[30일차]DataFrame재구성 - 인덱스 레벨 제어(stack, unstack, droplevel)
데브코스_데이터분석- Python Pandas 활용하기[6주차]
.stack()
- stack : 쌓아간다? 뭘 쌓는다는 걸까?
- 기존 컬럼 또는 로우 값을 다른 곳으로 이동하여 쌓는다~
- 데이터프레임의 구조를 재조정하는 데 유용
- columns에 다중 인덱스가 있는 데이터프레임에서 사용하면 컬럼 인덱스가 로우 인덱스의 레벨로 이동.
- 컬럼을 로우로 "압축"하는 작업을 수행
.stack() 문
DataFrame.stack(level=-1, dropna=_NoDefault.no_default, sort=_NoDefault.no_default, future_stack=False)
컬럼에서 지정된 레벨(들)을 인덱스로 스택(stack)한다.
현재의 데이터프레임과 비교하여 하나 이상의 새로운 내부 레벨을 가지는 다중 레벨 인덱스를 가진 재구성된 데이터프레임 또는 시리즈를 반환합니다. 새로운 내부 레벨은 현재 데이터프레임의 컬럼을 피벗(pivot)하여 생성된다.
- 만약 컬럼이 단일 레벨이라면, 결과는 시리즈(Series).
- 만약 컬럼이 다중 레벨이라면, 새로운 인덱스 레벨은 지정된 레벨에서 가져오며 결과는 데이터프레임(DataFrame).
Returns : DataFrame or Series
스택(stack)된 데이터프레임 또는 시리즈.
**.stack() 기본 사용**
아래와 같은 다중 레벨 컬럼을 가진 데이터 프레임이 있다고 하자.
data = {
('A', 'col1'): [1, 5],
('A', 'col2'): [2, 6],
('B', 'col1'): [3, 7],
('B', 'col2'): [4, 8]
}
df = pd.DataFrame(data)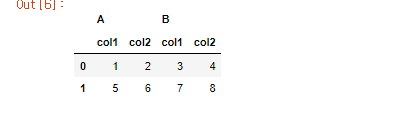
컬럼 인덱스 레벨 0 = A, B
컬럼 인덱스 레벨 -1 = col1, col2, col1, col2
스택을 진행
df.stack()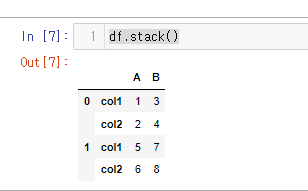
각 행을 쪼개서 설명해 보자
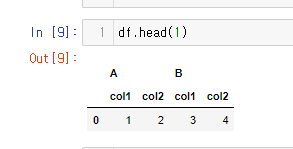
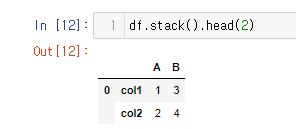
기존 값이다.
A 컬럼의 col1=1 B컬럼의 col1 =3
바뀐 값이다. col1이 인덱스로 들어가게 되며 각 컬럼에 알맞는 값으로 들어가게 되었다.
- index 0행 영역에서 columns -> index로 재조정 (A, B)
- index 1행 영역에서 columns -> index로 재조정 (col1, col2, col1, col2)
- unstack()은 되돌아간다.
