29일차에서 아주 중요한 내용!
**DataFrame심화 - 멀티인덱싱(Multi-indexing)**
**멀티인덱싱이란 인덱스가 여러개 라는 의미를 가지고 있다.**
멀티인덱스? 멀티인덱싱?
- https://pandas.pydata.org/docs/reference/api/pandas.MultiIndex.html#pandas.MultiIndex
- 하나 이상의 인덱스 레벨을 가지는 인덱스 구조.
- 데이터프레임이나 시리즈의 다차원적인 인덱싱을 지원하기 위해 사용.
- 멀티인덱스로 인해 데이터를 계층적(hierarchical)으로 조직화. 레벨링
- 다양한 차원(Multi-level)에서 데이터에 접근 가능.
- 멀티인덱스 생성은 데이터프레임 또는 시리즈를 생성할 때 인덱스를 array같은 형태로 지정한다.
실습 환경 구축
import pandas as pd
customers = pd.read_csv('marketing_campaign.csv', sep='\t')
customers멀티인덱스 설정 방법
파일을 불러 올 때 인덱스를 두 개 이상으로 불러오기.
'ID','Marital_Status' 를 인덱스로 불러온다.
customers = pd.read_csv('marketing_campaign.csv',sep='\t',index_col = ['ID','Marital_Status'])
customers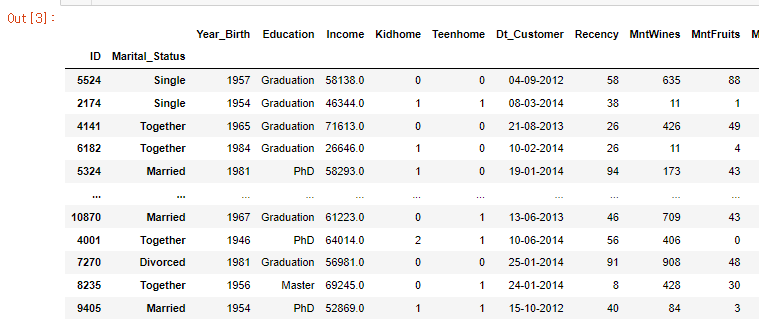
**set_index()로 인한 멀티인덱스 설정**
customers.set_index(['ID','Marital_Status'], inplace=True)
customers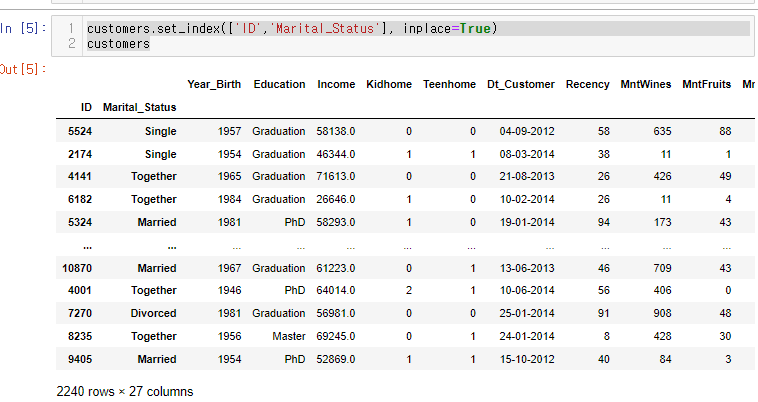
이렇게 멀티 인덱스를 설정하게 되면 index는 MultiIndex로 반환된다.
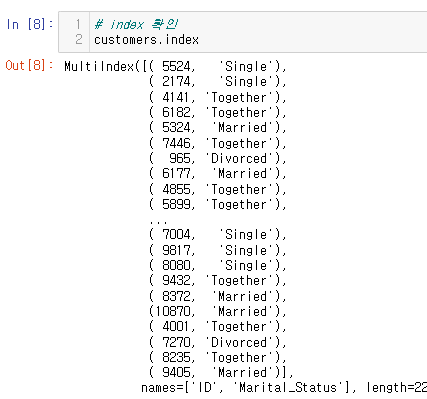
이 때 index의 순서를 level이라고 칭한다.
위의 데이터 프레임은 ID가 0레벨, Marital_Status는 1레벨이다.
