이 글은 논문 Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation (2021) 에 대한 설명입니다. 논문 원본에 대한 링크는 아래에 적어놓았습니다.
논문 원본 : https://arxiv.org/abs/2008.00951
git : https://eladrich.github.io/pixel2style2pixel/

Abstract
- Image-to-Image 변환 프레임워크인 pixel2style2pixel(psp)를 제안한다.
- 일련의 Style vectors를 직접 생성하는 새로운 Encoder와 사전 훈련된 StyleGAN Generator를 사용한다.
- Encoder는 추가 최적화 없이 실제 이미지를 W+로 Embedding 할 수 있다.
- Encoder를 활용하여 이미지 간 변환 작업을 직접 해결하여 일부 입력 도메인에서 잠재 도메인으로 인코딩 문제를 정의할 것을 제안한다.
- StyleGAN을 통해 변환 작업을 해결하는 것이 상대가 필요하지 않기 때문에 훈련 과정을 상당히 단순화하고, 픽셀 간 대응 없이 작업을 해결하는데 더 좋으며, 스타일의 재샘플링을 통해 Multi-modal synthesis를 지원한다는 것을 보여준다.
- SOTA와 비교했을 때, facial image-to-image translation tasks에서 psp의 잠재력을 입증했으며, 이것이 확장될 수 있음을 보여준다.
1. Introduction
- GAN은 얼굴 이미지 합성에서 상당히 진보되었으며, 현재 존재하는 SOTA는 사실적인 이미지를 생성할 수 있다.
- StyleGAN[1, 2]의 고해상도 이미지에서의 품질이 좋으며, 제어 및 편집 기능을 제공하는 W라는 Latent space를 가지고 있다. 이러한 방법은 "Invert first, edit later"라는 접근 방식을 따른다.
- 시간이 지나면서 W에서 확장하여 W+로 코딩을 하는 것이 일반적이게 되었고, 이는 StyleGAN의 각 입력 레이어에 하나씩 18개의 서로 다른 512차원 w 벡터의 연결에 의해 정의된다.
- 이렇게 단일 이미지를 W+로 변환하는데에는 이미지마다 최적화를 하기 때문에 몇 분이 소요되므로 이를 빠르고 정확하게 변환시키는 것은 여전히 어려운 과제이다.
-
본 논문에서는 Feature Pyramid Network[3] 기반의 Encoder를 사용하며, 여기서 Style vector는 다른 피라미드 스케일에서 추출되어 공간 스케일에 대응하여 사전 훈련된 StyleGAN Generator에 직접 삽입된다.
-
Image-to-Image translation tasks의 이전 연구들은 단일 문제를 해결하기 위한 전용 아키텍처를 가지지만, 본 논문은 pix2pix와 동일한 아키텍처를 사용하여 보다 일반적인 프레임워크를 정의한다.
-
psp는 훈련 과정의 단순화 외에도, Adversary discriminator를 훈련시킬 필요가 없어, 사전 훈련된 StyleGAN Generator를 사용하면 몇 가지 이점을 가진다.
- Encoder의 Residual feature map을 공급하여 강한 Locality bias을 생성한다.
- 생성된 스타일을 재샘플링하여 아키텍처 또는 훈련 프로세스에 대한 변경 없이 출력 이미지의 변형을 생성할 수 있다.
-
본 논문의 방법은 pixel2style2pixel 변환을 수행하는데, 모든 이미지가 먼저 Style vector로 Encodding된 다음 이미지로 Encodding되기 때문에 pSp라고 부른다.
2. Related Work
2.1 GAN Inversion
- GAN의 발전에 따라 많은 연구에서 그들의 Latent space를 이해하고 통제하려고 노력해왔다. 그 중 많은 관심을 받은 연구가 GAN Inversion이다.
- 이것은 사전 훈련된 GAN이 주어진 이미지를 가장 정확하게 재구성하는 Latent vector를 찾는다.
- 최근 연구들은 이 작업에 StyleGAN을 사용했으며, 일반적으로, Inversion 방법은 주어진 이미지에 대한 오류를 최소화하기 위해 Latent vector를 직접 최적화하거나, 주어진 이미지를 Latent space에 mapping하도록 Encoder를 훈련시키거나, 두 가지를 결합한 하이브리드 접근 방식을 사용한다.
