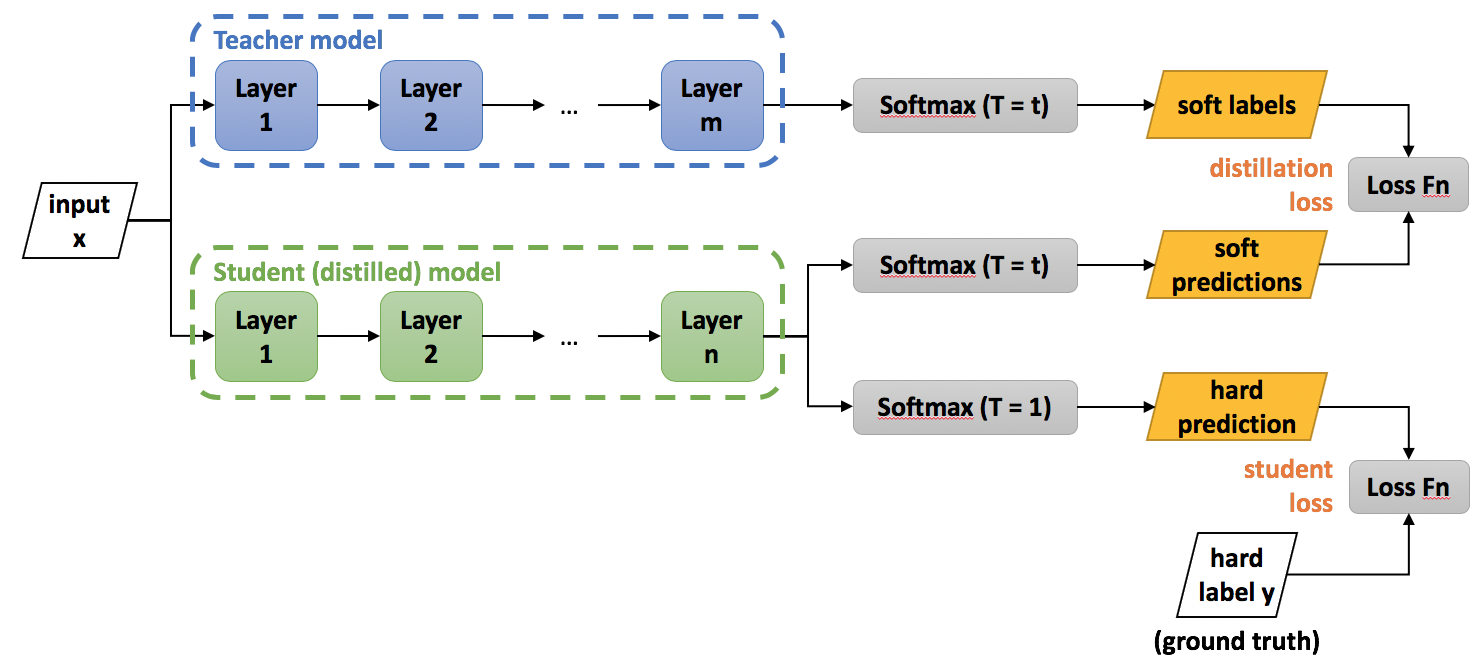
Knowledge Distillation 구조도 (출처 : https://intellabs.github.io/distiller/knowledge_distillation.html)
먼저 transfer set을 복잡한 모델에 대해서 높은 로 soft target을 만들어 내고, 같은 transfer set을 간단한 모델에 대해서 복잡한 모델과 같은 로 soft target을 만들어 냅니다. 마지막으로 transfer set을 간단한 모델에 대해서 즉 hard target을 만듭니다. 위에서 만들어낸 soft target과 hard target을 이용해서 간단한 지식 증류 모델을 만들 수 있습니다. 첫 번째 손실 함수로 큰 모델을 거친 soft targets와 작은 모델을 거친 soft targets들의 Cross-Entropy loss를 구합니다. 그리고 두 번째 손실함수로 작은 모델의 hard targets와 ground truth 사이의 Cross-Entropy loss를 구합니다. 두 번째 손실함수는 transfer set에 대한 정확한 레이블과 예측을 모델이 알게 함으로써 성능을 향상 시킨다고 논문에서 말합니다.
