Kaggle 에서 부자들의 데이터를 가져와서 실습해보자
링크:
100 Richest People In World
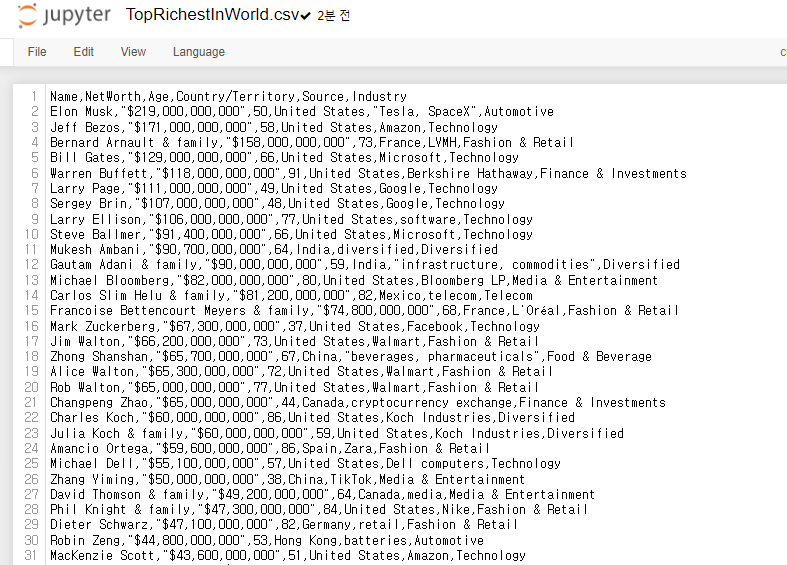
csv 파일이란?
- Comma-Sperated Value
- 컴마(,)로 값을 구분해놓는 방식 다운받은 csv파일을 주피터노트북에서 보면 컴마(,)들로 구분되어 있는것을 확인할 수 있다.
실습 환경 구축
먼저 판다스를 불러온다.
import pandas as pd그리고 파일을 읽어온다.
richest_dataset = pd.read_csv('TopRichestInWorld.csv')
richest_dataset🍯이때 꿀팁!
파일명 앞글자를 작성하고 TAP키를 누르면 자동으로 완성해줌.
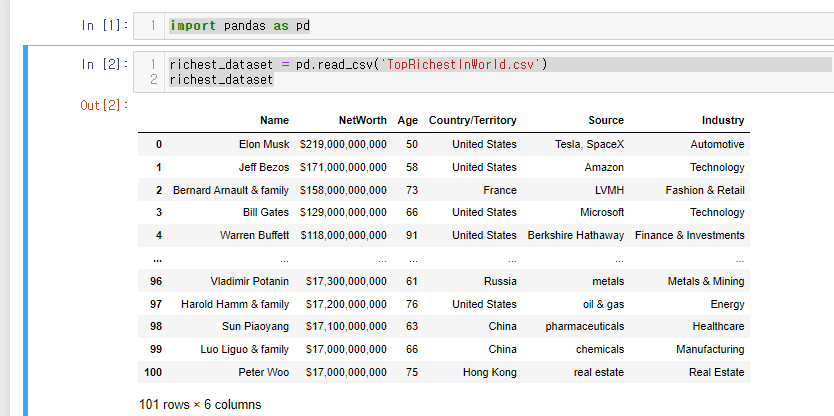
✏️무조건 DataFrame 형식으로 추출된다.✏️
파일을 Series 형태로 불러오기 - .squeeze()
흔하지는 않지만 데이터를 Series형태로 불러올 때가 있다.
컬럼이 너무 많을때에 또는 컬럼을 조절하고자 할 때
pd.read_ 메소드에서 특정 컬럼만을 추출할 수 있는 인자값이 있다.
바로 usecols = 이다.
richest_series = pd.read_csv('TopRichestInWorld.csv', usecols = ['Name'])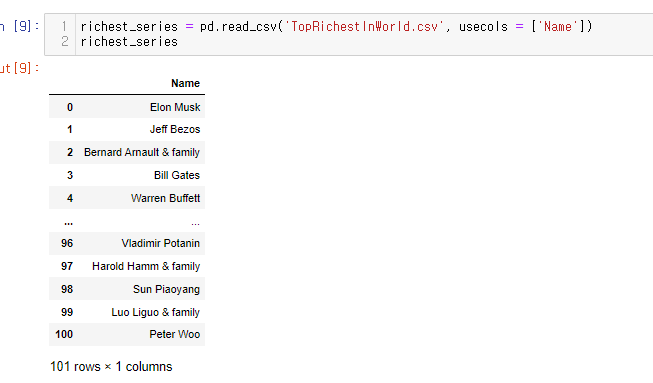
위와 같은 형태로 csv파일을 읽는다면 richest_series 함수에는 Name 컬럼만 들어가게 된다.
