집계함수 관련 인자에는 아래와 같은 값들이 있다.
**percentiles=, numeric_only=, include=**
집계함수 인자 **percentiles=**
- 백분위수를 확인할 수 있다.
.describe()사용시 나오는 25%,50%,75%를 커스터 마이징 하는 개념
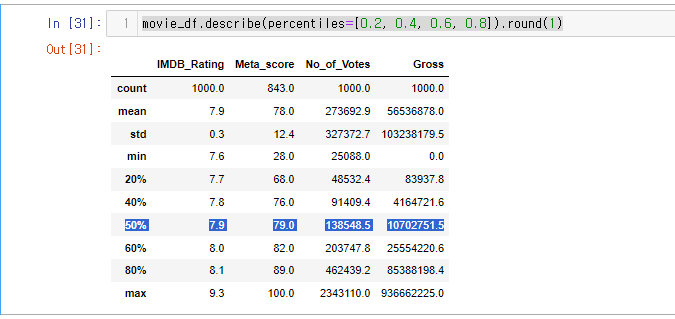
movie_df.describe(percentiles=[0.2, 0.4, 0.6, 0.8]).round(1)percentiles= 에는 리스트 형식으로 보고싶은 %를 넣는다.
결과값을 확인해 보면 50%를 넣지도 않았는데 나오는 것을 확인할 수있다.
movie_df.describe(percentiles=[]).round(1)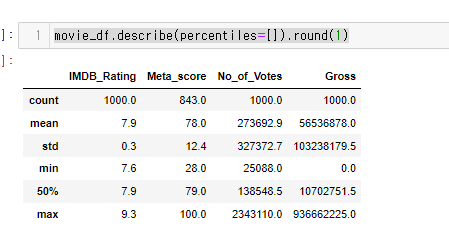
percentiles= 에 아무것도 안넣었을 때에도 50%가 나온다.
왜냐하면, 50%는 사실 MEDIAN(중앙값)이기 때문이다.
집계함수 인자 **numeric_only=**
- max, min, mean 등은 숫자형 데이터만 지원하기 때문에 문자열이 섞인 DataFrame내에서는 에러가 발생한다.
numeric_only=는 이때 숫자만 처리하도록 지정하는 함수이다.
에러나는 코드
movie_df.max()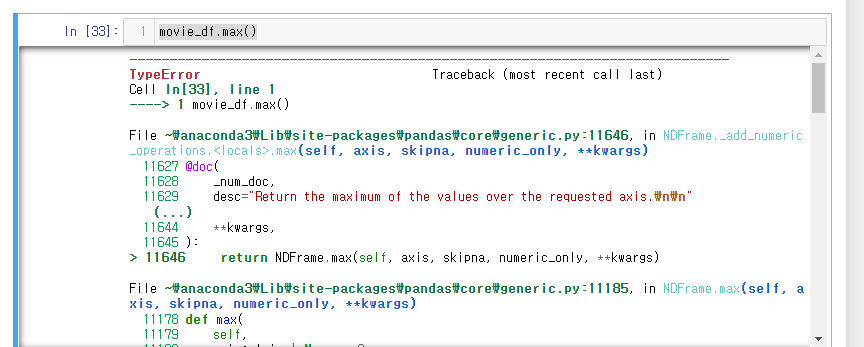
movie_df에는 문자열도 포함되어 있기 때문에 에러가 발생한다.
이때 max() 인자값에 numeric_only=True를 넣어주면 숫자열만 계산하게 된다.
movie_df.max(numeric_only=True)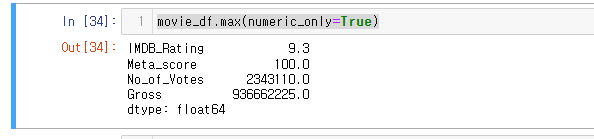
정상 작동!
집계함수 **quantile()**
- 분위수를 확인해줌.
- 인자값에
q=을 넣어 확인하려는 %를 작성 - 50%에 있는 값은 무엇?
- 인자값에
movie_df 에 있는 50% 값 확인 코드
movie_df.quantile(q=0.5,numeric_only=True)
집계함수 인자 **include=**
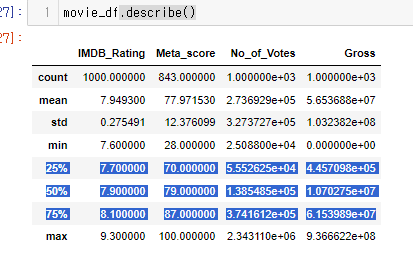
이전에 슬램덩크csv 파일에서 통계요약본 확인시 문자열도 보기 위해서 describe() 인자에 include=’all’ 을 입력한 적 있다.
즉, include= 는데이터 유형을 선택해서 조회할 수 있는 역할을 해준다.
default 값은 None을 가지고 있다.
movie_df.describe() 를 수행할 때 문자열만 있는 값을 통계 내보자.
사용 할때에는 대괄호 안에 오브젝트의 ‘O’ 또는 ‘object’를 넣어줘야 된다.
movie_df.describe(include = ['O'])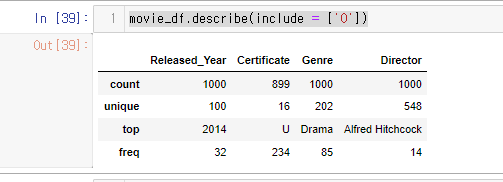
문자열만 되어있는 값을 보여줌.
문자열과 숫자열 둘다 볼 수도 있다.
include = 는 리스트의 형태이기 때문에 다른 값을 추가로 넣어줄 수 있다.
movie_df.describe(include = ['O','number'])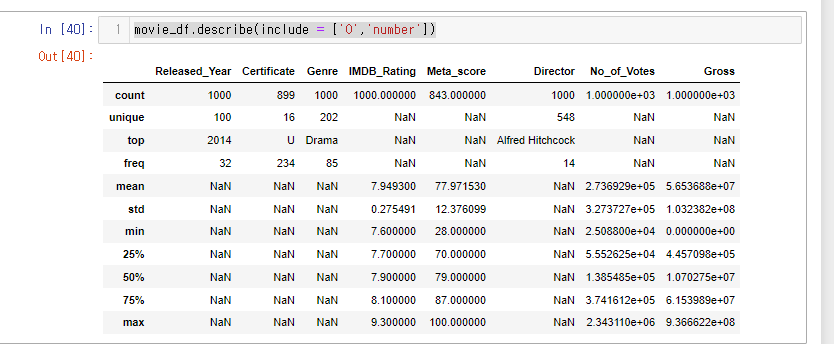
describe()에서 표현할 수 없는 항목은 NaN으로 나온다.
- 문자열 데이터는 mean, std, min 등을 표현할 수 없고
- 숫자형 데이터는 unique, top, freq를 표현할 수 없다.
- unique : 숫자형 데이터는 연속성을 갖는 데이터이다. 즉, 고유한 값의 개수를 가질 수 없으므로 NaN으로 처리
- top : 숫자형 데이터는 가장 빈도가 높은 (top) 값이라는 개념이 적용되지 않기에.
- freq : 숫자형 데이터는 각 값의 빈도수를 측정할 수 없으므로

LV. 1