Stanford의 cs224n 강의를 보고 복습차원에서 word2vec과 glove에 대해 정리하였습니다.
저번 강의에서는 word2vec에 대해서 주요 개념들을 정리하였습니다. 이번 챕터에서는 저번챕터에 이어 word2vec과 Glove에 대해서 알아보겠습니다.
word2vec
▶저번시간 내용
- random한 word vector로 초기화한다.
- 주어진 중심단어에 대해 주변단어들을 예측하는 과정의 반복을 통해 word vector를 update하며 학습을 진행한다.
- 이 과정을 통해 단어간의 similarity를 반영한 word vector를 가지게 된다.
more detail
word2vec에는 두가지 algorithm이 존재합니다.
skip-grams
그 중 첫번째인 Skip-grams algorithm은 이전 챕터에서 나왔던 방법입니다. 이 방법은 중심단어를 기준으로 주변의 단어를 예측하는 식으로 학습을 해나가는 방법입니다. window size가 2 인 문장으로 예를 들어보겠습니다.
I am a student of stanford university
I O O student O O university
위와 같은 식으로 Student라는 단어가 주어졌을 때 빈칸을 예측하는 방법입니다.
CBOW
두번째로는 CBOW라는 방법입니다. 이 방법은 Skip-grams와 반대로 주변단어가 주어지고 중심단어를 예측하는 방식으로 학습을 해나가는 방법입니다. 이 방법도 역시 window size가 2인 문장으로 예를 들어보겠습니다.
I am a student of stanford university
I am a ___ of stanford university
위와 같은 식으로 am, a, of, student 단어가 주어지고 그때의 빈칸단어를 예측하는 방법입니다.
negative sampling
다음으로 word2vec에서 생각해야할 방법은 negative sampling입니다. word2vec은 앞에서 말씀드렸을 때 소프트맥스 함수를 지나 단어 집합 크기의 벡터와 실제값인 원-핫 벡터와의 오차를 구하고 이로부터 임베딩 테이블에 있는 모든 단어에 대한 임베딩 벡터 값을 업데이트한다고 말씀드렸습니다. 이처럼 모든 단어임베딩에 대해서 업데이트를 한다면 단어가 많으면 많을수록 해야할 계산이 기하급수적으로 늘어나게 됩니다. 이러한 문제를 해결하고자 negative sampling 방법을 사용을 하였습니다. negative sampling은 이 문제를 일부 단어집합에만 집중하여 이진분류문제로 바꾸어 접근을 합니다. 예를들면 우리에게 주어진 중심단어가 student이고 주변단어가 stanford, study와 같은 단어라면 전체단어 집합에서 무작위로 상관없는 conference, cat이라는 단어들을 일부 가져옵니다. 이렇게 전체 단어집합보다 훨씬 작은 stanford, study, conference, cat이라는 단어집합을 가지고 실제 주변단어인지에 대한 긍정/부정의 문제로 바꾸어 푸는것입니다. 앞서 말씀드린 것을 좀 더 자세하게 살펴보겠습니다.

기존의 skip-gram모델은 cat이라는 단어가 주어졌을 때 sat이라는 단어를 예측하도록 학습을 합니다.

하지만 negative sampling의 방법은 위의 그림처럼 주변단어일 확률을 뽑아내고 그것이 실제 주변단어에 존재하는 지를 예측을 하는 것입니다.
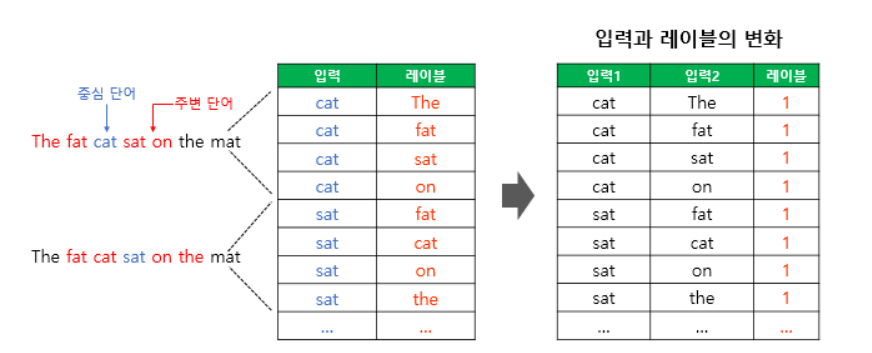
앞의 방식을 학습하기 위해서는 데이터셋을 좀 조정을 하여야 합니다. 실제 중심단어와 주변단어의 쌍을 input으로 만들고 실제 주변단어인지 여부를 label에서 1로 줍니다.
