실습 환경 구축
import pandas as pd
cols = ['Released_Year', 'Genre','Series_Title','Director','Meta_score', 'IMDB_Rating','No_of_Votes','Certificate','Gross']
movie_df = pd.read_csv('imdb_top_1000.csv')
movie_df = movie_df[cols]
movie_df.dropna()
- NaN 유형 데이터를 drop(삭제) 시킨다.
axis 값이 기본적으로 0(인덱스) 이기 때문에 NaN이 있는 인덱스를 다 지운다.
movie_df.dropna()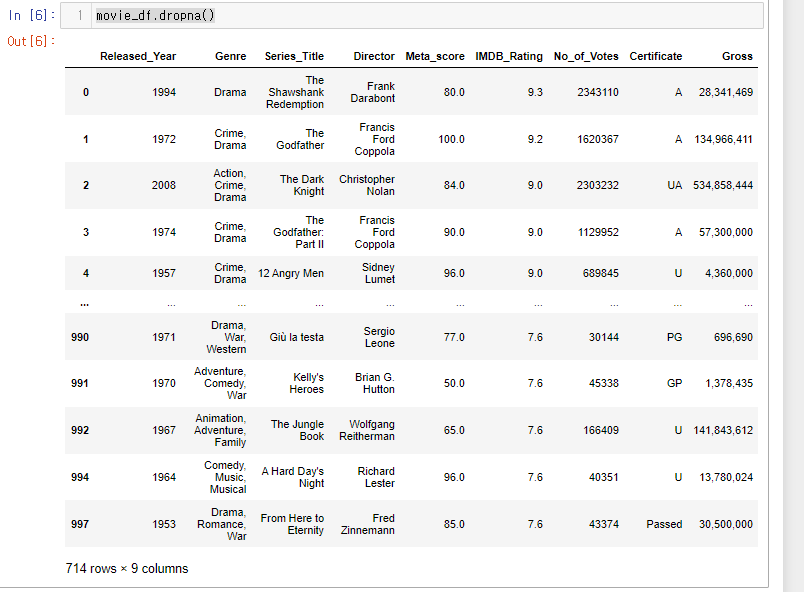
결측치가 있는 인덱스가 지워져 714행밖에 남지 않은 모습.
axis = 1 로 처리하면 결측치를 가지고 있는 컬럼들이 삭제된다.
인자값 : how=
how=
- NA 발견시 제거되는 방식을 설정한다.
- 문법 : how = ‘any’ 또는 ‘all’ 을 사용. 기본값은 any이다.
any:행에 결측치가 하나라도 있다면 제거all:모든 행이 결측치이면 제거
예시
연습용 데이터를 만들어 주었다.
#연습용 데이터
data = {
'A' : [1,2,None,4],
'B' : [None,None,None,8],
'C' : [9,None,None,None],
'D' : [None,None,None,None]
}
data_df = pd.DataFrame(data)
data_df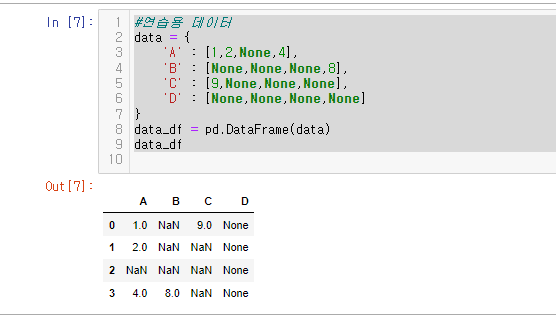
dropna() 사용시
data_df.dropna()
전체 데이터가 삭제 된다.
여기서 dropna(how = 'all') 을 사용해 주면
data_df.dropna(how = 'all')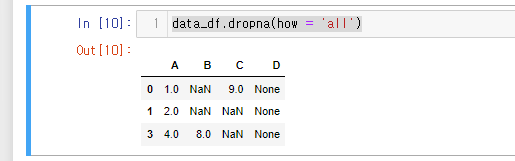
모든 값이 결측치였던 2번 레이블만 삭제가 된다.
인자값 : subset=
subset=
- 특정컬럼의 NA만 확인해준다.
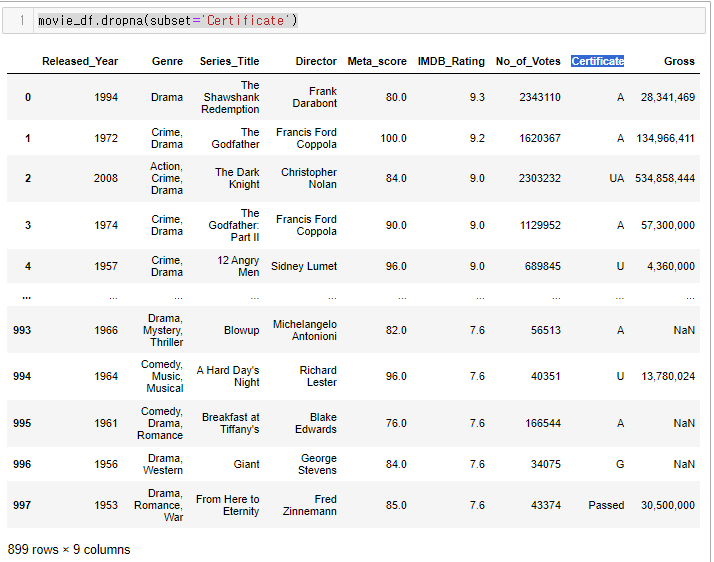
Certificate 컬럼의 결측치만 제거하고 싶다면?
movie_df.dropna(subset='Certificate')해당 컬럼만 제거가 완료 되었다.
리스트화 하여 여러 컬럼을 지정할 수 도 있다.

LV. 1