[28일차]DataFrame활용 - 서로 다른 차원 배열 연산(Matching, Broadcasting)
데브코스_데이터분석- Python Pandas 활용하기[6주차]
Broadcasting이란?
- Pandas에서 DataFrame 또는 Series의 모양이 다른 경우에 연산이 가능하도록 모양을 처리하는 방법을 말한다.
- 크기나 모양이 다를 때의 처리 방식을 정하는 것.(차원이 다를때)
numpy의 Broadcasting 예시를 보고 이해해보자.
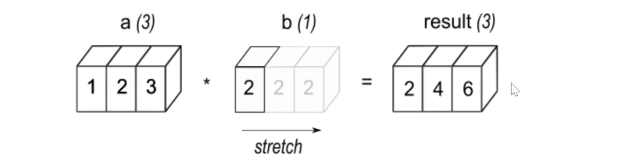
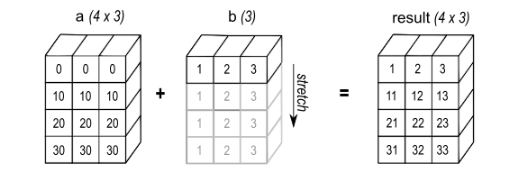
a(컬럼 3개)와 b(컬럼 1개) 차원이 다른 두 값이 있다.
이때 b를 스트레칭 해줘서 a와 동일하게 가상의 array를 확보해 결과값을 도출해준다.
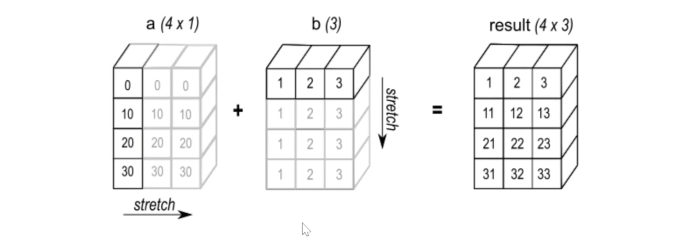
방향 자체를 열로 다르게 스트레칭 해줘서 결과값을 도출할 수 있다.
Broadcasting 비교 - Numpy vs pandas
Numpy
Numpy는 라이브러리임으로 호출을 해줘야 된다.
import numpy as np
Numpy로 레이블을 만들고 연산을 해보겠다.
# numpy Array로 할 때
a = np.array([1.0, 2.0, 3.0])
b = np.array([2.0,2.0,2.0])
이번엔 b의 값을 2.0하나로만 만들어서 진행해보자.
# numpy Array로 할 때
a = np.array([1.0, 2.0, 3.0])
b = np.array([2.0])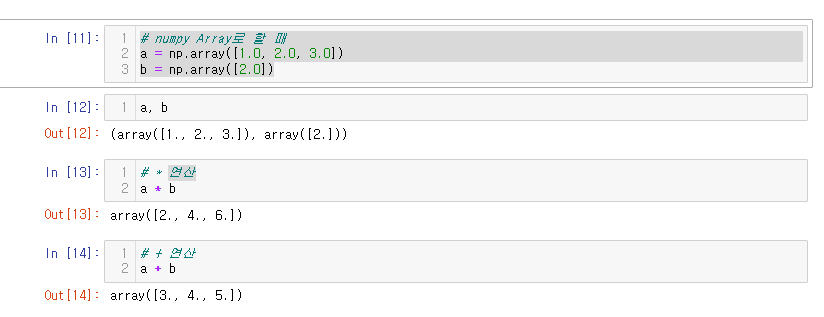
Broadcasting 으로 스트래칭 되어 동일한 결과가 나온다.
pandas
판다스로 시리즈를 만들고 진행해보자
# pandas Series로 할 때
a = pd.Series(data = [1, 2, 3])
b = pd.Series(data = [2,2,2])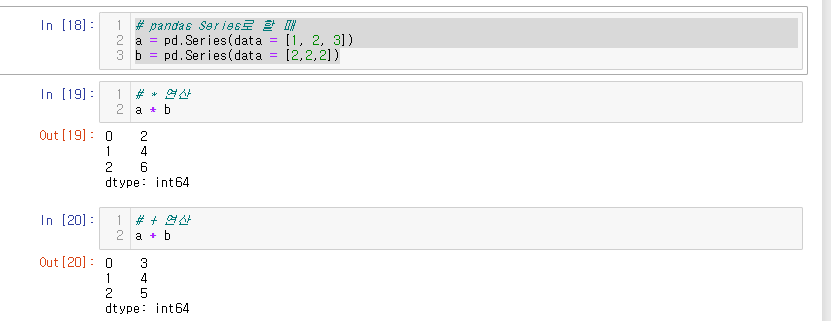
이번에는 b값을 2하나만 남겨두고 진행해보자.
