데이터셋 확인 순서
- 데이터를 판다스로 가져온다.
- 데이터의 정보를 확인한다. .info()
- 데이터의 통계를 확인한다. .describe()
**DataFrame심화 파트에서는**
캐글에서 고객 성격에 대한 데이터 셋을 가져와서 진행하겠다.
**Customer Personality Analysis** 데이터 속성은 아래와 같다.
가볍게 훑고 가자.
사람 정보
| 속성 | 설명 |
|---|---|
| ID | 고객의 고유 식별자 |
| Year_Birth | 고객의 출생 연도 |
| Education | 고객의 교육 수준 |
| Marital_Status | 고객의 결혼 여부 |
| Income | 고객의 연간 가구 소득 |
| Kidhome | 고객 가구의 어린이 수 |
| Teenhome | 고객 가구의 십대 수 |
| Dt_Customer | 고객이 회사에 등록한 날짜 |
| Recency | 고객의 마지막 구매로부터 경과한 일수 |
| Complain | 고객이 지난 2년 동안 불만을 제기한 경우 1, 그렇지 않으면 0 |
제품
| 속성 | 설명 |
|---|---|
| MntWines | 지난 2년간 와인에 지출한 금액 |
| MntFruits | 지난 2년간 과일에 지출한 금액 |
| MntMeatProducts | 지난 2년간 육류에 지출한 금액 |
| MntFishProducts | 지난 2년간 어류에 지출한 금액 |
| MntSweetProducts | 지난 2년간 과자에 지출한 금액 |
| MntGoldProds | 지난 2년간 금에 지출한 금액 |
프로모션
| 속성 | 설명 |
|---|---|
| NumDealsPurchases | 할인을 받아 구매한 횟수 |
| AcceptedCmp1 | 1차 캠페인에서 고객이 제안을 수락한 경우 1, 그렇지 않으면 0 |
| AcceptedCmp2 | 2차 캠페인에서 고객이 제안을 수락한 경우 1, 그렇지 않으면 0 |
| AcceptedCmp3 | 3차 캠페인에서 고객이 제안을 수락한 경우 1, 그렇지 않으면 0 |
| AcceptedCmp4 | 4차 캠페인에서 고객이 제안을 수락한 경우 1, 그렇지 않으면 0 |
| AcceptedCmp5 | 5차 캠페인에서 고객이 제안을 수락한 경우 1, 그렇지 않으면 0 |
| Response | 마지막 캠페인에서 고객이 제안을 수락한 경우 1, 그렇지 않으면 0 |
장소
| 속성 | 설명 |
|---|---|
| NumWebPurchases | 회사 웹사이트를 통해 구매한 횟수 |
| NumCatalogPurchases | 카탈로그를 사용하여 구매한 횟수 |
| NumStorePurchases | 직접 매장에서 구매한 횟수 |
| NumWebVisitsMonth | 지난 달 동안 회사 웹사이트를 방문한 횟수 |
pandas로 파일 읽어오기
csv 파일인데 컴마(,)로 구분이 안되어 있을 때
marketing_campaign.csv 파일은 csv임에도 불구하고 ,(콤마)로 구분되어 있지 않다.
