이번 글에서는 **Random Forest**에 대해서 알아보려고 한다.
그전에! Decision Tree에 대해 간단하게 알아보자.
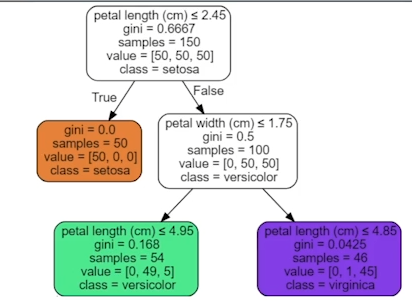
Decision Tree
x를 기준삼아, ‘해당 기준을 만족/불만족시 y값이 ~값일 것이다.’
라는 조건(x)-결과(y)를 나무처럼 발전시킨 것을 말한다.
-
Classification에서는 y값이 클래스,
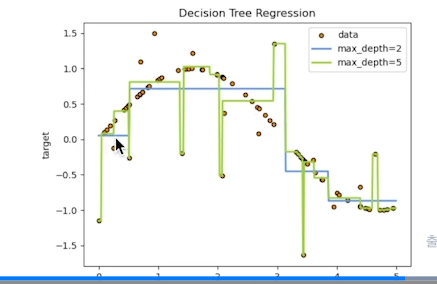
Regression에서는 y값이 평균값이다. -
아래 그래프와 같이 동작함.
**Random Forest**
그렇다면 **Random Forest**는 무엇일까? Forest 즉 숲을 의미한다.
Decision Tree를 무작위로 여러개 만든 후, 각 tree마다 나온 decision들을 voting(ensemble통합하다.)을 통해서 최종적인 y값을 예측한다.
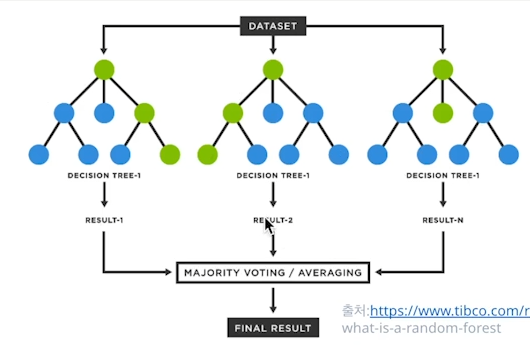
n_estimators(트리의 개수),
max_depth(각 트리의 길이) 등의 인자를 설정하여 모델의 성능을 높일 수 있다.
다만, 무조건 트리 개수나 길이값이 크다고 성능이 좋아지지는 않는다.
특히 학습 시간이나 차지하는 메모리가 지나치게 커질 수 있으니 그 점 참고하자.
# Random Forest
from sklearn.ensemble import RandomForestRegressor
rfr= RandomForestRegressor(n_estimators=100, max_depth=200)
LV. 1