타입 변환시 데이터 프레임의 메모리 크기가 어떻게 달라지는지 보자.
또 최적화는 어떻게 진행하는지 알아보자.
최적화가 필요한 이유!
데이터 하드웨어 저장공간을 줄이기 위해서는 아니다.
단지, 연산시 메모리 사용이 기하급수적으로 늘어나기 때문이다.
그렇게 되면 상대적으로 적은 캐시 메모리 사용 공간 으로 연산 시간이 많이 들게 된다.
즉, 머신러닝을 만들 때에 메모리 공간을 최적화해야 연산이 빠르게 된다.
실습 환경 구축
import pandas as pd
customers = pd.read_csv('marketing_campaign.csv', sep='\t', index_col='ID')
customers데이터셋 확인
# .info()로 dtype과 메모리 확인 -
customers.info()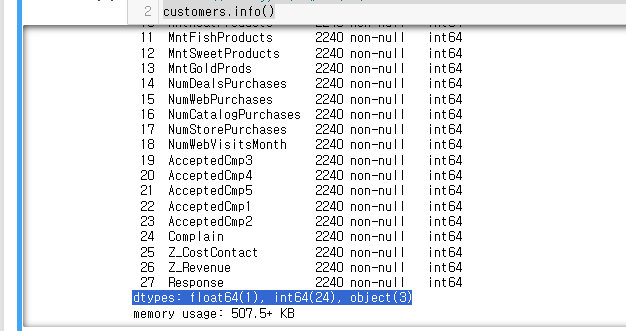
dtypes: float64(1), int64(24), object(3)
memory usage: 507.5+ KB
으로 볼 수 있다.
**.astype(dtype)로 형변환**
- NA는 형변환이 불가
- 이번 실습으로 데이터프레임의 메모리를 줄여보자. 이를 위해 int64를 int8로 줄일 예정
- int64는 64비트를 표현 가능한 범위를 사용
- int8은 8비트로 표현 가능한 범위를 사용
실습 ! 메모리를 줄이자.
1. Year_Birth 타입을 int64 -> int16로 변경
# int64 -> int16 탄생연도
customers['Year_Birth'] = customers['Year_Birth'].astype('int16')다시 info()로 데이터를 확인해 보면
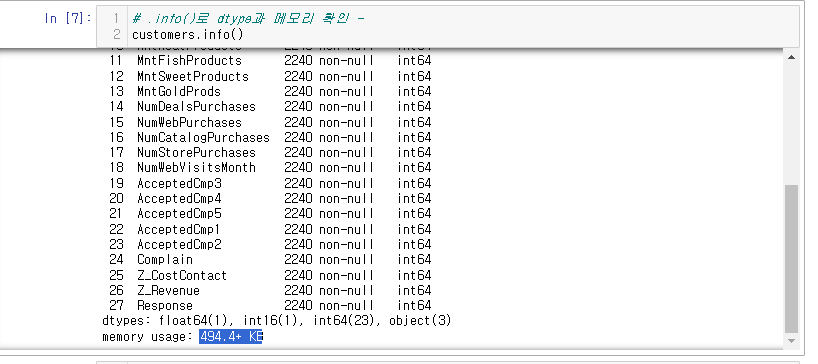
memory usage: 494.4+ KB 로 10KB 정도 줄었다.
하지만 int64(23) 23개나 남았다. 좀 더 줄여보자.
2. Kidhome, Teenhome 타입을 int64 -> int8로 변경
customers['Kidhome'] = customers['Kidhome'].astype('int8')
customers['Teenhome'] = customers['Teenhome'].astype('int8')
memory usage: 463.8+ KB
메모리가 더 줄었다~

LV. 1