SVM(Support Vector Machine) - 비선형
선형 SVM 모델의 한계
데이터의 복잡성으로 인해 선형 결정 경계로 데이터를 분류할 수 없는 경우가 있음
특히 데이터가 휘어진 형태로 분포한다면 선형 SVM 으로는 분류할 수 없음
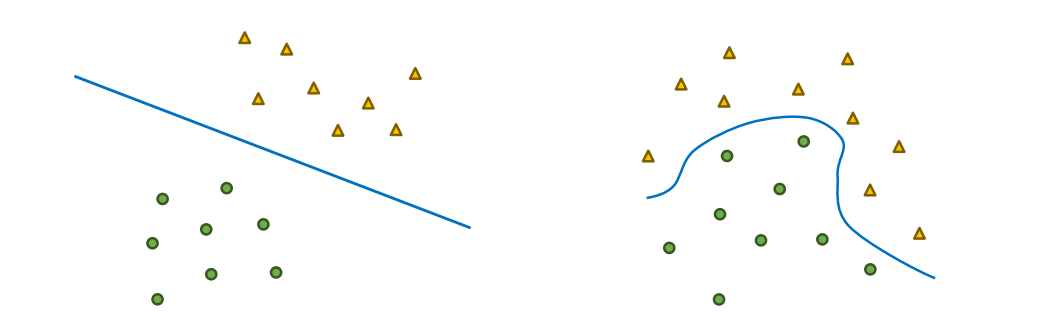
비선형 SVM은 이러한 데이터에 대해 효과적으로 작동
고차원에서의 데이터
선형적으로 분리할 수 없는 데이터를 고차원으로 변형하면
•고차원의 초평면으로 분리할 수 있는 형태로 변환이 가능하다.
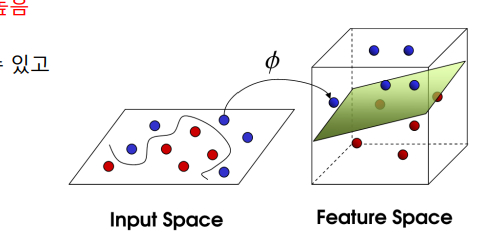
- 왜 그런걸까?
• 차원이 증가하면 데이터 포인트 간의 상대 거리는 증가
• 각 차원에서 데이터끼리 차지하는 공간이 확장
• 그러면서 비슷한 특성을 공유하는 데이터들은 특정한 축 혹은 방향으로 군집될 가능성이 ↑
따라서, 고차원의 데이터일수록 선형으로 분류할 수 있는 가능성이 높음(100%는 아니다!)
수학자들은 무한의 차원으로 옮기면 결국 선형으로 분리할 수 있다고 한다..!
- 저차원의 데이터를 고차원의 데이터로 옮기는 과정 함수를 정의할 수 있고
• 이른 Mapping function 이라고 부름
고차원 데이터가 갖는 문제
-
고차원의 데이터는 선형 분류할 수 있는 가능성이 있지만 계산량이 늘어난다는 단점이 있음
-
확장한 고차원이 원본 데이터의 차원보다 훨씬 크다면,
모델의 복잡도가 늘어나고 효율성이 떨어짐 -
딜레마에 봉착!
- 차원을 높여 선형 분류를 하고 싶은데
- 계산량과 복잡성이 덩달아 늘어남
-
이를 해결하기 위해 커널 트릭이 제시됨
- 높은 차원의 장점을 취하면서도,
계산의 복잡성이 증가되지 않는 기법
- 높은 차원의 장점을 취하면서도,
커널 트릭이란?
데이터를 선형 분류하기 위해서는 데이터 포인트 사이의 내적(두개의 벡터의 곱) 계산이 수행되어야 한다.
- 내적은 두 임의의 vector 사이의 유사도를 측정 & 선형 경계를 생성하데 사용됨
- 고차원에서 선형 분류를 해야하는 비선형 SVM 에서도 이 과정이 필요함
즉, 고차원에서 정상적으로 계산을 한다면 아래의 과정이 필요
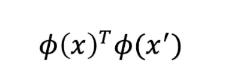
하지만 이는 계산량이 매우 많이 소모됨 ( ∅의 결과로 고차원 vector이므로)
이때, 고차원의 내적 연산의 결과와 똑같은 결과를 보여주는 저차원 vector 끼리의 연산 함수가 있다면 아래와 같이 식을 사용할 수 있다.
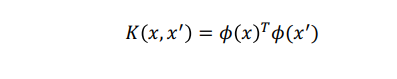
그렇다면 고차원으로 데이터를 변형하지 않고도,
저차원의 데이터 만으로도 고차원 데이터를 활용한 내적 연산의 효과를 누릴 수 있음
• 그래서 이름에 trick이라는 말이 들어간것이다!
다양한 커널의 종류
고차원의 내적 연산과 똑같은 결과를 보여주는 함수를 커널(kernel)이라고 하며
일반적으로 비선형 SVM에서 많이 사용하는 커널 함수는 아래와 같음

비선형 SVM의 최적화 문제
소프트 마진 SVM과 비슷한 구조를 갖고 있다.
