이 글은 논문 Offline Reinforcement Learning as One Big Sequence Modeling Problem에 대한 설명입니다. 논문 원본에 대한 링크는 아래에 적어놓았습니다.
논문 원본 : https://arxiv.org/abs/2106.02039
Abstract
- 자연어 처리(Transformer)와 같은 다른 영역에서 잘 작동하는 High-capacity sequence prediction models이 RL 문제에 대한 효과적인 해결책을 제공할 수 있을 것이다.
- 이를 위해, 본 논문에서는 Trajectory의 분포를 모델링하기 위해 Transformer architecture를 사용하고, Planning algorithm으로 Beam search를 사용했다.
- RL을 Sequence modeling 문제로 접근하면 Design decisions의 범위가 단순화되므로 Offline RL 알고리즘에서의 구성 요소를 제거할 수 있다.
- RL에 대한 이러한 접근이 Long-horizon dynamics prediction, Imitation learning, Goal-conditioned RL, Offline RL에서 SOTA(State-of-the-Art)임을 보여준다.
1. Introduction
- 기존 RL은 Long-horizon 문제를 Model-free RL의 Q-learning, Model-based RL의 Single-step prediction으로 다룬다.
- Actor-Critic은 별도의 Actor와 Critic이 필요하며, Model-based Algorithm은 Predictive dynamics model이 필요하며, Offline-RL은 Behavior policy에 대한 추정이 필요하다.
- 각각의 모델들은 각기 다른 분포를 추정하지만 <State, Action, Reward>를 단순한 Stream of data로 본다면 Single sequence model로 통합할 수 있다.
- Sequence model로 본다면 High-capacity sequence model architecture가 문제를 해결할 수 있고, 결과적으로 Large-scale unsupervised learning의 기초가 되는 scalability의 장점을 얻을 수 있다.
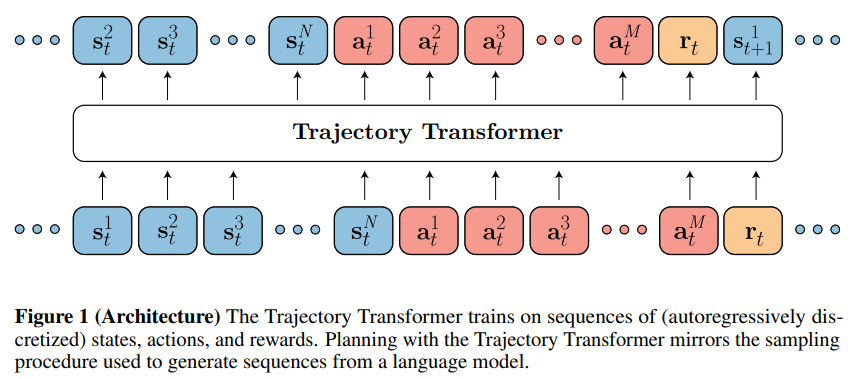
- 본 논문에서 사용한 모델은 Figure 1이며 Trajectory Transformer라고 부른다.
- 이 모델은 Offline-RL 벤치마크에서 좋은 결과를 얻는다. 또한, Decoding 절차의 변형으로 Imitation learning, Goal-reaching method, Dynamic programming과 결합될 경우 Sparse-reward, Long-horizon task에서 SOTA(State-of-the-Art) Planner가 된다.
2. Related Work
Deep networks를 이용한 Sequence modeling의 발전은 LSTM -> Sequence-to-sequence -> Transformer로 발전했다. 이를 RL과 함께 적용한 경우도 많지만 모두 RL의 표준 알고리즘을 그대로 사용했다. 하지만, 본 논문에서는 많은 RL 파이프라인을 Sequence modeling으로 대체하는 것을 목표로 한다.
RL에서는 predictive 모델 (for model-based RL), behaviror policy (for imitation learning), behavior constraint (for offline RL) 등의 다양한 분포들을 학습한다. 그러나 본 논문에서는 State, Action, Reward의 Sequence에 대한 joint distribution을 나타내기 위해 Single high-capacity sequence model을 훈련시킨다.
Trajectory Transformer는 Model-based RL과 유사하지만, ensembles in the online setting, conservatism mechanisms in the offline setting를 명시적으로 다룰 필요가 없다.
Decision Transformer가 거의 동시에 발표되었는데, 이는 보상 조건에 초점을 맞춘 Sequence 예측을 중심으로 한 RL 접근법을 제안했다.
(이전 포스팅에서 Decision Transformer 논문을 리뷰했으니, 궁금하면 그것을 참고하면 될 것같다.)
3. Reinforcement Learning and Control as Sequence Modeling
이 모델을 본 논문에서는 Trajectory Transformer라고 부르고, 이는 Model과 Search 전략이 자연어 처리와 거의 동일하다. 따라서 Architecture의 설계보다는 Trajectory data를 표현하는 방법에 더 관심이 있다.
1. Trajectory Transformer
- Trajectory Transformer에서 Trajectory는 아래와 같다.
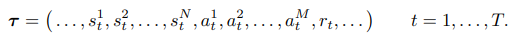
-
Trajectory τ는 N차원의 State, M차원의 Action과 스칼라 값인 Reward로 구성되어있다. 따라서, Trajectory의 길이는 시간을 나타내는 T가 곱해진 T(N + M + 1)이다.
-
논문에서는 2개의 simple discretization approache를 모델에 적용하여 Section 4.2에서 비교한다.
-> Uniform : 주어진 차원에 대한 모든 토큰은 Original continuous space의 Fixed width에 대응한다. 차원별 어휘 크기를 V로 가정할 때, State 차원 i의 토큰은 균일한 간격의 width ((max s(i) - min s(i))/V) 를 포함한다.
-> Quantile : 주어진 차원에 대한 모든 토큰은 Empirical data distribution에서 동일한 양의 probability mass를 설명하며, 각 토큰은 Training set의 모든 V data points 중 1개를 차지한다.
-
Uniform discretization은 연속 공간에서의 유클리드 거리에 대한 정보를 포함한다는 장점을 가지며, 이는 Training data 분포보다 문제의 구조를 더 잘 반영할 수 있다. 그러나 이상치가 발생하는 경우 크기에 큰 영향을 미칠 수 있으며, 많은 토큰이 zero training points가 된다.
-
Quantile discretization을 사용하면 모든 토큰이 데이터에 표현된다.
2. Planning with Beam Search
-
이 절에서는 Imitation learning, Goal-conditioned reinforcement learning, Offline reinforcement learning에 초점을 맞추어 설명한다.
-
그리고, Trajectory Transformer의 planning 기법의 기초를 제공하는 Beam search는 Algorithm 1과 같다.