- 본 논문에서 사용한 Encoder는 추가 최적화없이 주어진 얼굴 이미지를 확장된 Latent space인 W+에 정확하고 효율적으로 내장할 수 있다고 설명한다.
2.2 Latent Space Manipulation
- 많은 논문에서 Latent code의 의미 편집을 학습하기 위한 다양한 방법을 제시했는데, 그 중 인기있는 접근 방식은 "young ↔ old", "no-smile ↔ smile"와 같이 주어진 binary labeled의 변화에 대응하는 선형 방향을 찾는 것이다.
- 이외에도 다른 방법들이 논문에 작성되어져 있는데, 이런 방법들은 일반적으로 이미지가 Latent space에 삽입된 다음 그것의 잠재된 모습이 의미적으로 의미있는 방식으로 편집되는 "invert first, edit later" 절차를 따른다.
- 하지만 본 논문에서는 입력 이미지를 해당 Output latents에 직접 Encodding하여 StyleGAN 도메인에 존재하지 않는 입력도 처리할 수 있도록 하기 때문에 위 방법과 다르다고 설명하고 있다.
2.3 Image-to-Image
- Image-to-Image 변환 기술은 입력 이미지를 대상 도메인의 해당 이미지에 mapping하는 조건부 이미지 생성 기능을 학습하는 것을 목표로 한다.
- 이를 위해 Conditional GANs이 도입되었으며, 그 이후에는 고해상도 합성, 비지도 학습, Multi-modal 이미지 합성, 조건부 이미지 합성 등으로 확장되었다.
- 위 연구들은 전용 아키텍처를 구축하였는데, 이는 Generator를 훈련시켜야 하며 일반화되지 않기 때문에, 본 논문과 차이가 있다라고 서술하고 있다.
3. The pSp Framework
- pSp 프레임워크는 사전훈련된 StyleGAN Generator와 W+ Latent space를 기반으로 한다.
- 각 입력 이미지를 인코딩하는 간단한 기술은 Encoder의 마지막 layer에서 얻은 단일 512차원 vector를 사용하여 주어진 입력 이미지를 W+로 직접 Encoding하여 18가지 Style vector를 모두 학습하는 것이다.
- 그러나, 이러한 아키텍처는 병목현상을 보이고, 이미지의 세부 정보를 완전히 표현하기 어렵다는 단점이 존재한다.
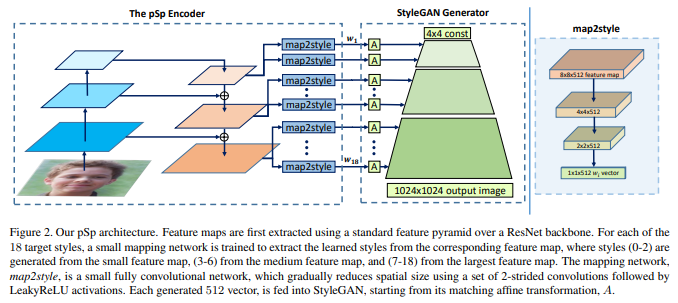
- StyleGAN에서 저자들은 다양한 스타일 입력이 Coarse, Medium, Fine이라는 3가지 그룹으로 나뉘는 다양한 수준의 세부 사항에 대응한다는 것을 보여주었다.
- 이에 따라 pSp에서는 Figure 2와 같이 map2style을 사용하여 스타일을 추출하는 세 가지 수준의 Feature map을 생성한다.
- 스타일은 출력 이미지를 생성하기 위해 스케일에 따라 StyleGAN의 Generator로 공급되며, 중간 스타일 표현을 통해 입력 픽셀에서 출력 픽셀로의 변환을 진행한다.
- 입력 이미지 x가 주어지면, 아래와 같이 출력이 정의된다. E( )는 Encoder를 나타내는 것이고, G( )는 StyleGAN의 Generator를 뜻하는 것으로 정의된다.
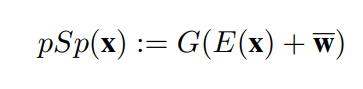
- 위 공식에서 Encoder는 Style vector의 평균과 관련하여 Latent code를 학습하는 것을 목표로한다.
