**DataFrame재구성 - 행렬 전치(transpose)**
데이터 프레임 구조가 너무 넓게(컬럼이 많다) 되어 있거나 너무 길다(인덱스가 많다.)
그럴때 내가 원하는 모습으로 재구성할 수 있다.
실습 사용 데이터 셋 설명
앞으로의 실습은 아래의 데이터를 가지고 진행할 것이다.
가볍게 훑어보자
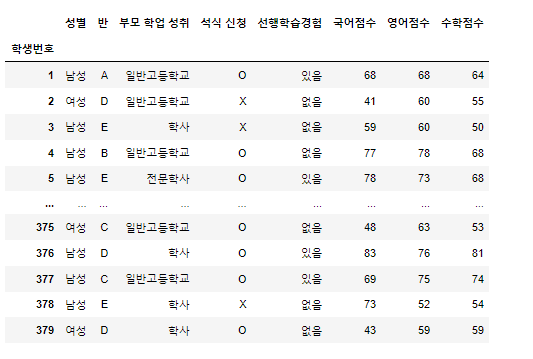
- sample1.csv - 학업성취도 총379개의 데이터로 한 학교의 학업에 대한 정보들이 있다.
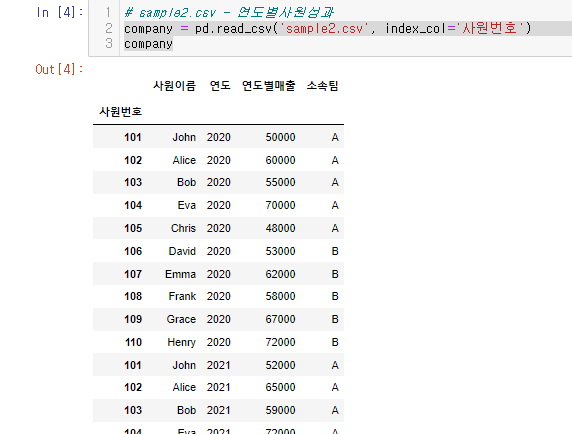
- sample2.csv - 연도별사원성과 총 40개의 데이터로 사원별 연도별 매출을 보여주고 있다.
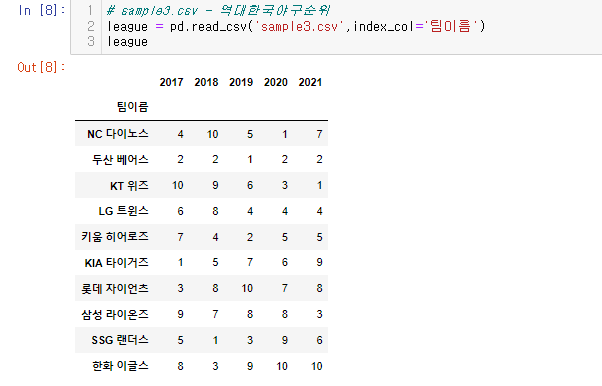
- sample3.csv - 역대한국야구순위 한국 야구 팀별 연도별 순위가 들어가 있다.
- 이전에 다뤘던 캐글 데이터
- TopRichestInWorld.csv - 캐글데이터 (부자 순)
- Pokemon.csv - 캐글데이터 (포켓몬 종류)
**.transpose() 행과 열을 반전시켜보자.**
- **.transpose()**
- 전치행렬 : 행과 열을 교환하여 얻는 행렬. 주대각선을 축으로 반사 대칭을 한다.
- 행과 열을 반전시키자.
위의 표를 아래처럼 반전 할 수 있다는 말1 3 5 2 4 6 1 2 3 4 5 6
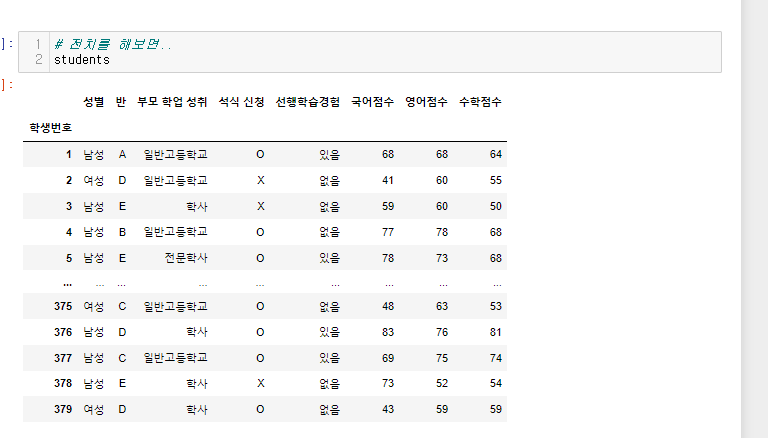
students 데이터 프레임을 전치해보자.
해당 전치는 유의미한 데이터를 가지고 올 수는 없지만 진행해보자.
students.transpose() 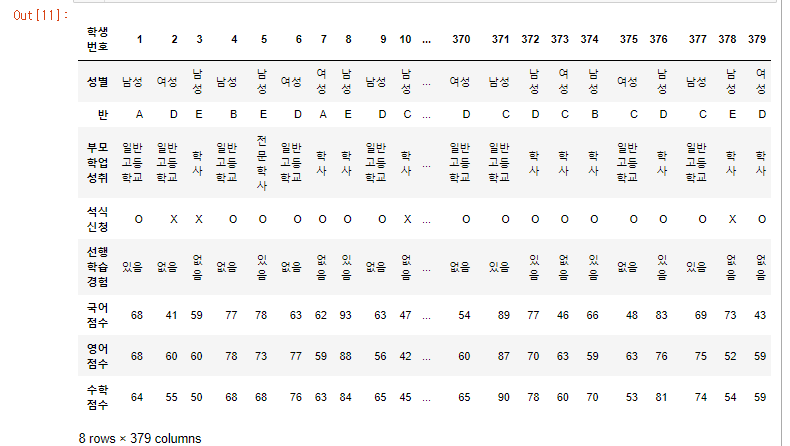
기존 인덱스가 컬럼으로
기존 컬럼이 인덱스로 갔다.
