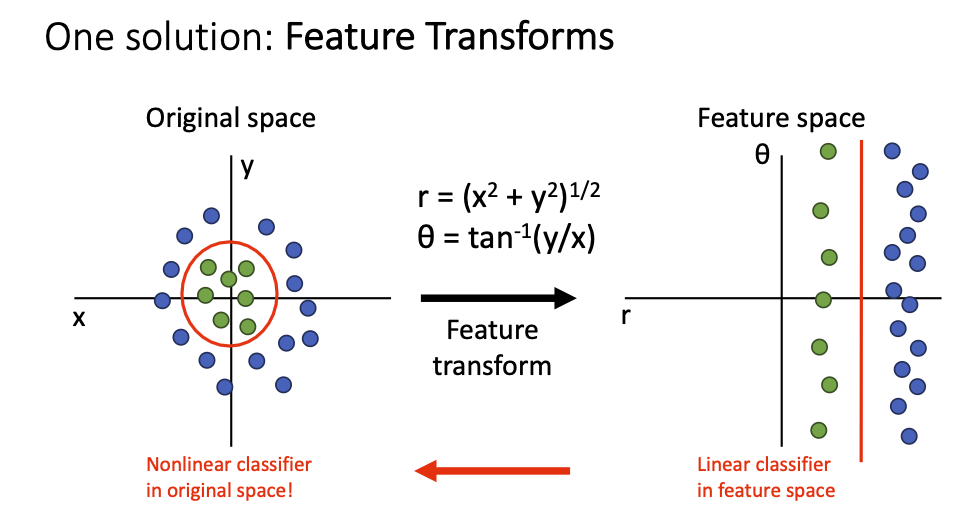
Feature Transforms
- Original space에서 선형함수로 구분할 수 없던 것을 함수 수식 같은 Feature Transform을 통해 새로 만든 변수에서 Linear Classification이 가능하게 만듦
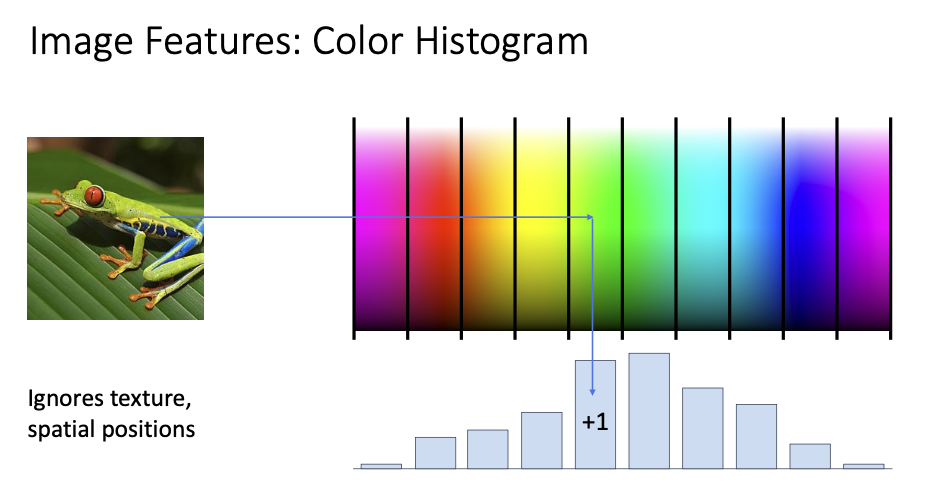
Image에 적용할 수 있는 Features
- Color Histogram
- image의 color hue만 고려
- 해당하는 색상 색에 +1
- Histogram of Oriented Gradients (HoG)
- image의 texture와 position만 고려
- image의 pixel별로 edge 분석

- Bag of Words
- image를 여러개의 조각으로 나눔
- images를 인코딩할 때는 저장된 여러개의 조각에 유사한 것에 +1

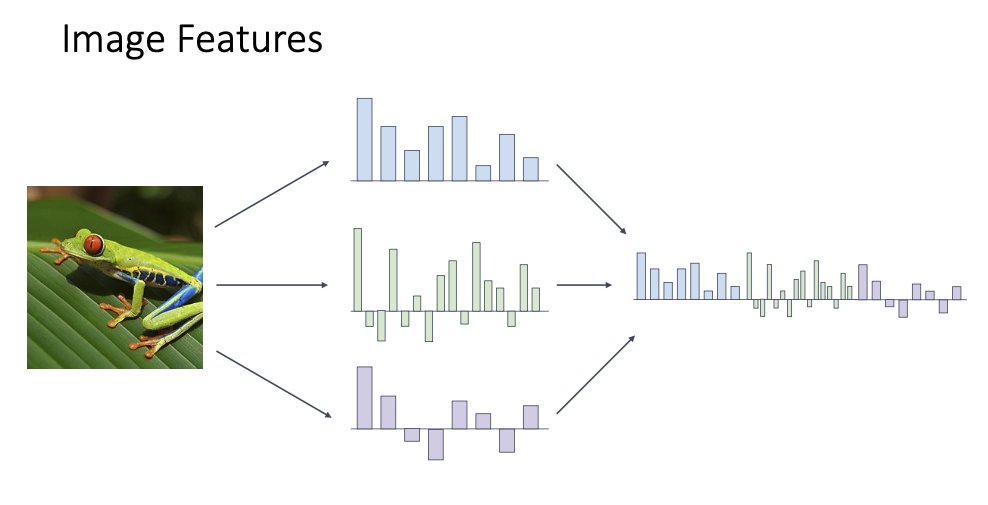
- Image Features의 조합
- Color Histogram, HoG, Bag of Words에서 추출된 features를 조합시켜 활용해도된다.