Imitation learning
-
Imitation learning은 Training data의 분포를 재생산하는 경우인데 이는 Sequence modeling의 기존 목적과 같으므로, 수정없이 Beam Search를 사용할 수 있다.
-
현재의 State로 시작하는 토큰화된 Trajectory를 생성하며, Sequence에서 첫번째 Action이 실행되고, Beam search를 반복되면서 reference behavior를 따라가므로 이는 long-horizon model based variant of behavior cloning과 비슷하다.
Goal-conditioned reinforcement learning
- Transformer에는 예측된 값이 Sequence의 이전 토큰에만 의존하도록 설계된 "causal" attention mask가 있다.
- 이를 Trajectory prediction 맥락에서 보면 물리적 인과관계를 반영하며, 미래가 과거에 영향을 미치지 않도록 한다.
- 그러나, 주어진 미래에 대한 과거의 조건부 확률이 잘 정의되어 있으므로, 이전의 State, Action, Reward 뿐만 아니라 미래의 Context에 대해서도 조건화할 수 있다. 따라서 미래의 Context가 Trajectory의 마지막일 경우 아래와 같은 형태의 확률로 Trajectory를 Decoding할 수 있다.

- 이때 sT를 Sequence의 제일 앞에 붙이는 방법{sT, s1, s2, ..., sT-1} 을 사용해 기존 Transformer의 "causal" attention mask를 그대로 사용함
- 이는 Supervised learning의 goal-conditioned policy, Model-free RL의 Relabeling과 비슷하다.
Offline reinforcement learning
4. Experiments
- 실험평가는 두가지에 초점을 맞춘다.
1. long-horizon predictor로서 Trajectory Transformer에 대한 Standard Dynamics model parameterizations의 비교
2. Offline RL, Imitation learning, Goal-reaching에서 Beam search를 Sequence 모델링 도구의 사용성에 초점을 맞춘다.
1. Model Analysis
Trajectory predictions

Error accumulation

Attention patterns

2. Reinforcement Learning and Control
Offline reinforcement learning


Combining with Q-functions

Imitation and goal-reaching

5. Discussion and Limitations
- 강화학습의 구성요소(Policies, Models, Value functions 등)를 Single sequence model로 통합했고, Beam search 알고리즘과 함께 사용한 결과 Imitation learning, Goal-reaching, Offline RL에서 효과적이었다.
- 기존의 Single-step 예측 모델에 비해 느리고, 리소스가 집약적이라는 단점이 존재해 실시간 제어를 수행할 수 없다. 하지만 현재 Transformer의 경량화가 진행되고 있으니 극복할 수 있을 것이다.
- Continuous data를 discretize해 사용해 기존 conventional continuous dynamics models보다 효과적임을 알 수 있었다.
- RL 문제를 적절한 모델 선택으로 Supervised learning으로 재구성할 수 있다.
References
