그래디언트 부스팅
- 다중가산회귀트리(MART, Multiple Additive Regression Trees), 확률적 그라디언트 부스팅, 그라디언트 머신 등 다양한 이름으로 불린다. GRBT(Gradient Boosted Regression Tree), GBT(Gradient Boosted Decision Tree), GBT(Gradient Boosted Tree)
- 2001년 제롬 프리드만 : 랜덤포레스트, GBDT(Gradient Boosted Decision Tree), GBRT(Gradient Boosted Regression)을 만들었다.
- 손실함수를 최소화
- 여러 약한 학습기(weak learner, 얕은 트리)를 합쳐 최종 모델
- 이전 트리에서 잘못 분류된 데이터 훈련
Gradient Boosting
- GradientBoostingClassifier, GradientBoostingRegressor 모두 사용하는 트리는 DecisionTreeRegressor를 사용
- Gradient Boost 프로세스(https://bkshin.tistory.com/entry/머신러닝-15-Gradient-Boost)
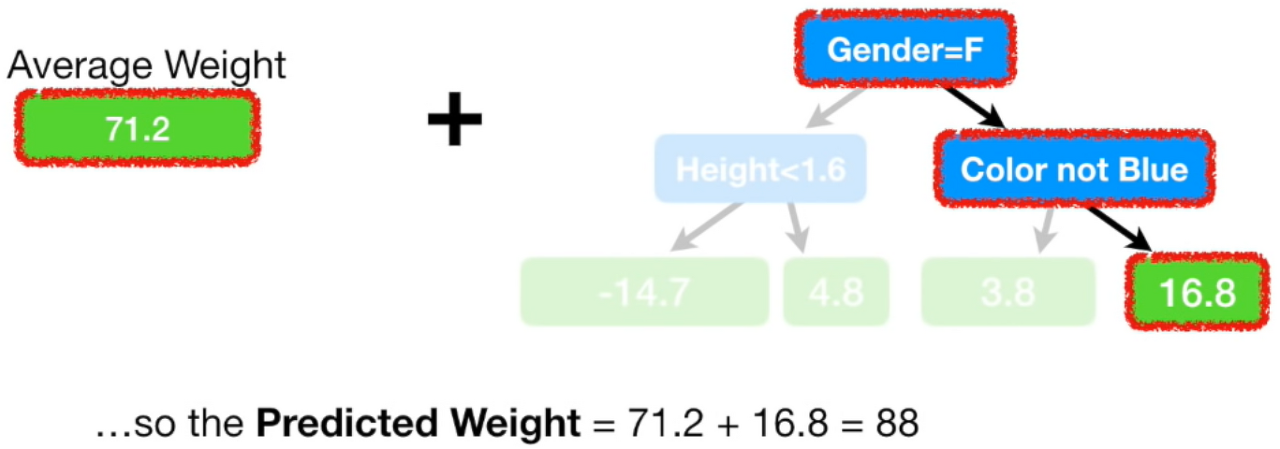
1. single leaf로 몸무게 예측
2. single leaf에서 예측한 값과 실제 값의 차이(error)를 반영한 새로운 트리 생성
1. leaf 8개~32개인 트리를 주로 사용
2. Pesudo Residual
- 중요 매개변수
- Boosting 관련
- n_estimators : 트리 개수 지정, 랜덤포레스트는 트리 개수가 많으면 좋지만, 그래디언트는 모델이 복잡해지고 과대적합이 될 수 있다.
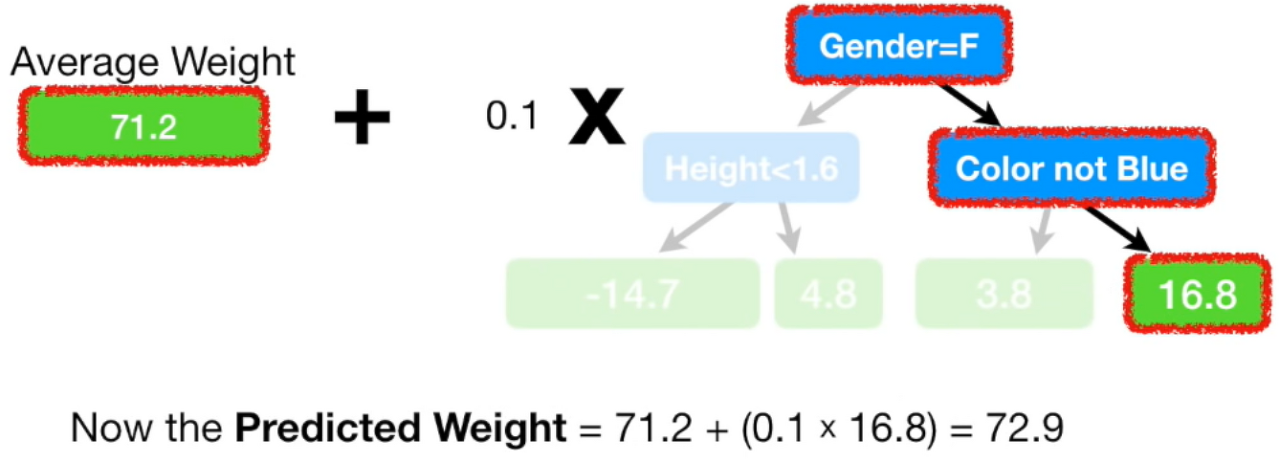
- learning_rate : 이전 트리의 오차를 얼마나 보정할 것인지 제어. 학습률이 크면 보정을 강하게 해 복잡한 모델이 만들어진다.
- Tree-Specific
- max_depth : 각 트리의 복잡도를 낮춤. 그라디언트에서는 5 이하로 설정
- max_leaf_nodes : 리프 노드의 최대 개수, 각 트리의 복잡도를 낮춤.
- Boosting 관련
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state = 42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
0.888108692152563, 0.8720430147331015
# train_score는 높아지지만, 검증세트에 대한 정확도는 큰 차이가 나지 않지만, 데이터가 많아지면 과대적합으로 검증세트에 대한 정확도가 낮아질 것이다.
gb = GradientBoostingClassifier(n_estimator = 500, learning_rate = 0.2, random_state = 42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
0.9464595437171814, 0.8780082549788999Histogram-based Gradient Boosting
- 256개 정수 구간 : 255개 구간으로 나누고, 1개는 누락된 값을 할당하기 위해 대비
- 누락된 값을 평균으로 대체하거나 하는 전처리를 할 필요가 없다.
- 실험적 단계의 기능이라서 sklearn.experimental 에서 불러올 수 있다.
- 히스토그램 기반 그래디언트 부스팅 알고리즘을 구현한 라이브러리 중 대표적인 라이브러리가 XGBoost
- XGBClassifier(tree_method=’hist’, random_state=42) 와 같이 설정해서 사용 가능
- 과대 적합을 억제하며 높은 성능을 제공한다.
- 트리 개수 지정 시, n_estimators 대신 부스팅 반복 횟수를 지정하는 max_iter를 사용
- 특성 확인 시 permutation_importances() 를 사용한다.
- permutation(순열, 치환) : 특성의 분포를 임의로 흐트린 후 , 기존의 결과와 비교해 해당 특성이 결과값에 얼마만큼의 영향을 미치는지(중요도)를 보여준다.
- permutation_importances를 확인하고 나면, 중요도가 낮은 특성을 제거해 feature_selection을 할 수 있지만 정확도는 낮아진다.
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state=42)
scores = cross_validate(hgb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
0.9321723946453317, 0.880124194861236
아직 고쳐나가는 중.