Matching logits is a special case of distillation
추가로 이 논문에서는 특별한 케이스의 증류를 다룹니다. 작은 모델의 logit 의 변화에 따른 Cross-Entropy의 변화를 라 하고, 큰 모델의 logit을 그리고 큰 모델에서 생성된 target 확률을 라 했을 때 다음의 식을 구할 수 있습니다.
여기서 temperature가 logit보다 매우 크다면 에 의해 다음 식으로 근사화 될 수 있습니다.
여기서 지식 증류가 잘 일어난 모델을 가정(작은 모델이 큰 모델의 성능을 가질 때)하면, logit 와 logit 의 평균은 0이 되어야 합니다(즉 ). 이를 적용하여 최종적으로 다음의 식을 얻을 수 있습니다.
즉 높은 에서 logit들의 zero-meaned가 주어졌을 때, 지식증류는 식 를 최소화 하는 것과 같습니다. 에 대한 특징이 또 있습니다. 낮은 에서는 negative logit matching에 대해서 적게 관심을 가지게 되는데, 대게 negative logit은 큰 모델의 noisy한 결과를 가져오기 때문에 이는 유용하게 사용될 수 있습니다. 예를 들어 작은 모델이 큰 모델의 지식을 수용하기에는 너무 작은 크기일 때, large negative logits을 무시하는 방향(를 작게)으로 를 설정하면 학습에 도움을 받을 수 있습니다.
Preliminary experiments on MNIST
이 논문에서는 지식 증류 기법이 실제로 잘 동작하는지 확인하기 위해서 MNIST 데이터셋으로 실험을 진행했습니다. 큰 모델로는 1200 ReLU를 가지는 두 개의 은닉층을 사용했고, 작은 모델로는 800 ReLU를 가지는 두 개의 은닉층을 사용했습니다. 60000개의 훈련 이미지를 사용해서 10000개의 테스트 이미지에 대해 평가했을 때, 큰 모델은 67개의 오류를 내었고, 작은 모델은 146개의 오류를 냈습니다. 그리고 큰 모델의 지식을 작은 모델에 으로 증류하였을 때, 74개의 오류를 달성했습니다. 이는 지식 증류 기법이 실제로 잘 동작함을 보여줍니다.
증류된 네트워크가 300개 이상의 유닛을 가지며 두 개의 은닉층을 가지면, temperature 값이 8 이상이어도 비슷한 결과를 보여줍니다. 그러나 레이어당 유닛의 개수가 30개 정도로 줄어든다면, temperature는 2.5 ~ 4 정도의 값을 가질 때 그 이상과 이하일 때 보다 더 좋은 성능을 보여줍니다.

(출처:https://blog.lunit.io/2018/03/22/distilling-the-knowledge-in-a-neural-network-nips-2014-workshop/)
또한 transfer set에서 숫자 "3"에 해당하는 이미지를 모두 제거하는, 즉 증류된 모델은 숫자 "3"을 본 적이 없는 상태로 예측을 하는 실험을 진행해봤는데 그 결과는 놀라웠습니다. 전체 오류는 206개였고, 숫자 "3"에 해당하는 1010개의 이미지중 단 133개만 오류를 일으켰습니다. 여기에 올바른 bias값을 주게 되었을 때, 모델은 본 적 없는 숫자 "3"에 대해서 98.6%의 정확도를 보여줬습니다.

(출처:https://blog.lunit.io/2018/03/22/distilling-the-knowledge-in-a-neural-network-nips-2014-workshop/)
심지어 transfer set에 숫자 "7"과 "8"만 두고 모델을 증류했을 때 증류된 모델은 47.3%의 정확도를 보여주기도 했습니다(비록 "7", "8"에 대한 bias가 감소했을 땐 13.2%까지 떨어지긴 했습니다).
Training ensembles of specialists on very big datasets
앙상블 모델은 병렬 계산을 가장 쉽게 취할 수 있는 구조입니다. 하지만 앙상블에 사용될 각 모델이 대규모의 신경망이라면, 병렬로 계산을 한다 할 지라도 매우 많은 계산능력과 훈련시간을 필요로 하게 됩니다. 저자는 혼동하기 쉬운 서로 다른 subset에 집중하는 전문가 모델을 제안해서 이 문제를 해결하려 합니다. 전문가 모델의 주된 문제는 오버피팅 현상이 잘 일어난다는 점인데 이는 soft target을 사용해서 방지할 수 있습니다.
