과제를 내주셨다...!
각 제목들은 문제이며 내 스스로 풀어보았다.
pandas 참조
import pandas as pd데이터 읽어오기-1
- TopRichestInWorld.csv 파일 읽어오기
data = pd.read_csv('TopRichestInWorld.csv')
data데이터 읽어오기-2
- TopRichestInWorld.csv 파일 읽어오기
- Industry 열만 사용 /
usecols=["Industry"]사용 - 시리즈화 /
.squeeze()사용
data_industry = pd.read_csv('TopRichestInWorld.csv',usecols=["Industry"]).squeeze()
data_industry데이터 읽어오기-3
- TopRichestInWorld.csv 파일 읽어오기
- col은 Age열 정보를 사용
- index는 Name열 정보를 사용
- 데이터를 시리즈화
내가 푼거)
data_age = pd.read_csv('TopRichestInWorld.csv',usecols=["Age"]).squeeze()
data_name = pd.read_csv('TopRichestInWorld.csv',usecols=["Name"]).squeeze()
data_age_name = pd.Series(data_age, index = data_name)
data_age_name이렇게 풀면 Age가 없어지고 다 결측값으로 나온다 ㅠㅠ
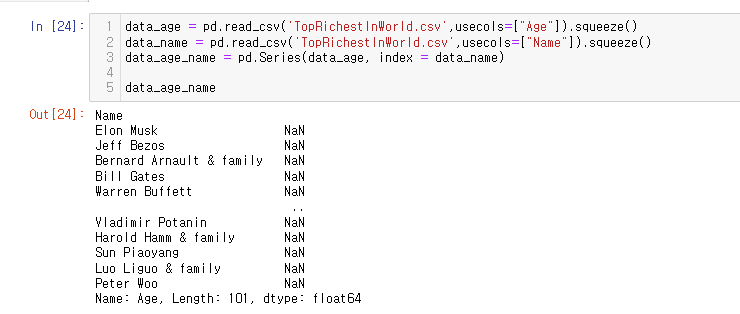
정답!)
data_age_name = pd.read_csv(
'TopRichestInWorld.csv',
usecols=["Age", "Name"],
index_col="Name").squeeze()
data_age_nameindex_col 인자는 처음보는데…
강의를 보니 혼자서 알아보는법을 배우는 부분이라고 한다 ㅎㅎ
index_col : index 부분을 지정하는 인자.
평균 나이가 어떻게 되나요?
- 평균 나이가 어떻게 되나요?
- 소수점 1자리 까지 반올림
data_age_name.mean().round(1)
누가 가장 어리나요?
- 코드로 그 사람 이름이 나오도록 해봅시다.
- 정렬을 사용하지말고 바로 지원하는 메소드를 생각!
- 힌트 : 현재 index에는 이름이 저장되어 있습니다. 때문에 나이가 어린 사람의 인덱스를 찾는다면 이름이 나오는거겠죠?
data_age_name.idxmin()
누가 가장 나이가 많나요?
- 코드로 그 사람 이름이 나오도록 해봅시다.
data_age_name.idxmax()
어린 순으로 정렬해봅시다.
data_age_name.sort_values()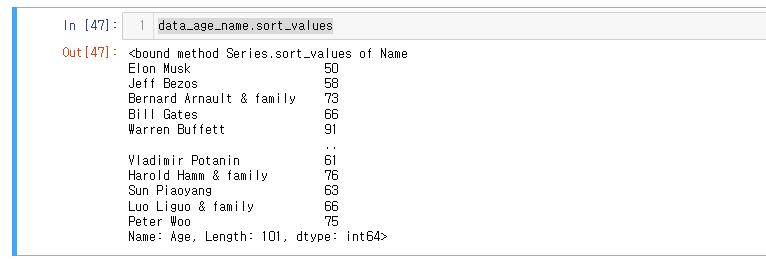
나이 분포가 어떻게 되나요?-1
- 5개로 구분하며 몇 명인지를 파악합니다.
- 비중이 높은 순으로 내림차순 합니다.
data_age_name.value_counts(bins=5).sort_values(ascending=False)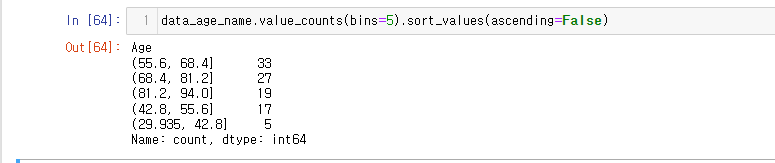
나이 분포가 어떻게 되나요? -2
- 5개로 구분하며
- 퍼센트 비중으로 어떠한지 파악합니다.
- 비중이 높은 순으로 내림차순 합니다.
data_age_name.value_counts(bins=5, normalize = True).sort_values(ascending=False)
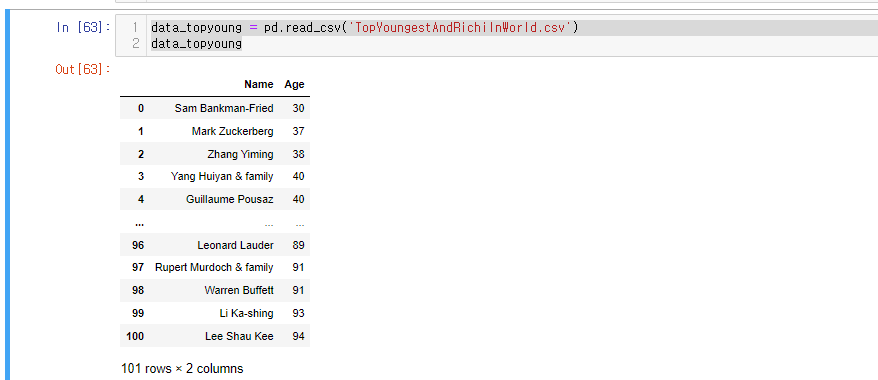
나이가 어린 순으로 새로운 csv를 저장합시다.
a.파일 이름은 TopYoungestAndRichilnWorld.csv
TopYoung = data_age_name.copy() #data_age_name를 copy()해줌.
TopYoung.sort_values(inplace = True)
TopYoung.to_csv('TopYoungestAndRichilnWorld.csv')제대로 저장되었는지 데이터 확인해봅시다.

LV. 1