boost course의 자연어 처리의 모든 것을 보고 강의 복습차원에서 작성하였습니다.
greedy deocoding
앞선 chapter에서는 seq2seq 모델에 대해서 설명을 하였습니다. seq2seq model의 decoder는 encoder에서 나온 output과 decoder의 input을 이용하여 다음으로 나올 단어들 중 확률이 가장 높은 단어 하나 만을 선택하게 됩니다. 이러한 방법을 greedy decoding이라고 합니다.

예를들어 위의 그림을 보시면 he라는 단어 다음으로 hit이라는 단어를 예측을 하였고 hit 다음으로 me라는 단어가 나와야 하는데 a라는 단어를 예측을 한 것을 볼 수 있습니다. 이 다음 단어를 예측을 한다고 가정을 한다면 a라는 x의 값을 가지고 예측을 해야하기 때문에 잘못된 결과가 나오게 될 것입니다. 이처럼 greedy decoding은 가장 확률이 높은 하나의 단어만을 예측값으로 사용하기 때문에 전체 문장의 sequence를 고려하지 못하고 하나의 잘못된 단어가 나오면 그 뒤로 쭉 이상한 예측을 할수밖에 없는 이러한 문제점을 가지고 있습니다.
exhaustive search

greedy decoding의 단점을 보완하기 위해 고안된 방법이 exhaustive search라는 방법입니다. 이 방법의 경우에는 모든 경우의 수를 생각하게 됩니다. 좀 더 쉽게 설명을 하기 위해 예를 들어보겠습니다. decoder의 1번째 step에서 [start]토큰과 encoder output을 입력으로 받습니다. 그 다음엔 1 step에서 나온 output을 가지고 softmax 함수를 사용하여 전체 확률을 구할 것입니다. 전체 vocab의 집합에는 [A,B,C]라는 단어 3개밖에 없고 A(0.8), B(0.1), C(0.1)이라는 단어가 나왔다고 가정을 하겠습니다. 이제 exhaustive search는 2번째 step에서는 이 A, B, C의 경우 모두를 고려하여 다음단어를 예측을 합니다. 그러면 총 3 X 3 = 9가지의 경우의수가 생기게 될 것이고 전체의 경우의 수는 (vocab에 있는 단어의 수)를 전체 time step만큼 곱한 경우의 수가 나오게 될 것입니다. 즉 모든 경우의 수를 다 고려하는 완전탐색을 한다는 뜻이 됩니다.
위와 같은 방법에서도 문제점이 존재합니다. 지금의 예시에서는 vocab의 size를 3으로 제한하였지만 실제 task의 경우에는 100000 또는 1000000개의 단어를 가지게 될텐데 이 경우에도 모든 step에 대하여 완전탐색을 하는 경우에는 시간적인 비용이 엄청나게 많이 들어간다는 것을 알 수 있습니다.
beam search

beam search 방법의 경우 위에서 말한 두가지 방법의 절충안이라고 할 수 있습니다. 이 방법은 각각의 step에서 확률이 가장 높은 k개의 경우만 고려합니다. k의 크기는 hyperparameter로 하나의 변수로 설정하는 것이고 이렇게 구해진 k개의 경우를 가지고 가장 높은 각각 계산한 확률이 가장 높은 경우 하나를 정답으로 택하는 것입니다. 이 방법에서는 모든 경우의 수를 고려하지 않고 k개의 겨우만 고려한다는 점에서 완벽한 방법은 아니지만 exhaustive search보다 시간적인 측면에서 훨씬 효율적이고 greedy deocoding 보다 더 좋은 예측값을 가져온다는 장점이 있습니다.
