이번 글에서는 실제로 데이터를 다뤄볼 예정이다.
캐글의 인터넷 영화 데이터베이스 파일을 토대로 진행해 보자!
해당 파일의 데이터와 사용 용도 예시는 아래와 같다.
실습환경 구축
import pandas as pdmovie_df = pd.read_csv('imdb_top_1000.csv')
movie_df파일을 불러왔다.
열 필터링
불필요한 열이 있기에 필터링 작업을 해주자.
cols = ['Series_Title', 'Released_Year', 'Certificate','Genre', 'IMDB_Rating','Meta_score','Director','No_of_Votes','Gross']먼저 컬럼으로 사용할 명칭을 cols 라는 함수에 리스트화 해서 넣어준 뒤
movie_df = pd.read_csv('imdb_top_1000.csv',usecols=cols)
movie_dfusecols=cols 를 이용해 컬럼을 정해주었다.
열 순서를 변경하기
열의 우선순위를 생각해서 가져와 보도록 하자.
먼저 이전에 데이터프레임을 조회할 때를 생각해보자.
movie_df[]이런 식으로 대괄호([])를 사용해서 조회를 하였다.
그럼 순서에 맞게 조회 후 이를 원본에 저장하면 변경된다.
movie_df[cols]
movie_df = movie_df[cols]
movie_df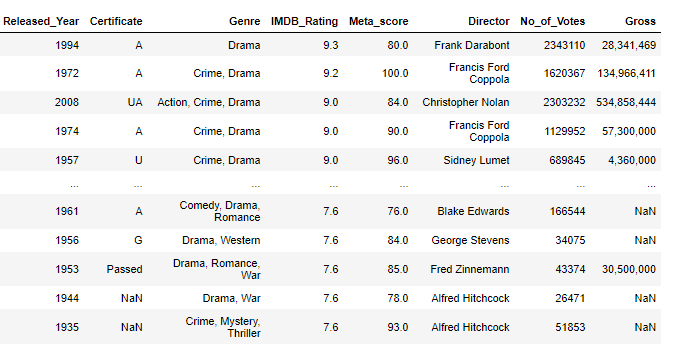
잘못된 열 순서 변경
열 필터링을 할때에 사용된 cols 함수에 데이터를 순서대로 넣는다고 해도 데이터 프레임에서는 순서대로 나타나지 않는다.
이점을 참고하고
열 순서를 변경하고자 할때에는 반드시 원본 데이터에 저장하도록 하자
결측치 파악
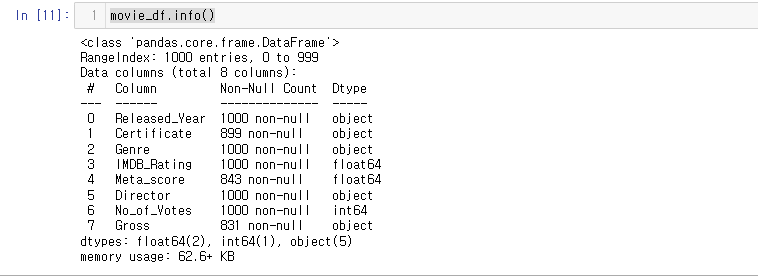
.info()를 이용한 결측치 파악
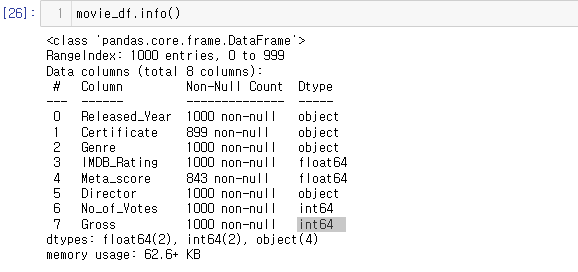
info()를 이용한 결측치를 파악해 보자
movie_df.info()
출력값을 보면 RangeIndex: 1000 entries, 0 to 999 라는 문장이 있다.
