SVM(Support Vector Machine) - 선형 실습
- 먼저 데이터를 만들어보자
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.svm import SVC
seed = 1234
np.random.seed(seed)make_classification : 더미데이터를 생성할 수 있다.
# 데이터 생성
X1, y1 = make_classification(n_samples=100, # 생성할 데이터 수
n_features=2, # 사용할 특성의 수
n_redundant=0, # 중복 특성(다른 특성으로부터 파생된 특성) 수
n_clusters_per_class=1, # 클래스 당 클러스터의 수
flip_y=0, # 클래스 레이블이 뒤바뀔 확률, 노이즈에 해당
class_sep=2, # 클래스 간 분리도를 조절, 높을수록 분리가 잘 됨을 의미
random_state=5)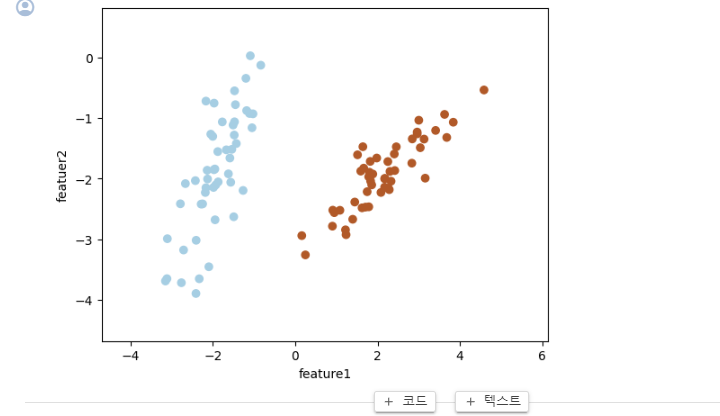
그럼 이런식의 데이터가 나온다!
하드마진 SVM
1. 피팅을 시켜준다.
SVC 메소드를 이용하여 하드 마진을 사용할 수 있다.
kernel= 선형 모델을 사용할 것이기 때문에 linear 입력
C= : 슬랙변수이다.
svm_hard_margin = SVC(kernel='linear', C=1000)
svm_hard_margin.fit(X1, y1)2.시각화
plt.scatter(X1[:, 0], X1[:, 1], c=y1, cmap=plt.cm.Paired)
plt.xlabel('feature1')
plt.ylabel('featuer2')
plt.margins(0.2)
# 현재 그래프의 x축과 y축 범위를 가져옴
xlim = plt.gca().get_xlim()
ylim = plt.gca().get_ylim()
# 그래프의 x & y축 범위를 바탕으로 모든 x,y 조합의 좌표 그리드를 생성
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 50),
np.linspace(ylim[0], ylim[1], 50))
# 그리드 포인트를 이용해 각 포인트에서의 Desicion 결과값을 출력
Z = svm_hard_margin.decision_function(
np.column_stack(
(xx.ravel(), # xx matrix를 1차원 행렬로 flatten
yy.ravel()) # yy matrix를 1차원 행렬로 flatten
) # 1 차원 행렬을 열 방향으로 묶어줌
) # 입력된 각 (x, y) 포인트에 대해 결정 경계로부터의 거리를 계산
Z = Z.reshape(xx.shape)
# 결정 경계와 마진 직선을 그리는 함수
plt.contour(xx, yy, # xx와 yy 공간 안에
Z, # Z를 그릴건데
levels=[-1, 0, 1], # Z가 -1, 0, 1 인 부분만 그릴것!
colors=['orange', 'blue', 'orange'],
alpha=0.5,
linestyles=['--', '-', '--'] # -1, 0, 1 의 직선 개형을 표시
)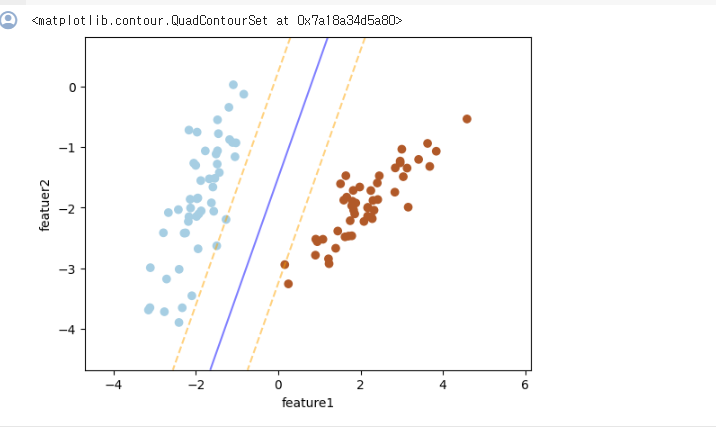
파란색 선이 우리가 찾고자 하는 선형이다.
