
Stanford의 cs224n 강의를 보고 복습차원에서 word2vec에 대하여 정리하였습니다.
언어라는 것은 지식을 전달하는 매개체로서 인간의 발전을 이끌어 왔고 현대에서도 아주 중요한 역할을 해오고 있습니다. cs224n의 강의는 이러한 인간의 언어를 어떻게 하면 컴퓨터가 인간의 언어를 더 잘 인식하게 만들고 문맥을 이해하며 사람과 비슷하게 언어를 이용하게 할 수 있을까에 초점을 맞추고 있습니다.

위에 보이는 그림은 OPEN-AI의 GPT-3 모델의 여러 NLP TASK 수행 결과인데 완벽하지는 않지만 여러 TASK에서 자연스럽게 문장을 만들어나가는 모습을 볼 수 있습니다. 이처럼 하나의 모델이 인간의 언어를 어떻게 이해하고 여러가지 태스크를 수행할 수 있었는지에 대해서 한번 알아보겠습니다.
컴퓨터가 언어를 인식하는데에 있어서는 WORD-LEVEL에서 단어의 의미를 인식하는 것 부터시작하여 발전을 해왔습니다. 단어의 의미란 무엇인가 하면 나무를 tree라고 부르듯이 하나의 idea나 things를 어떠한 단어, 즉 symbol에 매핑하여 표현하는 것을 의미합니다. 이러한 과정을 사전을 만드는 것으로 이해할 수 있는데 이 방법이 초기 NLP에서 사용되었던 방법입니다.

NLP 초기에는 컴퓨터가 인식할 수 있도록 WordNet이라는 사전을 만들어 동의어나 좀 더 상위태그의 단어들을 저장하고 사용을 하였습니다. 하지만 이러한 방법에는 몇가지 치명적인 단점이 존재합니다. 일단 이 사전을 업데이트하는데에 많은 Human Resource가 들어가고 많은 신조어들이 생기면서 이 속도를 따라 업데이트를 하는 것이 불가능했습니다. 또 예를들어 A라는 단어가 어떤 경우에는 A'라는 뜻으로 사용되지만 어떤 경우에는 완전히 다른 B라는 의미로 사용되는 경우 이러한 모든 경우들을 반영한다는 것이 사실상 불가능합니다.

무엇보다 Traditional한 방법의 가장 큰 문제는 단어를 개별적인 symbol로 인식을 한다는 점입니다. 위 그림의 oone-hot vectors를 보면 실제 motel과 hotel의 의미는 매우 유사하지만 두 벡터들 사이에 dot product를 계산한다면 0의 값이 나와 두 단어들 간에 유사성을 반영하지 못하게 됩니다. 그리고 원핫벡터로 표현하는 경우 벡터의 dimension은 단어사전 안에 존재하는 모든 단어의 수가 되고 해당 단어 외에는 전부다 0으로 표시하기 때문에 메모리적인 측면에서도 아주 비효울적이라는 단점이 존재합니다.
이러한 이유들로 각 단어벡터들이 similarity의 측면에서도 유사한 결과를 보여줄 수 있도록 word-level이 아닌 context-level에서 단어들을 벡터로 표현하는 방법에 대한 연구가 진행이 되었습니다. context-level에서 단어의 의미는 인접한 단어들이 얼마나 비슷한가로 볼 수 있습니다.