The JFT dataset
JFT는 구글의 내부자료 데이터셋입니다. 이는 10억개의 레이블된 이미지와 15,000개의 레이블을 가지고 있습니다. 이 데이터셋은 많은 수의 코어와 비동기식 경사 하강법을 사용한 구글의 baseline을 사용하여 훈련하면, 6개월 정도의 시간이 걸립니다. 이런 큰 모델에 대해서 앙상블 기법을 사용하게 된다면 수년의 시간이 걸릴텐데 이를 기다리고 있을 수는 없습니다. 그래서 baseline의 속도를 빠르게 개선하는 방법인 전문가 모델을 제안합니다.
Specialist Models
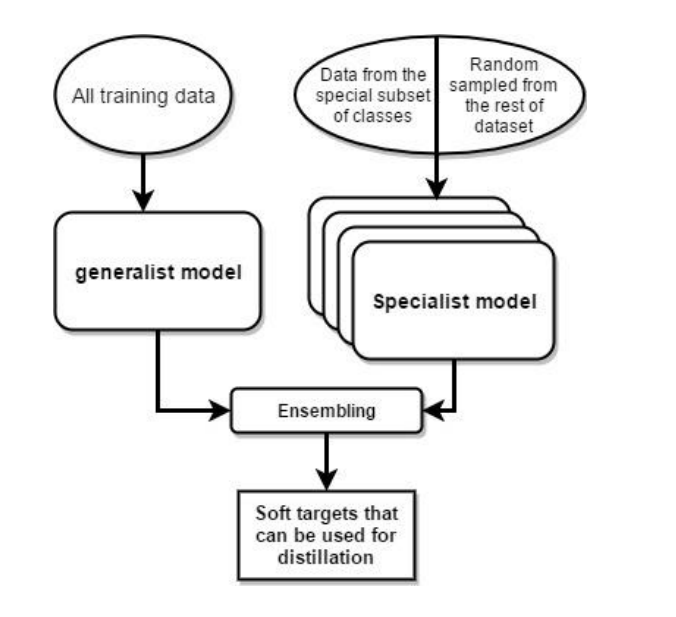
Specialist model 구조도 (출처 : https://www.cs.ubc.ca/~lsigal/532S_2018W2/4b.pdf)
클래스의 수가 매우 많을 경우, 복잡한 모델의 앙상블을 하기 위해서 전체 데이터셋에 대해 훈련된 "일반 모델"과 헷갈리기 쉬운 클래스의 subset 데이터에 대해서 훈련된 "전문가 모델"을 사용하는 것이 합리적입니다. 또한 전문가 모델이 신경쓰지 않는 다른 subset들을 하나의 dustbin 클래스로 결합하여 softmax를 더 가볍게 만들 수 있습니다.
전문가 모델의 가중치는 일반 모델의 가중치로 초기화 됩니다. 이는 오버피팅을 줄이고, 일반 모델의 작업을 공유하기 위해서입니다(결국 전문가 모델은 일반 모델의 하위에서 특정 클래스를 학습하는 것이기 때문에). 그리고 이 가중치들은 각 전문가의 목표 클래스에서 절반, 나머지 데이터 셋에서 랜덤으로 절반을 가져와 훈련하며 수정됩니다. 훈련이 끝난 후, 오버샘플된 전문가 클래스의 비율의 log값으로 dustbin 클래스의 logit을 증가시킴으로써 biased된 훈련셋을 수정합니다.
Assigning classes to specialists
전문가 모델로 클래스들을 병합 하기 위해서 전체 네트워크가 자주 혼동하는 카테고리에 집중합니다. Confusion 행렬을 계산하여 클러스터를 찾는 방법도 있지만, 이 논문에서는 더 간단한 접근방식을 선택했습니다.

전문가 모델의 클러스터를 구할 때, 일반 모델의 예측에 대한 공분산 행렬을 클러스터링 알고리즘에 적용해서 구합니다. 여기서 은 전문가 모델 으로 예측된 클래스들의 셋입니다. K-평균 알고리즘의 온라인 버전을 적용해 공분산 행렬의 열에 적용하여 표2의 합리적인 클러스터를 얻었습니다.
