boost course의 자연어 처리의 모든 것 강의를 보고 복습차원에서 작성하였습니다.
앞선 내용들 까지는 RNN의 구조와 문제점, lstm, gru에 대해서 살펴보았습니다. 이번에서는 이러한 모델들을 가지고 Sequence-to-sequence model을 만들고 이 모델의 구조인 encoder-decoder 구조와 attention에 대해서 살펴보겠습니다.
Sequence-to-sequence model
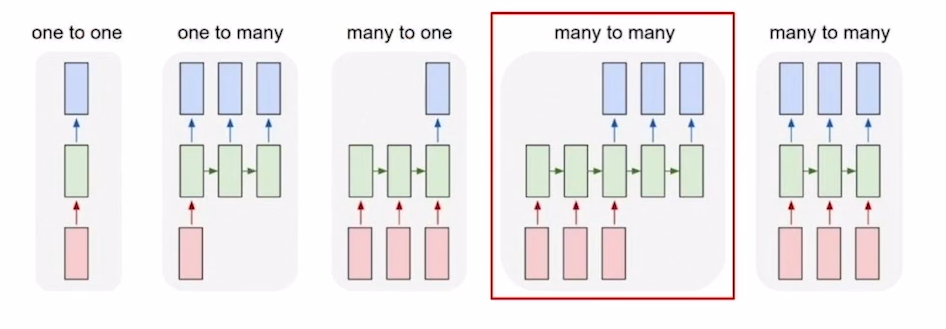
Sequence-to-sequence model은 many-to-many의 type에 해당합니다. 입력값들을 모두 읽고 출력값들을 문장단위로 생성하게 됩니다.
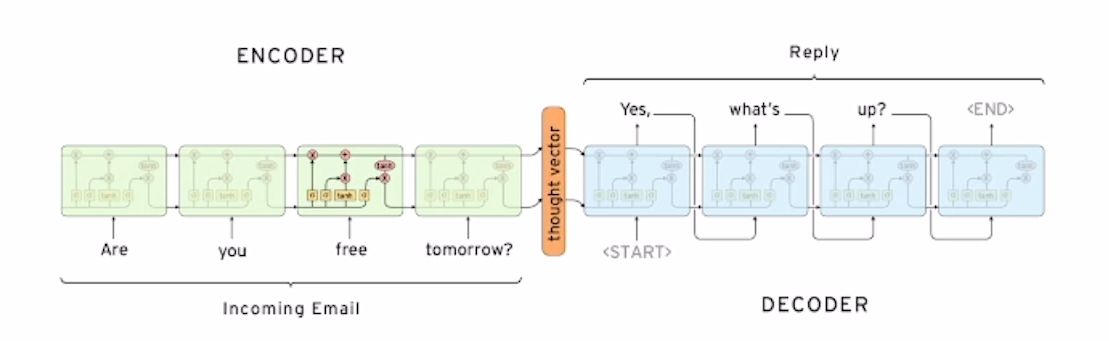
위의 그림은 Sequence-to-sequence model의 예시를 보여주고 있습니다. 위의 예시는 chatbot의 형태로 "Are you free tomorrow?"라는 문장을 입력으로 받고 "Yes, waht's up"이라는 대답을 출력해 주었습니다. 이처럼 입력을 하나의 sequence로 주고 결과를 하나의 sequence로 받는 것을 Sequence-to-sequence model이라고 합니다. 이러한 chatbot의 형태 외에도 Sequence-to-sequence model은 machine translation, MRC, summarize task등 많은 자연어 처리 task에서 사용될 수 있습니다. 이제 Sequence-to-sequence model의 구조를 좀 더 자세히 살펴보겠습니다.
Encoder
Sequence-to-sequence model의 모델에서 입력문장을 읽고 처리하는 부분을 Encoder라고 부르게 됩니다. Encoder와 Decoder 위의 이미지에서 보시면 LSTM의 구조로 이루어 진 것을 알 수 있습니다(LSTM, GRU, RNN 어떤 모델로 구성해도 됨). Encoder 앞장에서 말씀드린 LSTM의 학습방법에 따라 "Are you free tomorrow?"라는 문장에서 단어를 하나씩 입력을 받게 되고 이러한 단어 정보들을 하나의 hidden state로 표현을 하게 됩니다. 그러면 Encoder에서 학습된 마지막 hidden state는 하나의 입력문장 전체에 대한 정보를 포함한 context vector가 되게 될 것입니다.