3.1 Loss Function
-
Encoder의 Loss Function은 아래처럼 4가지 식의 가중합으로 이뤄진다.
-
아래 Loss Function은 이전 연구보다 StyleGAN으로 더 정확하게 Encoding할 수 있으며, 특성에 따라 다른 Encoding 작업에 쉽게 튜닝할 수 있다.
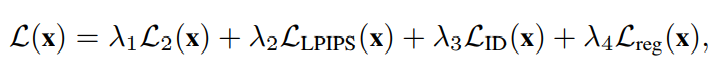
-
첫째로, 픽셀 단위 L2 Loss가 활용된다.
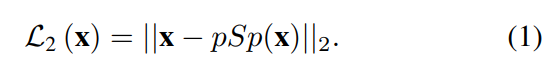
-
둘째로, Perceptual similarities를 학습하기 위한 LPIPS[4] Loss를 활용한다.
- F( )는 Perceptural feature extractor를 나타낸다.
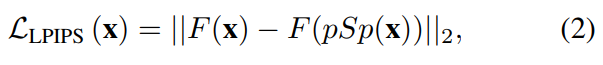
- F( )는 Perceptural feature extractor를 나타낸다.
-
셋째로, Encoder가 평균 Latent vector에 더 가까운 Latent style vector를 출력하도록 아래와 같은 정규화 Loss를 추가했다.
-
Encoder 훈련에 이 정규화 loss를 추가하면 이미지 품질이 향상된다는 것을 발견했으며, 이는 아래에서 탐구되는 더 모호한 작업 중 일부에서 눈에 띈다.
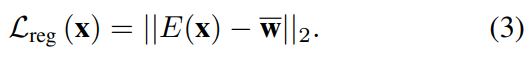
-
마지막으로, 얼굴 이미지 Encoding의 특정 작업을 처리할 때 공통적인 과제는 Input identity의 보존인데 이를 해결하기 위해 출력 이미지와 소스 사이의 Cosine similarity을 측정하는 전용 Recognition loss를 활용한다.
- R은 사전훈련된 ArcFace[5] 네트워크이다.
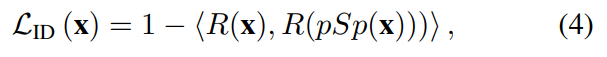
- R은 사전훈련된 ArcFace[5] 네트워크이다.
3.2 The Benefits of The StyleGAN Domain
-
스타일 도메인을 통한 이미지 간 변환은 pixel-to-pixel 대응 없이 로컬이 아닌 전체적으로 모델이 작동하도록 만들기 때문에 많은 표준 image-to-image 변환 프레임워크와 다르다.
-
StyleGAN이 학습한 의미론적 객체의 분리가 계층별 표현 때문이다.
-
Multi-modal generation을 위해서는 표준 image-to-image 아키텍처의 변경이 필요하지만, pSp의 프레임워크는 단순히 Style vector를 샘플링함으로써 이를 지원한다.
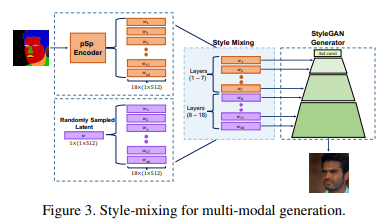
- Vector w를 무작위로 샘플링하고, w를 복제하여 W+에 해당하는 Latent code를 생성함으로써 이루어진다.
- 그 다음 Style Mixing은 계산된 Latent layer의 일부를 무작위로 생성된 Latent layer로 대체함으로써 수행되며, 두 스타일 간의 Blending을 위한 α 파라미터로도 가능하다.
4. Applications and Experiments
- 다양한 Image-to-Image 작업에서 pSp를 평가했다.
4.1 StyleGAN Inversion

- ALAE 방법은 입력 이미지를 정확하게 재구성하지 못한 것을 알 수 있다.
- IDInvert는 이미지 속성을 잘 보존하지만, 여전히 입력 이미지의 정확한 identity와 세부 정보를 보존하지 못한다.
- pSp는 identity를 보존하는 동시에 조명, 헤어스타일, 안경과 같은 미세한 세부 사항도 재구성할 수 있음을 알 수 있다.