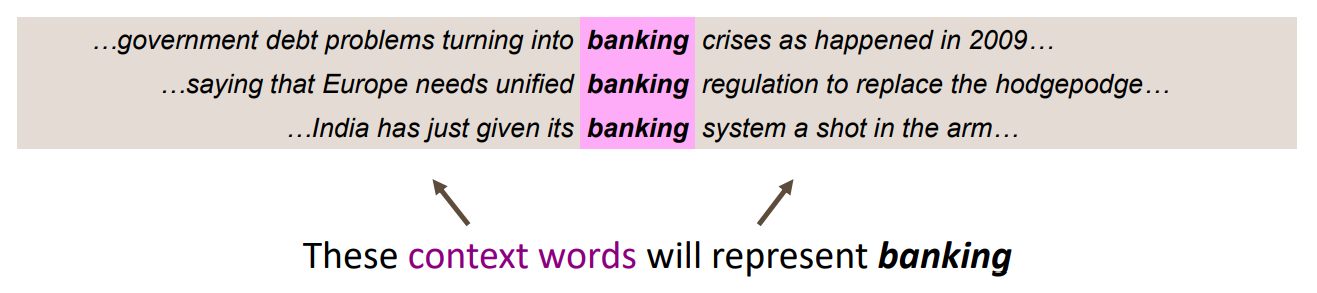
위의 예시에서 banking이라는 단어의 벡터는 주변의 context들로 부터 얻어집니다. 그래서 A라는 단어의 주변에 나온 단어들과 B라는 단어의 주변단어들이 비슷하다면 A와 B단어의 벡터는 유사하게 표현이 될 것이고 dot product를 통하여 similarity를 계산할 수 있게 됩니다. 이러한 내용들을 바탕으로 나온 방법이 word2vec입니다.
Word2Vec
word2vec은 대량의 텍스트 데이터로 부터 주변 단어가 주어졌을 때 이 단어가 나올 확률(또는 이 단어가 주어졌을 때 특정 주변단어가 주어질 확률)을 이용하여 단어 벡터를 학습하는 방법입니다.
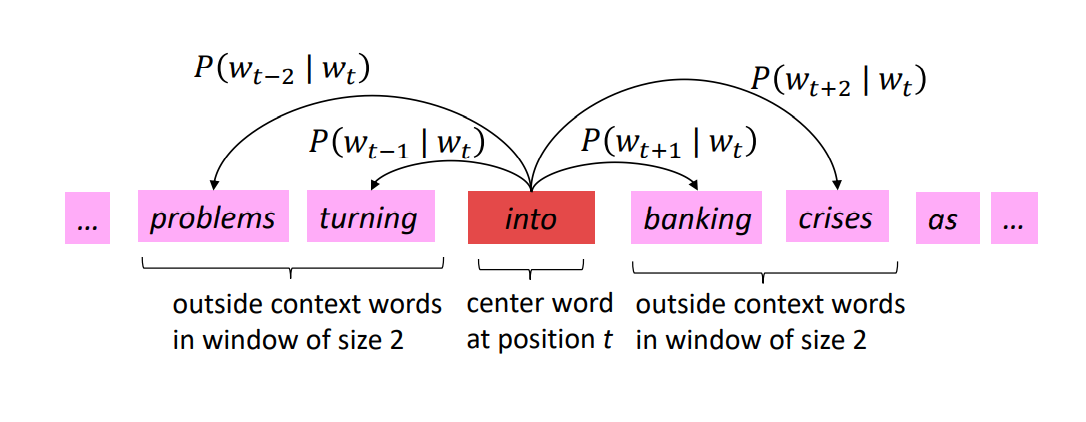
word2vec의 기본적인 원리는 위의 그림과 같습니다. 문장에서 t번째 자리에 'into'라는 단어가 나왔다고 가정을 해 보겠습니다. 그 후 특정 window size(몇개의 주변단어를 고려할 것인지)를 정하고 'into'라는 단어가 나왔을 때 problems, turning, banking, crises와 같은 주변 단어들이 나올 확률을 구하여 다 곱합니다. 그러면 이것이 t번째에 'into'라는 단어가 나올 확률이 됩니다. 그리고 이것을 문장에 있는 각각 개별 단어들에('into', 'banking', 'crises') 적용하여 곱하면 그것이 이 문장이 될 확률을 의미하게 되고 그때의 수식은 아래와 같이 나오게 됩니다. 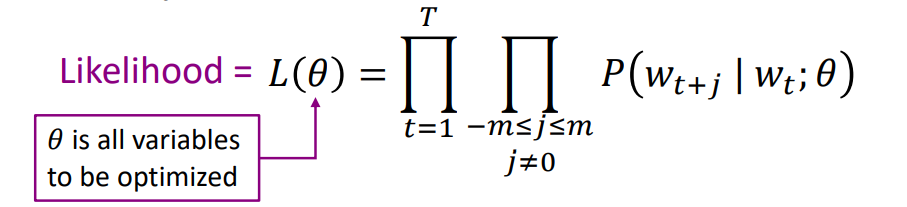
그래서 이론적으로는 word2vec 모델은 이 확률을 maximize하는 방향으로 학습을 하게 되지만 계산상의 편의를 위해 목적함수에 log와 '-'부호를 사용하여 minimize 하는 방향으로 학습을 진행하게 되고 목적함수 식은 아래와 같습니다.