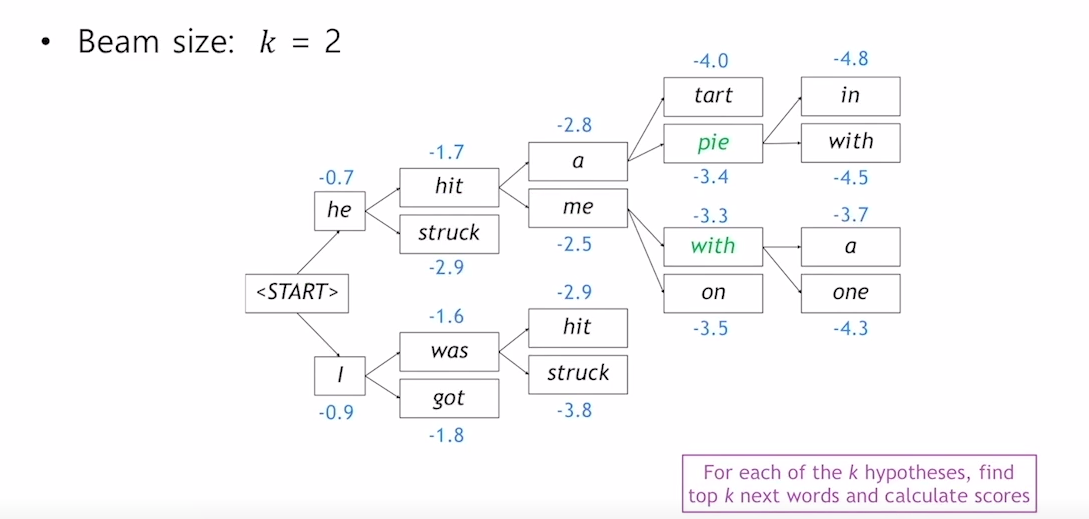
beam search의 예시를 한번 살펴보겠습니다. beam search는 k=2인 경우 처음에 [start] 토큰을 입력 받고 2가지 경우의 수(He, I)를 만들어 내게 됩니다. 그 후 각각의 경우에 대해 또 두가지 경우를 생각하고 (He - hit, struck), (I - was, got) 총 4 가지의 경우에 대하여 각각의 확률을 구합니다. 그 다음 4가지 경우중 가장 확률이 높은 (He - hit)과 (I - was)에 대해서 또 각각 두가지 경우를 생각하게 됩니다. 이러한 식으로 각각의 경우의 수에서 [END] 토큰이 나올때 까지 반복하여 총 K개의 sequence를 얻을 때까지 반복하게 되고 그 중 확률이 가장 높은 경우의 수를 정답으로 채택하게 됩니다.

이 방법에서는 [END] 토큰이 나올 때 까지 K개의 경우의 수를 고려하는 것을 반복하게 됩니다. 이러한 방식을 사용하는 경우 어떠한 문장에서는 [END] 토큰이 빨리나오고 또 다른 문장에서는 [END] 토큰이 나중에 나오는 경우가 발생할 수 있습니다. 이 경우 문장의 길이가 달라지게 되는데 확률의 특성상 문장의 길이가 달라지면 확률을 곱하는 횟수가 많아지게 되고 문장의 길이가 길면 길수록 확률이 작게 나오게 되는 문제가 발생합니다. 이 경우를 방지해 주기 위하여 beam search에서는 전체 확률에 time step으로 나누어 noramlize를 하여 확률을 비교합니다.
evaluation metric
지금부터는 자연어 생성모델을 평가하는 방법에 대하여 알아보겠습니다. machine learning에서의 평가지표에는 여러가지 방법들이 있습니다. 가장 기본적이 지표로는 accuracy가 있습니다. 하짐나 accuracy의 경우에는 자연어를 평가하는 데에는 좋은 지표는 아닙니다. 예를들어 i am a student라는 문장이 있고 모델이 oh i am a student라고 예측을 했다고 생각을 해봅시다. 그렇다면 이 두 문장에 있어서 의미의 차이라던지 의미의 유사도 측면에서는 크게 차이가 나지 않는 것을 알 수 있습니다. 하지만 실제 accuracy를 계산해보면 어떤 time step에서도 틀린결과가 나온 것이 되어 accuracy=0이 되게 됩니다. 이러한 점에서 accuracy는 자연어 생성모델을 평가하는 데에 있어서는 좋은 방법이 아닌 것을 알 수 있습니다.