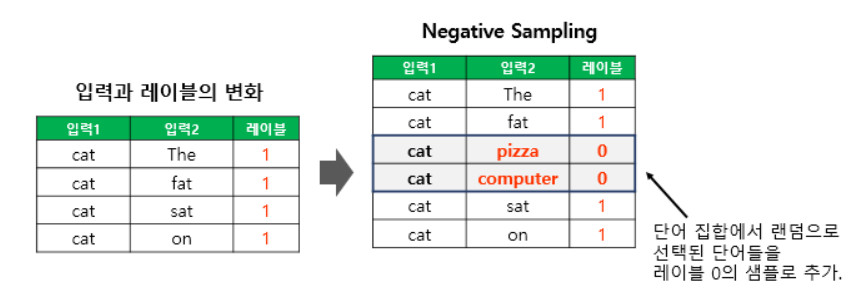
그리고 전체 단어집합에서 random으로 주변단어가 아닌 단어들을 뽑아와 0으로 label값을 줍니다.
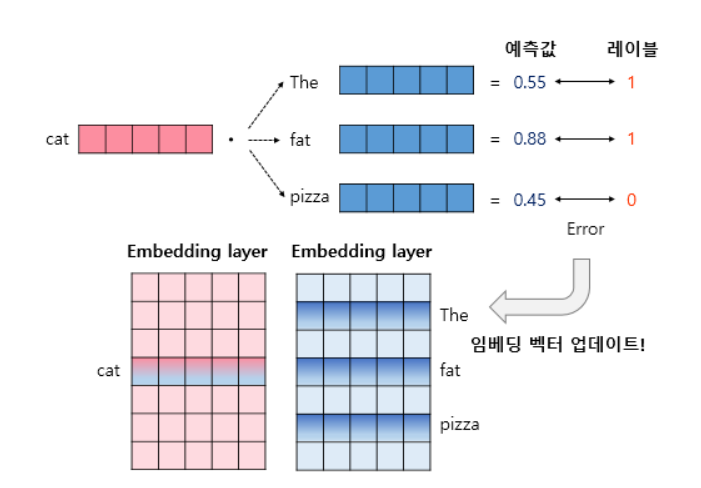
그 후 실제 학습을 진행하고 오차로부터 역전파하여 전체 단어 테이블이 아닌 실제 사용되는 일부 임베딩 벡터만을 업데이트 하는 방식으로 모델이 학습이 진행이 되는 것입니다.
co-occurence matrix
그러명 여기서 그냥 바로 동시에 등장하는 단어들을 고려하면 되지 왜 전체 corpus에 대해 여러번 학습을 진해해야 하는가에 대한 의문이 생길 수 있습니다.
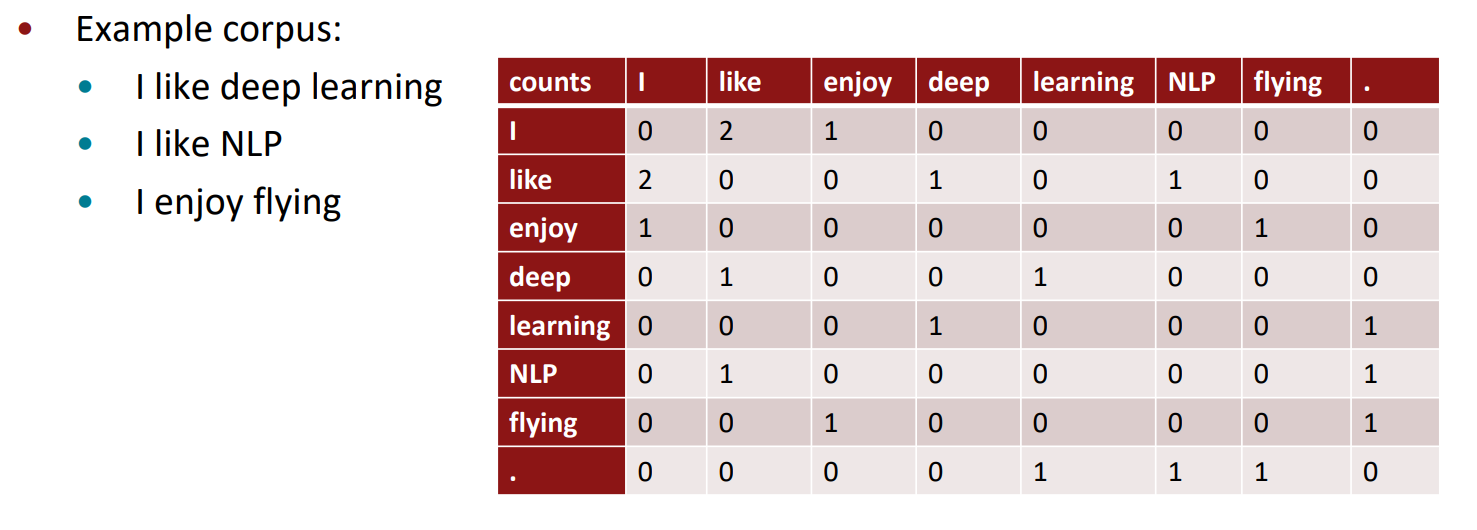
위의 그림이 co-occurence matrix입니다. 이런식으로 만드는 matrix에는 몇가지 문제가 있습니다. 단어의 수가 늘어나면 늘어날수록 matrix의 크기는 엄청나게 커질것이고 sparse matrix이기 때문에 저장공간적인 면에서 엄청난 비효율이 발생할 것입니다. 그래서 이 부분을 보완하고자 Singulr vector decomposition을 사용해 sparse한 matrix의 문제를 어느정도 해결하였습니다.