다만 원래 차원(저차원)이 아니라 고차원에서의 데이터 분류가 가능하도록 하는 조건이 들어감
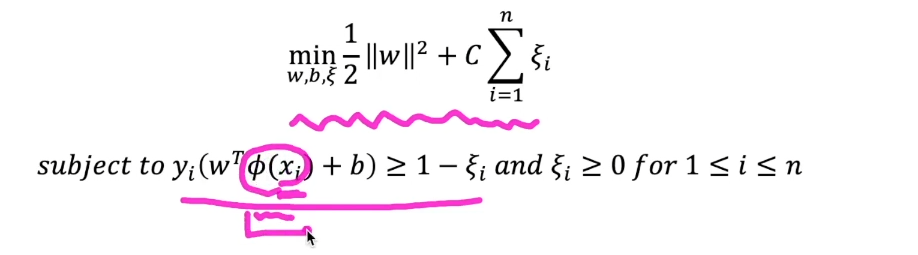
목적
• 마진의 크기를 최대화
• 마진 위반을 최소화
선형 SVM과 식은 위에서 원으로 표시한 부분을 제외하고는 동일하다.
원으로 표시한 부분 : 고차원 데이터에서 선형 분류가 가능함을 표시
비선형 SVM 실습!
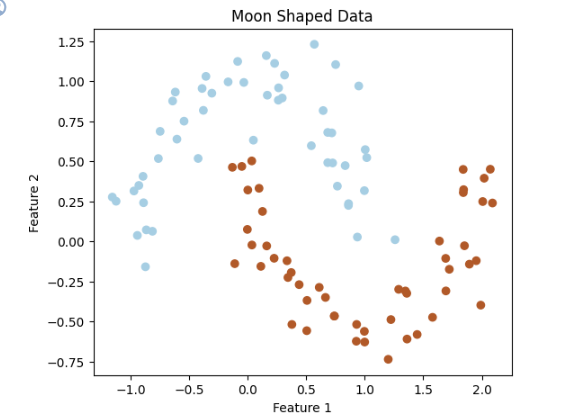
위와 같이 선형으로 분류할 수 없는 데이터가 있다.
SVC() 인자값에 ‘linear’(선형)이 아닌 아래의 값들을 넣어서 비선형을 추출할 수 있다.
# 비선형 SVM 으로 분류
# 선형 커널
Linear_SVM = SVC(kernel='linear')
# 다항 커널
Poly_SVM = SVC(kernel='poly', degree=3) #3차식으로 보낸다.
# RBF 커널
RBF_SVM = SVC(kernel='rbf')
# Sigmoid 커널
sigmoid_SVM = SVC(kernel='sigmoid')
# 시각화
plt.figure(figsize=(10, 10))
plt.subplot(2, 2, 1)
plot_svm_decision_boundary(Linear_SVM, X_moons, y_moons, "Linear SVM")
plt.subplot(2, 2, 2)
plot_svm_decision_boundary(Poly_SVM, X_moons, y_moons, "Polynomial SVM")
plt.subplot(2, 2, 3)
plot_svm_decision_boundary(RBF_SVM, X_moons, y_moons, "RBF SVM")
plt.subplot(2, 2, 4)
plot_svm_decision_boundary(sigmoid_SVM, X_moons, y_moons, "Sigmoid SVM")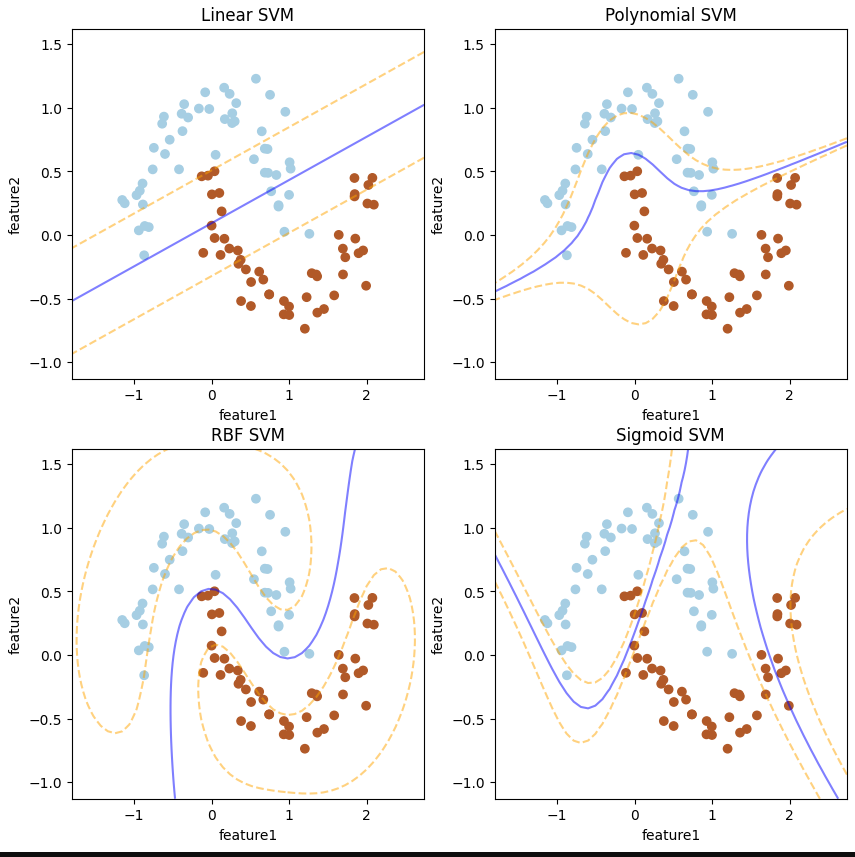
RBF SVM이 아주 잘 나누어진 것을 볼 수 있다.