- 실제로 Resnet?같은 모델이 나오기 전에 2011년 ImageNet challenge에서도 활용됨
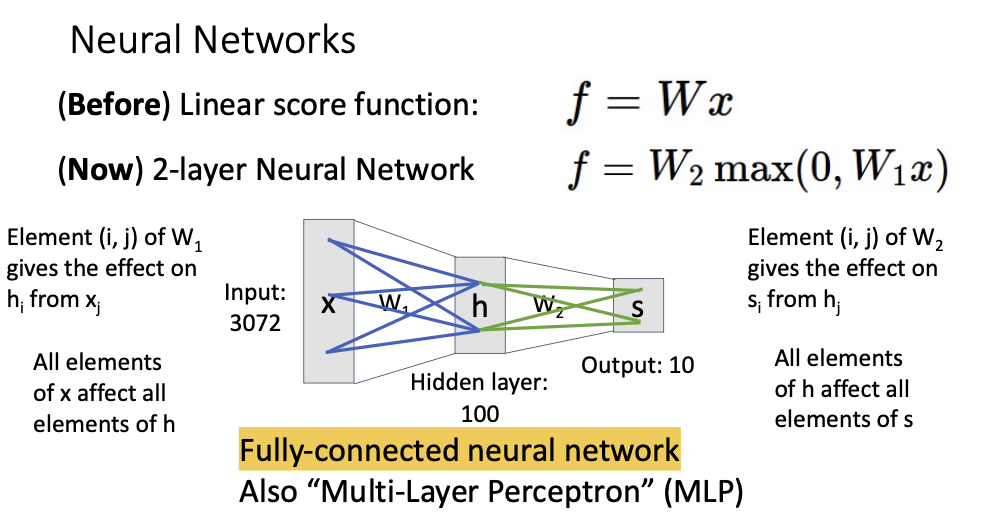
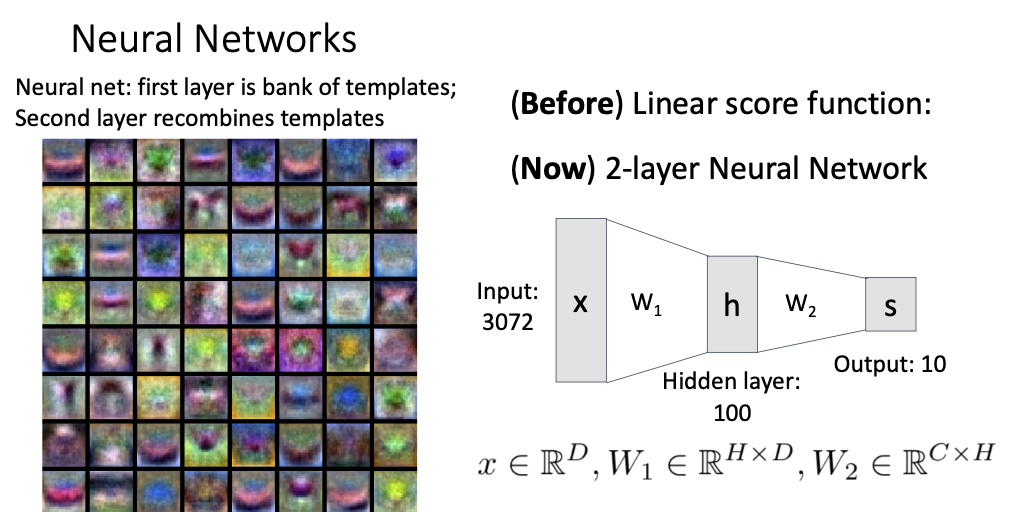
Neural Networks
-
linear classifiers를 여러개 쌓은것임
-
max(0,w1x)인 이유 Activation Function ReLU임

-
모든 노드들이 Fully-connected되어있음
-
linear의 첫번째 layer는 Visual Viewpoint(templates)를 의미
-
linear의 두번째 layer는 첫번째 layer의 templates의 조합으로 class의 다양한 형태를 표현함? ex) 말의 왼쪽 얼굴, 말의 오른쪽 얼굴에 대한 템플릿