co-occurence matrix with SVD
하지만 단순이 Count에서 SVD를 적용하는 것에도 문제가 있습니다. 자주 등장하는 단어들이 결과에 너무 많은 영향을 끼친다는 점이었습니다. 그래서 Count에 몇가지 scaling을 적용을 하였습니다.
- log frequencies
- set maximum limit
- ignore the function words(he, she, has)
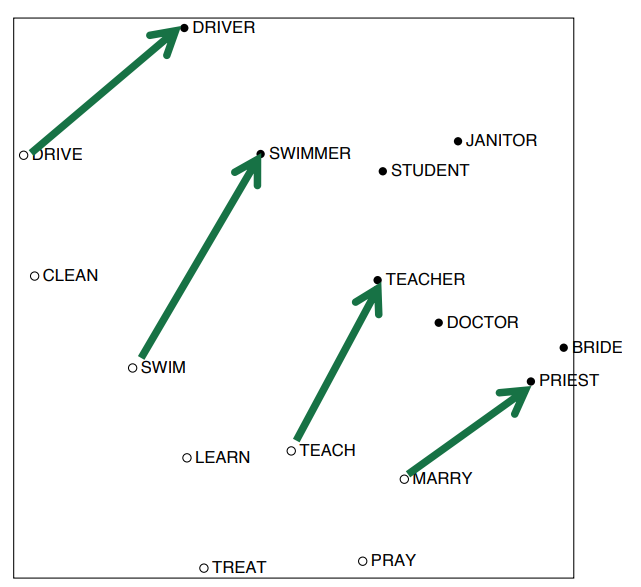
앞의 scaling을 거친 후 단어간의 의미에 있어 어느정도 선형적인 결과가 나오는 것을 알 수 있습니다.
GLOVE
기존의 co-occurence matrix with SVD와 같은 방법은 Count를 기반으로 하여 통계적인 정보를 고려하여 차원축소(SVD)를 이용하여 의미를 잡아내는 것이었습니다. word2vec과 같은 방법은 신경망 학습을 통하여 주변단어 또는 중심단어의 예측을 통해 단어의 벡터를 학습하는 방법이었습니다. 두가지 방법에는 각각 장단점이 다 존재합니다.
첫번째 방법은 count를 기반으로 하여 전체적인 통계를 고려하고 word2vec과 달리 학습하는 데에 오랜 시간이 걸리지 않지만 단어간의 similarity를 넘어서 (왕-남자=여왕)과 같이 유추하는 작업에는 약하다는 단점이 있습니다. 두번째 방법은 유추하는 면에서는 뛰어나지만 window size를 고려하기 때문에 문장 전체에 대한 통계적인 정보는 담지 못한다는 단점이 있습니다. GLOVE algorithm은 이 두가지 모두를 고려하여 단어벡터를 구합니다.