그 뜻은 각 컬럼별 1000개의 인덱스를 가지고 있다는 것이다.
즉, Non-Null Count에서 1000 non-null 이 아닌 것은 결측치를 가지고 있다는 것이다.
Certificate,Meta_score,Gross 컬럼에 결측치가 있다.
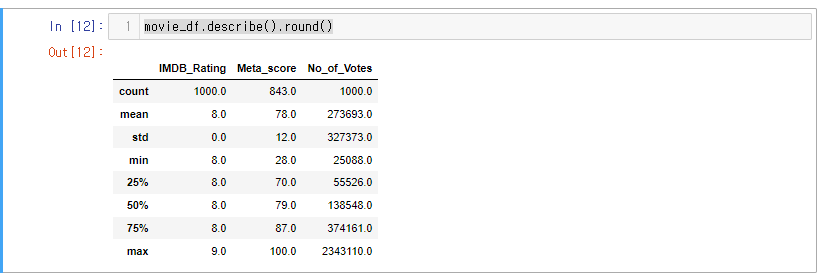
.describe()로 요약 확인.
movie_df.describe().round()
해당 메소드를 통해 요약을 확인해 보았다.
🔎그런데!!! 영화에서 가장 중요한 Gross 수익이 나오지 않았다.
describe 는 숫자열만을 가져오기 때문에 Gross 열은 문자열이지 않을까 하는 의심이 든다.
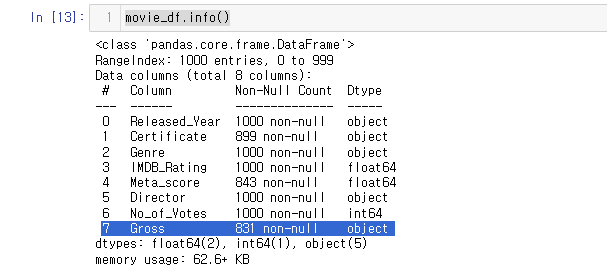
한번 확인해보자.
movie_df.info()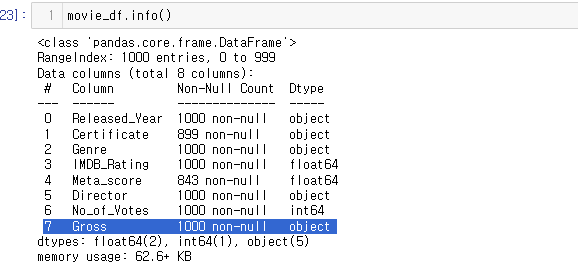
Gross 는 object 즉, 문자열로 구성되어 있는 것을 확인할 수 있다.
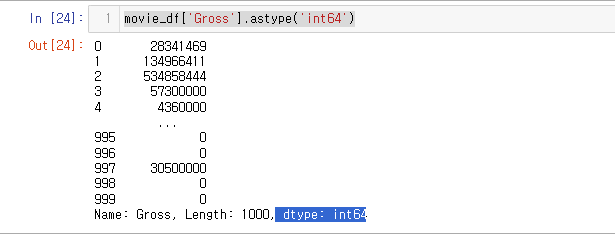
Gross 데이터 확인시 28,341,469 즉 콤마(,) 로 구성되어 있는 문자열이다.
이를 숫자형으로 변환시켜보자.
- 콤마제거
- 결측치 해결
- 숫자형으로 변경
으로 진행 고고!
데이터 형태 변환
- 숫자형 데이터로 변환 가능한 형태로 처리
- 데이터 분석에 유용한 형태로 가공하는 작업 : 데이터 전처리
- comma(,) 부터 삭제해야 된다.
.str.replace() - 1단계 : 포맷 변경하기
1단계 콤마(,) 삭제하기.
movie_df['Gross'].str.replace(',','')replace 메소드를 사용하여 콤마를 제거
movie_df['Gross'] = movie_df['Gross'].str.replace(',','')이후 원본데이터에 적용해준다.