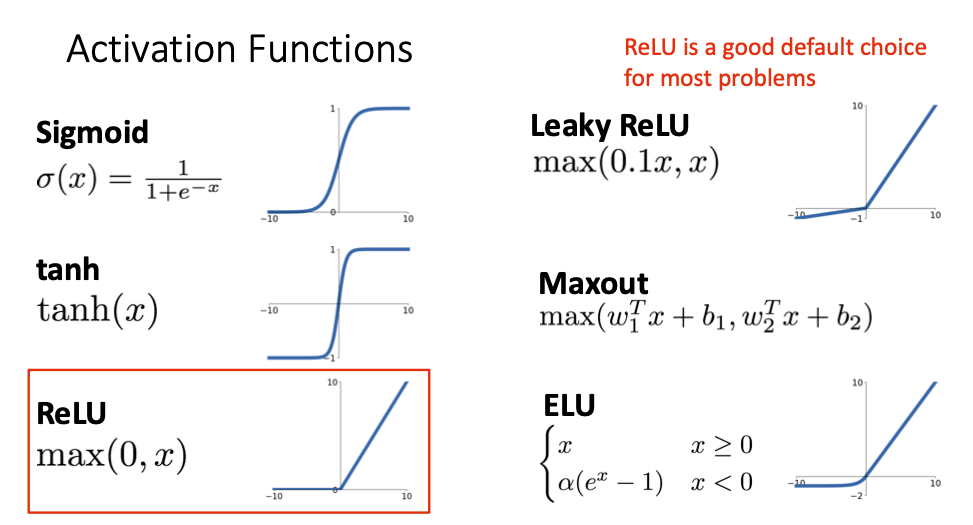
Activation Functions
-
Linear 사이에 넣어주는 Activation Function은 비선형함수임
-
왜 필요한가? activation function이 없으면 아무리 여러개의 hidden layer를 겹쳐도 그냥 단순한 lienar classifier임

-
여러종류의 Activation 함수
-
계산 복잡도나 gradient vanishing, gradient exploding등의 이유를 고려하여 Activation Function을 고르게 됨
-
실제 뉴런의 Firing Rate도 비선형함수의 모습을 취함 (Activation Function도 비선형함수)
-
강의에서는 꼭 실제의 뉴런과 꼭 연관지어서 구현할 중요도는 없다고 했음