Decoder
Sequence-to-sequence model의 모델에서 입력된 문장을 바탕으로 출력문장을 처리하는 부분을 Decoder라고 부르게 됩니다. Decoder 역시 LSTM의 구조로 이루어져 있는 것을 볼 수 있습니다. LSTM은 input으로 그 시점의 입력값과 이전 시점의 hidden state를 입력으로 받는다는 것을 말씀드렸습니다. 여기서 디코더의 첫번째 셀의 hidden state는 Encoder의 마지막 hidden state인 context vector를 사용하게 되고 첫 시점의 input은 하나의 특수문자로써 [start] 토큰을 사용하게 됩니다. 이 LSTM은 첫번 째 cell에서 context vector와 [start] 토큰을 이용하여 다음단어를 예측하게 되고 예측한 단어를 다시 다음시점의 input( x(t) )으로 사용하여 [end] 토큰이 나올 때 까지 반복하여 하나의 문장을 만들게 됩니다.
말로만 설명드리면 구조에 대해 이해하기 힘드실 수 있을 것 같아 예시를 들어 설명드리겠습니다. 예를 들어 Encoder를 통하여 "Are you free tomorrow?"라는 문장에 대해서 하나의 context vector가 생성이 되었다고 가정해 보겠습니다. 이 context vector와 [start] 토큰이 Decoder의 입력으로 들어가게 되고 Decoder는 "Yes"라는 단어와 "Yes"라는 단어를 만들었을 때의 시점에 해당하는 hidden state를 출력하게 될 것입니다. 그렇다면 다음 시점의 LSTM은 이전시점의 hidden state와 "Yes"라는 단어를 input( x(t) )으로 사용할 것이고 그것에 대한 output값은 "what's"가 될 것입니다. 이러한 과정을 매 시점마다 반복을 하고 그 시점의 output값이 [end] 토큰이 나올 때 까지 반복한다면 하나의 sequence로 이루어 질 것이고 그것이 "Yes, waht's up"이라는 문장이 될 것입니다.
attention
Sequence-to-sequence model은 LSTM, GRU, RNN등을 이용하여 구성을 한다고 말씀을 드렸습니다. LSTM, GRU와 같은 RNN 계열의 모델들은 Sequence 정보를 하나의 hidden state vector안에 저장을 하게 됩니다. 그래서 아무리 RNN에서 일어나는 Long term dependency의 문제를 어느정도 해결했다고 하더라고 문장의 길이가 길어지면 길어질 수록 sequence의 모든 정보를 하나의 고정된 벡터공간 안에 담아야 하기 때문에 sequence 앞쪽의 정보에 대해서는 정보손실이 발생할 수 밖에 없습니다. 이러한 문제를 해결하기 위해 나온것이 bidirectional과 attention입니다.(bidirectional에 대한 설명은 생략하겠습니다.)
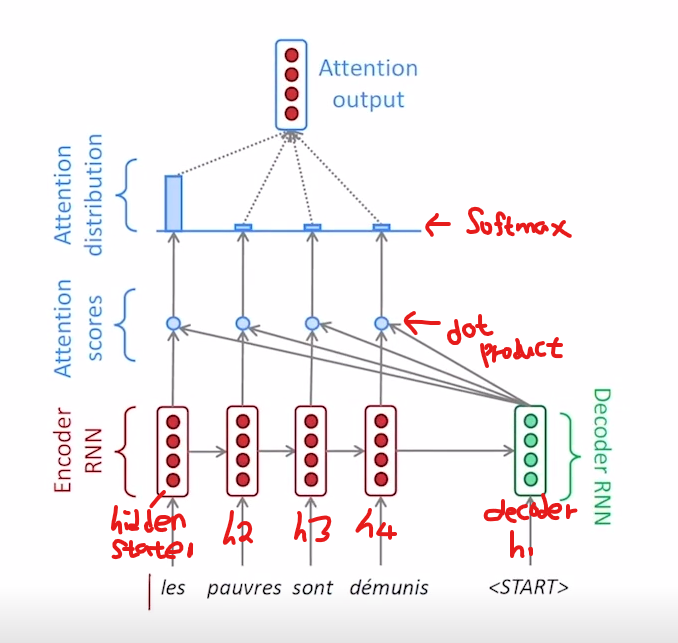
이제부터는 attention의 구조에 대해서 좀 더 자세하게 알아보겠습니다. 앞에서 말씀드린 c의 경우에는 encoder에서 decoder로 마지막 hidden state만을 넘겨주었습니다. 하지만 attention기법에서는 매 time step에서의 hidden state와의 직접적인 계산을 통하여 수행을 하게 됩니다. 매 time step에서의 hidden state는 그 시점의 단어정보들을 가장 잘 반영을 하고 있기 때문에 문장의 길이가 길어지더라도 Long term dependency의 문제가 발생하지 않게 되는 것입니다.
