****
28일차에서는 DataFrame에 대해서 알아볼것이다.
DataFrame
- Series는 1차원 구조
- DataFrame은 2차원 구조
- axis = 0 : index 방향
- axis = 1 : columns 방향
- 2개 이상의 Series로 구조
DataFrame 생성
먼저 실습 환경을 구축해 준다.
판다스 라이브러리 참조
import pandas as pd딕셔너리로 DataFrame 생성
- member 라는 딕셔너리를 만들어 보겠다.
- 이후 DataFrame() 메소드를 사용하여 member 함수를 데이터프레임화 하였다.
member = {
'Attack' : [111,222,333],
'Defence' : [444,555,666],
'Luck' : [777,888,999]
}
member_df = pd.DataFrame(member)
member_df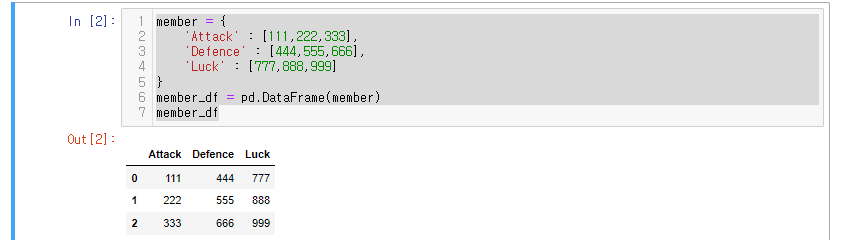
- type 확인
type(member_df) #출력값 : pandas.core.frame.DataFrame딕셔너리에서는 각 한줄 한줄이 Series 가 된다.
AttackSeries
DefenceSeries
LuckSeries
이 시리즈가 모여 데이터 프레임이 생성!
list로 DataFrame 생성
이번에는 다른 방법으로 member_df와 동일한 데이터프레임을 생성해 보자.
data = [[111,222,333],[444,555,666],[777,888,999]]
columns = ['Attack', 'Defence', 'Luck']
member_df = pd.DataFrame(data = data, columns= columns)2차원 데이터이기 때문에
data, columns 인자값을 설정해주어야 된다.
위와 같은 코드 작성 후 member_df를 출력해 보았다.
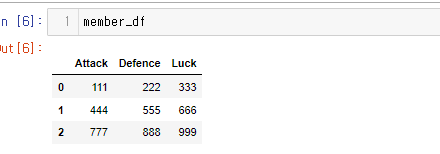
오잉..?! 결과값이 list내에 인덱스에 맞춰서 생성이 되었다.
우리가 원하던 모습처럼 만들기 위해서는 각 대괄호([]) 안의 값을 인덱스 번호를 주어서 생각해야 된다.
0 인덱스 : 111,222,333
1 인덱스 : 444, 555, 666
2 인덱스 : 777, 888, 999
그렇기 때문에 위와 같은 결과가 나오는 것이고, 우리가 원하는 결과값을 얻기 위해서는 아래와 같이 코드를 짜주면 된다.
data = [[111,444,777],[222,555,888],[333,666,999]]
columns = ['Attack', 'Defence', 'Luck']
member_df = pd.DataFrame(data = data, columns= columns)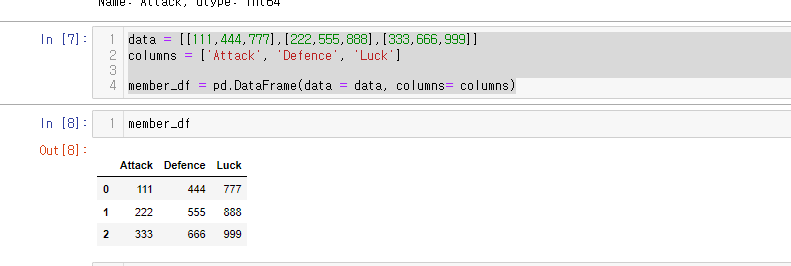
DataFrame - index
데이터 프레임에 index를 생성해보자.
위에서 데이터프레임 생성 코드를 보면 index를 생성해주지 않았기 때문에 Series 때와 마찬가지로 자동으로 인덱스가 생성되었다.
data = [[111,444,777],[222,555,888],[333,666,999]]
columns = ['Attack', 'Defence', 'Luck']
index = ['Spencer', 'Tommy', 'Uriel']
member_df = pd.DataFrame(data = data, columns= columns, index=index)index 라는 함수를 설정후
DataFrame 인자값에 index 설정을 해주었다.

열(Columns) 접근 방법
member_df['Attack']위의 코드처럼 하나의 컬럼만 지정하면 Series 형태로 출력이 된다.

**[주의사항] 이렇게 열 조회하면 안된다.**
- .(dot)을 이용한 접근 방식도 있긴하다.
member_df.Attack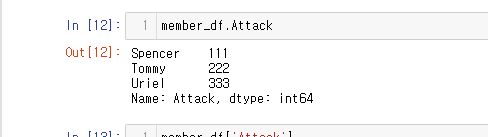
🚫하지만 이방법은 추천하지 않는다.🚫
왜 일까?
.(dot)을 이용한 접근법은 체인형 함수를 사용할때에 혼동할 수 있는 상황이 발생할 수 있다.
예를 들어 컬럼명이 ‘shape’, ‘info’와 같이 있다면 메소드와 동일하기 때문에 컬럼이 호출되지 않는다.
df1 = pd.DataFrame([[1,2,3],[4,5,6]], columns=['shape', 'index', 'info'])
df1
위와 같은 데이터프레임이 있다고 했을때 .(dot)을 이용해서 index컬럼을 조회해 보자.
df1.index
조회가 안되고 index 함수가 사용된다.
그렇기 때문에 컬럼 조회시에는 반드시 [] 대괄호를 사용해서 읽어오자!
csv로 DataFrame 생성
read_csv 사용.
이전에 Series를 읽어오는 것 과 동일하다.
rich_df = pd.read_csv('TopRichestInWorld.csv')
rich_df