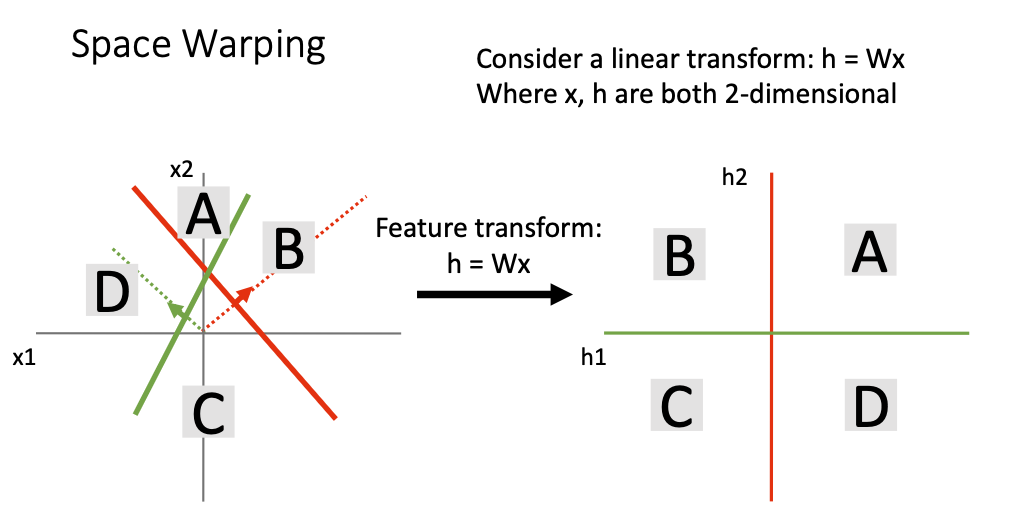
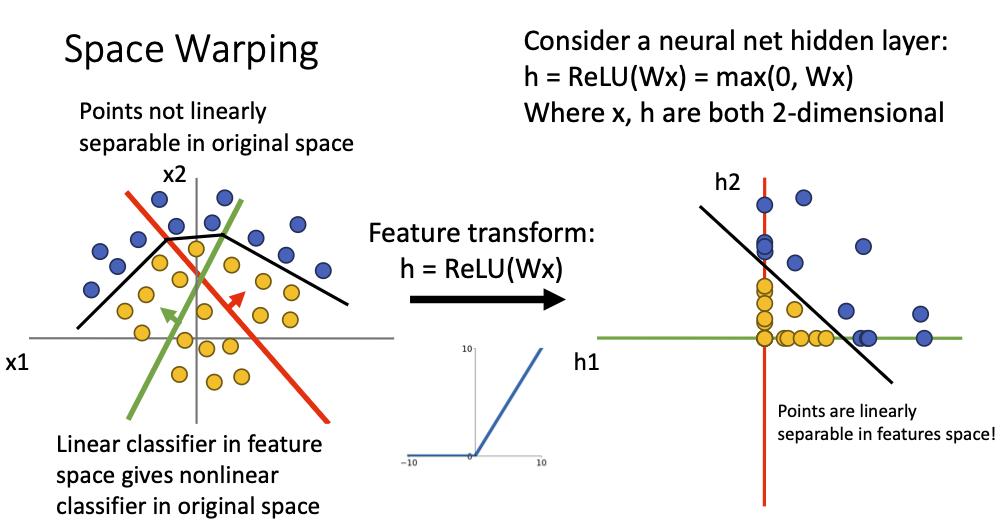
Space Warping
- linear classifier의 geometric point of view를 생각해보면 h1와 h2 새로운 축으로 변환하는 weight W가 있다고 생각
- Relu함수를 적용하면 다음과 같은 모양이되고, feature space에서는 한개의 lienar classifier로 작용하는 것처럼 보이지만, original space에서는 nonlinear classifier로 보임
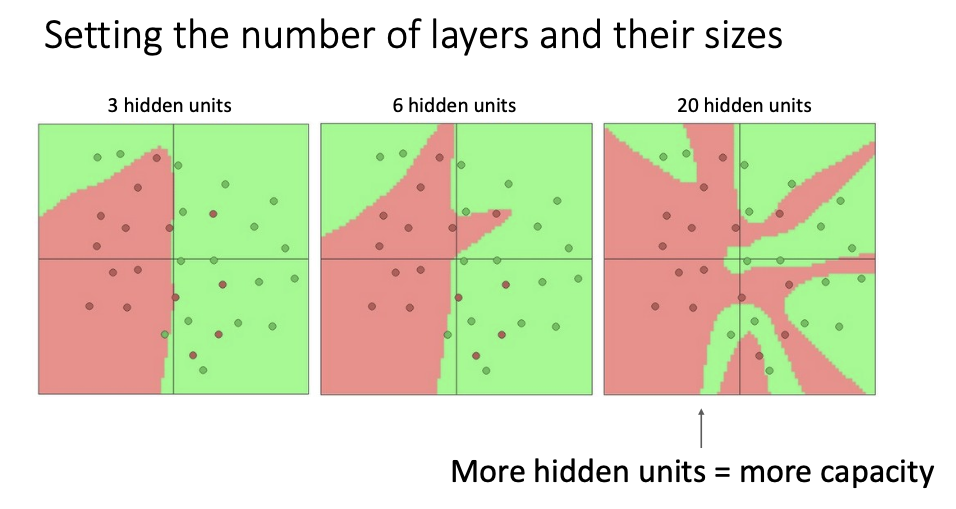
- 여러개의 hidden units을 추가할수록 original input space의 linear가 증가하게 되어 더욱 세세하게 구분할 수 있음