# pandas Series로 할 때
a = pd.Series(data = [1, 2, 3])
b = pd.Series(data = [2])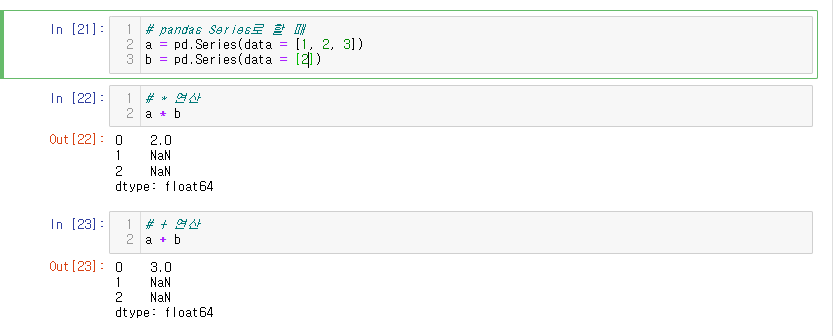
Broadcasting으로 오류 없이 결측치로 처리한다.
정리
- numpy는 스트레칭 방식으로 모두 계산
- pandas는 각각 처리하고 반영이 어려운 곳은 결측치로 처리하는 방식
Pandas의 Broadcasting
위 처럼 결측치 없이 계산을 하려면 Matching도 함께 해야 된다.
행렬 크기가 다를 때
결측치가 있는 데이터 프레임을 만들어 보자.
# Case1. 크기가 다른 Series를 DataFrame시킬 때
s1 = pd.Series(data = [1, 2, 3], index=['a', 'b', 'c'])
s2 = pd.Series(data = [4, 5, 6, 7], index=['a', 'b', 'c', 'd'])
s3 = pd.Series(data = [8, 9, 10], index=['a', 'b', 'd'])df1 = pd.DataFrame(
data = {
'1열': s1, '2열': s2, '3열': s3
}
)
df2 = pd.DataFrame(
data = {
'2열': s2
}
)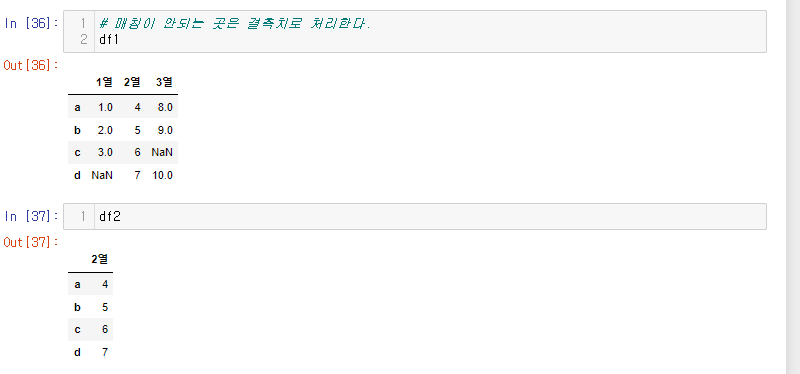
행의 수는 같지만 컬럼 갯수가 다른 두 데이터 프레임을 가지고 연산을 해보자.
1.두 데이터 프레임을 빼보자.
# Case2. 모두 DataFrame이고 행렬 크기가 다르나 동일한 열이름이 있는 경우 사칙 연산은?
df1 - df2
두 데이터 프레임에 있는 2열 컬럼의 값만 연산 되고 매칭이 안되는 열은 모두 결측치로 나온다.
즉! pandas에서 차원끼리의 연산은 컬럼명을 기준으로 함!
차원이 다르고 행렬 크기가 다를 때
차원이 다른 Serise와 DataFrame을 빼면 어떤 값이 나올까?
컬럼 하나만 있던 df2를 시리즈화 후 연산해보았다.
s4 = df2.squeeze()
s4-df1
그 결과.. 엉망진창으로 나온다!!!
🔎왜일까?
일단 컬럼명이 다 다르기때문이다.
시리즈는 차원이 1차원이기 때문에 시작점과 끝점만을 가지고 있다.
그렇기에 컬럼명이 동일하지 않는다면 모든 축을 계산하게 된다.
이럴때는 축을 지정할 수 있는 axis 를 이용해서 진행해야 된다.
sub() 함수 를 이용하여 뺄셈을 해보자.
시리즈나 데이터프레임을 뺄 때 사용하는 함수
구문 : .sub(Series(), axis)
axis를 인덱스 기준으로 두었기 때문에 a,b,c,d의 인덱스가 동일하면 결과값을 내어줄 것이다.
df1.sub(s4, axis = 'index')
s4가 스트레칭이 일어났다…!!!
아래 기존 데이터를 보고 한번 이해해보기를..

df2가 시리즈화 후 데이터프레임과 차를 뒀을때 스트레칭 후 값을 연산하게 되었다.
왜 그럴까?
시리즈는 1차원으로 이뤄져있기 때문에 스트레칭을 가질 수 있다고 한다.
데이터 프레임은 불가능!