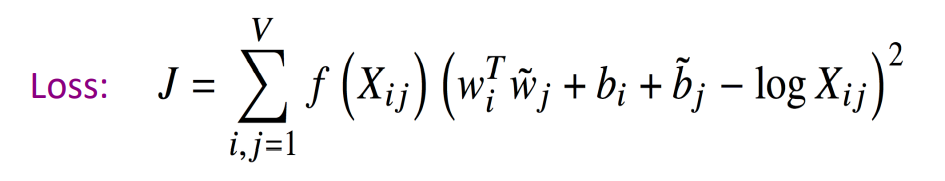
GLOVE에서는 동시등장 확률을 사용하여 임베딩된 중심단어와 주변단어 벡터의 내적이 동시등장 확률이 되도록 하는 것입니다. 동시등장 확률이란 특정 단어 A의 전체 등장 횟수에 특정 단어 A가 등장했을 때 어떤 단어 B가 등장한 횟수를 카운트하여 계산한 조건부 확률입니다. 앞에서 말씀드린 동시등장 확률이 두 A와 B의 단어벡터의 내적이 되도록 위의 loss function을 이용하여 학습을 진행합니다.
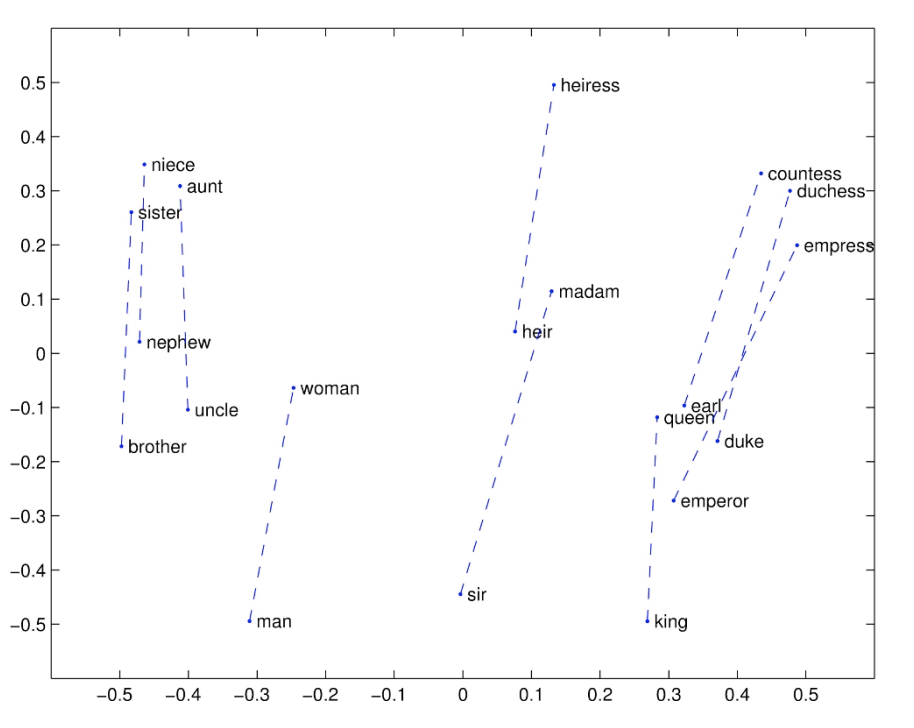
이 그림은 GLOVE algorithm의 결과를 시각화 한 것입니다. 남자와 여자라는 의미상의 차이에 있어 벡터들이 완벽히 직선상의 관계에 있고 그 길이 또한 같은 것은 아니지만 분명히 두개의 의미 사이에 선형의 관계가 존재하고 그 길이 또한 비슷하다는 것을 알 수 있습니다.
GLOVE 방법의 주요 아이디어와 손실함수에 대한 내용은 아래 링크에 잘 설명되오 있으니 참조 부탁드립니다.
https://wikidocs.net/22885
Evaluation
앞의 내용까지는 어떻게 단어들을 더 효율적으로 나타낼 것이지에 대한 방법들에 초점을 맞추었습니다. 이제는 이렇게 만들어진 방법을 어떻게 평가하는지에 대해 알아보겠습니다. 벡터들을 평가하는 방법에는 크게 intrinsic한 방법과 extrinsic한 방법 두가지로 나누어 집니다.