이제 실제 attention output의 계산과정에 대해서 말씀을 드리겠습니다. 위의 그림을 보면 입력문장이 encoder를 거쳐 마지막 hidden state를 decoder에 전달하고 decoder는 [start] 토큰과 encoder의 마지막 hidden state를 입력으로 받아 첫번째 decoder hidden state를 만들어 내었습니다. 이제 여기서 decoder hidden state vector는 encoder의 매 시점의 hidden state vector와 dot product를 수행하여 값을 구하게 되고 이것을 attention score라고 부르게 됩니다. 여기서 attention score의 의미는 decoder hidden state vector와 encoder state vector의 dot product 값이므로 두벡터의 similarity에 대한 score의 의미를 가진다고 볼 수 있습니다. 현재 위의 그림의 예시에 따르면 4개의 attention score가 나오게 되었고 그것을 softmax의 값을 통하여 하나의 확률값으로 변환을 하게 됩니다. 위의 변환을 통하여 softmax를 거쳐 나온 확률값이 [0.85, 0.08, 0.04, 0.03]이 나왔다고 가정을 해 보겠습니다.
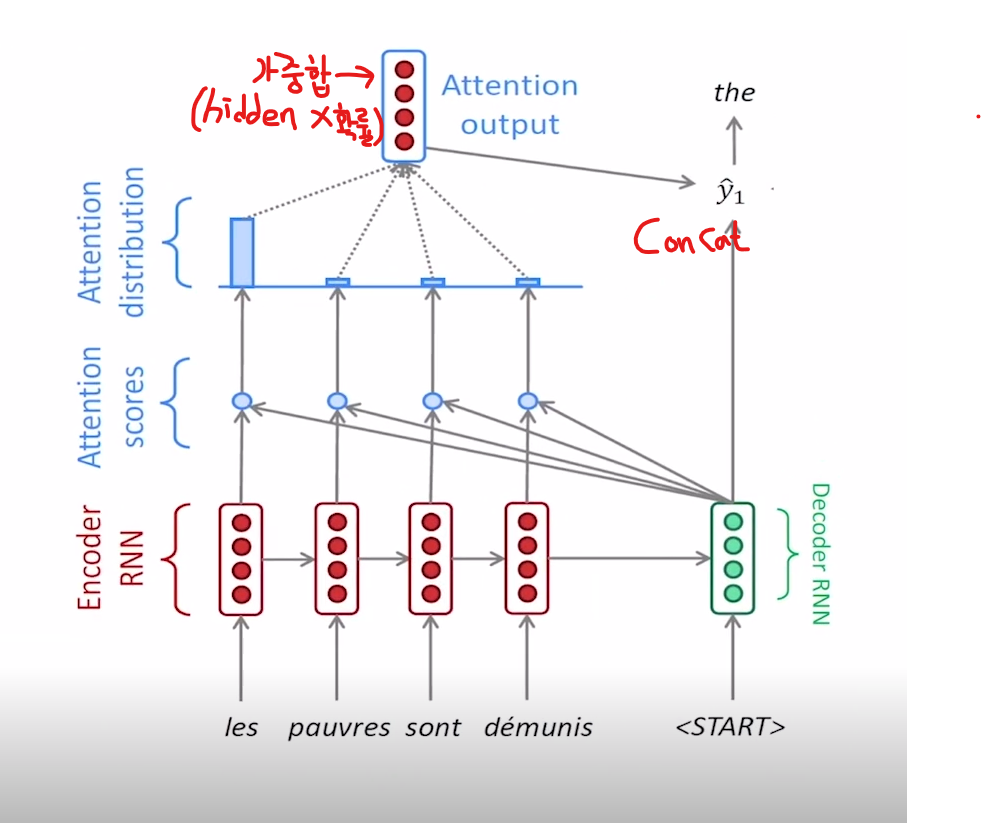
여기서 attention output은 sum(각 시점의 확률 x 각 시점의 hidden state)로 계산을 하여 하나의 벡터가 되게 됩니다. 이것을 attention output이라고 하고 decoder의 첫번째 output과 단순 concat하여 다음 단어를 예측하게 됩니다.