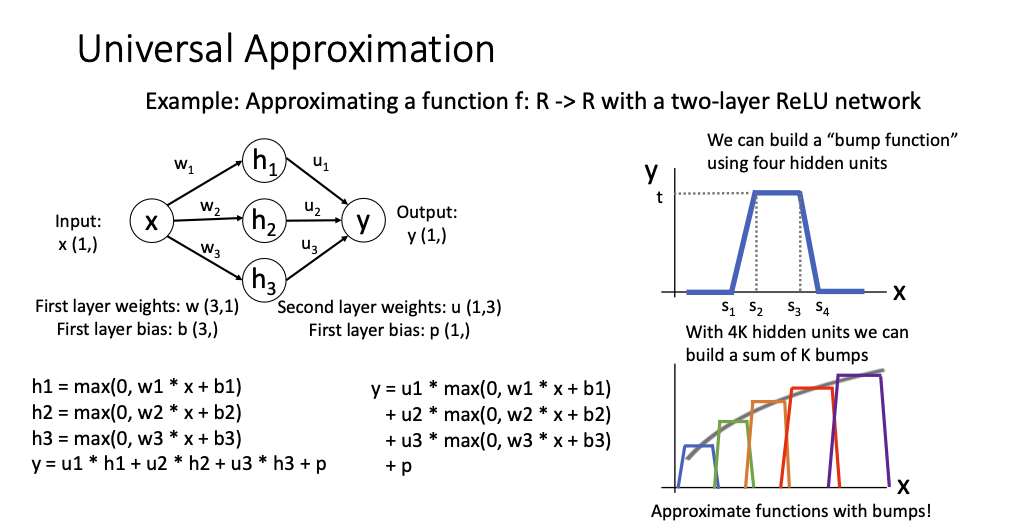
Universal Approximation
- 모든 함수를 표현할 수 있다?
- output y는 shifted ReLU로 만들어지는데 이로 bumped function을 만들고, 이를 통해 함수를 표현?
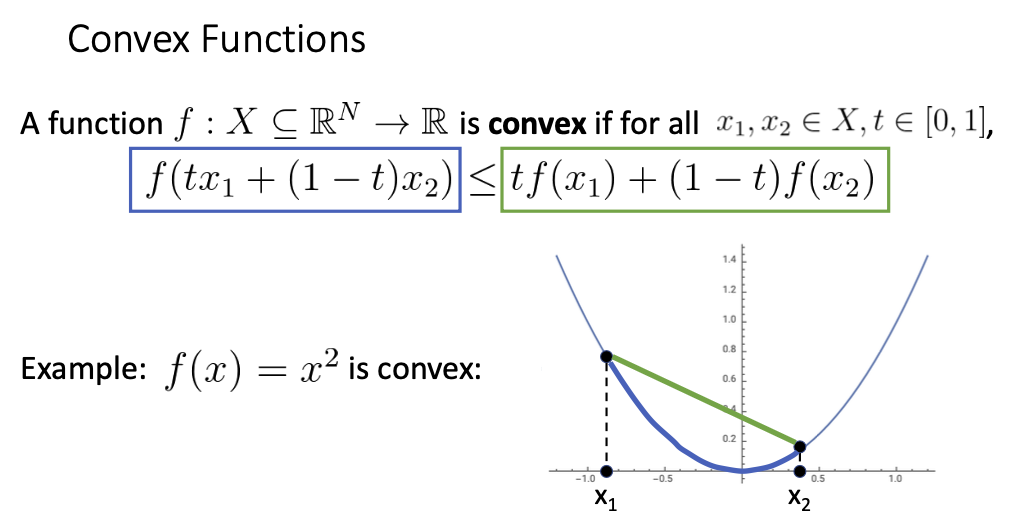
Convex Functions
-
함수의 모든 x1,x2와 모든 0에서 1의 t값에 대하여 다음 수식이 만족하면 convex 함수이고, convex함수는 항상 global minimum을 보장할 수 있음
-
Linear Classifiers: convex함수(Softmax와 SVM)를 최적화함
-
Neural Networks: 대게 nonconvex함수를 최적화해야되기 때문에 local minimum에 빠질 수 있음