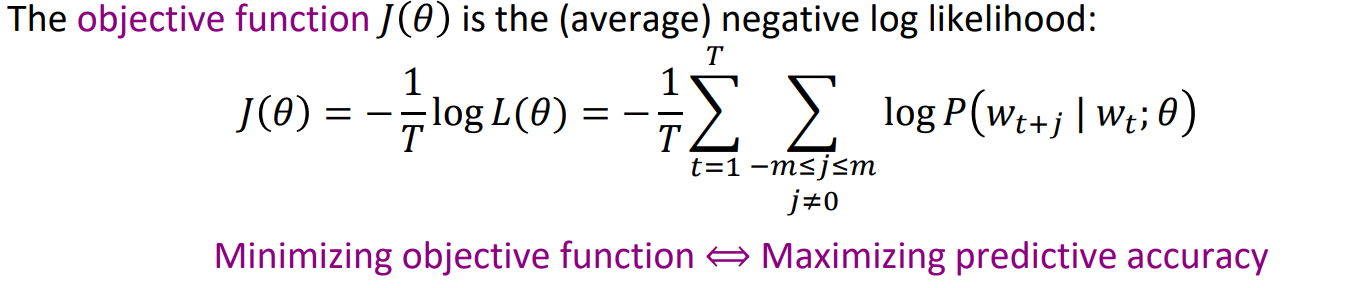
이까지 하면 word2vec에 대한 이해는 거의다 되었습니다. 다음으로는 특정 단어가 나왔을 때 어떤 주변단어들이 나올 확률을 어떻게 계산하는지에 대해 알아보겠습니다.
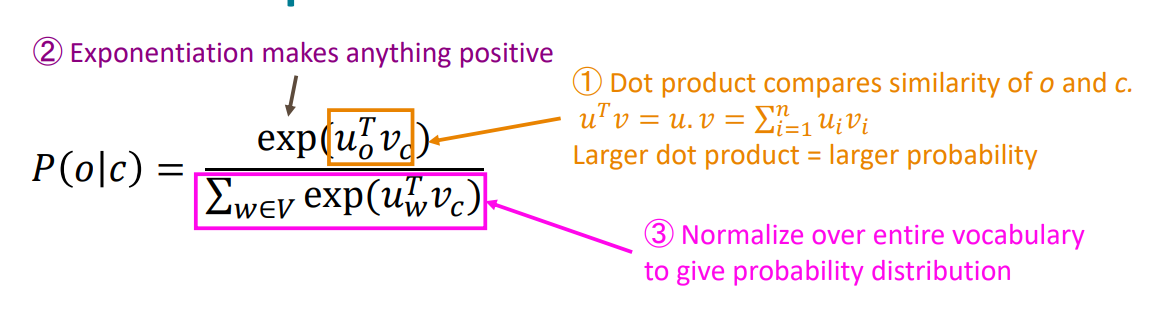
결론부터 말씀을 드리면 두 벡터의 dot product 계산을 이용하여 구하게 됩니다. 이 조건부확률은 확률값으로 나타내기 위하여 먼저 각각의 단어들에 대한 dot product를 다 구한 후 더한 값을 분모에 사용하고 그 단어에 해당하는 dot product값을 분자로 사용하여 각각의 합이 1인 확률값으로 나타나게 됩니다. 앞에서 dot product을 이용하여 조건부확률을 계산한다고 말씀드렸습니다. dot product 계산은 두 벡터의 similarity를 의미합니다. 그리고 모델은 이 확률을 maximize하는 방향으로 학습되기 때문에 같이 자주 등장하는 단어들의 벡터들은 dot product의 값이 커지도록 학습을 진행하게 되고 비슷한 벡터를 가지도록 학습되는 것입니다.
