앙상블은 여러 분류기를 하나로 연결해 개별 분류기보다 좋은 성능을 달성한다고 공부를 했다. 그 중 보팅은 여러 분류 알고리즘을 사용하고, 배깅과 부스팅은 하나의 분류 알고리즘을 사용한다.
-
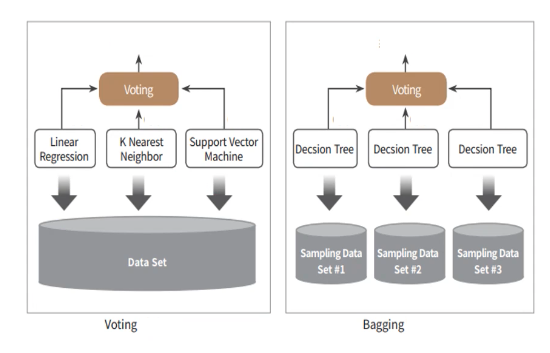
Voting
각 결정나무의 예측값이 0.7, 0.8, 0.6의 결과가 나왔다고 가정했을 때,
soft voting은 평균값인 0.7을,
hard voting은 0.8을 출력하게 된다.
(이 예시만 보면 하드보팅은 최고의 점수를 출력하는 것 같다. 하드보팅을 다수결의 원칙이라고 하는 것에 헷갈렸는데, https://blog.naver.com/fbfbf1/222484365132 글을 참고하니 이해가 된다.)
-
배깅
배깅은 여러 개의 분류기가 같은 알고리즘을 사용하는 것을 위의 이미지를 통해 알 수 있다. 배깅에서 가장 대표적인 알고리즘이랜덤포레스트인데, 이미지에서 Decision Tree 여러 개를 사용한 배깅 모델이 랜덤포레스트라는 것을 알 수 있다.(천리길 스터디 설명) -
부스팅 - 경사하강법
그레디언트 부스팅 할 때 경사하강법이 많이 언급되는데, 그 개념을 알아보자. 부스팅 알고리즘은 여러 개의 알고리즘을 사용하는데, 약한 알고리즘을 순차적으로 학습-예측하며 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해나가면서 학습한다.- 3명의 학생이 있을 때, 1번 학생이 5/10문제를 맞췄다.
- 1번 학생이 2번 학생에게 가르쳐 줄 때, 맞춘 5문제는 똑같이 맞출 수 있도록 전달하고, 틀린 문제에 집중해서 가르쳐준다.
- 2번 학생은 7/10 문제를 맞춘다.
- 2번 학생이 3번 학생에게 가르쳐 줄 때, 맞춘 7문제는 똑같이 맞출 수 있도록 전달하고, 틀린 문제에 집중해서 가르쳐준다.
- 마지막 학생인 3번 학생은 예측 오류를 개선해 제일 나은 결과를 낼 수 있다.
그 중, GBM(Gradient Boosting Machine)은 경사 하강법을 통해 가중치 업데이트를 수행한다.
천리길 스터디 시간에 우리가 산 정상에 있고, 하산하는 지점이 Goal이라서 내려오는 방법을 찾고 있다는 예시를 들어서 이해를 도왔다. 직선, 지그재그, 뒤로 한바퀴 돌아서 내려 오기 등 다양한 방법을 쓸 수 있는데, 파란점이 최적의 파라미터라고 한다면, 파란점을 스치는 루트가 최적값을 지나쳐왔다고 할 수 있다. 이를 통해 어떤 식으로 내려갈 지를 결정하는 것이 learning rate라고 한다.
-
XGBoost와 LightGBM
XGBoost와 LightGBM 은 GBM 기반의 대표적인 알고리즘이다.- XGBoost(eXtreme Gradient Boost)
- 트리 기반의 앙상블 중 인기가 많은 알고리즘 중 하나이다.
- 과적합 방지를 위해 learning rate를 낮추고, n_estimator를 높이고/ max_depth를 낮추고 / min_child_weight 를 높이고 / gamma를 높이고 / subsample, colsample_bytree를 낮추는 방법을 많이 들어주는데, n_estimator와 max_depth를 제외하고는 공부가 좀 더 필요하다.
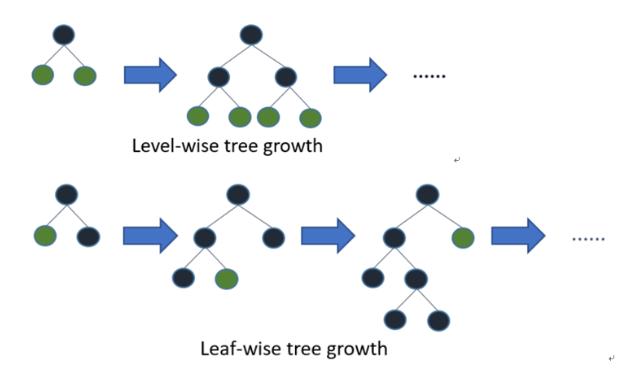
- leve-wise방식(BFS 넓이 우선 방식)를 사용 : 트리의 깊이를 줄이고 균형 있게 만들기 위해서 root 노드와 가까운 노드를 우선적으로 순회하여 수평성장하는 방식.
- LightGBM
- 기존 알고리즘의 정확도를 유지하면서 훨씬 좋은 효율성
- XGBoost보다는 빠르지만, 다중 분류나 다중회귀가 안되는 치명적인 단점이 있다.
- leaf-wise방식(DFS 깊이 중심 방식)을 사용 : 현재 위치의 leaf에서 갈 수 있는 점들을 모두 탐색해서 트리를 완성한다. 비대칭적인 트리를 생성하지만, level-wise에 비해 예측 오류 손실이 작거나 빠르게 도달할 수 있다.
- XGBoost(eXtreme Gradient Boost)