행의 크기가 다를 때
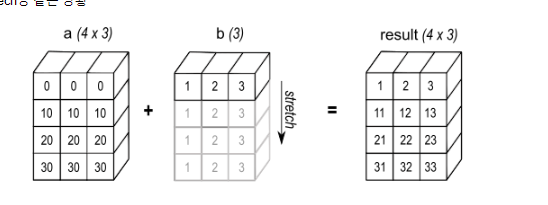
위와 같은 그림처럼 컬럼은 같지만 행의 크기가 다를때 연산을 진행해 보자.
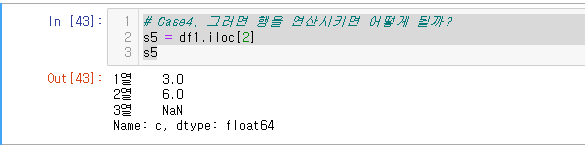
# Case4, 그러면 행을 연산시키면 어떻게 될까?
s5 = df1.iloc[2]
s5df1의 한 인덱스만 가져와 준다.
이후 sub() 메소드로 두 값을 빼보자.
df1.sub(s5)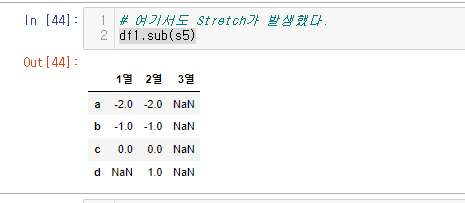
스트레칭이 이루어졌다.
정리
즉, pandas에서 numpy와 같이 스트레칭 연산을 처리하기 위해서는
- 데이터를 1차원 줄여 시리즈화 해야된다.
- 축설정을 해 아래와 같은 그림의 형태로 재배치한다.(컬럼이 동일하게)
축 설정 메소드
| 연산자 | 메소드 | 사용 예시 |
|---|---|---|
| + | add() | df.add(row, axis='columns'), df.add(column, axis='index') |
| - | sub() | df.sub(row, axis='columns'), df.sub(column, axis='index') |
| * | mul() | df.mul(row, axis='columns'), df.mul(column, axis='index') |
| / | div() | df.div(row, axis='columns'), df.div(column, axis='index') |
실습활용
타이타닉 데이터를 가지고 실습을 통해 Broadcasting을 이해해보자.
cols = ['name','fare','survived']
titanic = pd.read_excel('titanic3.xls',usecols=cols)
titanic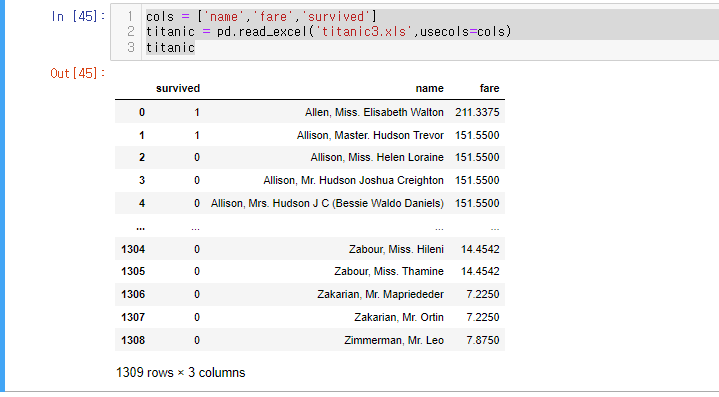
해당 데이터 프레임이 있다고 하자.
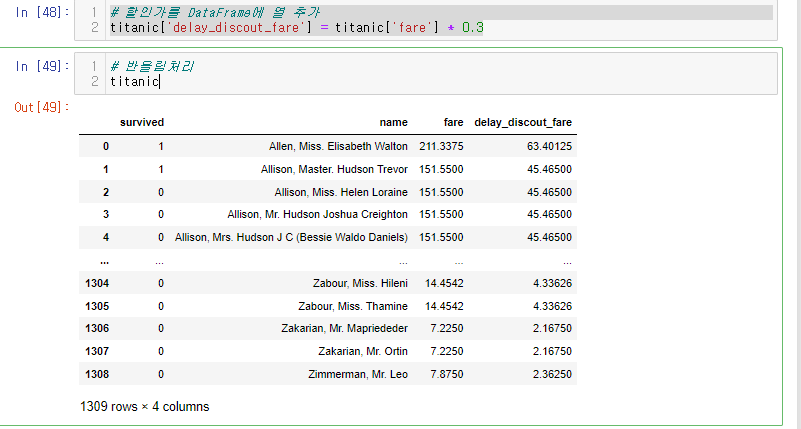
이때 출항이 늦어져서 30% Discount 하는 열을 추가해보자.
계산을 먼저해보자.
titanic['fare'] * 0.3위의 연산은 차원이 다르기때문에 계산이 안되지만 Broadcasting을 통해 계산을 하게 도와준다.
이제 이 값을 열을 추가해주면 끝!
# 할인가를 DataFrame에 열 추가
titanic['delay_discout_fare'] = titanic['fare'] * 0.3