삭제가 잘 되었다.
.fillna() - 2단계 : 결측치 대체하기
2단계 결측치 해결.
.fillna() : NaN으로 나오고 있는 결측치를 인자값 으로 대체
결측값을 0으로 대체해준다.
movie_df['Gross'].fillna(0)이후 원본데이터에 저장!
movie_df['Gross'] = movie_df['Gross'].fillna(0)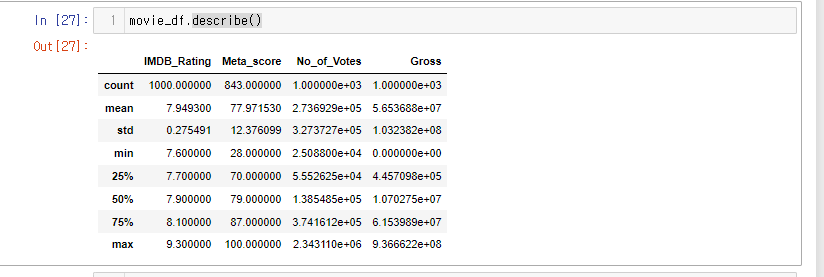
결측치가 0으로 잘 저장이 되었다.
저장시 inplace= 인자를 활용해 파괴적으로 진행하여 원본데이터에 저장해도 된다.
movie_df['Gross'].fillna(0, inplace = True).astype() - 3단계 : dtype 변환하기
astype() 함수를 사용하여 정수형 int64로 변환
astype() : 인자값에 들어가는 형태로 dtype을 변환해준다.
movie_df['Gross'].astype('int64')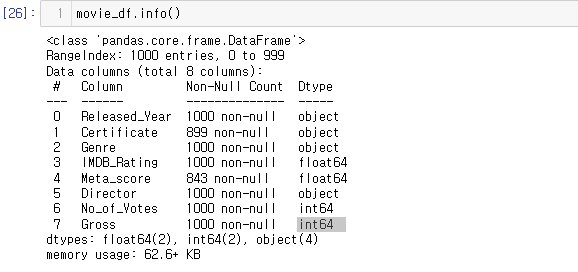
마찬가지로 원본 데이터에 저장해준다.
movie_df['Gross'] = movie_df['Gross'].astype('int64')info() 를 사용해 Dtype이 잘 변환되었는지 확인해 보자.
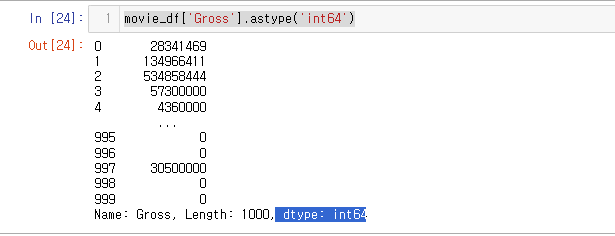
잘되었다!
.describe()로 요약 재확인.
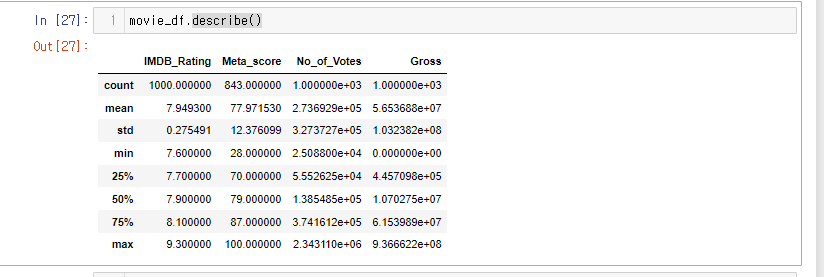
Gross 컬럼이 잘 들어온 것을 확인할 수 있다!
e+는 10의 제곱이라는 뜻.
e+05는 10의 5제곱!