- Figure 5는 W+로의 간단한 확장이 결과를 크게 향상시키지만, 여전히 pSp 아키텍처에서 생성된 세부 정보를 보존할 수 없다는 것을 보여준다.
- Figure 6은 재구성 작업에서의 Identity Loss의 중요성을 보여준다.
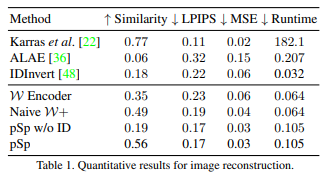
- Table 1은 정량적인 평가를 제시한다. 다른 Encoder와 비교하여 pSp는 Perceptual similarity와 identity 측면에서 원본 이미지를 더 잘 보존할 수 있다.
4.2 Face Frontalization
- 얼굴 정면화 작업은 훈련 데이터 부족으로 인해 Image-to-Image 변환 프레임워크에서 어려운 작업이다.
- 이를 위해 Train 시 두가지 변경 사항을 적용하였다.
- 첫째는 훈련 중에 대상 이미지를 무작위로 뒤집어서 모델이 원본 이미지와 미러링된 이미지 모두에 가까운 이미지를 출력하도록 효과적으로 강요하는 것이다.
- 둘째는 Identity loss의 가중치를 증가시키고 이미지의 외부 부분에 대한 L2 및 LLPIPS loss의 가중치를 줄인다. 이는 얼굴 영역과 얼굴 identity에 비해 배경 영역을 보존하는데 관심이 적다는 사실에 기초한다.

- pix2pixHD는 입력 쌍과 출력 쌍 사이의 대응에 훨씬 더 의존하기 때문에 만족스러운 결과를 얻을 수 없다.
- 이에 비해, pSp는 작업을 성공적으로 처리할 수 있었으며, R&R 접근법과 비슷한 현실적인 정면 이미지를 생성한다.
- 이는 이미지 변환에서 사전훈련된 StyleGAN을 사용하면 Weak supervision에도 시각적으로 만족스러운 결과를 얻을 수 있기 때문에 이점을 보여준다.
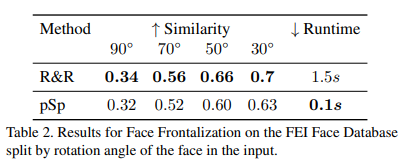
- Table 2는 정량적인 평가를 제공한다.
4.3 Conditional Image Synthesis
- 조건부 이미지 합성은 특정 입력 유형에 따라 조정된 사실적인 이미지를 생성하는 것을 목적으로 한다.
- Sketches 및 Semantic segmentation maps에서 고품질 얼굴 이미지를 생성하는 두가지 조건부 이미지 생성 작업에서 pSp 아키텍처를 테스트했다.
- 두 조건부 생성 작업의 훈련은 Encoder의 훈련과 유사하며, 여기서 입력은 조건부 이미지이고 대상은 해당 실제 이미지이다.
- 추론 시간에 여러 이미지를 생성하기 위해 입력 이미지의 잠재 코드에서 레이어(1-7)를 취하고 랜덤하게 그려진 w 벡터에서 레이어(8-18)를 취하여 미세 수준 특징에 대한 스타일 믹싱을 수행한다.
4.3.1 Face From Sketch
- 현재 손으로 그린 얼굴 스케치를 대표하는 데이터 세트가 없어 자체 데이터 세트를 구성하여 실험을 진행했다.

- DeepFace는 pix2pixHD에 비해 시각적으로 더 만족스러운 결과를 얻지만, 여전히 다양성에 한계가 존재한다.
- pSp는 스케치를 더 잘 일반화할 수 있으며, 얼굴 털과 같은 세밀한 세부 정보를 더 잘 보존하며 다양한 출력을 얻을 수 있다.
4.3.2 Face from Segmentation Map
- Segmentation map에서 얼굴 이미지를 합성하기 위해 pSp를 사용하여 평가한다.
- SPADE와 CC_FPSE는 둘다 pix2pixHD를 기반으로 한다.

- Figure 9에서 pSp를 제외한 모델들은 pix2pixHD를 기반으로 하기 때문에, 유사한 결과를 가진다.
- pSp는 이들에 비해 다양한 자세와 표현의 광범위한 입력에 걸쳐 고품질의 이미지를 생성할 수 있다.