**.get_level_values(level)**
**.get_level_values(level) 메소드로 인덱스를 따로 조회할 수 있다.**
customers.index.get_level_values(0)
**.swaplevel()**
인덱스 레벨을 스왑! 인덱스 순서를 변경해주는 메소드
customers = customers.swaplevel()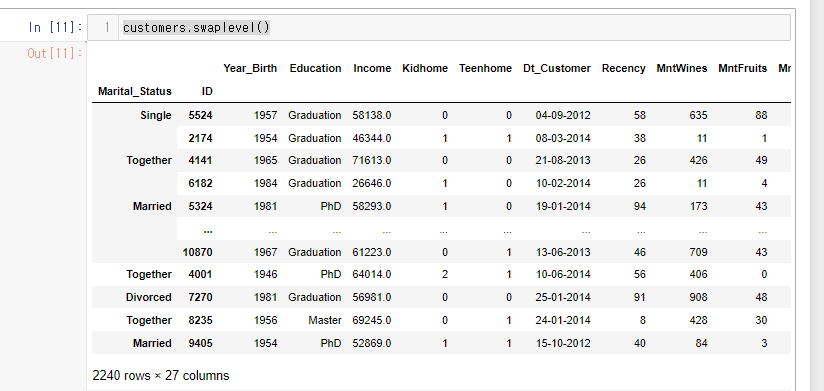
레벨이 변경됨.
음.. 인덱스 정렬을 좀 시켜주자.
# index가 섞여있으니 정렬
customers.sort_index()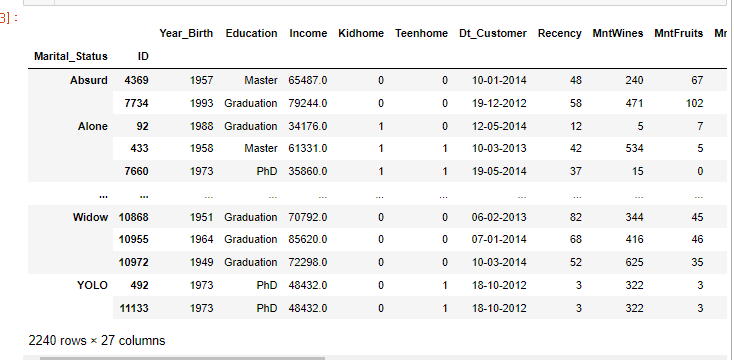
굳~
**멀티인덱스를 활용해 조회하기**
멀티인덱스를 사용하는 이유는 결국에 조회이다.
데이터를 얼마나 쉽게 조회할 수 있게 되는지 실습을 통해 확인해 보자.
먼저 문법을 보겠다.
dp.loc[level0,level1,컬럼명]위와 같은 문법이다.
customers.loc['Single']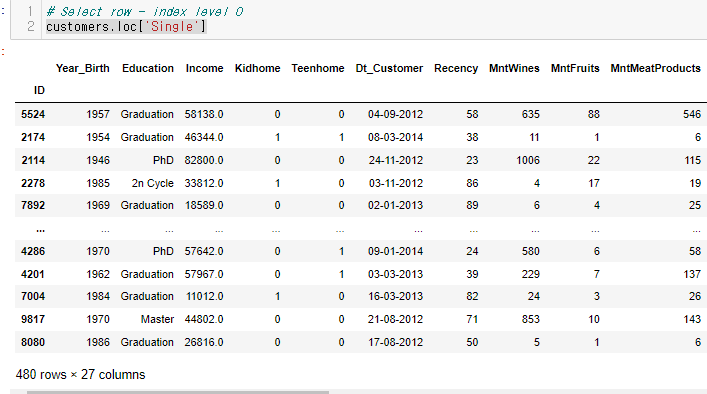
해당 코드로 Single 인 사람들의 정보를 아주 쉽게 가져올 수 있다.
하지만 이런식의 조회는 level0에 해당하는 인덱스만 가능하다. level1과 컬럼명은 스킵한 형태로 작성.
또, 인덱스가 두개 이기 때문에 아래와 같이 사용할 수 도 있다.
customers.loc['Single',5524]싱글 중 id가 5524인 사람의 정보!
컬럼을 확인할 때에는 아래와 같이 인덱스를 튜플 형태로 사용하면 된다.
customers.loc[('Single',5524), 'Income']싱글 중 id가 5524인 사람의 Income, Year_Birth 데이터가 추출 된다.
슬라이싱(:)을 이용한 인덱스 여러개 값 조회
1. 2개의 인덱스를 조회할 때 주의점(컬럼 슬라이싱 생략)
아래의 데이터를 조회해 보자.
.loc[([lv1_labels], [lv2_labels])]
'Single', 'Alone', 'Absurd', 'YOLO'
5524, 2114, 92, 4369, 11133
customers.loc[(['Single', 'Alone', 'Absurd', 'YOLO'],[5524, 2114, 92, 4369, 11133])]튜플 처리로 각 인덱스 값을 넣어준다.
하지만 이렇게 넣으면 에러가 발생한다.