이제 다른 지표들을 한번 살펴보겠습니다.
- Reference : Half of my heart is in Havana ooh na na (실제값)
- Predicted : Half as my heart is in Obama ooh na (예측값)
위의 경우를 가정하여 보겠습니다.
Precision
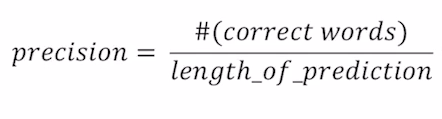
먼저 precision의 경우를 살펴보겠습니다. precision은 전체 예측값의 길이 분에 맞춘 word의 수로 계산이 됩니다. precision의 좀 더 직관적인 의미는 결과(예측값)가 우리가 원하는 값(실제값)을 얼마나 포함하고 있는지에 대한 의미가 됩니다. 그래서 위의 예시의 경우 precision을 구하게 되면 7/9이 되어 78% 정도 나온다고 볼 수 있습니다.
Recall
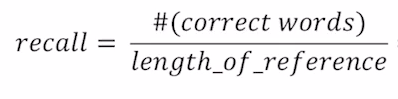
다음으로 recall의 경우를 살펴보겠습니다. recall은 전체 실제값의 길이 분에 맞춘 word의 수로 계산이 됩니다. recall의 경우는 예측값이 실제값을 얼마나 잘 표현해 주었는가에 대한 지표라고 할 수 있습니다. 그래서 위의 예시의 경우 recall을 구하게 되면 7/10이 되어 70% 정도 나온다고 볼 수 있습니다. recall 지표를 자연어 생성모델의 평가에 사용하는 경우에는 몇가지 문제점이 발생할 수 있습니다. 몇 단어가 잘못 들어오게 된 경우와 몇 단어가 빠진 경우를 생각해 보겠습니다. 자연어 생성에 있어서 직관적으로 생각해 보았을 때 몇 단어가 빠진 경우는 의미에 있어 큰차이가 나지 않을 수 있지만 몇 단어가 잘못 들어온 경우는 완전히 의미가 달라지게 됩니다. 이 두가지 경우를 평가지표에 매핑시켜보면 예측값에서 몇단어가 빠진 경우는 recall은 그데로 일 것이고 precision은 커질 것입니다. 그리고 몇단어가 잘못 들어간 경우 precision 자체는 작아질 것이고 recall은 변화가 없을 것입니다. 그래서 문장에서 단어가 잘못 들어오게 되는 경우를 더 잘 반영해 주는 precision이 recall보다 좀 더 적합한 지표라고 할 수 있습니다.
F1-score
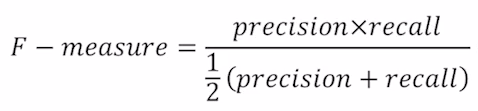
이제 f1-score에 대해서 살펴보겠습니다. f1-score는 위와 같은 식으로 계산이 되며 precision과 recall의 조화평균을 의미하게 됩니다. 조화평균의 경우에는 두 값중 좀 더 낮은 값에 비중을 더 실어주는 경향이 있습니다.