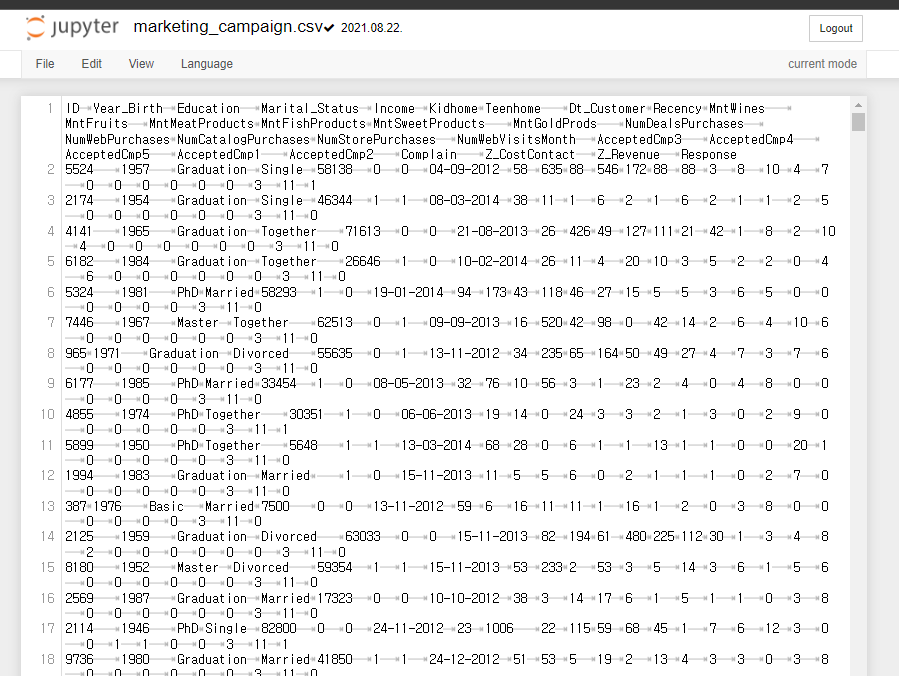
파일을 확인해보면 tap키로 구분이 되어있다.
즉, read_csv() 메소드로 읽어올 때 sep= 인자를 이용해서 탭키로 구분짓도록 해주어야 된다.
customers = pd.read_csv('marketing_campaign.csv',sep = '\t')
customers이렇게!
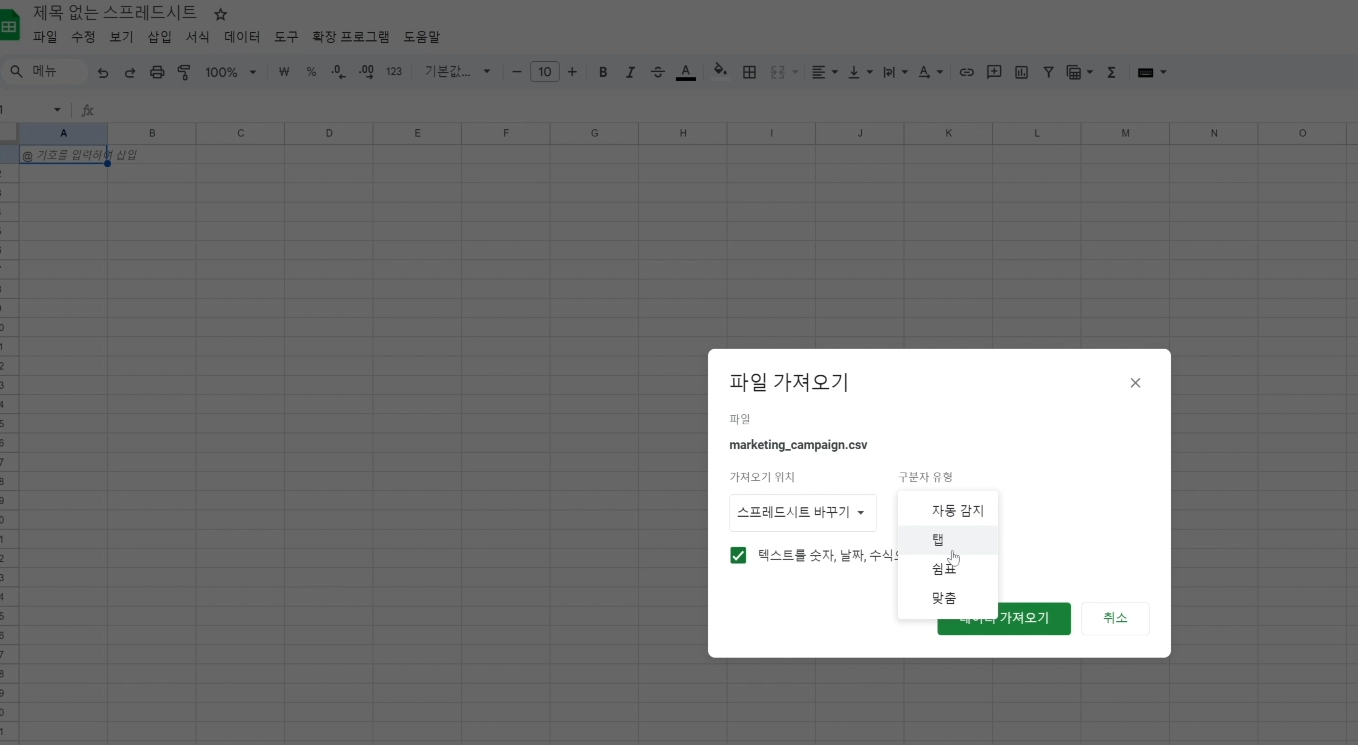
sep= 인자는 스프레드시트에서 파일을 읽어올 때 구분자 유형을 잡아주는 것과 동일한 역할을 한다.
