Pandas 참조
import pandas as pdmarketing_campaign.csv 가져오기
- multi_index : 'Marital_Status', 'Education' 순
customers = pd.read_csv('marketing_campaign.csv',sep='\t',index_col=['Marital_Status','Education'])
customersMarital_Status 순으로 정렬
customers.sort_index(level=0, inplace=True)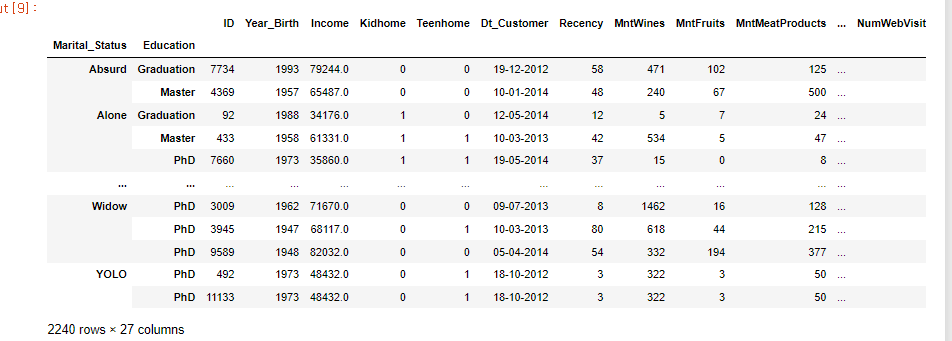
풀이
customers.sort_index(level='Marital_Status', inplace=True)또는
customers.sort_values('Marital_Status', inplace=True)Married & Graduation 조회
- 코드가 잘못된 건 아닌데, 멀티 인덱싱 정렬이 안되서 경고가 뜬다.
- 데이터프레임의 인덱싱 성능이 저하될 수 있기 때문에 경고가 발생.
- 때문에 정렬이 필요하다.
customers.loc['Married','Graduation']풀이 : 컬럼 열도 해주는 습관!
customers.loc['Married','Graduation', :]Year_Birth와 Income의 max, min, mean을 확인
- 단 agg를 사용해서!
customers.agg({'Year_Birth' : ['max','min','mean'], 'Income' :['max','min','mean']}).round(0)풀이
위와 동일하게 한것과 아래 방법이 있다.
customers[['Year_Birth','Income']].agg(['max','min','mean'])Year_Birth와 Income의 max, min, mean을 확인
- 이번에는 apply를 이용해서
- 이건 좀 이해가 안됨.;’;;;;;
- apply는 agg와 동일한 방법으로 수행이 가능하다고 한다.
customers[['Year_Birth','Income']].apply({'max','min','mean'})수익을 다음으로 분류
- 60000이상 고임금
- 30000이상~60000미만 평균임금
- 30000미만 저임금
- 열 이름은 'Class_Income'
1.먼저 apply에 사용될 함수를 만들어준다.
def income(money):
if money >= 60000:
return '고임금'
elif money >= 30000 and money < 60000:
return '평균임금'
else:
return '저임금'- apply로 위의 함수를 적용한 컬럼을 만듦
customers['Class_Income'] = customers['Income'].apply(income)3.컬럼 위치 수정
data = customers.pop('Class_Income')
customers.insert(loc = 3, column= 'Class_Income', value=data)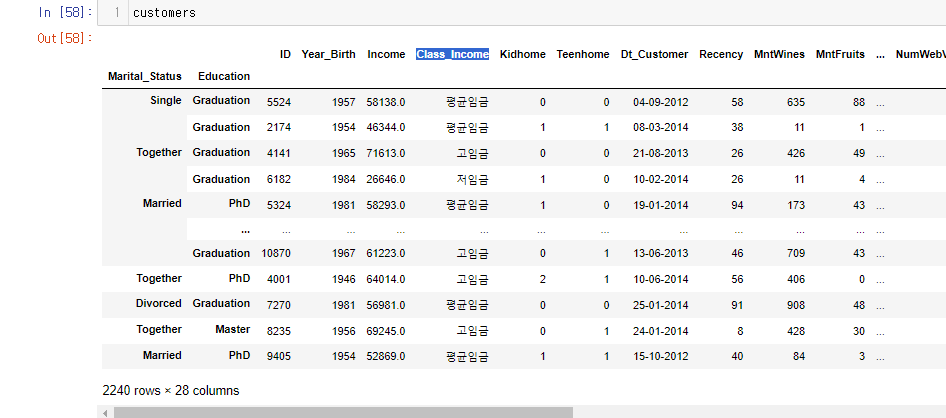
**Alone, Absurd, YOLO를 Single로 변경**
- reset_index()로 되돌리고
- replace으로 값을 바꾼다음에
- 다시 set_index()로 설정해보자.
- 실제로 잘 변경되었는지 get_level_values(0)후 value_counts()로 데이터 경우의 수를 확인해보자.
customers.reset_index(['Marital_Status','Education'],inplace=True) #인덱스 초기화 #reset_index(inplace=True) 이렇게 해도 됨.
customers['Marital_Status'].replace(['Alone','Absurd','YOLO'],'Single',inplace=True)#값 Single로 변경
customers.set_index(['Marital_Status','Education']) #인덱스 재조립customers.value_counts('Marital_Status')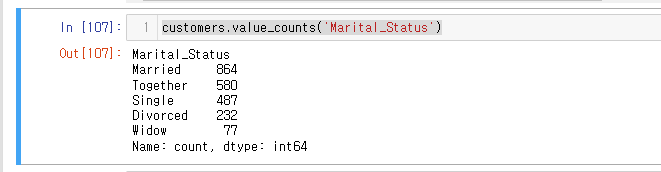
데이터 수를 확인하니 **Alone, Absurd, YOLO** 얘들 없어짐
풀이
확인할 때 이렇게 하더라
customers.index.get_level_values(0).value_counts()근데 값은 동일하게 나옴

LV. 1