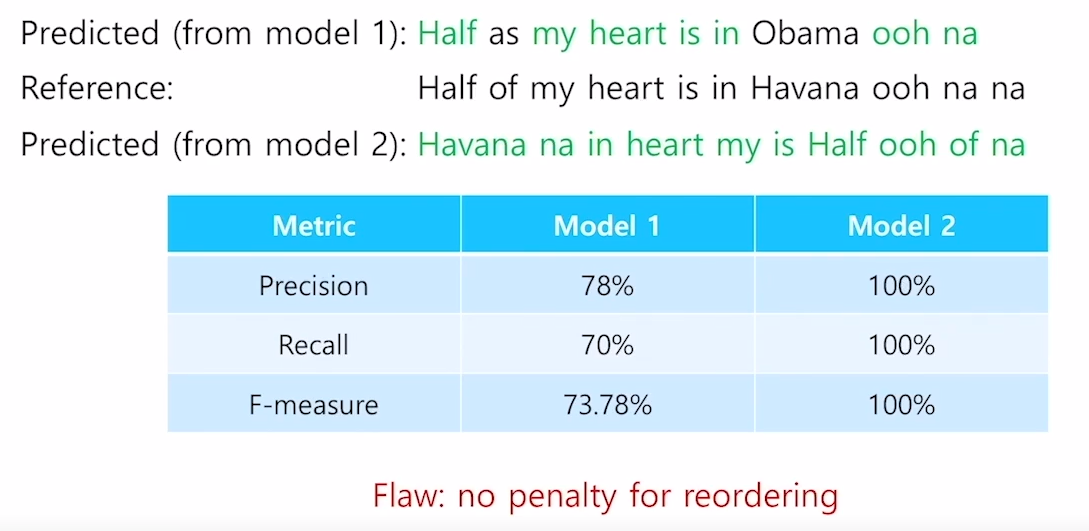
f1-score와 다른 지표들의 실제 예시를 한번 보겠습니다. 위의 그림을 보면 두개의 모델이 예측결과를 나타내었고 reference가 존재하는 것을 알 수 있습니다. model 1의 prediction을 보면 전체 문장 중 2개의 단어를 틀리고 하나를 빼먹은 것을 알 수 있고 model 2의 prediction을 보면 reference 문장의 단어순서를 완전히 섞어 놓아 문법상으로 하나도 맞지 않는 것을 알 수 있습니다. 하지만 1번째의 경우에는 73.78이 나오고 두번째 경우엔 3가지 지표 모두 100이 나오는 것을 알 수 있습니다. 이처럼 이 3가지 지표는 문장의 순서를 섞어두면 문법상 하나도 맞지 않지만 100점짜리 문장이라고 판단을 하는 것을 볼 수 있습니다.
BLEU score

위 지표들의 reordering 문제에 있어 단점을 보완한 지표가 BLEU score입니다. BLEU score는 precision을 이용하여 계산이 구해집니다. recall을 사용하지 않고 precision만을 사용하는 이유는 위의 recall의 설명에 잘 나와있으니 참고 부탁드립니다. BLEU score는 precision을 사용을 하는데 하나의 개별 단어만을 고려하는 것이 아니라 n-gram을 1 ~ 4까지의 span 범위를 설정하여 고려하게 됩니다. 기존의 precision의 경우는 문장의 순서를 바꿔둔 경우 문법상 맞지 않지만 100점으로 인식한다는 단점이 존재하였습니다. 하지만 이처럼 n-gram을 이용하여 여러가지 span을 기준으로 precision을 고려한다면 문장의 순서가 바뀌어도 precision의 점수에 penalty가 들어가기 때문에 위의 방법들 보다 좀 더 효율적이라고 할 수 있습니다.
또 BLEU score에서 중요한 point는 brevity penalty를 고려한다는 점입니다. brevity penalty는 만약 모델이 reference보다 짧은 문장을 생성을 하였을 때 penalty를 적용하는 방법입니다. 문장이 짧으면 짧을수록 좀 더 높은 확률을 가지기 때문에 위의 수식을 보면 reference의 문장길이/prediction 문장의 길이를 곱해주어 짧은 예측문장에 대하여 penalty를 적용하는 것을 알 수 있습니다.

이제 BLEU score의 예시를 한번 살펴보겠습니다. prediction과 reference의 setting은 위 그림과 같습니다. 아까 f1-score에서 보았을 때에는 문장의 순서를 바꿔둔 model 2의 경우 100점의 score가 나온 것을 볼 수 있었습니다. 하지만 BLEU score에서는 이러한 문제점들이 n-gram precision에 의하여 잡히는 모습을 볼 수 있습니다. 이러한 이유로 machine translation과 같은 자연어 생성모델에서 BLEU score를 지표로 많이 사용한다고 합니다.