또 다른 데이터로 실습을 해보자
**stack() unstack() 가벼운 데이터로 이해하기**
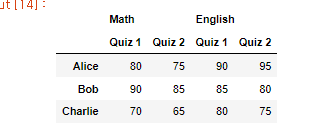
# 예시 데이터
data = {
('Math', 'Quiz 1'): [80, 90, 70],
('Math', 'Quiz 2'): [75, 85, 65],
('English', 'Quiz 1'): [90, 85, 80],
('English', 'Quiz 2'): [95, 80, 75]
}
df = pd.DataFrame(data, index=['Alice', 'Bob', 'Charlie'])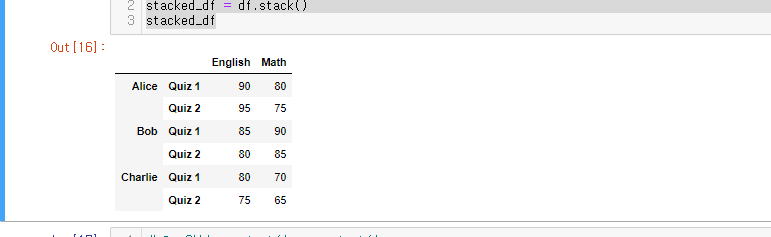
stack() 사용
# 1. 원본 -> stack()
stacked_df = df.stack()
stacked_df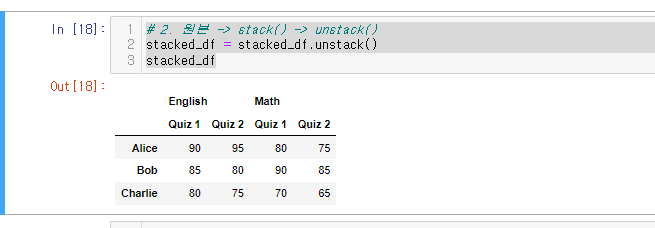
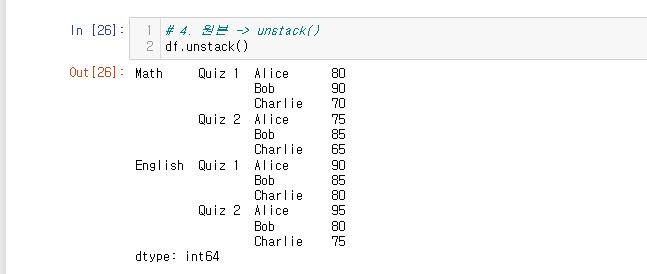
unstack() 사용
# 2. 원본 -> stack() -> unstack()
stacked_df = stacked_df.unstack()
stacked_df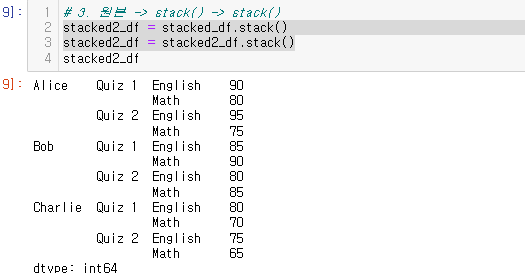
stack된 데이터 프레임을 한번 더 stack 해보자.
두 번 스택한 코드
stacked2_df = stacked_df.stack()
stacked2_df = stacked2_df.stack()출력은 컬럼이 모두 로우 인덱스로 이동되기 때문에 시리즈 형태로 변환 된다.
이때 시리즈는 멀티 인덱스 형태를 가지고 있다.

stacked2_df.index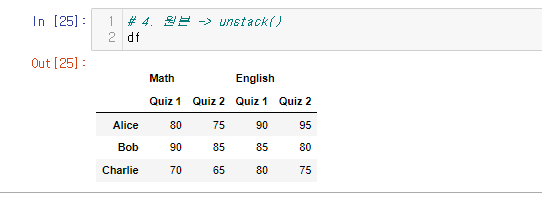
멀티 인덱스가 level0~2까지 만들어진 것 을 확인할 수 있다.
원본을 unstack() 한다면?
다중 컬럼 인덱스가 모두 로우인덱스로 이동한 모습!
원래라면 로우 인덱스가 컬럼 인덱스로 가야 정상인데.. 이미 두개 이상의 멀티 인덱스를 가지고 있어서 그런가??
아마 stack의 반대역할이라 그 반대로 실행돼서 다 이동하는 것 같다.
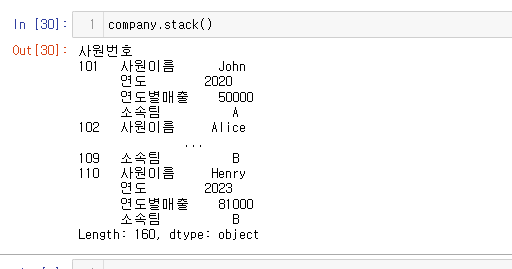
**단일 레벨의 Columns을 stack()하면?**
위에서는 다중 레벨의 컬럼을 만져보았다.
