model_selection 에서 cross_validate, cross_val_predict, cross_val_score 출력 결과가 헷갈려서 다시금 공부하고자 했다. 사이킷런 공식 문서의 sklearn.model_selection 부분을 들어가보면,
Splitter Classes에 KFold
Splitter Functions에 train_test_split
Hyper_parameter optimizers에 그리드서치와 랜덤서치 기능
Model validation에 cross_validate, cross_val_predict, cross_val_score
가 들어있다. 교차 검증의 순서를 이해하면 항목들이 이해가 잘 될 것 같다.
교차 검증 워크플로
교차 검증은 train_test_split으로 1회 분리한 모델의 학습과 검증을 여러 번 시도해 같은 데이터로 여러번 훈련하는 효과를 낸다.

train_test_split
학습과 테스트 세트 분할은 train_test_split 함수로 빠르게 훈련세트를 만들 수 있다.
sklearn.model_selection import train_test_splittrain_test_split과 교차 검증 때의 split 을 잘 설명해주는 이미지
출처 : https://zngsup.tistory.com/48
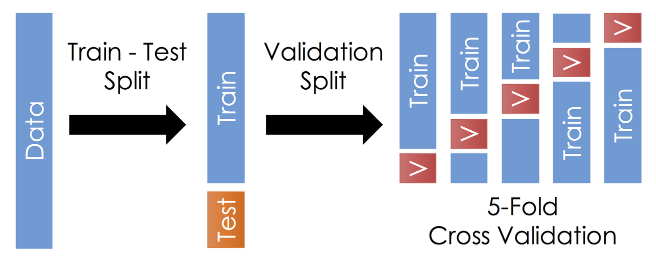
교차 검증
일반적으로 k-fold cross validation을 많이 사용한다!
과적합을 방지한다.
데이터 편향을 방지한다.
일반화 된 모델을 생성할 수 있다.
비교
cross_val_score
사이킷런에서 교차 검증을 조금 더 편리하게 수행할 수 있게 해준다. 검증할 세트 설정, 반복적으로 학습과 테스트 데이터 인덱스 추출, 반복적으로 학습과 예측 수행, 성능 반환의 일련의 과정을 한번에 진행할 수 있게 해준다.
cross_val_score(estimator, X, y=None, *, groups=None,
scoring=None, cv=None, n_jobs=None, verbose=0,
fit_params=None, pre_dispatch="2*n_jobs", error_score=nan)
***
# 예시
from sklearn.model_selection import cross_val_score
clf = svm.SVC(kernel='linear', C=1, random_state=42)
scores = cross_val_score(clf, X, y, cv=5)
scores
# 출력 결과
array([0.96..., 1. , 0.96..., 0.96..., 1. ])cross_validate
Evaluate metric(s) by cross-validation and also record fit/score times.
cross_val_score보다 좀 더 여러 정보들을 dict 형태로 출력한다.
{'fit_time' : array([숫자, 숫자, 숫자]), 'score_time' : array([0. , 0. , 0.]), 'test_score': array([]), 'train_score':array([])}
- return_train_score는 훈련 점수를 포함할지 여부
- 학습 시간, 평가시간, 평가 점수, 훈련 점수
- cross_val_score는 간단하게 평가 점수만을 보여준다.
cross_validate(estimator, X, y=None, *, groups=None,
scoring=None, cv=None, n_jobs=None, verbose=0,
fit_params=None, pre_dispatch="2*n_jobs",
return_train_score=False, return_estimator=False, error_score=nan)cross_val_predict
cross_val_score과 비슷하지만, cross_val_score는 교차 검증 폴드에 대한 평균을 취하는 반면, cross_val_predict는 구별되지 않은 개별 모델의 레이블을 반환한다.
데이터셋을 train, test로 나누고 -> 여러 번 훈련을 반복하여 시키는데 발생할 수 있는 문제를 막기 위해 교차 검증을 실시하고 -> 성능을 테스트하기 위해서 점수를 출력하는데 거기에 사용되는 것이 cross_val_score, cross_validate, cross_val_predict 같다.
하지만 cross_val_score이 가장 간단하게 필요한 정보만을 전달해주고 일련의 과정을 생략할 수 있게 해주기 때문에, k_fold랑 cross_val_score랑 일반적으로 많이 사용하는 것으로 이해하면 되려나?
참고
Model Selection : https://scikit-learn.org/stable/modules/classes.html#module-sklearn.model_selection
교차 검증 : https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation
cross_validate : https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html#sklearn.model_selection.cross_validate
cross_val_predict : https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_predict.html#sklearn.model_selection.cross_val_predict
cross_val_score : https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html#sklearn.model_selection.cross_val_score