intrinsic - 단어벡터 그 자체로 평가하는 방법
-
how well their cosine distance after addition captures intuitive semantic and syntactic analogy questions
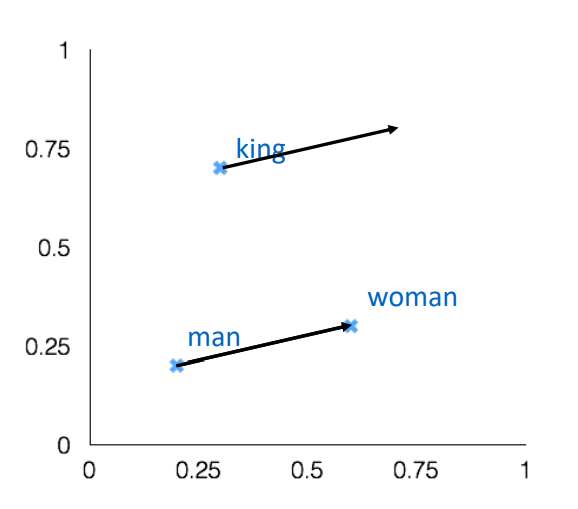
-
Word vector distances and their correlation with human judgments
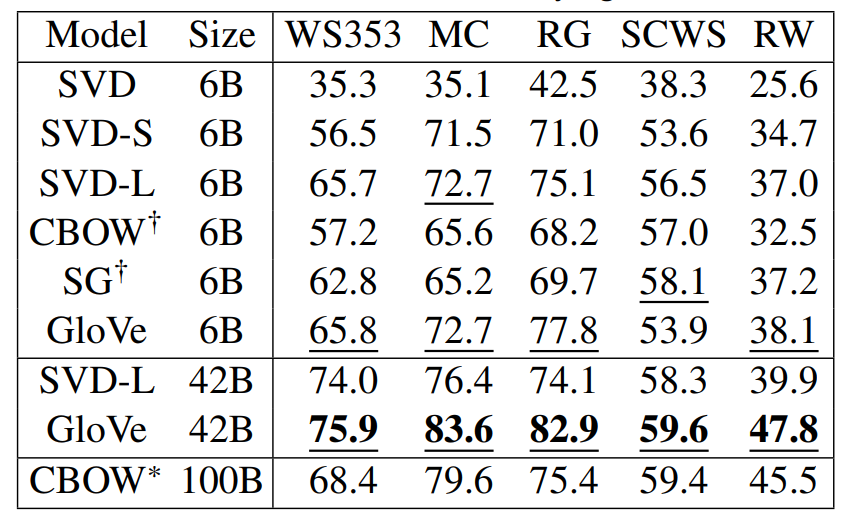
extrinsic - 실제 task에 적용시켜 평가하는 방법
- named entity recognition
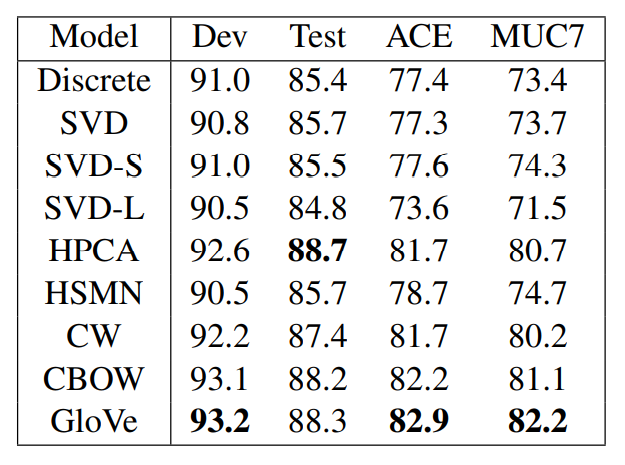
sense ambiguity
여기까지 말씀드리면 한가지 궁금증이 생길 수 있습니다. 예를 들면 '말'이라는 단어는 사람들의 생각을 전달할 때에 사용하는 음성언어를 의미하는 talk의 의미가 있고 말을 타다할때 사용하는 horse라는 의미도 가지고 있습니다. 하지만 word2vec이나 GLOVE와 같은 경우 '말'이라는 단어를 하나의 벡터로 표현을 합니다. 이러한 경우 하나의 벡터가 두가지 모두의 뜻을 가질 수 있을까에 대한 의문이 생길 수 있습니다.
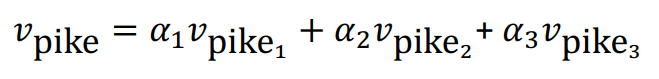
결론을 보면 가질 수 있다고 합니다. 실제 위의 pike라는 예시를 보면 여러가지 뜻을 가지고 있고 word2vec과 GLOVE는 pike를 하나의 벡터로 표현했습니다. 이렇게 표현된 하나의 벡터안에는 각각의 뜻을 가진 벡터의 linear transformation으로 이루어진 것을 알 수 있습니다. 실제로 이렇게 개별 단어의 뜻으로 완벽하게 분리가 되어있는 것은 아니지만 어느정도 의미를 분리할 수 있는 정도까지는 학습이 이루어진다고 합니다.
reference