이번에는 평범하게 보이는 단일 레벨의 컬럼을 stack() 해보자.
company.stack()
이런 데이터 프레임을 스택해보자
아마 모든 컬럼이 로우 인덱스로 이동할 것 이다. 그래서 멀티 로우 인덱스 형태로 될 듯 하다.
예상이 맞았다!
.droplevel(level, axis)
위에서 데이터 프레임을 stack() 해서 시리즈화 하였다.
그럼 컬럼이 없는 시리즈가 만들어지는데, 이때 다시 데이터 프레임화를 진행하면!
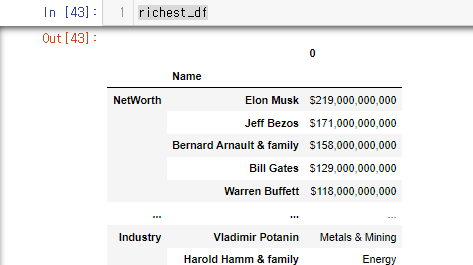
richest_df = pd.DataFrame(richest)
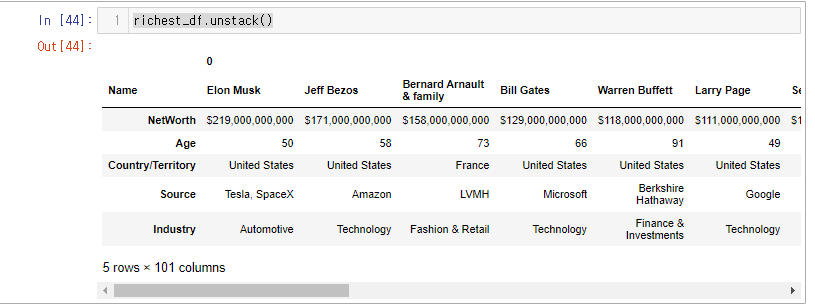
richest_df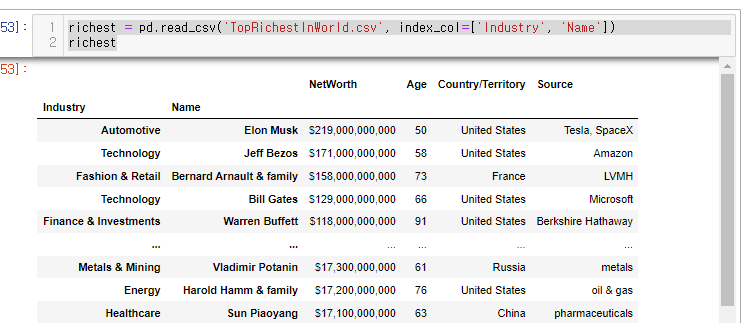
컬럼에 자동으로(인덱스 레인지) 0이 생기는 것을 볼 수 있다.
그럼 이상태에서 unstack()을 한다면?
richest_df.unstack()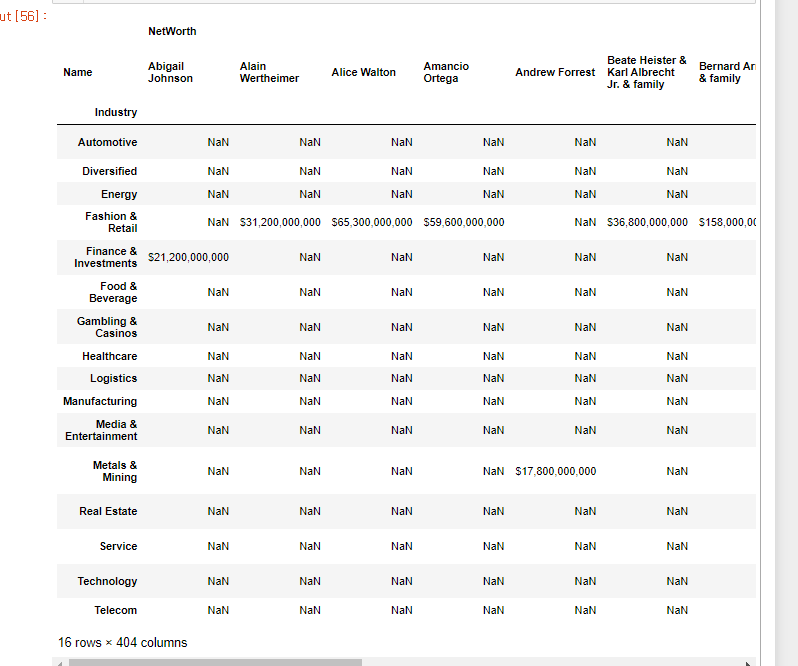
다중 컬럼이 생성되게 된다.
