값을 교체하는 replace 메소드를 한번 더 보자~
실습 환경 구축
import pandas as pd
customers = pd.read_csv('marketing_campaign.csv', sep='\t', index_col='ID')
customers결혼 상태
현재 데이터를 확인하면 결혼 상태 컬럼이 다양함을 알 수 있다.
customers['Marital_Status'].value_counts()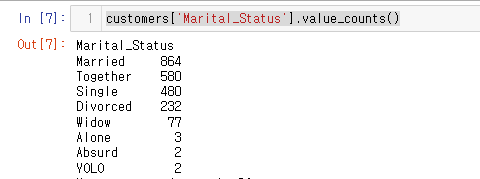
총 8가지로 무엇을 뜻하는지 알아보자.
| 결혼 상태 | 인원 수 | 뜻 |
|---|---|---|
| Married | 864 | 기혼 |
| Together | 580 | 동거 |
| Single | 480 | 독신 |
| Divorced | 232 | 이혼 |
| Widow | 77 | 미망 |
| Alone | 3 | 혼자, 싱글 |
| Absurd | 2 | 터무니없는 |
| YOLO | 2 | 욜로 인생 |
이 중 Alone, Absurd, YOLO는 해석에 애매한 부분이 있다.
해당 데이터의 토론에도 이슈가 있으며
YOLO같은 경우는 일반적인 Single과는 다른 고객패턴이 있음을 표시하고 싶었던 것 일수도.
여기서는 이 3가지를 Single로 귀속시켜보자.
방법 1. 시리즈.replace(dict)
replace()를 딕셔너리 형태로 사용해보자
# 방법 1. 시리즈.replace(dict)
customers['Marital_Status'].replace({'Alone' : 'Single', 'Absurd' : 'Single', 'YOLO': 'Single'}, inplace= True)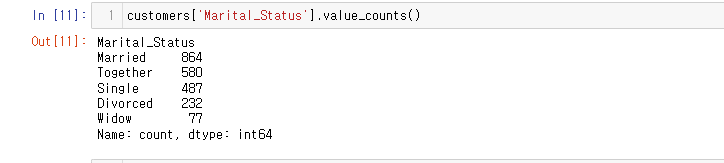
Single로 귀속된 것을 확인할 수 있다.
방법2. 시리즈.replace(list, value)
변환할 값이 동일한 경우 리스트와 value 인자 부분에 스칼라값으로 넣어줘도 된다.
customers['Marital_Status'].replace(['Alone' , 'Absurd', 'YOLO'],'Single')방법3. 데이터프레임.replace()
시리즈 말고 데이터 프레임 전체에 대해서 값을 변경할 수 도 있다.
이점 참고!
Series.replace와 Dataframe.replace의 차이는 탐색&변경의 범위
참고!
**없는 값을 바꾸려고 하면?**
replace에서 없는 값을 바꾸려고 하면 에러 발생없이
그냥 원본 데이터만 보여준다.

LV. 1