customers.set_index('ID',inplace = True)
customers인덱스는 id로 만들어주자.
데이터 프레임 정보 확인
customers.info()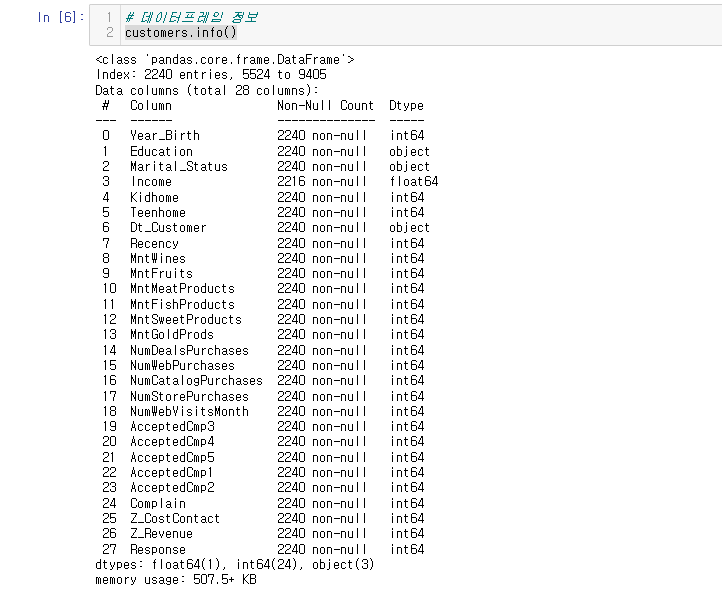
info()로 크게 3가지를 알 수 있다.
데이터의 크기 : index,entries
Index: 2240 entries, 5524 to 9405
라고 적혀있는데 5524 to 9405 는 인덱스 레이블이기 때문에 데이터 크기를 의미하는 것이 아니다.
이점 주의!
데이터 타입 : Dtype
데이터 리소스 : memory usege
통계 확인하기
숫자형 데이터
customers.describe().round()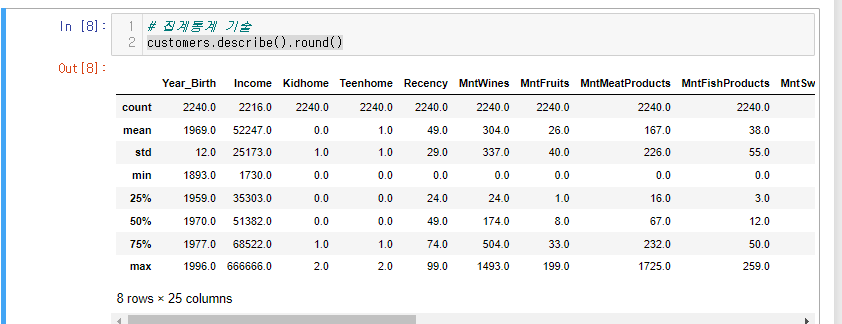
문자형 데이터
# 집계통계 기술 - 숫자 아닌 정보 확인
customers.describe(include='O').round()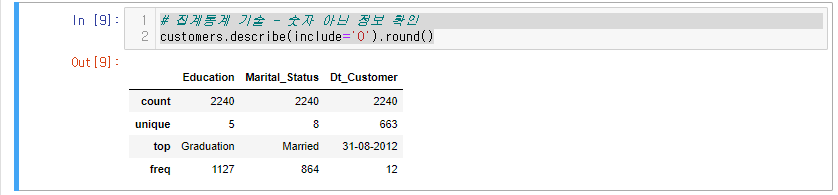
학사, 결혼한 사람들이 많다~

LV. 1