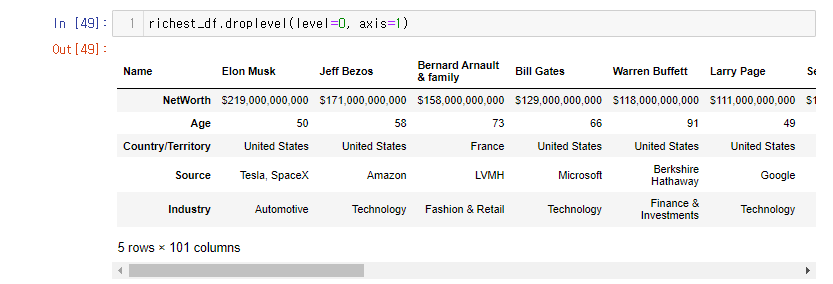
이때 0을 지울 수 있는 메소드가 바로 .droplevel() 이다.
.droplevel() : 컬럼 인덱스 또는 로우 인덱스를 제거할 때 사용. 기본 값은 로우 인덱스 이다.
richest_df 에서 0 컬럼을 지워보자
richest_df.droplevel(level=0, axis=1)- 어떤 레벨이냐? 0
- 기본값이 로우인덱스 이기 때문에 축 변환을 해 컬럼을 지정해줬다.
굳
**level값에 따른 stack, unstack변화**
데이터는 아래와 같이 멀티 로우 인덱스 형태 가져와 보았다.
richest = pd.read_csv('TopRichestInWorld.csv', index_col=['Industry', 'Name'])
richest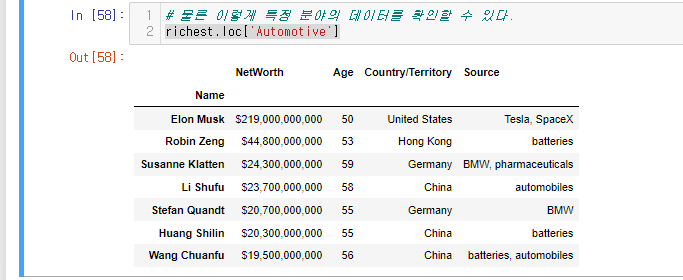
이 데이터를 unstack() 해보자.
그럼 로우인덱스가 컬럼 인덱스로 빠질 것 이다.
이때 어떤걸 기준으로 하는지 level= 인자를 사용해보면 된다.
Name을 언스택한다.(Name을 컬럼으로 빼버린다.)
richest.unstack(level=-1)물론 level 인자의 기본값이 -1 이기때문에 따로 작성 안해줘도 된다~
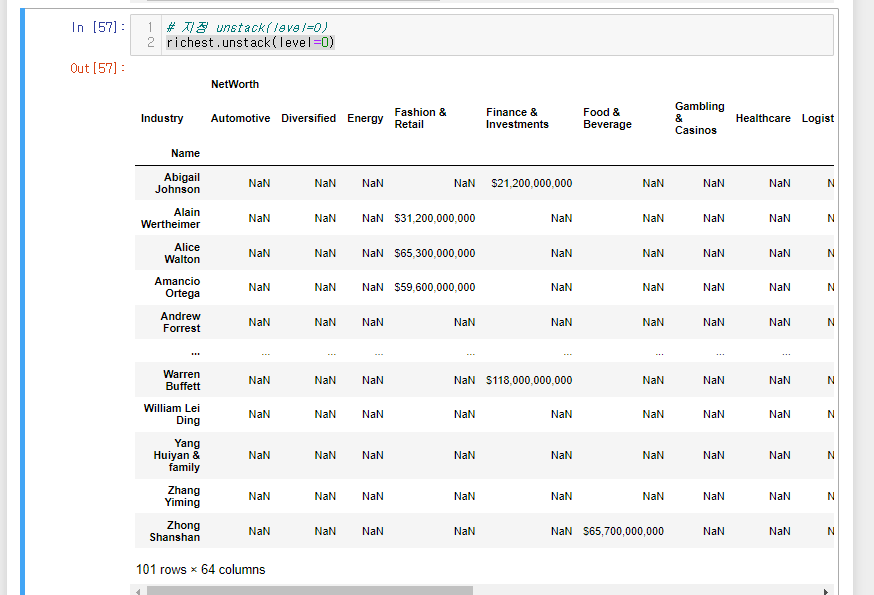
만약 Name을 남기고 Industry를 컬럼으로 빼고 싶다면?