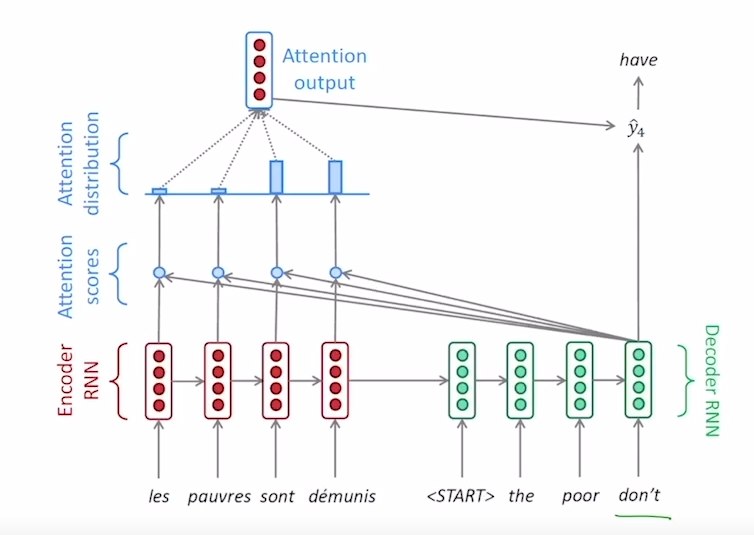
위그림은 위에서 말씀드린 방법을 decoder의 매 시점마다 반복하여 계산을 한 모습을 보여주는 그림입니다. 이처럼 decoder의 매시점마다 반복하면 time step마다 attention을 이용하여 하나의 sequence를 구할 수 있을 것입니다.
teacher forcing
Sequence-to-sequence model을 학습시에는 고려해야하는 요소가 한가지 더 있습니다. 위에서는 decoder의 input을 이전시점의 output을 사용한다고 말씀드렸습니다. 예를 들어 모델을 학습을 하는 시점에서 "Are you free tomorrow?"라는 문장이 인코더에 들어오고 decoder의 input으로 [start] 토큰이 들어왔다고 가정을 해 봅시다. 처음에는 당연히 모델의 모든 parameter가 random initialize 되어 있기 때문에 정답이 "Yes"라는 단어가 나오지 않을 것이고 이상한 다른 단어가 나올 것입니다. 이 것을 "teacher"라는 단어가 첫 time step의 결과로 나왔다고 생각하고 이 단어를 다음 step의 input으로 넣으면 decoder의 입력문장이 이상해져 model이 잘못된 방향으로 학습을 하게 될 것입니다. 이러한 상황을 방지해 주는 것이 teacher forcing이라는 방법입니다. 학습시에는 teacher foring은 decoder의 input으로 예측값이 아닌 실제 정답을 넣어주는 것이고 이렇게 했을 때에 모델이 바른 방향으로 학습을 할 수 있을 것입니다.
training이 아닌 inference의 경우에는 teacher forcing을 사용하지 않고 예측값을 다음 step의 input으로 넣어줌.
다양한 attention mechanism
위의 예제에서는 attention score를 구할 때 decoder hidden state와 encoder hidden state의 단순한 dot product로 구했습니다. 여기서는 attention score를 구하는 다양한 방법들을 알아보겠습니다.
