melt()
- https://pandas.pydata.org/docs/reference/api/pandas.melt.html
- 넓은 형식으로 구성된 데이터프레임을 긴 형식으로 변환하여 데이터를 재구성
- 함수를 사용하면 하나 이상의 열을 식별자 변수(
id_vars)로 설정하고, 나머지 열인 측정 변수(value_vars)를 행 방향으로 언피벗하여 두 개의 비-식별자 열인variable과value만 남게 되는 형태로 데이터프레임을 변환
문법
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
Parameters
id_vars : tuple, list, or ndarray, optional
식별자 변수로 사용할 열을 지정하는 매개변수
value_vars : tuple, list, or ndarray, optional
언피벗할 열을 지정하는 매개변수. 지정하지 않으면 id_vars로 설정되지 않은 모든 열이 사용.
var_name : scalar
'variable' 열에 사용할 이름을 지정하는 매개변수. None이면 frame.columns.name 또는 'variable'가 사용됨
value_name : scalar, default ‘value’
'value' 열에 사용할 이름을 지정하는 매개변수. 기본값은 'value'
col_level : int or str, optional
열이 MultiIndex인 경우 해당 레벨을 사용하여 언피벗하는 매개변수.
ignore_index : bool, default True
True로 설정하면 원래의 인덱스가 무시. False로 설정하면 원래의 인덱스가 유지. 필요에 따라 인덱스 레이블이 반복.
Returns
DataFrame : Unpivoted DataFrame.
Unpivot..?
melt()에 대해 설명하면서 언피벗한다~ 라고 했다. 언피벗이 무엇일까?
데이터프레임의 구조를 변형하여 wide(넓은) 형식에서 long(긴) 형식으로 데이터를 재구성하는 작업
일반적으로 wide(넓은) 형식의 데이터 프레임은
- 각 행이 고유한 식별자를 가지고 있고,
- 각 열은 실제 관측값이 있는 열로 구성.
반대로 long 형식의 데이터프레임은
- 각 행이 하나의 관측값을 가지고 있고
- 식별자 변수와 측정 변수를 나타내는 열로 구성
그래서 Unpivot 작업이란
- 데이터프레임에서 측정 변수를 열에서 행 방향으로 이동시켜 long 형식으로 변환하는 것을 의미
- 이를 통해 데이터의 구조를 변경, 분석, 시각화 작업에 더 적합한 형태로 데이터를 재구성
설명들이 너무 복잡하다
예시 데이터로 이해해보자!
간단한 예제 실습
wide한 데이터 테이블을 만들어보자
# 예시 데이터 생성
data = {
'이름': ['Spencer', 'Lune', 'Mark'],
'국어': [66, 90, 95],
'영어': [77, 80, 65],
'수학': [99, 80, 75]
}
df = pd.DataFrame(data)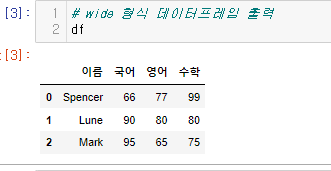
long형식 데이터프레임 출력
# long형식 데이터프레임 출력
df.melt(id_vars='이름', value_vars=['국어','영어','수학'])인자 설명
언피봇을 해서 데이터 프레임을 다시 조립하는 과정
id_vars= : id값으로 지정. 분류 기준이 됨.
value_vars= : id의 값들을 지정
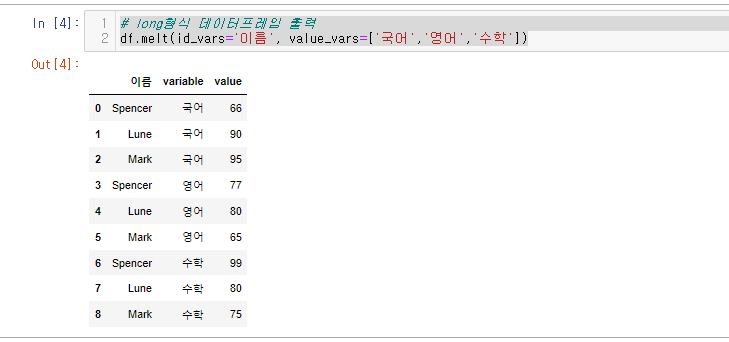
그럼 위와 같이 나온다
마치 SQL의 cross join과 같이 열과 행을 모두 곱해서 가져옴!