level=0으로 지정해 주면 된다.
richest.unstack(level=0)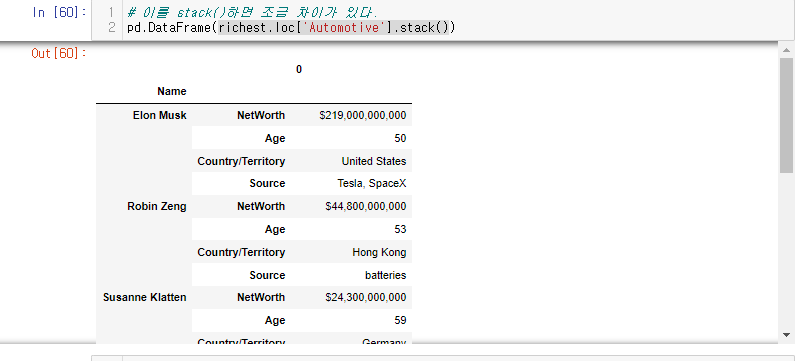
정리
- 기존 열은 level 0
- unstack()으로 지정된 index는 level 1
- 교차가 되지 않는 값은 NA로 지정된다.
실제 사용 방법⭐⭐⭐
위의 데이터는 실제 데이터 분석에서는 사용하기 힘들 것이다.
stack과 unstack을 실무에서 어떻게 사용하는지 보자.
이 부분만 이해해도 됨 ㅎㅎ
richest.loc['Automotive']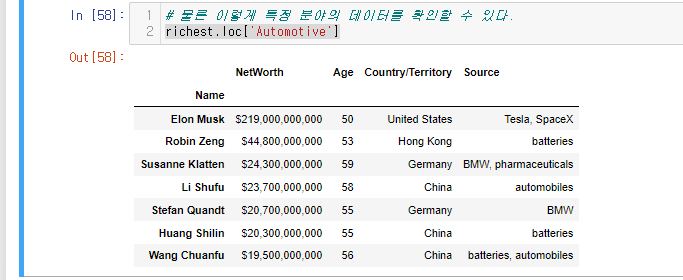
Automotive 산업에 관련된 사람들의 정보가 나온다.
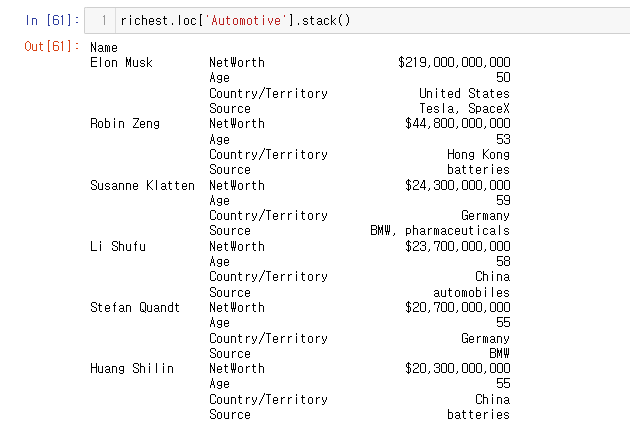
한 사람 한 사람을 로우 인덱스에 묶고 싶을 때는 아래와 같이 진행하면 된다.
richest.loc['Automotive'].stack()
이 시리즈를 데이터 프레임화 하면?
사람별로 각 정보를 다 확인할 수 있도록(.loc 을 이용해) 데이터 프레임이 설정 되었다.
이건 솔직히 많이 못쓸듯 ㅎㅎ
skill개념으로만 알고있자~
