데이터 모델링 - Logistic regression(로지스틱 회귀)
데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로 예측한 뒤 그 확률에 따라서 가능성이 특정 기준치(threshold) 이상인 경우 해당 클래스로 분류해 주는 지도학습 알고리즘이다.
-
Linear regression의 output y값에
’Sigmoid function’을 적용해서
output y의 값이 0~1 사이 값으로 만든다.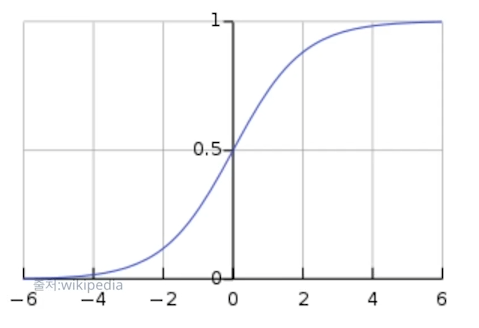
x축은 무한대의 값으로나오고
y축은 0~1사이의 값으로 나오게 한다.
만약 동전 뒤집기 모델이라고 했을 때
값이 0.5이상이 나오면 모델은 뒤집어 진다고 판단하게 된다.
Support Vecter Machine(SVM)
데이터를 분류하기 위해 최적의 초평면을 찾는 지도 학습 알고리즘이다.

- 사진에서 처럼 Linear regression(선형회귀)와 비슷하지만, 선에 같이 없는 분홍색 점들또한 고려해주는 모습이다.
즉, ’어느 정도의 허용오차(C)안에 있는 오차값은 허용해준다’
라고 생각하면 된다.(허용오차 안에 없는 초록색 점은 제외) - 허용 오차 C 값을 잘 설정해야 모델이 좋은 성능을 낼 수 있다.
kernel=인자를 통해 모델이 가정하는 x와 y의 관계 등을 잘 잡아낼 수 있다.
# Support Vector Machines (SVM)
from sklearn.svm import SVR
svr= SVR(kernel='linear', C=10.)
LV. 1