이때 새로 생긴 컬럼의 이름이 지정이 안되어 variable,value로 나온다.
컬럼의 이름도 지정해 주자.
# long형식 데이터프레임 출력
df.melt(id_vars='이름', value_vars=['국어','영어','수학'],var_name='과목',value_name='점수')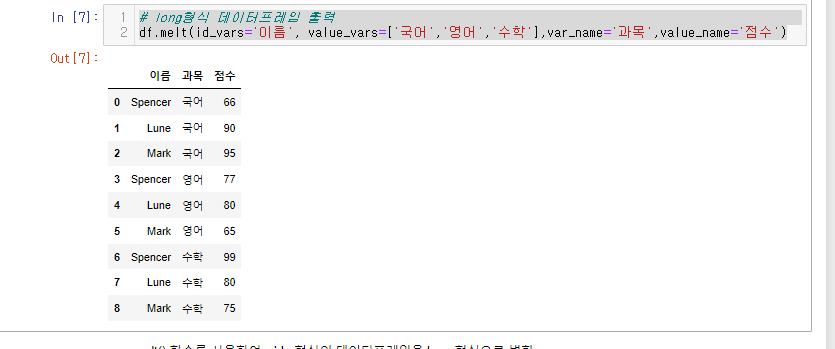
인자 설명
var_name= : variable의 이름을 지정
value_name : value의 이름을 지정
정리
- melt() 함수를 사용하여 wide 형식의 데이터프레임을 long 형식으로 변환
id_vars매개변수에'이름'을 지정하여 식별자 변수로 설정value_vars매개변수에['국어', '영어', '수학']를 지정하여 언피벗할 열을 선택var_name매개변수에 '과목'을,value_name매개변수에 '점수'를 지정하여 열 이름을 변경
- 변환된 long 형식의 데이터프레임은 각 행이 하나의 관측값을 가지며, 이름, 과목, 점수 열로 구성
- 보다 유연하게 데이터를 분석하거나 시각화하는 등의 작업을 수행할 수 있다.
야구 데이터로 실습
이번에는 우리가 사용했던 역대한국야구순위 데이터를 가지고 실습을 해보자
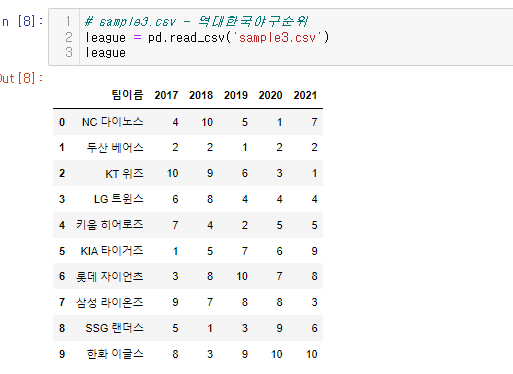
해당 데이터는 wide한 데이터이다.
왜냐??
연도가 늘어날 수 록 가로로 늘어날테니!
(팀이 늘 수 도 있지만 평균적으로 연도가 더 빨리 늘었다..)
이를 melt()를 이용해 long하게 만들어보자
league.melt(id_vars='팀이름',value_vars=['2017','2018','2019','2020','2021'], var_name = '시즌', value_name ='순위')어우! 코드가 너무 길다.. value_vars 에 들어갈 값을 줄여보자
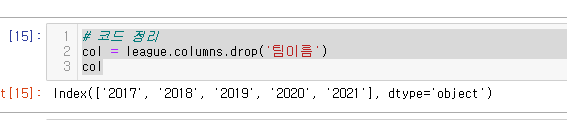
# 코드 정리
col = league.columns.drop('팀이름')요렇게 하면 원본데이터 컬럼에서 팀이름 빼고 다 가져와 지게 된다.
이제 다시 코드를 작성하면 동일하게 long형 데이터가 만들어진다.
league.melt(id_vars='팀이름',value_vars=col, var_name = '시즌', value_name ='순위')