Performing inference with ensembles of specialists
전문가 모델을 증류하기 전에 전문가 모델이 포함된 앙상블이 어느정도 성능을 내는지 확인하고 싶었습니다. 이를 위해 주어진 이미지 에 대해서 두 단계에 걸쳐서 평가합니다.
첫 번째로, 각 테스트 케이스에 대해 일반 모델에 따라 가장 가능성이 높은 개의 클래스를 찾아냅니다(실험에서는 ). 이 클래스 집합을 라고 합니다.
두 번째로, 클래스 집합 의 하위 클래스 과 사이의 교차점을 가져와 활성 전문가 셋 를 구성합니다. 그런 다음 다음의 식을 최소화하는 전체 클래스에 대한 확률분포 를 구합니다.
여기서 는 KL 다이버젼스이고, , 는 각각 전문가 모델의 확률 분포와 일반 모델의 확률 분포입니다. 분포 은 에 속해있는 모든 전문가 클래스의 분포와 dustbin 클래스의 분포를 포함하기 때문에, 분포 와 다이버젼스를 계산하면 전체 분포가 의 dustbin에 있는 모든 클래스에 할당하는 모든 확률을 합산하게 됩니다.
Results

훈련된 기본 전체 네트워크에서 시작하여 전문가 모델은 매우 빠르게 훈련합니다.(JFT의 경우 몇 일) 또한 모든 전문가 네트워크는 완적히 독립적으로 훈련됩니다. 표3은 baseline과 전문가 모델이 적용된 것의 절대적인 테스트 정확도를 나타낸 것입니다. 표4는 전문가 모델이 추가될 수록 나타나는 상대적 개선률이 나타나 있습니다.
Soft Targets as Regularizers
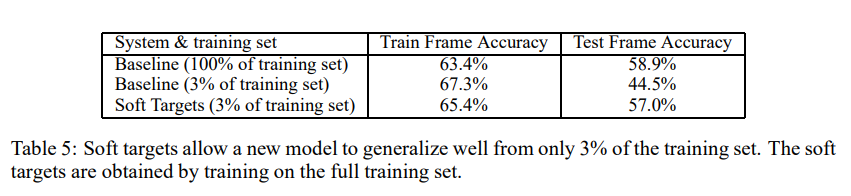
soft target을 쓰면 hard target을 쓸 때보다, 더 많은 유용한 정보를 전달할 수 있습니다. 또한 훈련 셋의 데이터를 적게 전달해보는 실험을 통해 soft target을 사용하면 과적합을 예방할 수 있다는 사실도 발견할 수 있었습니다. 추가로 soft target을 사용하면 정확도가 수렴하게 되어 조기 중단을 고려하지 않아도 된다는 이점도 발견했습니다. 이는 soft target이 대형 모델이 가지고 있는 지식을 다른 모델에 전달하는데 매우 효과적인 방법임을 보여줍니다.
Relationship to Mixtures of Experts
전문가 모델을 사용하는 다른 방법 중 하나는 혼합 전문가 방법을 사용하는 것입니다. 이는 게이팅 네트워크를 통해 데이터에 적합한 전문가를 할당하는 방법으로 단순히 입력 벡터를 클러스터링 하여 전문가를 할당하는 것보다 훨씬 좋지만, 훈련을 병렬로 진행하기 어렵습니다. 따라서 일반 모델을 훈련한 뒤 confusion 행렬을 사용해 전문가 모델이 훈련한 subset을 할당하는 방식을 사용합니다.
Disscussion
이 논문은 Distillation이 앙상블 혹은 고도로 정규화된 모델에서 더 작은 모델로 지식을 전달하는데 효과적임을 보여줍니다. 심지어 MNIST에서는 하나 이상의 클래스 예제가 없음에도 지식 증류가 잘 작동함을 보였습니다. 또한 전문가 모델의 개념을 도입하여 거대한 데이터셋에 대해 훈련된 거대한 모델의 앙상블도 가능함을 보여줍니다.
논문 출처 : https://arxiv.org/pdf/1503.02531.pdf
Knowledge Distillation에 대한 논문 리뷰입니다.
잘못된 내용이 있다면 댓글로 남겨주세요. 감사합니다 :)