- 또한 Multi-modal 기술을 사용하여 pSp는 단일 입력 의미 맵 또는 스케치 이미지에 대해 동일한 포즈와 속성을 가지지만 다양한 미세 스타일을 가진 다양한 출력을 쉽게 생성할 수 있다.
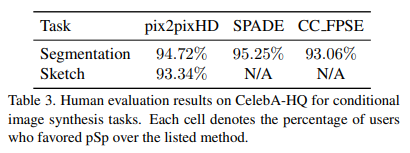
- 위 방법의 시각적 품질을 비교하기위해 인간의 평가를 추가로 수행했으며 Table 3이 그 결과이다.
4.4 Extending to Other Applications
- 훈련 프로세스에 최소한의 변경으로 다양한 추가 작업에 pSp를 적용할 수 있다는 것을 발견하였다.
- Figure 1의 pSp를 사용한 Super-resolution 및 Inpainting 결과의 샘플을 부록 C에 제시된 세부 정보와 결과를 제시한다.
4.5 Going Beyond the Facial Domain
- pSp 프레임워크가 얼굴 영역의 identity loss에 의해 제공되는 장점에 의존하지 않고, 위에서 탐색한 다양한 작업을 해결하도록 훈련될 수 있음을 보여준다.

- Figure 10은 StyleGAN Inversion 및 Sketch-to-image 작업에 대한 AFHQ Cat 및 AFHQ Dog 데이터 세트에 대한 결과를 보여준다.
- 이러한 작업을 위해 두 도메인 각각에 대해 사전 훈련된 StyleGAN-ADA[1] 모델을 사용하고 얼굴 도메인에 사용된 것과 동일한 α 값을 가진 L2, LPIPS 및 정규화 loss만 사용하여 pSp 인코더를 훈련시킨다.
- 위 그림처럼, 조사된 영역으로 잘 일반화할 수 있으며, Style-mixing 접근법을 통해 Multi-modal 합성을 지원하는 동시에 고품질, 정확한 재구성 결과를 얻을 수 있다.
5. Discussion
- pSp는 다양한 Applications에서 괜찮은 결과를 달성하지만, 고려해야할 몇 가지 고유한 가정을 가지고 있다.
-
사전훈련된 StyleGAN을 활용하여 생성되는 고품질 이미지에는 비용이 따른다.
- StyleGAN을 훈련할 때, 이러한 예를 사용할 수 없다면 정면이 아니거나, 특정 표정을 가진 얼굴을 생성하는 것은 어려울 수 있다.
-
pSp의 접근 방식은 많은 작업에서 유리하지만 귀걸이, 배경 세부 정보와 같은 입력 이미지의 세부 정보를 보존하는데 어려움이 있다.
- 이는, Inpainting 또는 초고해상도 같은 작업에서 특히 중요하다.
- Figure 11 참조

6. Conclusion
- 본 논문에서는 최적화 없이 실제 이미지를 W+ Latent space에 직접 mapping하는데 사용할 수 있는 새로운 Encoder 아키텍처를 제안한다.
- Style은 Encoder에서 계층적 방식으로 추출되며, 고정된 StyleGAN Generator(Decoder)의 입력으로 공급된다. 이는 다양한 이미지 간 변환을 해결하기 위한 일반적인 프레임워크이다.
- 단일 번역 작업을 해결하기 위해 일반적으로 전용 아키텍처에 의존하는 이전 작업과 달리 pSp는 다양한 문제를 해결할 수 있으며 Train loss와 방법론에 대한 최소한의 변경만 요구한다는 것을 보여준다.
References
[1] Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. "Training generative adversarial networks with limited data". In Proc. NeurIPS, 2020.
[2] Tero Karras, Samuli Laine, and Timo Aila. "A style-based generator architecture for generative adversarial networks". In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4401–4410, 2019.
[3] Wallace Lira, Johannes Merz, Daniel Ritchie, Daniel CohenOr, and Hao Zhang. "Ganhopper: Multi-hop gan for unsupervised image-to-image translation". arXiv preprint arXiv:2002.10102, 2020.
[4] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. "The unreasonable effectiveness of deep features as a perceptual metric". In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018.
[5] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. "Arcface: Additive angular margin loss for deep face recognition". In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4690–4699, 2019.