소프트 마진 SVM
이번에는 데이터가 섞인 상태에서 소프트 마진 SVM을 사용해보자
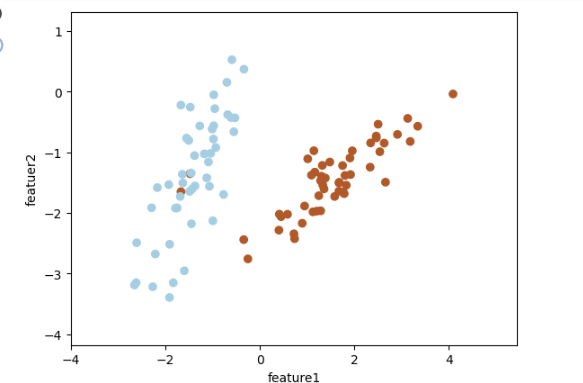
svm_soft_margin = SVC(kernel='linear', C=0.1)
svm_soft_margin.fit(X2, y2)C 에는 선형을 위반한 데이터 중 어느 정도 감안을 하는 범위를 작성.
그럼 아래와 같이 그릴 수 있다.
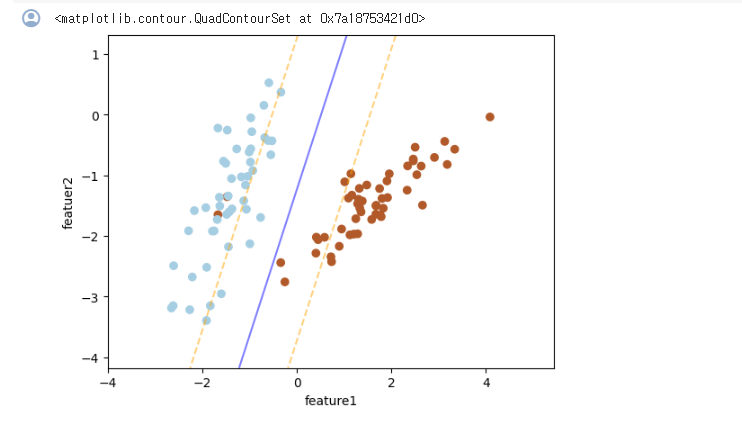
어느 정도의 노이즈는 감안하더라도 잘 감안했다.
C가 커지면 어떻게 될까?
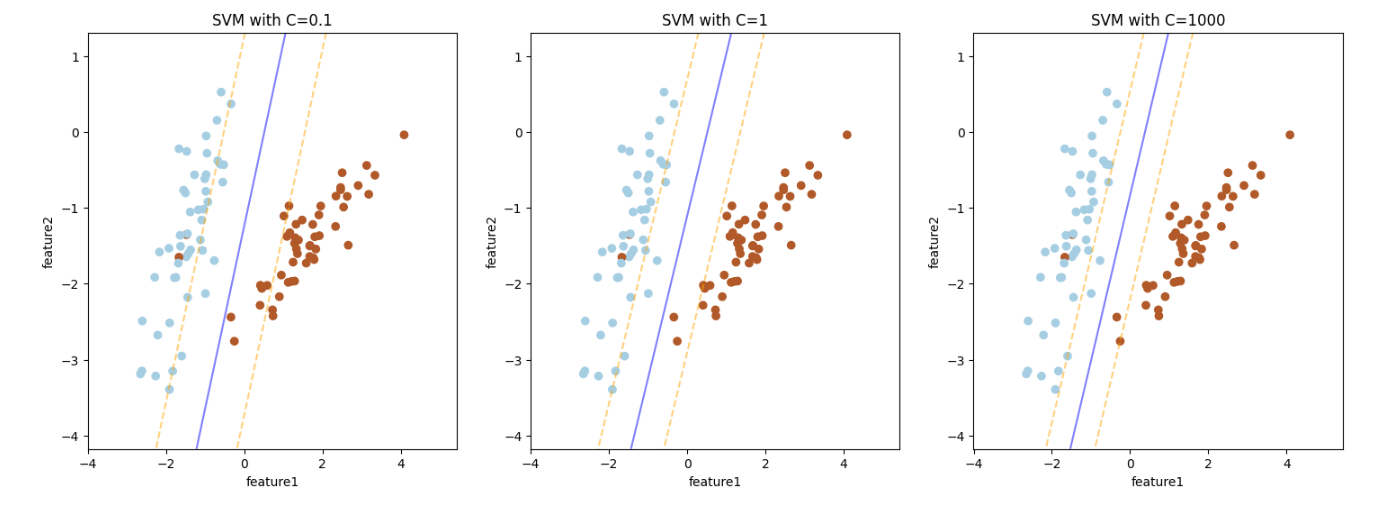
위와 같이 C가 커질 수 록 모델이 값을 더 잘 나누기 위해서 간격이 좁아지는 것을 볼 수 있다.

LV. 1