인덱스 넘버 개념을 사용할 수 있는 iloc 을 이용해서 데이터를 추출해보자.
실습 환경 구축
import pandas as pd
cols = ['name', 'sex', 'age', 'pclass', 'fare']
titanic = pd.read_excel('titanic3.xls',usecols=cols)
titanic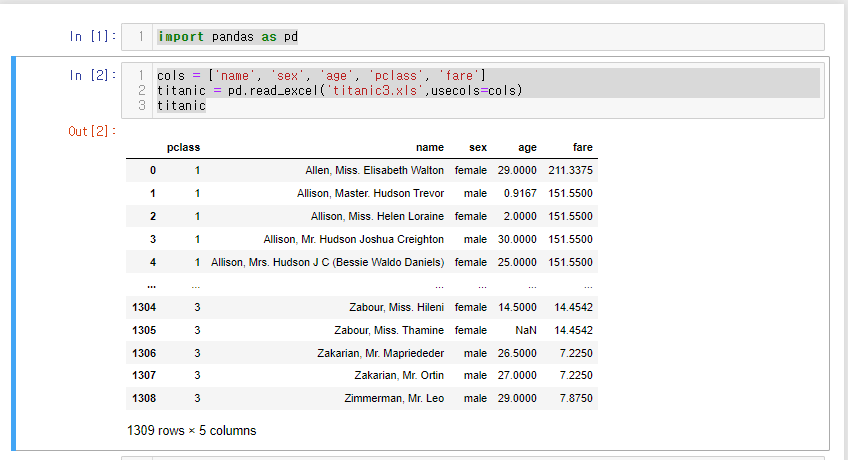
.loc 와 .iloc 의 차이
두 차이는 계속해서 말했듯이 인덱스 레이블과, 인덱스 넘버링 차이이다.
그 차이를 알기 위해 0번 레이블을 삭제 후 진행해 보자
titanic.drop(labels=0, inplace = True).loc 의 경우 오류가 뜬다.
0번 레이블이 없어졌기 때문에.
titanic.loc[0]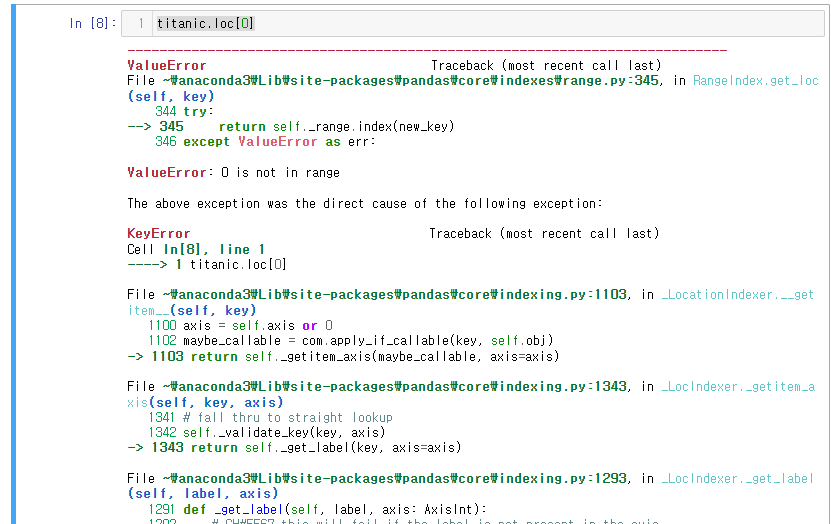
.iloc의 경우 0번째 인덱스를 가져오는 것을 볼 수 있다.
titanic.iloc[0]

iloc은 지양하는 것이 좋다~
.loc 과 동일하게 사용 가능하며
파이썬과 동일하게 .iloc[-1] 로 마지막 값을 가져올 수 있다.
보통 하나의 컬럼만 추출하면 Series 형태로 추출이 되었다.
그렇다면 특정 값만 추출하면 어떻게 추출이 될까?
스칼라
titanic.iloc[0,1]
0번 인덱스의 1번 컬럼 값을 가져와 봤다.
이처럼 단일 값 형태로 가져오는 것을 ‘스칼라’ 라고 한다.
시리즈를 한단계 축소한 개념.
(데이터프레임을 한단계 축소하면 시리즈이다.)
정리!
iloc은 파이썬의 인덱스와 같은 개념으로 적용하기 때문에 편하게 사용할 수 있다.- 하지만 유의미하고 명확하게 사용 되는건
loc- ‘특정 누구를 찾는다’ 라고 할 땐
loc이 유리하기 때문 - 정렬을 하다보면 인덱스 넘버링은 바뀌기 마련이다.
- ‘특정 누구를 찾는다’ 라고 할 땐
- 때문에 ‘특정 행에서 특정 처리를 한다’ 는 상황은 가능한
loc을 지향하자.

LV. 1