이때 뒤에.squeeze()메소드를 붙여준다면 Series로 데이터를 생성할 수 도 있다.
richest_series = pd.read_csv('TopRichestInWorld.csv', usecols = ['Name']).squeeze()
richest_series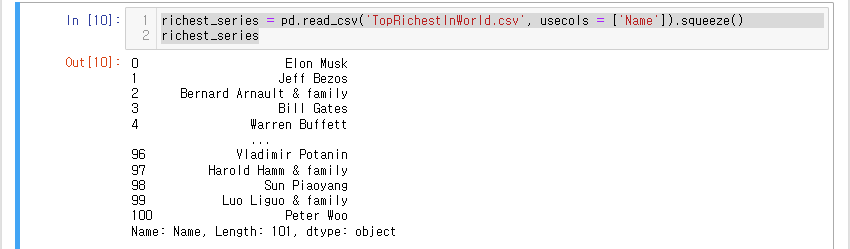
.to_csv()
파일을 저장하고자 할때에는 .to_csv() 메소드를 사용한다.
- richest_series 함수를 기존 파일에 덮어 쓰는 경우 / 기존 이름을 인자값에 작성.
richest_series.to_csv('TopRichestInWorld.csv')- richest_series를 새로운 파일 TopRichestInWorld_New로 만드는 경우
richest_series.to_csv('TopRichestInWorld_New.csv')
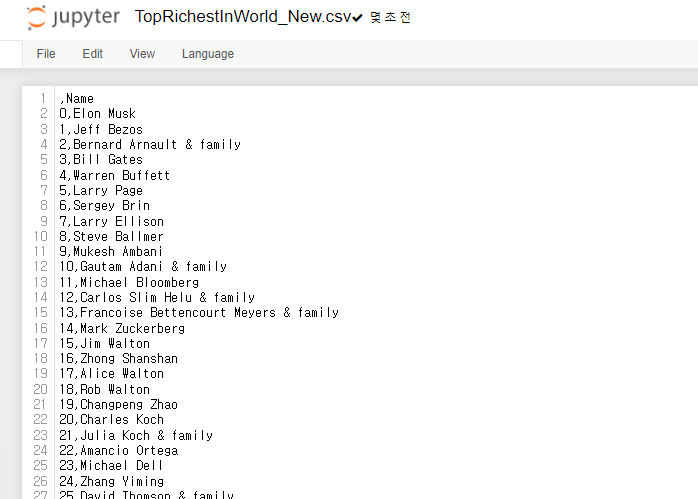
그럼 이름정보만 들어간 새로운 csv 파일이 만들어진것을 확인할 수 있다.
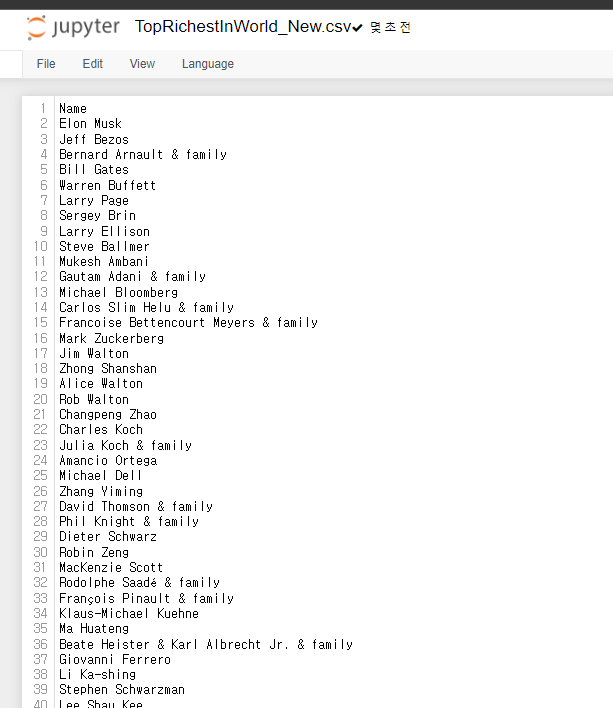
이때 index를 제외하고 파일을 저장할 수 있다.
richest_series.to_csv('TopRichestInWorld_New.csv',index = False)index = False 인자값을 더해주면 인덱스가 없어진다.

LV. 1