실습 환경 구축
import pandas as pd
cols = ['Released_Year', 'Genre','Series_Title','Director','Meta_score', 'IMDB_Rating','No_of_Votes','Certificate','Gross']
movie_df = pd.read_csv('imdb_top_1000.csv')
movie_df = movie_df[cols]
movie_df#연습용 데이터
data = {
'A' : [1,2,None,4],
'B' : [None,None,None,8],
'C' : [9,None,None,None],
'D' : [None,None,None,None]
}
data_df = pd.DataFrame(data)
data_df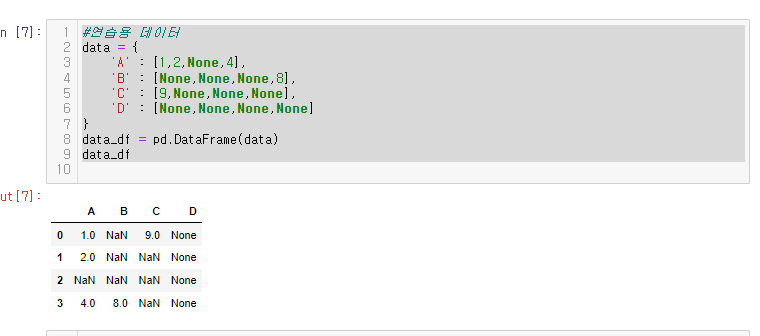
fillna()
결측값을 다른 값으로 변경해준다.
인자값 value= 를 사용
연습용 데이터 data_df 의 결측값을 0으로 바꿔보자.
data_df.fillna(value = 0) 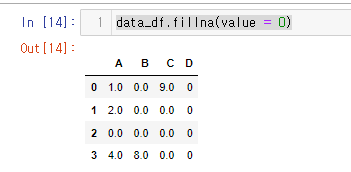
인자값 method= 를 사용
='ffill': 결측치를 이전에 있던 인덱스 레이블 값으로 대체
data_df.fillna(method = 'ffill') 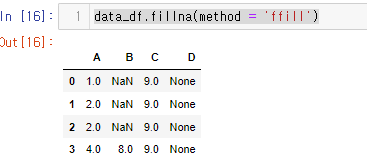
기존 연습용 데이터의 모습과 비교해보면 이전 인덱스 레이블 값을 가져온것을 알 수 있다.
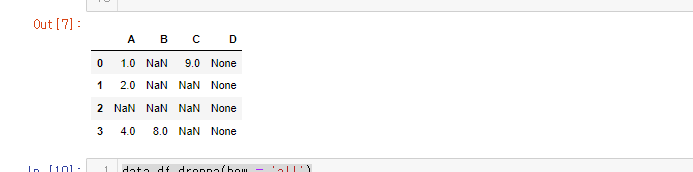
연습용 데이터
=’bfill’: 결측치 다음에 있는 인덱스 레이블 값으로 대체
data_df.fillna(method = 'bfill') 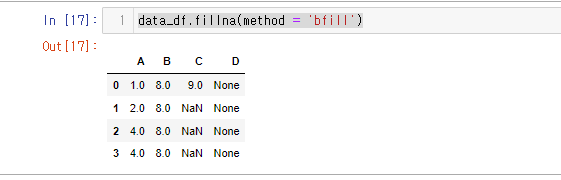
axis = 1 로 작성하여 행을 기준으로 변경할 수 도 있다~
인자값 limit= 을 사용
연속되어 결측치가 나올 경우, 결측치 대체 횟수를 지정한다.
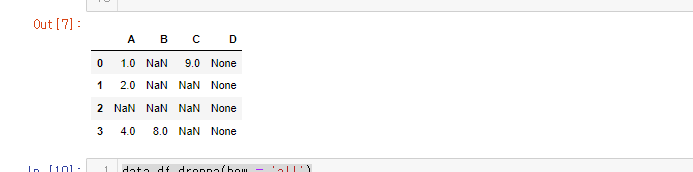
연습용 데이터
연습용 데이터는 원래 이러한 형태이다.
이때 fillna(method = 'ffill') 를 이용하여 결측치를 앞의 값으로 채운다면 C열은 모두 9.0이 될 것이다.
하지만 이때 limt = 을 이용하여 결측치의 변환 횟수를 지정할 수 있다.
data_df.fillna(method = 'ffill', limit = 2) 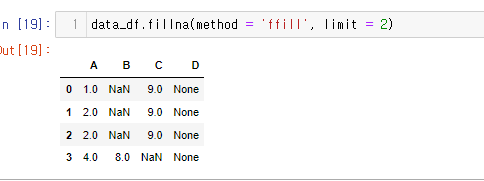
이렇게 하면 2번까지만 ffill 인자가 적용된 것을 확인할 수 있다.
이를 value= 인자와 같은 개념으로 사용할 수 있다.

LV. 1