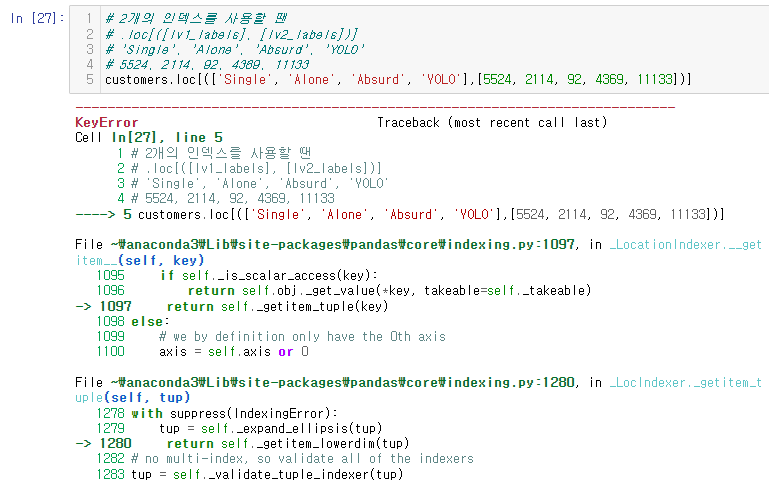
이는 사실 인덱스를 조회시 컬럼을 지정하는 칸이 있기 때문이다.
customers.loc[(['Single', 'Alone', 'Absurd', 'YOLO'],[5524, 2114, 92, 4369, 11133]),:]위의 코드처럼 맨 끝에 : 이게 생략이 된거다. 그렇기 때문에 저 부분도 있다는 듯 , 를 하나 더 붙여주면 코드가 실행된다.
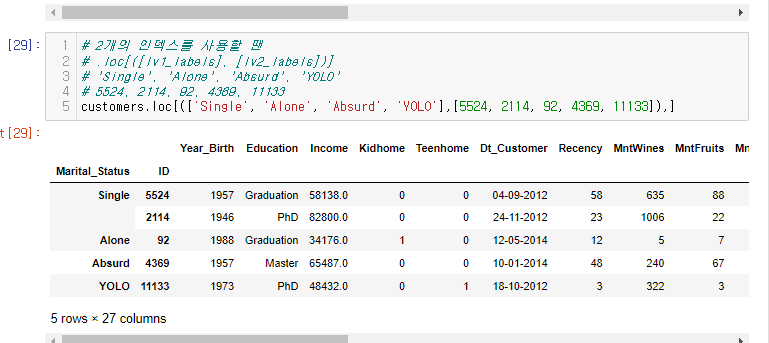
✏️처음 말했던 아래 문법을 잊지말고 각 인덱스와 컬럼을 넣어주는 연습을 하자.
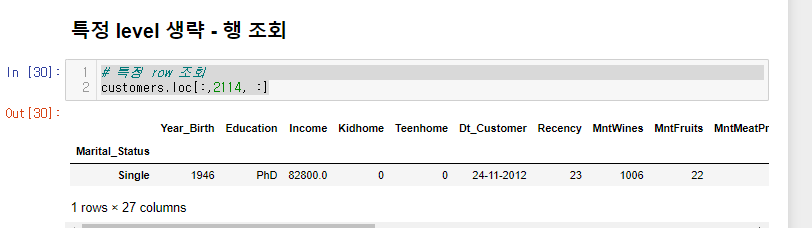
dp.loc[level0,level1,컬럼명]2. **특정 level 생략 - 행 조회**
# 특정 row 조회
customers.loc[:,2114, :]레벨 0(Marital_Status) 인덱스는 전체를,
레벨 1(ID) 인덱스는 2114의 전체컬럼을 가져올거야. 라는 코드!
3. **특정 level 생략 - 행과 열 조회**
문법적으로 맞는 것 같은데 오류가 뜨는 코드가 있다.
customers.loc[:, 2114, 'Income']“0번 레벨 인덱스 전체에서
1번 레벨 인덱스 2114번 중
Income 컬럼만 가져와라”
하는 코드이다.
문법적으로는 괜찮은거 같은데 이는 `IndexError: list index out of range` 를 반환한다.
그럼 아래와 같이 수정하면 괜찮을까?
customers.loc[(:, [2114, 92]), 'Income']인덱스 부분을 튜플로 묶은 뒤 실행해 보았다.
여기서는 `SyntaxError: invalid syntax` 에러를 반환한다.
이는 사실 : 이 부분으로 인해 발생하는 에러이다.
✏️해결방법은 아래와 같다.
slice()메소드 사용
customers.loc[(slice(None), [2114,92]), 'Income']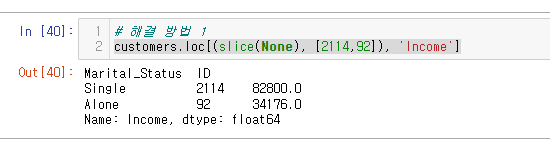
실행이 잘 된다.
- pandas의 IndexSlice를 사용
customers.loc[pd.IndexSlice[:,2114], ['Income','Kidhome']]
추출하고자 하는 인덱스와 컬럼을 리스트 형식[] 으로 넣어준다.
🚫멀티인덱싱 할 때에는 이처럼 추출하는 방식이 상당히 까다롭다.
때문에 잘 찾아서 익숙해지는 연습을 해보자.