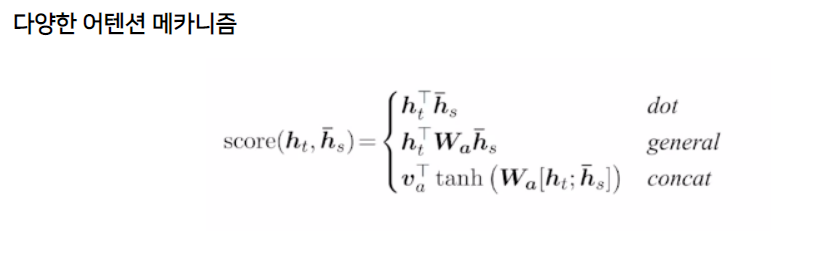
-
Luong - dot : 간단한 내적계산을 통하여 계산하는 방법(기존의 방법과 동일), 학습가능한 parameter 존재하지 않음
-
Luong - general : decoder hidden state와 encoder hidden state의 내적계산 사이에 학습가능한 파라미터로 구성된 행렬을 사용
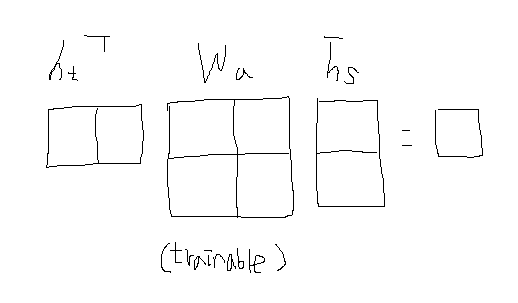
-
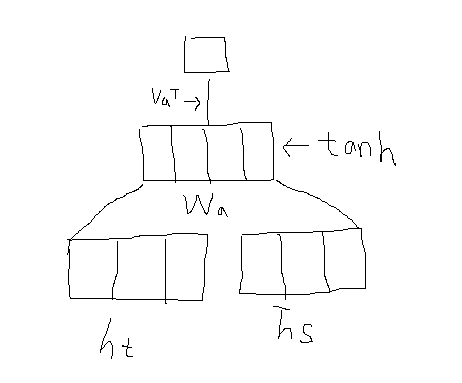
Luong - concat : decoder hidden state와 encoder hidden state를 단순 concat하여 선형변환을 거친 후 tanh함수에 넣고 그 결과를 또 선형변환하여 나타낸 방법
attention의 의의

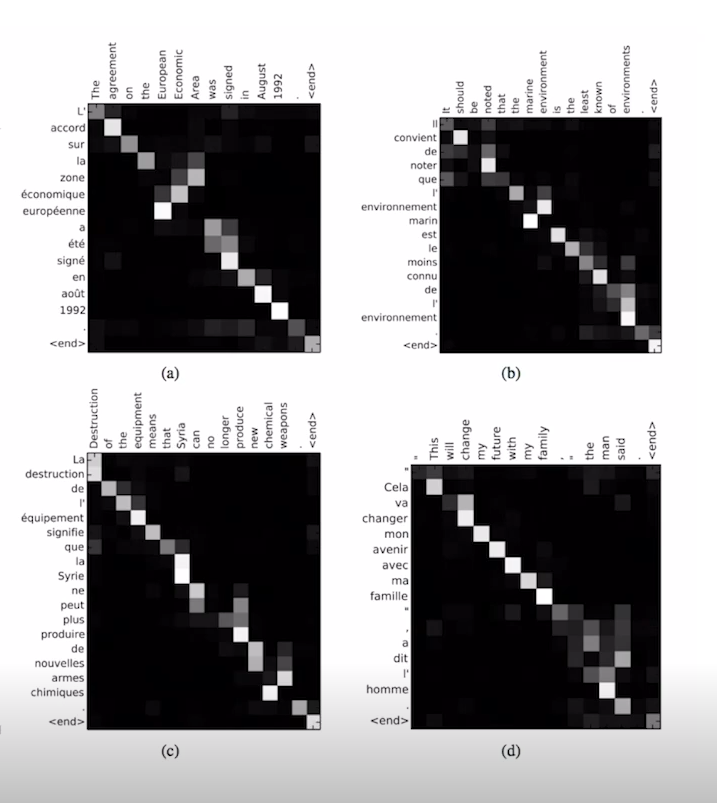
attention score visualization