이 transpose 메소드는 .T 로 줄여서 사용할 수 있다.
students.T이런식으로!
❗위의 전치는 유의미하지 않다!
데이터의 증가는 행의 방향이 옳다고 생각될 경우에 유의미할 것
야구리그를 전치해보자.
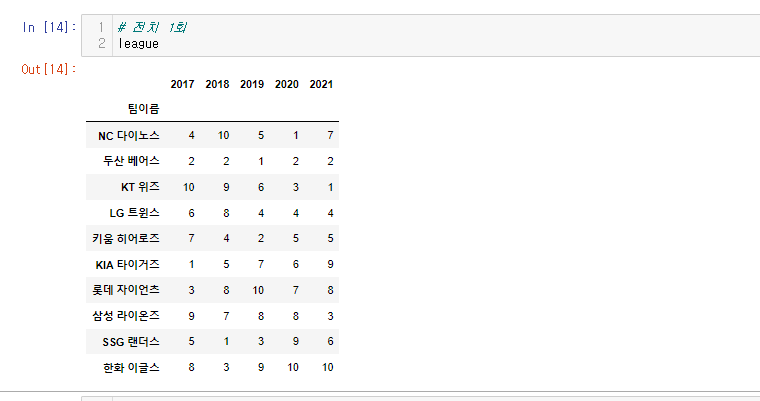
league.T 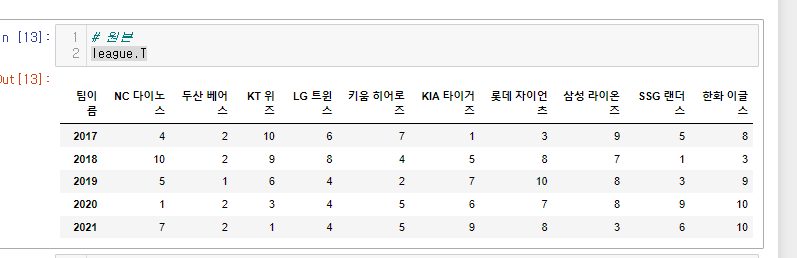
야구팀 이름을 기준으로 했던 데이터프레임이
연도를 기준으로 바뀌었다.
데이터 분석에 있어 유의미하게 바뀐것을 볼 수 있다.
🚫주의사항🚫
‘전치를 두번하면 원본으로 돌아가겠지?’
데이터는 그대로 인 것처럼 보이지만
타입이 변경되게 된다.
예를 통해 보자.
원본데이터 회사정보와 데이터 프레임 모습이다.
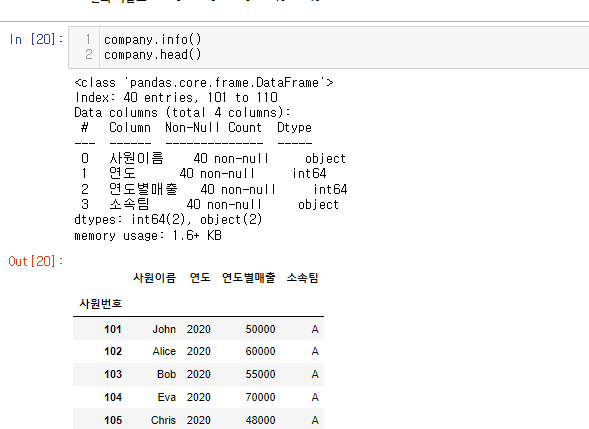
이를 두번 전치 해보겠다.
먼저 T_2 라는 두번 전치된 함수를 만들어 주었다.
T = company.T
T_2 = T.T데이터 확인
T_2.info()
T_2.head() 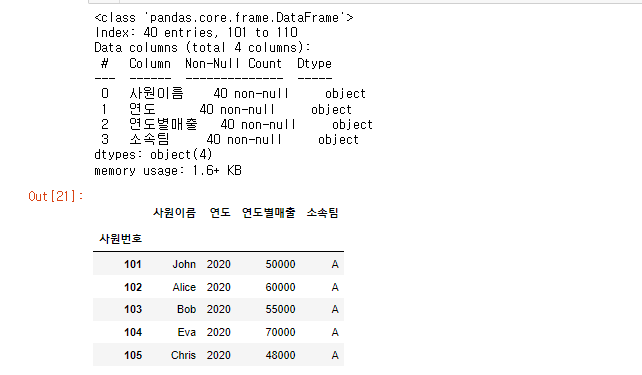
데이터 프레임은 동일해 보이지만,
모든 열의 dtype이 object로 변경되었다.
왜 그럴까?
판다스의 데이터 프레임은 각각의 컬럼 한줄의 데이터 타입이 일치해야 된다.(연속적 특징)
전치시에는 데이터를 기존 컬럼 타입에 맞게 변경되기 때문에 Dtype도 변경되게 된다.
이후 한번더 전치시 변경된 타입을 그대로 가져오게 됨.
결국 전치 후 데이터 타입을 확인해
숫자형 타입은 astype 으로 타입변경을 해주는
전처리 과정이 필요하다.

LV. 1